Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure Cosmos DB kan lagra flera terabyte data. Du kan utföra en storskalig datamigrering för att flytta din produktionsarbetsbelastning till Azure Cosmos DB. I den här artikeln beskriver vi utmaningarna med att flytta storskaliga data till Azure Cosmos DB och introducerar ett verktyg som hjälper dig med migreringen. I den här fallstudien använde kunden Azure Cosmos DB-API:et för NoSQL.
Innan du migrerar hela arbetsbelastningen till Azure Cosmos DB kan du migrera en delmängd data för att verifiera vissa aspekter som val av partitionsnyckel, frågeprestanda och datamodellering. När du har verifierat konceptbeviset kan du flytta hela arbetsbelastningen till Azure Cosmos DB.
Verktyg för datamigrering
Azure Cosmos DB-migreringsstrategier skiljer sig för närvarande beroende på API-valet och storleken på data. Om du vill migrera mindre datamängder – för att validera datamodellering, frågeprestanda, val av partitionsnyckel osv. – kan du använda Azure Data Factorys Azure Cosmos DB-anslutningsprogram. Om du är bekant med Spark kan du också välja att använda Azure Cosmos DB Spark-anslutningsappen för att migrera data.
Utmaningar för storskaliga migreringar
De befintliga verktygen för att migrera data till Azure Cosmos DB har vissa begränsningar som blir särskilt uppenbara i stor skala:
Begränsade utskalningsfunktioner: För att migrera terabyte data till Azure Cosmos DB så snabbt som möjligt och för att effektivt använda hela det etablerade dataflödet bör migreringsklienterna ha möjlighet att skala ut på obestämd tid.
Brist på förloppsspårning och kontrollpekande: Det är viktigt att spåra migreringsförloppet och ha kontrollpunkter vid migrering av stora datamängder. Annars stoppar alla fel som inträffar under migreringen migreringen och du måste starta processen från grunden. Det skulle inte vara produktivt att starta om hela migreringsprocessen när 99 % av den redan har slutförts.
Brist på kö med obeställbara meddelanden: I stora datamängder kan det i vissa fall uppstå problem med delar av källdata. Dessutom kan det finnas tillfälliga problem med klienten eller nätverket. Något av dessa fall bör inte leda till att hela migreringen misslyckas. Även om de flesta migreringsverktyg har robusta återförsöksfunktioner som skyddar mot tillfälliga problem räcker det inte alltid. Om till exempel mindre än 0,01% av källdatadokumenten är större än 2 MB, gör det att dokumentskrivningen misslyckas i Azure Cosmos DB. Helst är det användbart för migreringsverktyget att bevara dessa "misslyckade" dokument till en annan kö med obeställbara meddelanden, som kan bearbetas efter migreringen.
Många av dessa begränsningar åtgärdas för verktyg som Azure Data Factory, Azure Data Migration Services.
Anpassat verktyg med massexekutorbibliotek
De utmaningar som beskrivs i föregående avsnitt kan lösas med hjälp av ett anpassat verktyg som enkelt kan skalas ut över flera instanser och som är motståndskraftigt mot tillfälliga fel. Dessutom kan det anpassade verktyget pausa och återuppta migreringen vid olika kontrollpunkter. Azure Cosmos DB tillhandahåller redan massexekutorbiblioteket som innehåller några av dessa funktioner. Till exempel har massexekutorbiblioteket redan funktioner för att hantera tillfälliga fel och kan skala ut trådar i en enda nod för att använda cirka 500 K RU:er per nod. Massexekutorbiblioteket delar också upp källdatauppsättningen i mikropartitioner som hanteras självständigt som en form av kontrollpunkt.
Det anpassade verktyget använder massexekutorbiblioteket och stöder utskalning över flera klienter och för att spåra fel under inmatningsprocessen. Om du vill använda det här verktyget ska källdata partitioneras i distinkta filer i Azure Data Lake Storage (ADLS) så att olika migreringsarbetare kan hämta varje fil och mata in dem i Azure Cosmos DB. Det anpassade verktyget använder en separat samling som lagrar metadata om migreringsförloppet för varje enskild källfil i ADLS och spårar eventuella fel som är associerade med dem.
