Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Med Azure Cosmos DB for MongoDB kan du använda indexering för att påskynda frågeprestanda. Den här artikeln visar hur du hanterar och optimerar index för snabbare datahämtning och bättre effektivitet.
Indexering för MongoDB-server version 3.6 och senare
Azure Cosmos DB för MongoDB-server version 3.6+ indexerar _id automatiskt fältet och shardnyckeln (endast i fragmenterade samlingar). API:et framtvingar det unika fältet _id per shardnyckel.
API:et för MongoDB fungerar annorlunda än Azure Cosmos DB för NoSQL, som indexerar alla fält som standard.
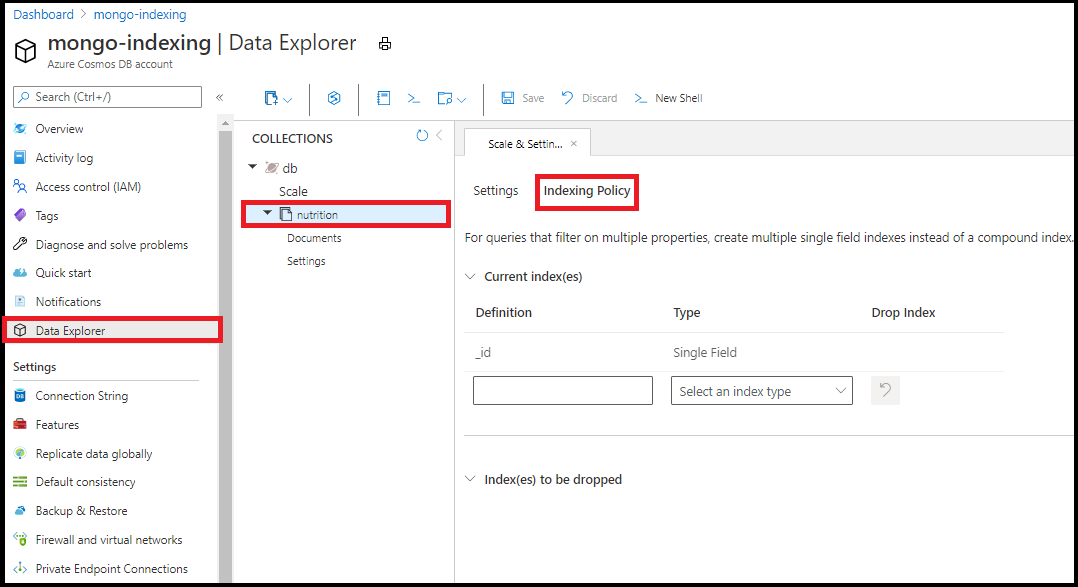
Redigera indexeringsprincip
Redigera indexeringsprincipen i Datautforskaren i Azure-portalen. Lägg till index med ett fält och jokertecken från indexeringsprincipredigeraren i Datautforskaren:
Kommentar
Du kan inte skapa sammansatta index med hjälp av indexeringsprincipredigeraren i Datautforskaren.
