Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Kassandra
Kassandra
![]() Gremlin
Gremlin
![]() Bord
Bord
Genom att erbjuda en etablerad dataflödesmodell erbjuder Azure Cosmos DB förutsägbara prestanda i valfri skala. Att reservera eller etablera dataflöde i förväg eliminerar den "bullriga granneffekten" på prestandan. Du anger exakt hur mycket dataflöde du behöver och Azure Cosmos DB garanterar det konfigurerade dataflödet som backas upp av serviceavtalet.
Du kan börja med ett minsta dataflöde på 400 RU/sek och skala upp till tiotals miljoner begäranden per sekund eller ännu mer. Varje begäran som du utfärdar mot din Azure Cosmos DB-container eller databas, till exempel en läsbegäran, skrivbegäran, frågebegäran, lagrade procedurer, har en motsvarande kostnad som dras av från ditt etablerade dataflöde. Om du etablerar 400 RU/s och utfärdar en fråga som kostar 40 RU:er kan du utfärda 10 sådana frågor per sekund. Alla förfrågningar utöver detta får hastighetsbegränsade och du bör försöka begäran igen. Om du använder klientdrivrutiner stöder de logiken för automatiska återförsök.
Du kan etablera dataflöden för databaser och containrar, och de olika strategierna kan ge besparingar beroende på scenariot.
Optimera genom att etablera dataflöde på olika nivåer
Om du etablerar dataflöde i en databas kan alla containrar, till exempel samlingar/tabeller/grafer i databasen dela dataflödet baserat på belastningen. Dataflödet som är reserverat på databasnivå delas ojämnt, beroende på arbetsbelastningen på en specifik uppsättning containrar.
Om du etablerar dataflöde på en container garanteras dataflödet för containern, som backas upp av serviceavtalet. Valet av en logisk partitionsnyckel är avgörande för jämn belastningsfördelning över alla logiska partitioner i en container. Mer information finns i artiklar om partitionering och horisontell skalning .
Följande är några riktlinjer för att besluta om en etablerad dataflödesstrategi:
Överväg att etablera dataflöde i en Azure Cosmos DB-databas (som innehåller en uppsättning containrar) om:
Du har några dussin Azure Cosmos DB-containrar och vill dela dataflöde över vissa eller alla av dem.
Du migrerar från en databas med en klientorganisation som är utformad för att köras på virtuella IaaS-värddatorer eller lokalt, till exempel NoSQL eller relationsdatabaser till Azure Cosmos DB. Och om du har många samlingar/tabeller/grafer och inte vill göra några ändringar i datamodellen. Observera att du kan behöva kompromettera vissa av fördelarna med Azure Cosmos DB om du inte uppdaterar datamodellen när du migrerar från en lokal databas. Vi rekommenderar att du alltid omvärderar din datamodell för att få ut mesta möjliga när det gäller prestanda och även för att optimera för kostnader.
Du vill absorbera oplanerade toppar i arbetsbelastningar på grund av pooldataflöde på databasnivå som utsätts för en oväntad topp i arbetsbelastningen.
I stället för att ange specifikt dataflöde för enskilda containrar bryr du dig om att få det aggregerade dataflödet över en uppsättning containrar i databasen.
Överväg att etablera dataflöde för en enskild container om:
Du har några Azure Cosmos DB-containrar. Eftersom Azure Cosmos DB är schemaoberoende kan en container innehålla objekt som har heterogena scheman och inte kräver att kunderna skapar flera containertyper, en för varje entitet. Det är alltid ett alternativ att överväga om gruppering av separata 10–20 containrar i en enda container är meningsfullt. Med ett minimum på 400 RU:er för containrar kan poolning av alla 10–20 containrar i en vara mer kostnadseffektiv.
Du vill styra dataflödet för en specifik container och få garanterat dataflöde på en viss container som backas upp av SLA.
Överväg en hybrid av ovanstående två strategier:
Som tidigare nämnts kan du med Azure Cosmos DB blanda och matcha ovanstående två strategier, så att du nu kan ha vissa containrar i Azure Cosmos DB-databasen, som kan dela dataflödet som etablerats på databasen samt vissa containrar i samma databas, som kan ha dedikerade mängder etablerat dataflöde.
Du kan använda ovanstående strategier för att komma fram till en hybridkonfiguration, där du har både databasnivåetablerade dataflöden med vissa containrar med dedikerat dataflöde.