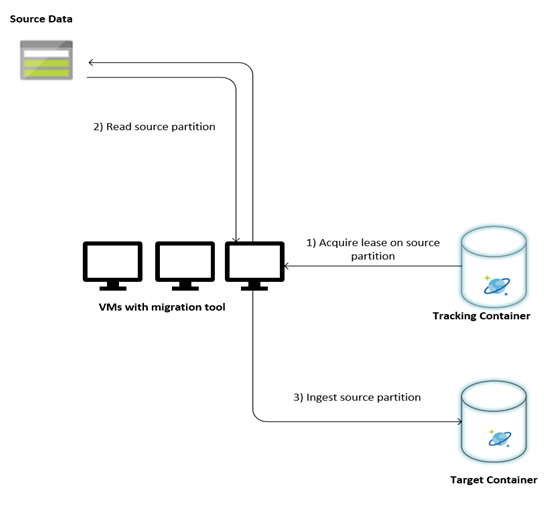
Följande bild beskriver migreringsprocessen med det här anpassade verktyget. Verktyget körs på en uppsättning virtuella datorer och varje virtuell dator frågar spårningssamlingen i Azure Cosmos DB för att hämta ett lån på en av källdatapartitionerna. När detta är klart läss källdatapartitionen av verktyget och matas in i Azure Cosmos DB med hjälp av massexekutorbiblioteket. Därefter uppdateras spårningssamlingen för att registrera förloppet för datainmatning och eventuella fel som påträffas. När en datapartition har bearbetats försöker verktyget fråga efter nästa tillgängliga källpartition. Den fortsätter att bearbeta nästa källpartition tills alla data migreras. Källkoden för verktyget är tillgänglig på lagringsplatsen för massinmatning i Azure Cosmos DB.
Spårningssamlingen innehåller dokument som visas i följande exempel. Du ser ett sådant dokument för varje partition i källdata. Varje dokument innehåller metadata för källdatapartitionen, till exempel dess plats, migreringsstatus och fel (om sådana finns):
{
"owner": "25812@bulkimporttest07",
"jsonStoreEntityImportResponse": {
"numberOfDocumentsReceived": 446688,
"isError": false,
"totalRequestUnitsConsumed": 3950252.2800000003,
"errorInfo": [],
"totalTimeTakenInSeconds": 188,
"numberOfDocumentsImported": 446688
},
"storeType": "AZURE_BLOB",
"name": "sourceDataPartition",
"location": "sourceDataPartitionLocation",
"id": "sourceDataPartitionId",
"isInProgress": false,
"operation": "unpartitioned-writes",
"createDate": {
"seconds": 1561667225,
"nanos": 146000000
},
"completeDate": {
"seconds": 1561667515,
"nanos": 180000000
},
"isComplete": true
}
Förutsättningar för datamigrering
Innan datamigreringen startar finns det några förutsättningar att tänka på:
Beräkna datastorleken:
Källdatastorleken kanske inte exakt mappas till datastorleken i Azure Cosmos DB. Några exempeldokument från källan kan infogas för att kontrollera datastorleken i Azure Cosmos DB. Beroende på exempeldokumentets storlek kan den totala datastorleken i Azure Cosmos DB efter migreringen uppskattas.
Om till exempel varje dokument efter migreringen i Azure Cosmos DB är cirka 1 KB och om det finns cirka 60 miljarder dokument i källdatauppsättningen skulle det innebära att den uppskattade storleken i Azure Cosmos DB skulle vara nära 60 TB.
Skapa containrar i förväg med tillräckligt många RU:er:
Även om Azure Cosmos DB skalar ut lagringen automatiskt är det inte lämpligt att börja från den minsta containerstorleken. Mindre containrar har lägre dataflödestillgänglighet, vilket innebär att migreringen skulle ta mycket längre tid att slutföra. I stället är det användbart att skapa containrar med den slutliga datastorleken (enligt uppskattning i föregående steg) och se till att migreringsarbetsbelastningen förbrukar det etablerade dataflödet fullt ut.
I föregående steg, eftersom datastorleken uppskattades till cirka 60 TB, krävs en container med minst 2,4 M RU:er för att rymma hela datamängden.
Beräkna migreringshastigheten:
Förutsatt att migreringsarbetsbelastningen kan förbruka hela det tillgängliga dataflödet, skulle det tillgängliga dataflödet ge en uppskattning av migreringshastigheten. Om du fortsätter med föregående exempel krävs fem RU:er för att skriva ett 1 KB-dokument till Azure Cosmos DB API för NoSQL-konto. 2,4 miljoner RU:er skulle tillåta överföring av 480 000 dokument per sekund (eller 480 MB/s). Det innebär att den fullständiga migreringen på 60 TB tar 125 000 sekunder eller cirka 34 timmar.