Indextyper
Enskilt fält
Skapa ett index för ett enskilt fält. Sorteringsordningen för det enskilda fältindexet spelar ingen roll. Använd följande kommando för att skapa ett index i fältet name:
db.coll.createIndex({name:1})
Skapa samma index för name ett enda fält i Azure-portalen:
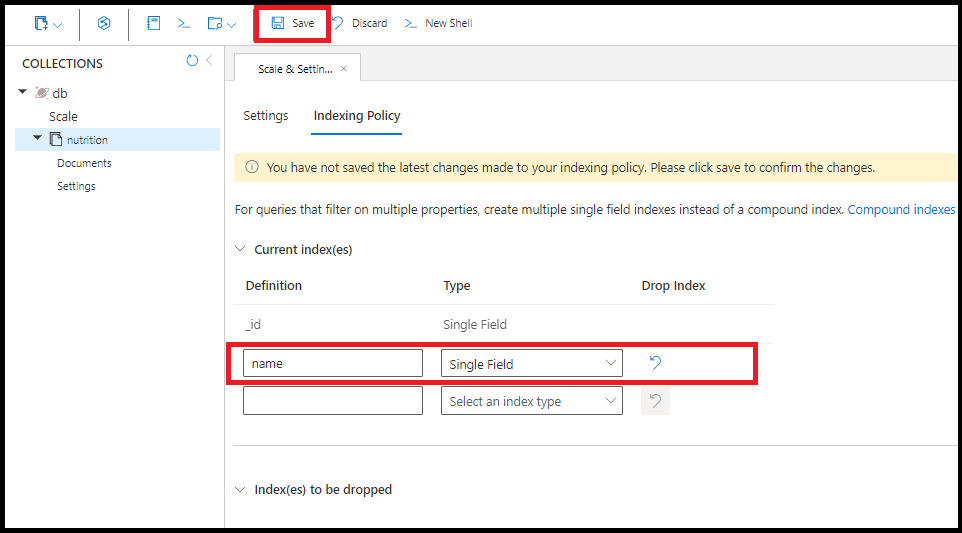
En fråga använder flera index med ett enda fält där det är tillgängligt. Skapa upp till 500 index för enskilda fält per samling.
Sammansatta index (MongoDB-serverversion 3.6+)
I API:et för MongoDB använder du sammansatta index med frågor som sorterar flera fält samtidigt. För frågor med flera filter som inte behöver sorteras skapar du flera index med ett enda fält i stället för ett sammansatt index för att spara på indexeringskostnader.
Ett sammansatt index eller ett enda fältindex för varje fält i det sammansatta indexet resulterar i samma prestanda för filtrering i frågor.
Sammansatta index för kapslade fält stöds inte som standard på grund av begränsningar med matriser. Om ett kapslat fält inte har någon matris fungerar indexet som avsett. Om ett kapslat fält har en matris någonstans på sökvägen ignoreras det värdet i indexet.
Ett sammansatt index som innehåller people.dylan.age fungerar till exempel i det här fallet eftersom det inte finns någon matris på sökvägen:
{
"people": {
"dylan": {
"name": "Dylan",
"age": "25"
},
"reed": {
"name": "Reed",
"age": "30"
}
}
}
Samma sammansatta index fungerar inte i det här fallet eftersom det finns en matris i sökvägen:
{
"people": [
{
"name": "Dylan",
"age": "25"
},
{
"name": "Reed",
"age": "30"
}
]
}
Aktivera den här funktionen för ditt databaskonto genom att aktivera funktionen "EnableUniqueCompoundNestedDocs".
Kommentar
Du kan inte skapa sammansatta index på matriser.
Följande kommando skapar ett sammansatt index för fälten name och age:
db.coll.createIndex({name:1,age:1})
Du kan använda sammansatta index för att sortera effektivt på flera fält samtidigt, enligt följande exempel:
db.coll.find().sort({name:1,age:1})
Du kan också använda föregående sammansatta index för att effektivt sortera på en fråga med motsatt sorteringsordning på alla fält. Här är ett exempel:
db.coll.find().sort({name:-1,age:-1})
Sekvensen för sökvägarna i det sammansatta indexet måste dock exakt matcha frågan. Här är ett exempel på en fråga som skulle kräva ett extra sammansatt index:
db.coll.find().sort({age:1,name:1})
Multikey-index
Azure Cosmos DB skapar multikey-index för indexering av innehåll i matriser. Om du indexerar ett fält med ett matrisvärde indexerar Azure Cosmos DB automatiskt varje element i matrisen.
Geospatiala index
Många geospatiala operatorer drar nytta av geospatiala index. Azure Cosmos DB for MongoDB stöder 2dsphere index. API:et stöder 2d inte index ännu.
Här är ett exempel på hur du skapar ett geospatialt index i location fältet:
db.coll.createIndex({ location : "2dsphere" })
Textindex
Azure Cosmos DB for MongoDB stöder inte textindex. För textsökningsfrågor i strängar använder du Azure AI Search-integrering med Azure Cosmos DB.
Jokerteckenindex
Använd jokerteckenindex för att stödja frågor mot okända fält. Föreställ dig en samling som innehåller data om familjer.
