Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
Den här funktionen är för närvarande i förhandsversion och tillhandahålls utan ett serviceavtal. För närvarande rekommenderas inte förhandsversioner för användning i produktion. Vissa funktioner i den här förhandsversionen stöds inte eller kan ha kapacitetsbegränsningar. Mer information finns i kompletterande användningsvillkor för Förhandsversioner av Microsoft Azure.
I den här guiden aktiverar du Azure Cosmos DB fleet analytics för din Microsoft Fabric-arbetsyta.
I den här guiden aktiverar du Azure Cosmos DB-flottanalys för ditt Azure Data Lake Storage-konto.
Förutsättningar
En befintlig Azure Cosmos DB-flotta
Om du inte har en befintlig flotta skapar du en ny flotta.
Fleet Analytics stöder endast Azure Cosmos DB för NoSQL-konton som har konfigurerats med flottan.
En befintlig Microsoft Fabric-arbetsyta
Arbetsytan måste använda OneLake som standardlagringsplats.
Arbetsytan ska stödjas av en licensierad eller utvärderings-Fabric-kapacitet.
Ett befintligt Azure Storage-konto som är kompatibelt med Azure Data Lake Storage (Gen2)
- Den hierarkiska namnområdesfunktionen måste vara aktiverad när kontot skapas.
Aktivera analys av flottan
Konfigurera först de resurser som krävs för fleet analytics.
Logga in på Azure-portalen (https://portal.azure.com).
Gå till den befintliga Azure Cosmos DB-flottan.
På sidan för flottan väljer du Fleet Analytics i avsnittet Övervakning på resursmenyn.
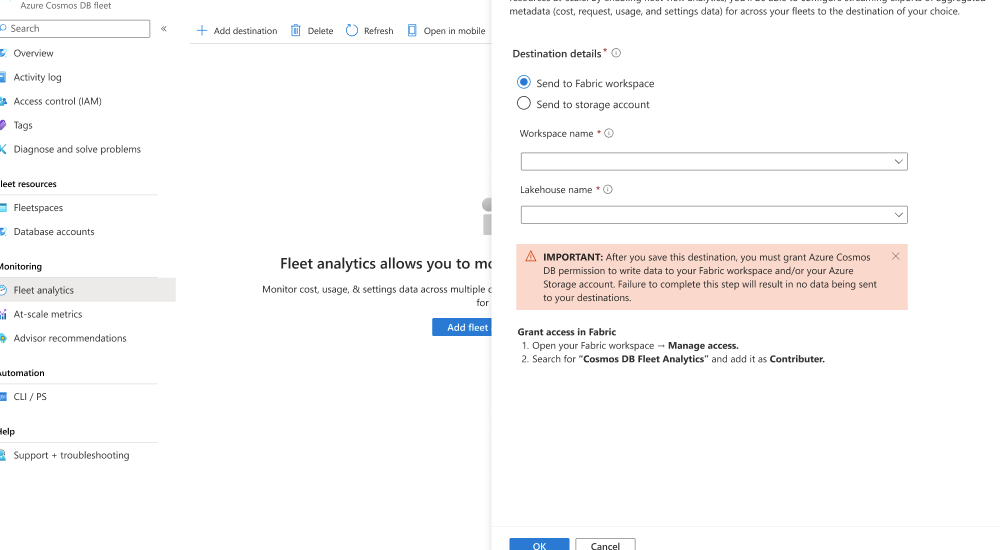
Välj sedan Lägg till mål.
I dialogrutan Fleet Analytics väljer du Skicka till Fabric-arbetsyta. Välj sedan din befintliga Fabric-arbetsyta, välj ett befintligt OneLake-lakehouse och spara destinationen.
Gå till din Fabric-arbetsyta i Microsoft Fabric-portalen.
I avsnittet Hantera på din arbetsyta lägger du till tjänstehuvudprincipen för fleet analytics till rollen Deltagare genom att söka efter den delade Cosmos DB Fleet Analytics tjänstehuvudprincipen.