Om du vill att migreringen ska slutföras inom en dag bör du öka det etablerade dataflödet till 5 miljoner RU:er.
Inaktivera indexeringen:
Eftersom migreringen bör slutföras så snart som möjligt rekommenderar vi att du minimerar tiden och ru:erna som ägnas åt att skapa index för vart och ett av de dokument som matas in. Azure Cosmos DB indexerar automatiskt alla egenskaper. Det är värt att minimera indexeringen till några få termer eller inaktivera den helt under migreringen. Du kan inaktivera containerns indexeringsprincip genom att ändra indexingMode till none enligt följande:
{
"indexingMode": "none"
}
När migreringen är klar kan du uppdatera indexeringen.
Migreringsprocessen
När förutsättningarna har slutförts kan du migrera data med följande steg:
Importera först data från källan till Azure Blob Storage. För att öka migreringens hastighet är det bra att parallellisera mellan olika källpartitioner. Innan du påbörjar migreringen ska källdatauppsättningen partitioneras i filer med en storlek på cirka 200 MB.
Massexekutorbiblioteket kan skalas upp för att förbruka 500 000 RU:er på en enskild virtuell klientdator. Eftersom det tillgängliga dataflödet är 5 miljoner RU:er bör 10 virtuella Ubuntu 16,04-datorer (Standard_D32_v3) etableras i samma region där din Azure Cosmos DB-databas finns. Du bör förbereda dessa virtuella datorer med migreringsverktyget och dess inställningsfil.
Kör kösteget på en av de virtuella klientdatorerna. Det här steget skapar spårningssamlingen, som söker igenom ADLS-containern och skapar ett förloppsspårningsdokument för var och en av källdatauppsättningens partitionsfiler.
Kör sedan importsteget på alla virtuella klientdatorer. Var och en av klienterna kan ta ägarskap för en källpartition och mata in sina data i Azure Cosmos DB. När den är klar och dess status har uppdaterats i spårningssamlingen kan klienterna sedan fråga efter nästa tillgängliga källpartition i spårningssamlingen.
Den här processen fortsätter tills hela uppsättningen källpartitioner har matats in. När alla källpartitioner har bearbetats ska verktyget köras på nytt i felkorrigeringsläget i samma spårningssamling. Det här steget krävs för att identifiera de källpartitioner som ska bearbetas på grund av fel.
Vissa av dessa fel kan bero på felaktiga dokument i källdata. Dessa bör identifieras och åtgärdas. Därefter bör du köra importsteget igen på de misslyckade partitionerna för att ange dem igen.
När migreringen är klar kan du kontrollera att antalet dokument i Azure Cosmos DB är detsamma som antalet dokument i källdatabasen. I det här exemplet visade sig den totala storleken i Azure Cosmos DB vara 65 terabyte. Efter migreringen kan indexering aktiveras selektivt och RU:erna kan sänkas till den nivå som krävs av arbetsbelastningens åtgärder.
Nästa steg
- Läs mer genom att testa exempelprogram som använder massexekutorbiblioteket i .NET och Java.
- Massexekutorbiblioteket är integrerat i Azure Cosmos DB Spark-anslutningsappen. Mer information finns i artikeln om Azure Cosmos DB Spark-anslutningsappen .
- Kontakta Produktteamet för Azure Cosmos DB genom att öppna ett supportärende under problemtypen "Allmän rådgivning" och "Stora (TB+)-migreringar" för mer hjälp med storskaliga migreringar.
- Försöker du planera kapacitet för en migrering till Azure Cosmos DB? Du kan använda information om ditt befintliga databaskluster för kapacitetsplanering.
- Om allt du vet är antalet virtuella kärnor och servrar i ditt befintliga databaskluster, bör du läsa om hur man uppskattar enheter för förfrågningar med hjälp av virtuella kärnor eller virtuella CPU:er
- Om du känner till vanliga begärandefrekvenser för din aktuella databasarbetsbelastning kan du läsa om att uppskatta enheter för begäranden med azure Cosmos DB-kapacitetshanteraren