Här är en del av ett exempeldokument i samlingen:
"children": [
{
"firstName": "Henriette Thaulow",
"grade": "5"
}
]
Här är ett annat exempel med en annan uppsättning egenskaper i children:
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"pets": [
{ "givenName": "Goofy" },
{ "givenName": "Shadow" }
]
},
{
"familyName": "Merriam",
"givenName": "John",
}
]
Dokument i den här samlingen kan ha många olika egenskaper. Om du vill indexering av alla data i matrisen children skapar du separata index för varje egenskap eller skapar ett jokerteckenindex för hela children matrisen.
Skapa ett jokerteckenindex
Använd följande kommando för att skapa ett jokerteckenindex för alla egenskaper i children:
db.coll.createIndex({"children.$**" : 1})
- Till skillnad från i MongoDB kan jokerteckenindex stödja flera fält i frågepredikat. Det finns ingen skillnad i frågeprestanda om du använder ett enda jokerteckenindex i stället för att skapa ett separat index för varje egenskap.
Skapa följande indextyper med jokerteckensyntax:
- Enskilt fält
- Geospatiell
Indexera alla egenskaper
Skapa ett jokerteckenindex för alla fält med följande kommando:
db.coll.createIndex( { "$**" : 1 } )
Skapa jokerteckenindex med datautforskaren i Azure-portalen:

Kommentar
Om du precis har börjat utveckla börjar du med ett jokerteckenindex för alla fält. Den här metoden förenklar utvecklingen och gör det enklare att optimera frågor.
Dokument med många fält kan ha en hög ru-avgift (Request Unit) för skrivningar och uppdateringar. Om du har en skrivintensiv arbetsbelastning använder du individuellt indexerade sökvägar i stället för jokertecken.
Begränsningar
Jokerteckenindex stöder inte någon av följande indextyper eller egenskaper:
Sammansättning
TTL
Unik
Till skillnad från i MongoDB kan du i Azure Cosmos DB for MongoDB inte använda jokerteckenindex för:
Skapa ett jokerteckenindex som inkluderar flera specifika fält
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection " : { "children.givenName" : 1, "children.grade" : 1 } } )Skapa ett jokerteckenindex som exkluderar flera specifika fält
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection" : { "children.givenName" : 0, "children.grade" : 0 } } )
Du kan också skapa flera jokerteckenindex.
Indexegenskaper
Följande åtgärder är vanliga för konton som använder wire protocol version 4.0 och tidigare versioner. Läs mer om index som stöds och indexerade egenskaper.
Unika index
Med unika index ser du till att två eller flera dokument inte har samma värde för indexerade fält.
Kör följande kommando för att skapa ett unikt index i student_id fältet:
db.coll.createIndex( { "student_id" : 1 }, {unique:true} )
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 4
}
För fragmenterade samlingar anger du shardnyckeln (partition) för att skapa ett unikt index. Alla unika index i en fragmenterad samling är sammansatta index och ett av fälten är shardnyckeln. Shardnyckeln bör vara det första fältet i indexdefinitionen.
Kör följande kommandon för att skapa en fragmenterad samling med namnet coll (med university som shardnyckel) och ett unikt index för fälten student_id och university :
db.runCommand({shardCollection: db.coll._fullName, key: { university: "hashed"}});
{
"_t" : "ShardCollectionResponse",
"ok" : 1,
"collectionsharded" : "test.coll"
}
db.coll.createIndex( { "university" : 1, "student_id" : 1 }, {unique:true});
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 3,
"numIndexesAfter" : 4
}
Om du utelämnar "university":1 satsen i föregående exempel visas följande felmeddelande:
cannot create unique index over {student_id : 1.0} with shard key pattern { university : 1.0 }
Begränsningar
Skapa unika index medan samlingen är tom.