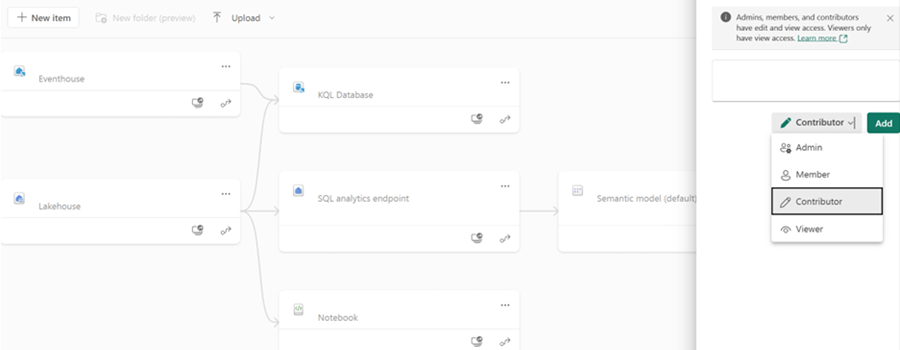
Viktigt!
Om du inte slutför det här steget kommer data inte att skrivas till din Fabric-målarbetsyta.
Spara dina ändringar.
Logga in på Azure-portalen (https://portal.azure.com).
Gå till den befintliga Azure Cosmos DB-flottan.
På sidan för flottan väljer du Fleet Analytics i avsnittet Övervakning på resursmenyn.
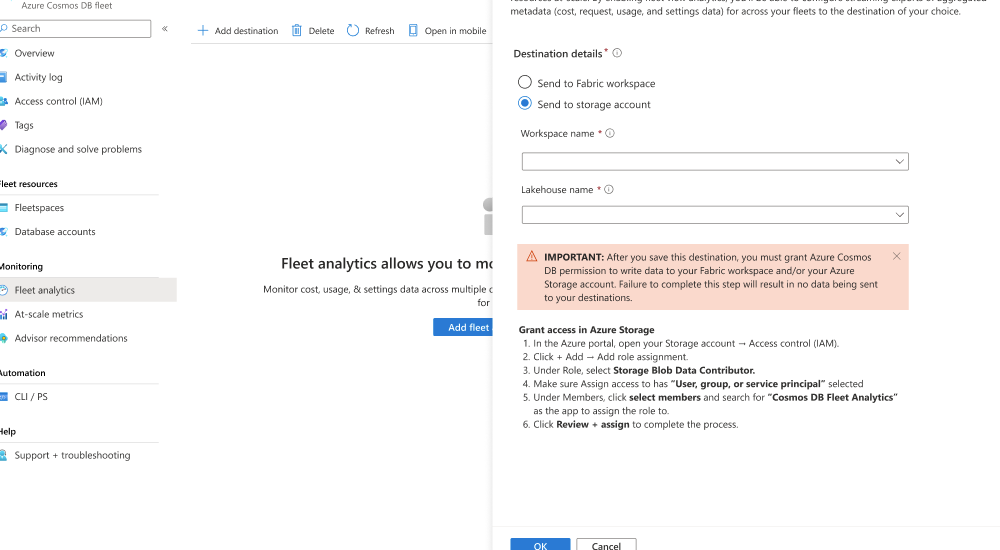
Välj sedan Lägg till mål.
I dialogrutan Fleet Analytics väljer du Skicka till lagringskonto. Välj sedan ditt befintliga Azure Storage-konto, välj en befintlig container och spara sedan målet.