Som du ser i följande tabell kan du, beroende på valet av API, etablera dataflöde med olika kornigheter.
| API (gränssnitt för programmering av applikationer) | Konfigurera för delat dataflöde | Konfigurera för dedikerat dataflöde |
|---|---|---|
| API för NoSQL | Databas | Behållare |
| API för Azure Cosmos DB för MongoDB | Databas | Samling |
| API för Cassandra | Nyckelutrymme | Register |
| API för Gremlin | Databaskonto | Diagram |
| API för tabell | Databaskonto | Register |
Genom att etablera dataflöde på olika nivåer kan du optimera dina kostnader baserat på arbetsbelastningens egenskaper. Som tidigare nämnts kan du programmatiskt och när som helst öka eller minska ditt etablerade dataflöde för antingen enskilda containrar eller kollektivt över en uppsättning containrar. Genom att elastiskt skala dataflödet när arbetsbelastningen ändras betalar du bara för det dataflöde som du har konfigurerat. Om din container eller en uppsättning containrar distribueras över flera regioner kommer dataflödet som du konfigurerar för containern eller en uppsättning containrar garanterat att göras tillgängligt i alla regioner.
Optimera genom att hastighetsbegränsa dina förfrågningar
För arbetsbelastningar som inte är känsliga för svarstid kan du etablera mindre dataflöde och låta programmet hantera hastighetsbegränsning när det faktiska dataflödet överskrider det etablerade dataflödet. Servern avslutar begäran i förebyggande syfte med RequestRateTooLarge (HTTP-statuskod 429) och returnerar x-ms-retry-after-ms huvudet som anger hur lång tid i millisekunder som användaren måste vänta innan begäran görs på nytt.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Prova logik igen i SDK:er
De inbyggda SDK:erna (.NET/.NET Core, Java, Node.js och Python) fångar implicit det här svaret, respekterar det serverdefinierade återförsöket efter huvudet och försöker begära igen. Såvida inte ditt konto används samtidigt av flera klienter kommer nästa återförsök att lyckas.
Om du har fler än en klient som kumulativt fungerar konsekvent över begärandefrekvensen kanske standardantalet för återförsök, som för närvarande är inställt på 9, inte räcker. I sådana fall genererar klienten en RequestRateTooLargeException med statuskod 429 till programmet. Standardantalet för återförsök kan ändras genom att ange RetryOptions på ConnectionPolicy-instansen. Som standard RequestRateTooLargeException returneras med statuskod 429 efter en kumulativ väntetid på 30 sekunder om begäran fortsätter att fungera över begärandefrekvensen. Detta inträffar även om det aktuella antalet återförsök är mindre än det maximala antalet återförsök, oavsett om det är standardvärdet 9 eller ett användardefinierat värde.
MaxRetryAttemptsOnThrottledRequests är inställt på 3, så i det här fallet, om en begärandeåtgärd begränsas genom att överskrida det reserverade dataflödet för containern, försöker begärandeåtgärden tre gånger innan undantaget skickas till programmet. MaxRetryWaitTimeInSeconds är inställt på 60, så i det här fallet om den kumulativa väntetiden för återförsök i sekunder sedan den första begäran överskrider 60 sekunder genereras undantaget.
ConnectionPolicy connectionPolicy = new ConnectionPolicy();
connectionPolicy.RetryOptions.MaxRetryAttemptsOnThrottledRequests = 3;
connectionPolicy.RetryOptions.MaxRetryWaitTimeInSeconds = 60;
Partitioneringsstrategi och kostnader för etablerat dataflöde
En bra partitioneringsstrategi är viktig för att optimera kostnaderna i Azure Cosmos DB. Se till att det inte finns någon snedställning av partitioner som exponeras via lagringsmått. Se till att det inte finns någon skev dataflöde för en partition som exponeras med dataflödesmått. Se till att det inte finns någon skevhet mot vissa partitionsnycklar. Dominerande nycklar i lagringen exponeras via mått, men nyckeln är beroende av ditt programåtkomstmönster. Det är bäst att tänka på rätt logisk partitionsnyckel. En bra partitionsnyckel förväntas ha följande egenskaper:
Välj en partitionsnyckel som sprider arbetsbelastningen jämnt över alla partitioner och jämnt över tid. Med andra ord bör du inte ha några nycklar till med majoriteten av data och vissa nycklar med mindre eller inga data.
Välj en partitionsnyckel som gör att åtkomstmönster kan fördelas jämnt över logiska partitioner. Arbetsbelastningen är någorlunda jämn över alla nycklar. Med andra ord bör majoriteten av arbetsbelastningen inte fokusera på några specifika nycklar.
Välj en partitionsnyckel som har ett stort antal värden.
