Använda en partitionerad graf i Azure Cosmos DB
GÄLLER FÖR: ![]() Gremlin
Gremlin
En av de viktigaste funktionerna i API:et för Gremlin i Azure Cosmos DB är möjligheten att hantera storskaliga grafer genom horisontell skalning. Containrarna kan skalas oberoende av lagring och dataflöde. Du kan skapa containrar i Azure Cosmos DB som kan skalas automatiskt för att lagra grafdata. Data balanseras automatiskt baserat på den angivna partitionsnyckeln.
Partitionering görs internt om containern förväntas lagra mer än 20 GB i storlek eller om du vill allokera mer än 10 000 enheter för begäranden per sekund (RU:er). Data partitioneras automatiskt baserat på den partitionsnyckel som du anger. Partitionsnyckel krävs om du skapar grafcontainrar från Azure-portalen eller 3.x eller senare versioner av Gremlin-drivrutiner. Partitionsnyckel krävs inte om du använder 2.x eller lägre versioner av Gremlin-drivrutiner.
Samma allmänna principer från Azure Cosmos DB-partitioneringsmekanismen gäller med några grafspecifika optimeringar som beskrivs nedan.
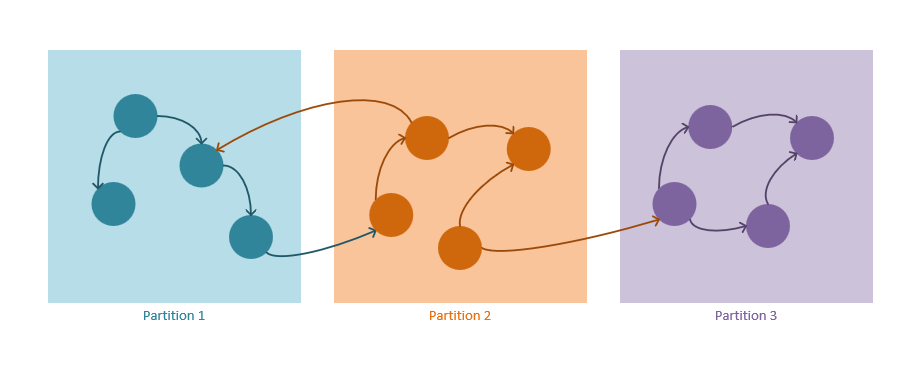
Mekanism för grafpartitionering
Följande riktlinjer beskriver hur partitioneringsstrategin i Azure Cosmos DB fungerar:
Både hörn och kanter lagras som JSON-dokument.
Hörn kräver en partitionsnyckel. Den här nyckeln avgör i vilken partition brytpunkten ska lagras via en hash-algoritm. Egenskapsnamnet för partitionsnyckeln definieras när du skapar en ny container och har formatet .
/partitioning-key-nameKanter lagras med källhörnet. För varje hörn definierar partitionsnyckeln med andra ord var de lagras tillsammans med dess utgående kanter. Den här optimeringen görs för att undvika frågor mellan partitioner när kardinaliteten används
out()i graffrågor.Kanter innehåller referenser till hörnen som de pekar på. Alla kanter lagras med partitionsnycklarna och ID:na för hörnen som de pekar på. Den här beräkningen gör att alla
out()riktningsfrågor alltid är en partitionerad omfångsfråga och inte en blind korspartitionsfråga.Graph-frågor måste ange en partitionsnyckel. Om du vill dra full nytta av den horisontella partitioneringen i Azure Cosmos DB bör partitionsnyckeln anges när ett enda hörn väljs, när det är möjligt. Följande är frågor för att välja en eller flera hörn i en partitionerad graf:
/idoch/labelstöds inte som partitionsnycklar för en container i API för Gremlin.Välj ett hörn efter ID och använd
.has()sedan steget för att ange egenskapen partitionsnyckel:g.V('vertex_id').has('partitionKey', 'partitionKey_value')Välja ett hörn genom att ange en tuppeln inklusive partitionsnyckelvärde och ID:
g.V(['partitionKey_value', 'vertex_id'])Välja en uppsättning hörn med sina ID:n och ange en lista med partitionsnyckelvärden:
g.V('vertex_id0', 'vertex_id1', 'vertex_id2', …).has('partitionKey', within('partitionKey_value0', 'partitionKey_value01', 'partitionKey_value02', …)Använda partitionsstrategin i början av en fråga och ange en partition för omfånget för resten av Gremlin-frågan:
g.withStrategies(PartitionStrategy.build().partitionKey('partitionKey').readPartitions('partitionKey_value').create()).V()
Metodtips när du använder ett partitionerat diagram
Använd följande riktlinjer för att säkerställa prestanda och skalbarhet när du använder partitionerade grafer med obegränsade containrar:
Ange alltid partitionsnyckelvärdet när du kör frågor mot ett hörn. Att hämta hörn från en känd partition är ett sätt att uppnå prestanda. Alla efterföljande angränsande åtgärder kommer alltid att begränsas till en partition eftersom Kanter innehåller referens-ID och partitionsnyckel till målhörn.
Använd den utgående riktningen när du kör frågor mot kanter när det är möjligt. Som nämnts ovan lagras kanterna med sina källhörn i utgående riktning. Därför minimeras risken för att tillgripa frågor mellan partitioner när data och frågor utformas med det här mönstret i åtanke. Tvärtom kommer frågan
in()alltid att vara en dyr-out-fråga.Välj en partitionsnyckel som distribuerar data jämnt mellan partitioner. Det här beslutet beror mycket på lösningens datamodell. Läs mer om att skapa en lämplig partitionsnyckel i Partitionering och skalning i Azure Cosmos DB.
Optimera frågor för att hämta data inom en partitions gränser. En optimal partitioneringsstrategi skulle justeras efter frågemönstren. Frågor som hämtar data från en enda partition ger bästa möjliga prestanda.
Nästa steg
Därefter kan du fortsätta med att läsa följande artiklar:
- Lär dig mer om partitionering och skalning i Azure Cosmos DB.
- Läs mer om Gremlin-stödet i API för Gremlin.
- Läs mer om Introduktion till API för Gremlin.