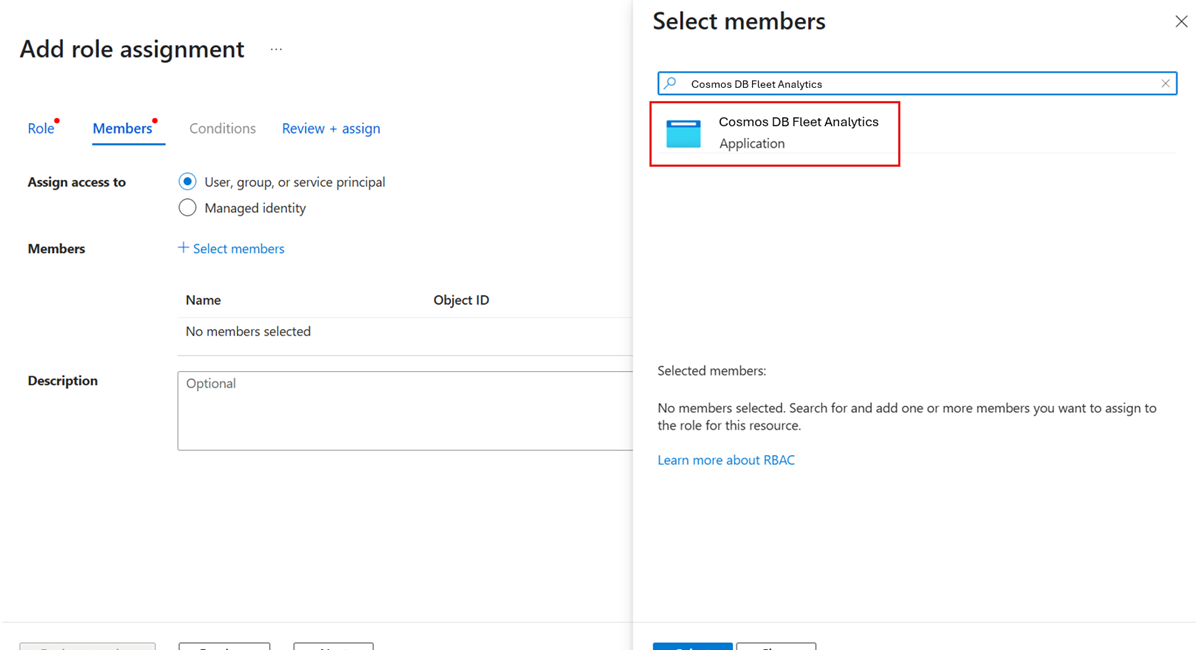
Gå till ditt Azure Storage-konto. Gå sedan till sidan Åtkomstkontroll (IAM).
Välj menyalternativet Lägg till rolltilldelning .
På sidan Lägg till rolltilldelning väljer du rollen Storage Blob-deltagare för att bevilja behörighet att bidra med blobar till det befintliga kontot.
Använd nu alternativet + Välj medlemmar . I dialogrutan söker du efter och väljer tjänstens huvudnamn för den delade Cosmos DB Fleet Analytics-tjänsten .
Viktigt!
Om du inte slutför det här steget kommer data inte att skrivas till ditt Azure Storage-målkonto.
Granska och tilldela din roll.
Fråga efter och visualisera data
I en star-schemadesign kräver hämtning av detaljerad information vanligtvis att faktatabeller kopplas till deras relaterade dimensionstabeller enligt bästa praxis. Det här avsnittet går igenom stegen för att fråga och visualisera data med hjälp av Microsoft Fabric.
Öppna arbetsytan Infrastruktur.
Gå till din befintliga OneLake-resurs.