Den grundläggande idén är att sprida data och aktiviteten i containern över uppsättningen logiska partitioner, så att resurser för datalagring och dataflöde kan distribueras över de logiska partitionerna. Kandidater för partitionsnycklar kan innehålla de egenskaper som ofta visas som ett filter i dina frågor. Frågor kan dirigeras effektivt genom att du tar med partitionsnyckeln i filterpredikatet. Med en sådan partitioneringsstrategi är det mycket enklare att optimera etablerat dataflöde.
Utforma mindre objekt för högre dataflöde
Begärandeavgiften eller kostnaden för bearbetning av begäranden för en viss åtgärd är direkt korrelerad till objektets storlek. Åtgärder på stora objekt kostar mer än åtgärder på mindre objekt.
Dataåtkomstmönster
Det är alltid bra att logiskt dela upp dina data i logiska kategorier baserat på hur ofta du kommer åt data. Genom att kategorisera den som frekventa, medelstora eller kalla data kan du finjustera den förbrukade lagringen och det dataflöde som krävs. Beroende på åtkomstfrekvensen kan du placera data i separata containrar (till exempel tabeller, grafer och samlingar) och finjustera det etablerade dataflödet på dem så att de passar behoven för det datasegmentet.
Om du använder Azure Cosmos DB och vet att du inte kommer att söka efter vissa datavärden eller sällan kommer åt dem bör du dessutom lagra de komprimerade värdena för dessa attribut. Med den här metoden sparar du lagringsutrymme, indexutrymme och etablerat dataflöde och ger lägre kostnader.
Optimera genom att ändra indexeringsprincipen
Som standard indexerar Azure Cosmos DB automatiskt varje egenskap för varje post. Detta är avsett att underlätta utvecklingen och säkerställa utmärkta prestanda för många olika typer av ad hoc-frågor. Om du har stora poster med tusentals egenskaper kanske det inte är användbart att betala dataflödeskostnaden för indexering av varje egenskap, särskilt om du bara kör frågor mot 10 eller 20 av dessa egenskaper. När du närmar dig att få grepp om din specifika arbetsbelastning är vår vägledning att justera din indexprincip. Fullständig information om Azure Cosmos DB-indexeringsprincipen finns här.
Övervaka etablerat och förbrukat dataflöde
Du kan övervaka det totala antalet etablerade enheter för begäranden, antalet hastighetsbegränsade begäranden och antalet RU:er som du har förbrukat i Azure Portal. Mer information finns i Analysera Azure Cosmos DB-mått. Följande bild visar ett exempel på användningsstatistik:
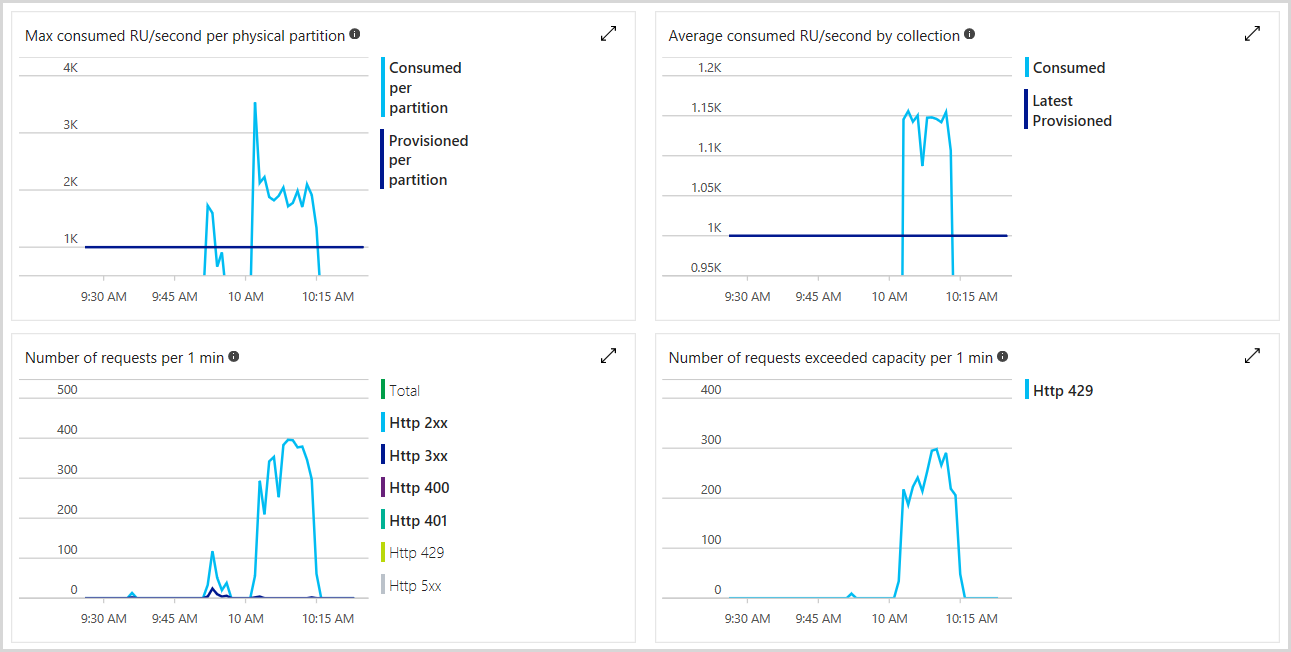
Du kan också ange aviseringar för att kontrollera om antalet hastighetsbegränsade begäranden överskrider ett visst tröskelvärde. Mer information om aviseringar finns i Azure Monitor-aviseringar.