Azure Cosmos DB för MongoDB-konton med kontinuerlig säkerhetskopiering har inte stöd för att skapa ett unikt index för en befintlig samling. För ett sådant konto måste unika index skapas tillsammans med skapandet av deras samling, vilket måste och bara kan göras med hjälp av kommandona för att skapa samlingstillägget.
db.runCommand({customAction:"CreateCollection", collection:"coll", shardKey:"student_id", indexes:[
{key: { "student_id" : 1}, name:"student_id_1", unique: true}
]});
Unika index på kapslade fält stöds inte som standard på grund av begränsningar med matriser. Om det kapslade fältet inte har någon matris fungerar indexet som avsett. Om det kapslade fältet har en matris någonstans på sökvägen ignoreras det värdet i det unika indexet och unikheten bevaras inte för det värdet.
Ett unikt index på people.tom.age fungerar till exempel i det här fallet eftersom det inte finns någon matris på sökvägen:
{
"people": {
"tom": {
"age": "25"
},
"mark": {
"age": "30"
}
}
}
Men fungerar inte i det här fallet eftersom det finns en matris i sökvägen:
{
"people": {
"tom": [
{
"age": "25"
}
],
"mark": [
{
"age": "30"
}
]
}
}
Den här funktionen kan aktiveras för ditt databaskonto genom att aktivera funktionen "EnableUniqueCompoundNestedDocs".
TTL-index
Om du vill att dokument ska upphöra att gälla i en samling skapar du ett TTL-index (time-to-live). Ett TTL-index är ett index i fältet _ts med ett expireAfterSeconds värde.
Exempel:
db.coll.createIndex({"_ts":1}, {expireAfterSeconds: 10})
Föregående kommando tar bort alla dokument i db.coll samlingen som ändrades för mer än 10 sekunder sedan.
Kommentar
Fältet _ts är specifikt för Azure Cosmos DB och är inte tillgängligt från MongoDB-klienter. Det är en reserverad egenskap (system) som innehåller tidsstämpeln för dokumentets senaste ändring.
Spåra indexstatus
Version 3.6+ av Azure Cosmos DB for MongoDB stöder currentOp() kommandot för att spåra indexförloppet på en databasinstans. Det här kommandot returnerar ett dokument med information om pågående åtgärder på en databasinstans.
currentOp Använd kommandot för att spåra alla pågående åtgärder i den interna MongoDB. I Azure Cosmos DB for MongoDB spårar det här kommandot endast indexåtgärden.
Här följer några exempel på hur du använder currentOp kommandot för att spåra indexets förlopp:
Hämta indexstatus för en samling:
db.currentOp({"command.createIndexes": <collectionName>, "command.$db": <databaseName>})Hämta indexstatus för alla samlingar i en databas:
db.currentOp({"command.$db": <databaseName>})Hämta indexstatus för alla databaser och samlingar i ett Azure Cosmos DB-konto:
db.currentOp({"command.createIndexes": { $exists : true } })
Exempel på index förloppsutdata
Information om indexets förlopp visar procentandelen för förloppet för den aktuella indexåtgärden. Här är exempel på utdatadokumentformatet för olika steg i indexets förlopp:
En indexåtgärd i en "foo"-samling och en "bar"-databas som är 60 procent färdig har följande utdatadokument. Fältet
Inprog[0].progress.totalvisar 100 som målslutprocent.{ "inprog": [ { ... "command": { "createIndexes": foo "indexes": [], "$db": bar }, "msg": "Index Build (background) Index Build (background): 60 %", "progress": { "done": 60, "total": 100 }, ... } ], "ok": 1 }Om en indexåtgärd precis har startats i en "foo"-samling och en "bar"-databas kan utdatadokumentet visa 0 procents förlopp tills den når en mätbar nivå.
{ "inprog": [ { ... "command": { "createIndexes": foo "indexes": [], "$db": bar }, "msg": "Index Build (background) Index Build (background): 0 %", "progress": { "done": 0, "total": 100 }, ... } ], "ok": 1 }När indexåtgärden är klar visar utdatadokumentet tomma
inprogåtgärder.{ "inprog" : [], "ok" : 1 }
Uppdateringar av bakgrundsindex
Indexuppdateringar körs alltid i bakgrunden, oavsett vilket värde du anger för egenskapen Background-index . Eftersom indexuppdateringar använder enheter för programbegäran (RU: er) med lägre prioritet än andra databasåtgärder orsakar indexändringar inte avbrottstid för skrivningar, uppdateringar eller borttagningar.