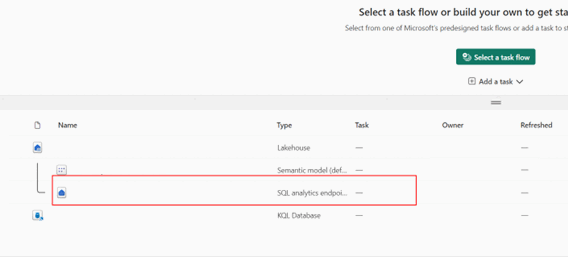
I SQL-slutpunktsutforskaren väljer du valfri tabell och kör en
SELECT TOP 100fråga för att snabbt observera data. Den här frågan finns på snabbmenyn.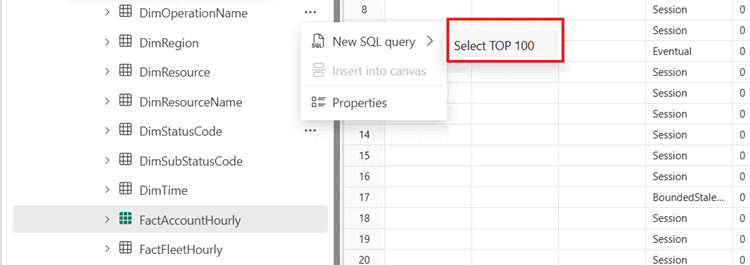
Tips/Råd
Du kan också köra följande fråga för att visa information på kontonivå:
SELECT TOP (100) [Timestamp], [ResourceId], [FleetId], [DefaultConsistencyLevel], [IsSynapseLinkEnabled], [IsFreeTierEnabled], [IsBurstEnabled], [BackupMode], [BackupStrategy], [BackupRedundancy], [BackupIntervalInMinutes], [BackupRetentionIntervalInHours], [TotalRUPerSecLimit], [APISettings], [AccountKeySettings], [LastDateAnyAccountKeyRotated] FROM [FactAccountHourly]Observera resultatet av frågan. Observera att du bara har en referens till fältet
ResourceId. Med bara resultatet av den här frågan kan du inte fastställa den exakta databasen eller containern för enskilda rader.Kör den här exempelfrågan som ansluter till både tabellerna
DimResourceochFactRequestHourlyför att hitta de 100 mest aktiva kontona efter transaktioner.SELECT TOP 100 DR.[SubscriptionId], DR.[AccountName], DR.[ResourceGroup], SUM(FRH.[TotalRequestCount]) AS sum_total_requests FROM [FactRequestHourly] FRH JOIN [DimResource] DR ON FRH.[ResourceId] = DR.[ResourceId] WHERE FRH.[Timestamp] >= DATEADD(DAY, -7, GETDATE()) -- Filter for the last 7 days AND ResourceName IN ('Document', 'StoredProcedure') -- Filter for Dataplane Operations GROUP BY DR.[AccountName], DR.[SubscriptionId], DR.[ResourceGroup] ORDER BY sum_total_requests DESC; -- Order by total requests in descending orderKör den här frågan för att hitta de 100 största kontona efter lagring.
SELECT TOP 100 DR.[SubscriptionId], DR.[AccountName], MAX(FRH.[MaxDataStorageInKB] / (1024.0 * 1024.0)) AS DataUsageInGB, MAX(FRH.[MaxIndexStorageInKB] / (1024.0 * 1024.0)) AS IndexUsageInGB, MAX( FRH.[MaxDataStorageInKB] / (1024.0 * 1024.0) + FRH.[MaxIndexStorageInKB] / (1024.0 * 1024.0) ) AS StorageInGB FROM [FactResourceUsageHourly] FRH JOIN [DimResource] DR ON FRH.[ResourceId] = DR.[ResourceId] WHERE FRH.[Timestamp] >= DATEADD(DAY, -1, GETDATE()) -- Filter for the last 1 day GROUP BY DR.[AccountName], DR.[SubscriptionId] ORDER BY StorageInGB DESC; -- Order by total storage usageSkapa nu en vy över data genom att öppna snabbmenyn och välja Spara som-vy. Ge vyn ett unikt namn och välj sedan Ok.