Skala dataflödet elastiskt och på begäran
Eftersom du debiteras för det etablerade dataflödet kan det hjälpa dig att undvika avgifterna för det oanvända dataflödet genom att matcha det etablerade dataflödet efter dina behov. Du kan skala upp eller ned ditt etablerade dataflöde när som helst efter behov. Om dina dataflödesbehov är mycket förutsägbara kan du använda Azure Functions och använda en timerutlösare för att öka eller minska dataflödet enligt ett schema.
Övervakning av förbrukningen av ru:er och förhållandet mellan hastighetsbegränsade begäranden kan visa att du inte behöver behålla etableringen under hela konstanten under dagen eller veckan. Du kan få mindre trafik på natten eller under helgen. Genom att använda antingen Azure Portal eller Inbyggda SDK:er för Azure Cosmos DB eller REST API kan du skala ditt etablerade dataflöde när som helst. Azure Cosmos DB:s REST-API tillhandahåller slutpunkter för att programmatiskt uppdatera prestandanivån för dina containrar, vilket gör det enkelt att justera dataflödet från koden beroende på tidpunkten på dagen eller veckodagen. Åtgärden utförs utan avbrott och börjar vanligtvis gälla på mindre än en minut.
Ett av de områden som du bör skala dataflödet är när du matar in data i Azure Cosmos DB, till exempel under datamigrering. När du har slutfört migreringen kan du skala ned etablerat dataflöde för att hantera lösningens stadiga tillstånd.
Kom ihåg att faktureringen ligger på en timmes kornighet, så du sparar inga pengar om du ändrar ditt etablerade dataflöde oftare än en timme i taget.
Fastställa det dataflöde som behövs för en ny arbetsbelastning
Om du vill fastställa det etablerade dataflödet för en ny arbetsbelastning kan du använda följande steg:
Utför en inledande, grov utvärdering med hjälp av kapacitetshanteraren och justera dina uppskattningar med hjälp av Azure Cosmos DB Explorer i Azure Portal.
Vi rekommenderar att du skapar containrar med högre dataflöde än förväntat och sedan skalar ned efter behov.
Vi rekommenderar att du använder en av de interna Azure Cosmos DB-SDK:erna för att dra nytta av automatiska återförsök när begäranden blir hastighetsbegränsade. Om du arbetar på en plattform som inte stöds och använder Rest-API:et
x-ms-retry-after-msför Azure Cosmos DB implementerar du en egen återförsöksprincip med hjälp av huvudet.Kontrollera att programkoden har stöd för ärendet när alla återförsök misslyckas.
Du kan konfigurera aviseringar från Azure Portal för att få meddelanden om hastighetsbegränsning. Du kan börja med konservativa gränser som 10 hastighetsbegränsade begäranden under de senaste 15 minuterna och växla till mer ivriga regler när du har listat ut din faktiska förbrukning. Tillfälliga hastighetsgränser är bra, de visar att du spelar med de gränser du har angett och det är precis vad du vill göra.
Använd övervakning för att förstå ditt trafikmönster, så att du kan överväga behovet av att dynamiskt justera dataflödesetablering under dagen eller en vecka.
Övervaka förhållandet mellan etablerat och förbrukat dataflöde regelbundet för att se till att du inte har etablerat fler än nödvändigt antal containrar och databaser. Att ha lite över etablerat dataflöde är en bra säkerhetskontroll.
Metodtips för att optimera etablerat dataflöde
Följande steg hjälper dig att göra dina lösningar mycket skalbara och kostnadseffektiva när du använder Azure Cosmos DB.