Att lägga till ett nytt index påverkar inte lästillgängligheten. Frågor använder endast nya index när indextransformeringen har slutförts. Under omvandlingen fortsätter frågemotorn att använda befintliga index, så du ser liknande läsprestanda som innan du startar indexeringsändringen. Att lägga till nya index riskerar inte ofullständiga eller inkonsekventa frågeresultat.
Om du tar bort index och omedelbart kör frågor som filtrerar på de borttagna indexen kan resultaten vara inkonsekventa och ofullständiga tills indextransformeringen är klar. Frågemotorn ger inte konsekventa eller fullständiga resultat för frågor som filtrerar på nyligen borttagna index. De flesta utvecklare släpper inte index och frågar dem sedan omedelbart, så den här situationen är osannolik.
Kommentar
Du kan spåra index förloppet.
reIndex kommando`
Kommandot reIndex återskapar alla index i en samling. I sällsynta fall kan körning av reIndex kommandot åtgärda frågeprestanda eller andra indexproblem i samlingen. Om du har problem med indexering kan du försöka återskapa indexen reIndex med kommandot .
reIndex Kör kommandot med följande syntax:
db.runCommand({ reIndex: <collection> })
Använd följande syntax för att kontrollera om körningen av reIndex kommandot förbättrar frågeprestandan i samlingen:
db.runCommand({"customAction":"GetCollection",collection:<collection>, showIndexes:true})
Exempel på utdata:
{
"database": "myDB",
"collection": "myCollection",
"provisionedThroughput": 400,
"indexes": [
{
"v": 1,
"key": {
"_id": 1
},
"name": "_id_",
"ns": "myDB.myCollection",
"requiresReIndex": true
},
{
"v": 1,
"key": {
"b.$**": 1
},
"name": "b.$**_1",
"ns": "myDB.myCollection",
"requiresReIndex": true
}
],
"ok": 1
}
Om reIndex förbättrar frågeprestandan är requiresReIndex sant. Om reIndex inte förbättrar frågeprestanda utelämnas den här egenskapen.
Migrera samlingar med index
Du kan bara skapa unika index när samlingen inte har några dokument. Populära MongoDB-migreringsverktyg försöker skapa unika index när data har importerats. Du kan undvika det här problemet genom att manuellt skapa motsvarande samlingar och unika index i stället för att låta migreringsverktyget försöka. Du får det här beteendet genom mongorestore att använda --noIndexRestore flaggan på kommandoraden.
Indexering för MongoDB version 3.2
Indexeringsfunktioner och standardvärden skiljer sig åt för Azure Cosmos DB-konton som använder version 3.2 av MongoDB-trådprotokollet. Kontrollera ditt kontos version på feature-support-36.md#protocol-support och uppgradera till version 3.6 på upgrade-version.md.
Om du använder version 3.2 visar det här avsnittet viktiga skillnader från version 3.6 och senare.
Ta bort standardindex (version 3.2)
Till skillnad från version 3.6 och senare indexerar Azure Cosmos DB för MongoDB version 3.2 varje egenskap som standard. Använd följande kommando för att släppa dessa standardindex för en samling (coll):
db.coll.dropIndexes()
{ "_t" : "DropIndexesResponse", "ok" : 1, "nIndexesWas" : 3 }
När du har lagt ned standardindexen lägger du till fler index som du gör i version 3.6 och senare.
Sammansatta index (version 3.2)
Sammansatta index refererar till flera fält i ett dokument. Om du vill skapa ett sammansatt index uppgraderar du till version 3.6 eller 4.0 på upgrade-version.md.
Jokerteckenindex (version 3.2)
Om du vill skapa ett jokerteckenindex uppgraderar du till version 4.0 eller 3.6 vid upgrade-version.md.
Nästa steg
- Indexering i Azure Cosmos DB
- Utgå data i Azure Cosmos DB automatiskt med time to live