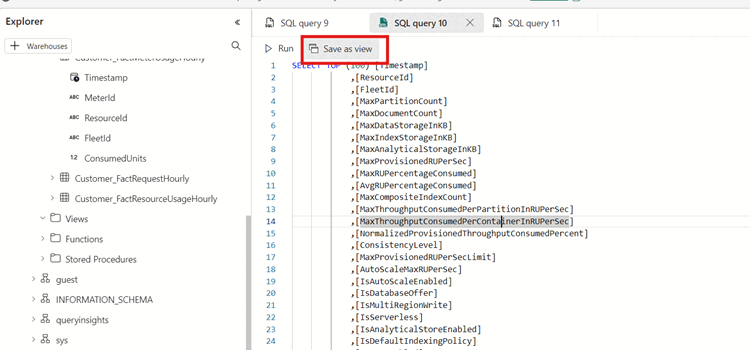
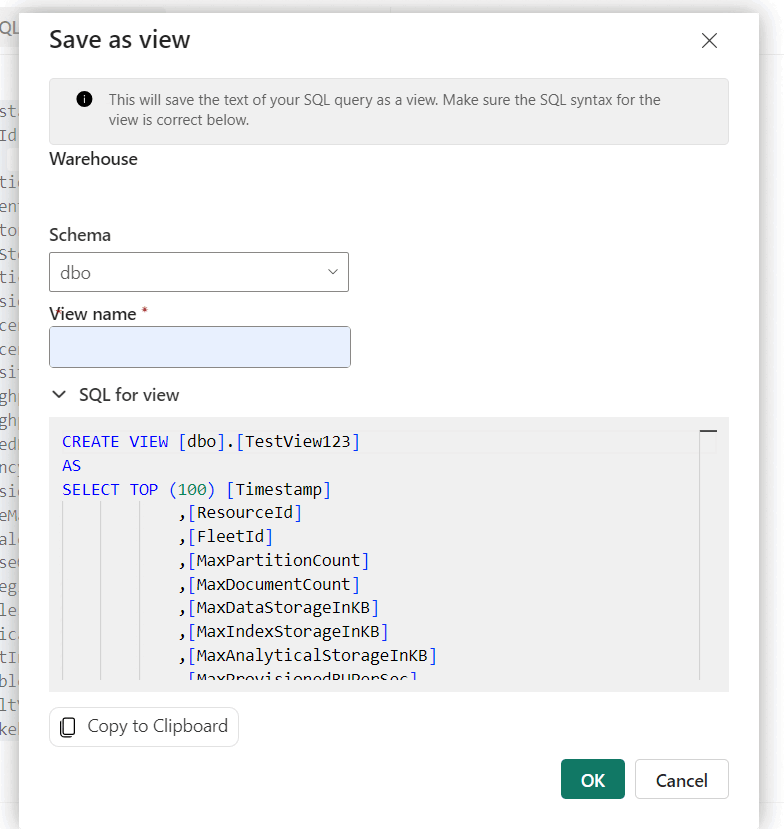
Tips/Råd
Du kan också skapa en vy direkt med den här frågan:
CREATE VIEW [MostActiveCustomers] AS SELECT a.ResourceId AS UsageResourceId, a.Timestamp, a.MeterId, a.FleetId, a.ConsumedUnits, b.ResourceId AS ResourceDetailId FROM FactMeterUsageHourly a INNER JOIN DimResource b ON a.ResourceId = b.ResourceIdNavigera till den nyligen skapade vyn i mappen Vyer för slutpunkten.