Om du har betydligt över etablerat dataflöde mellan containrar och databaser bör du granska RU:er som etablerats jämfört med förbrukade RU:er och finjustera arbetsbelastningarna.
En metod för att beräkna mängden reserverat dataflöde som krävs av ditt program är att registrera ru-avgiften för begärandeenheten som är associerad med att köra typiska åtgärder mot en representativ Azure Cosmos DB-container eller databas som används av ditt program och sedan beräkna antalet åtgärder som du förväntar dig att utföra varje sekund. Se till att mäta och inkludera vanliga frågor och deras användning också. Information om hur du beräknar RU-kostnader för frågor programmatiskt eller med hjälp av portalen finns i Optimera kostnaden för frågor.
Ett annat sätt att få åtgärder och deras kostnader i RU:er är genom att aktivera Azure Monitor-loggar, vilket ger dig en uppdelning av åtgärden/varaktigheten och begärandeavgiften. Azure Cosmos DB tillhandahåller en begärandeavgift för varje åtgärd, så att varje åtgärdsavgift kan lagras tillbaka från svaret och sedan användas för analys.
Du kan skala upp och ned etablerat dataflöde elastiskt eftersom du behöver för att tillgodose dina arbetsbelastningsbehov.
Du kan lägga till och ta bort regioner som är associerade med ditt Azure Cosmos DB-konto när du behöver och kontrollera kostnaderna.
Kontrollera att du har en jämn fördelning av data och arbetsbelastningar mellan logiska partitioner av dina containrar. Om du har en ojämn partitionsdistribution kan det leda till högre dataflöde än det värde som behövs. Om du upptäcker att du har en skev distribution rekommenderar vi att du omdistribuerar arbetsbelastningen jämnt över partitionerna eller partitionerar om data.
Om du har många containrar och dessa containrar inte kräver serviceavtal kan du använda det databasbaserade erbjudandet för de fall där serviceavtalen för dataflöde per container inte gäller. Du bör identifiera vilka av de Azure Cosmos DB-containrar som du vill migrera till dataflödeserbjudandet på databasnivå och sedan migrera dem med hjälp av en ändringsflödesbaserad lösning.
Överväg att använda den kostnadsfria Azure Cosmos DB-nivån (kostnadsfri i ett år), Prova Azure Cosmos DB (upp till tre regioner) eller nedladdningsbar Azure Cosmos DB-emulator för utvecklings-/testscenarier. Genom att använda dessa alternativ för test-dev kan du avsevärt sänka dina kostnader.
Du kan utföra ytterligare arbetsbelastningsspecifika kostnadsoptimeringar – till exempel öka batchstorleken, belastningsutjämningsläsningar i flera regioner och deduplicera data, om tillämpligt.
Med reserverad Azure Cosmos DB-kapacitet kan du få betydande rabatter för upp till 65 % i tre år. Den reserverade kapacitetsmodellen för Azure Cosmos DB är ett förskottsåtagande för enheter för begäranden som behövs över tid. Rabatterna är nivåindelade så att ju fler enheter för begärande du använder under en längre period, desto mer blir rabatten. Dessa rabatter tillämpas omedelbart. Alla RU:er som används ovanför dina etablerade värden debiteras baserat på kostnaden för icke-reserverad kapacitet. Mer information finns i Reserverad kapacitet för Azure Cosmos DB. Överväg att köpa reserverad kapacitet för att ytterligare sänka dina etablerade dataflödeskostnader.
Nästa steg
Härnäst kan du fortsätta med att lära dig mer om kostnadsoptimering i Azure Cosmos DB med följande artiklar:
- Försöker du planera kapacitet för en migrering till Azure Cosmos DB? Du kan använda information om ditt befintliga databaskluster för kapacitetsplanering.
- Om allt du vet är antalet virtuella kärnor och servrar i ditt befintliga databaskluster läser du om att uppskatta enheter för begäranden med virtuella kärnor eller virtuella kärnor
- Om du känner till vanliga begärandefrekvenser för din aktuella databasarbetsbelastning kan du läsa om att uppskatta enheter för begäranden med azure Cosmos DB-kapacitetshanteraren
- Läs mer om att optimera för utveckling och testning
- Läs mer om att förstå din Azure Cosmos DB-faktura
- Läs mer om att optimera lagringskostnaden
- Läs mer om hur du optimerar kostnaden för läsningar och skrivningar
- Läs mer om att optimera kostnaden för frågor
- Läs mer om att optimera kostnaden för Azure Cosmos DB-konton i flera regioner