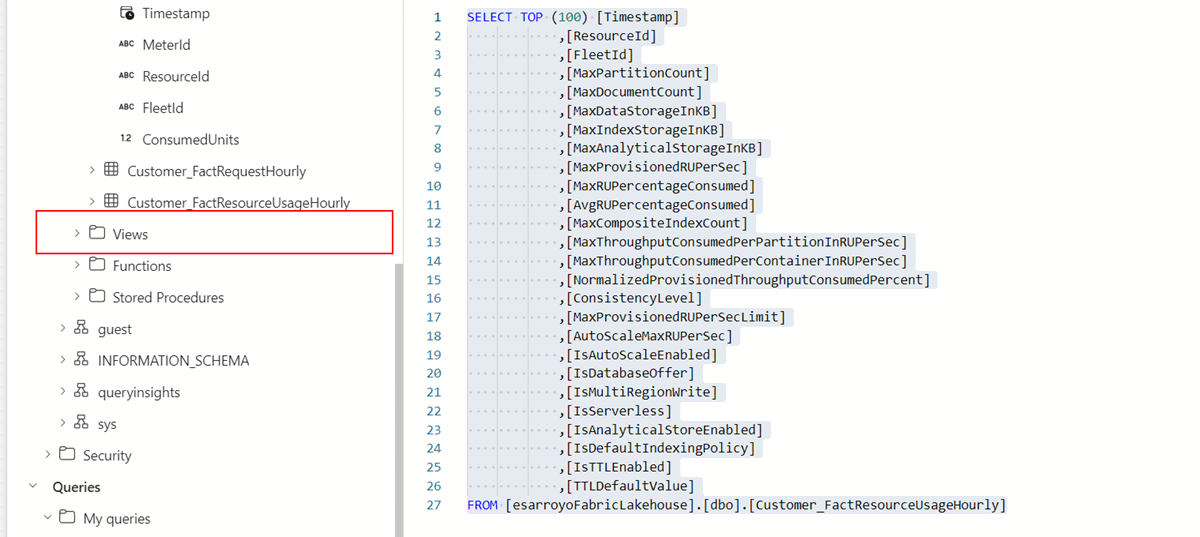
Gå till den vy som du nyligen skapade (eller en fråga) och välj sedan Explorer för dessa data (förhandsversion) och välj sedan Visualisera resultat.
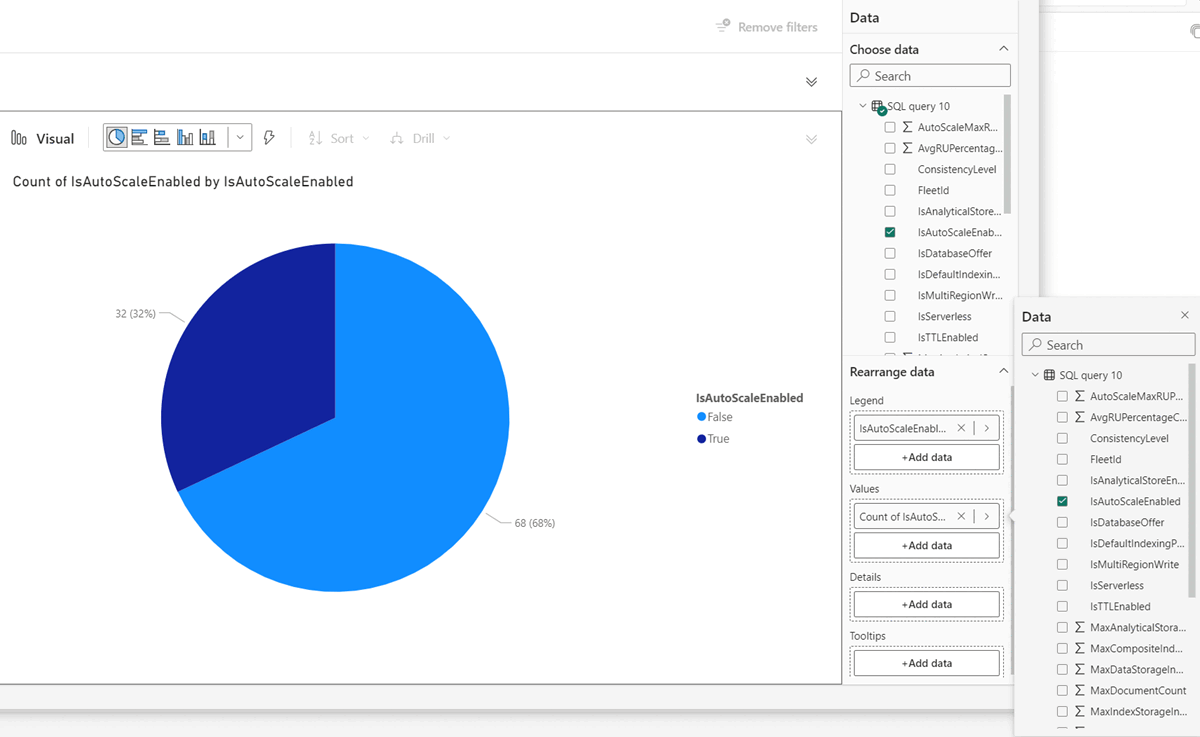
På Power BI-landningssidan skapar du relevanta visuella objekt för ditt scenario. Du kan till exempel visa procentandelen av din Azure Cosmos DB-arbetsbelastning med funktionen autoskalning aktiverad.
Det här avsnittet går igenom stegen för att skapa och köra frågor mot en tabell eller DataFrame som lästs in från data som lagras i Azure Storage (ADLS) eller Azure Databricks. I det här avsnittet används en notebook-fil som är ansluten till Apache Spark med Python- och SQL-celler.
Definiera först konfigurationen av Azure Storage-kontot som är inriktad på
# Define storage configuration container_name = "<azure-storage-container-name>" account_name = "<azure-storage-account-name>" base_url = f"abfss://{container_name}@{account_name}.dfs.core.windows.net" source_path = f"{base_url}/FactResourceUsageHourly"Skapa data som en tabell. Ladda om och uppdatera data från en extern källa (Azure Storage – ADLS) genom att släppa och återskapa
fleet_datatabellen.table_name = "fleet_data" # Drop the table if it exists spark.sql(f"DROP TABLE IF EXISTS {table_name}") # Create the table spark.sql(f""" CREATE TABLE {table_name} USING delta LOCATION '{source_path}' """)Fråga efter och återge resultatet från
fleet_datatabellen.# Query and display the table df = spark.sql(f"SELECT * FROM {table_name}") display(df)Definiera den fullständiga listan över extra tabeller som ska skapas för bearbetning av analysdata för flottan.
# Table names and folder paths (assumed to match) tables = [ "DimResource", "DimMeter", "FactResourceUsageHourly", "FactAccountHourly", "FactRequestHourly", "FactMeterUsageHourly" ] # Drop and recreate each table for table in tables: spark.sql(f"DROP TABLE IF EXISTS {table}") spark.sql(f""" CREATE TABLE {table} USING delta LOCATION '{base_url}/{table}' """)Kör en fråga med någon av dessa tabeller. Den här frågan hittar till exempel dina 100 mest aktiva konton efter transaktioner.
SELECT DR.SubscriptionId, DR.AccountName, DR.ResourceGroup, SUM(FRH.TotalRequestCount) AS sum_total_requests FROM FactRequestHourly FRH JOIN DimResource DR ON FRH.ResourceId = DR.ResourceId WHERE FRH.Timestamp >= DATE_SUB(CURRENT_DATE(), 7) -- Filter for the last 7 days AND FRH.ResourceName IN ('Document', 'StoredProcedure') -- Filter for Dataplane Operations GROUP BY DR.AccountName, DR.SubscriptionId, DR.ResourceGroup ORDER BY sum_total_requests DESC LIMIT 100; -- Limit to top 100 resultsKör den här frågan för att hitta de 100 största kontona efter lagring.
SELECT DR.SubscriptionId, DR.AccountName, MAX(FRH.MaxDataStorageInKB / (1024.0 * 1024.0)) AS DataUsageInGB, MAX(FRH.MaxIndexStorageInKB / (1024.0 * 1024.0)) AS IndexUsageInGB, MAX( FRH.MaxDataStorageInKB / (1024.0 * 1024.0) + FRH.MaxIndexStorageInKB / (1024.0 * 1024.0) ) AS StorageInGB FROM FactResourceUsageHourly FRH JOIN DimResource DR ON FRH.ResourceId = DR.ResourceId WHERE FRH.Timestamp >= DATE_SUB(CURRENT_DATE(), 1) -- Filter for the last 1 day GROUP BY DR.AccountName, DR.SubscriptionId ORDER BY StorageInGB DESC LIMIT 100; -- Limit to top 100 results