Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
Azure Cosmos DB for PostgreSQL stöds inte längre för nya projekt. Använd inte den här tjänsten för nya projekt. Använd i stället en av dessa två tjänster:
Använd Azure Cosmos DB för NoSQL för en distribuerad databaslösning som är utformad för storskaliga scenarier med ett serviceavtal på 99,999% tillgänglighet , omedelbar autoskalning och automatisk redundans i flera regioner.
Använd funktionen Elastiska kluster i Azure Database For PostgreSQL för fragmenterad PostgreSQL med citus-tillägget med öppen källkod.
Samlokalisering innebär att relaterad information lagras på samma noder. Frågor kan gå snabbt när alla nödvändiga data är tillgängliga utan nätverkstrafik. Genom att samlokalisera relaterade data på olika noder kan frågor köras effektivt parallellt på varje nod.
Datasamlokalisering för hash-distribuerade tabeller
I Azure Cosmos DB för PostgreSQL lagras en rad i en shard om hashvärdet i distributionskolumnen hamnar inom shard-hashintervallet. Shards med samma hash-intervall placeras alltid på samma nod. Rader med lika fördelningskolumnvärden finns alltid på samma nod mellan tabeller. Begreppet hash-distribuerade tabeller kallas även radbaserad horisontell partitionering. I schemabaserad horisontell partitionering samallokeras tabeller i ett distribuerat schema alltid.
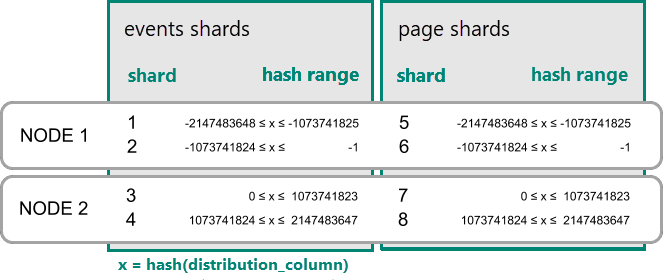
Ett praktiskt exempel på samlokalisering
Tänk på följande tabeller som kan ingå i en saaS för webbanalys med flera klientorganisationer:
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
Nu vill vi besvara förfrågningar som kan genereras av en kundgränssnittsinställning. Ett exempel på en fråga är "Ge antalet besök under den senaste veckan för alla sidor som börjar med '/blog' i hyresgäst sex."
Om våra data finns på en enda PostgreSQL-server kan vi enkelt uttrycka vår fråga med hjälp av den omfattande uppsättningen relationsåtgärder som erbjuds av SQL:
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Så länge arbetsuppsättningen för den här frågan passar i minnet är en tabell med en server en lämplig lösning. Nu ska vi överväga möjligheterna att skala datamodellen med Azure Cosmos DB for PostgreSQL.
Distribuera tabeller efter ID
Enserverfrågor börjar bli långsammare när antalet hyresgäster och den data som lagras för varje hyresgäst växer. Arbetsuppsättningen får inte längre plats i minnet och CPU:n blir flaskhalsen.
I det här fallet kan vi fragmentera data över många noder med hjälp av Azure Cosmos DB för PostgreSQL. Det första och viktigaste valet vi behöver göra när vi bestämmer oss för att fragmentera är distributionskolumnen. Låt oss börja med ett naivt val av att använda event_id för händelsetabellen och page_id för page tabellen:
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
När data sprids över olika arbetare kan vi inte utföra en koppling som vi skulle göra på en enda PostgreSQL-nod. I stället måste vi utfärda två frågor:
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
Därefter måste resultaten från de två stegen kombineras av programmet.
Att köra frågorna måste söka data i shards spridda över noder.
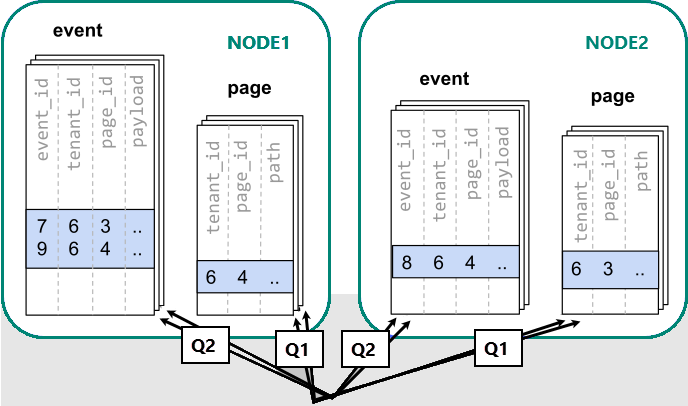
I det här fallet skapar datadistributionen betydande nackdelar:
- Kostnader från att fråga varje fragment och utföra flera förfrågningar.
- Omkostnader för Q1 som returnerar många rader till klienten.
- Q2 blir stort.
- Behovet av att skriva frågor i flera steg kräver ändringar i programmet.
Data sprids så att frågorna kan parallelliseras. Det är bara fördelaktigt om mängden arbete som frågan utför är betydligt större än omkostnaderna för att fråga många shards.
Distribuera tabeller efter klientorganisation
I Azure Cosmos DB för PostgreSQL garanteras rader med samma distributionskolumnvärde att finnas på samma nod. Från och med nu kan vi skapa våra tabeller med tenant_id som distributionskolumn.
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
Nu kan Azure Cosmos DB for PostgreSQL svara på den ursprungliga frågan med en enskild server utan ändring (Q1):
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
På grund av filtrering och sammanfogning på tenant-ID vet Azure Cosmos DB for PostgreSQL att frågeställningen helt kan besvaras genom att använda uppsättningen samlokaliserade shards som innehåller data för just den klientorganisationen. En enskild PostgreSQL-nod kan besvara frågan i ett enda steg.
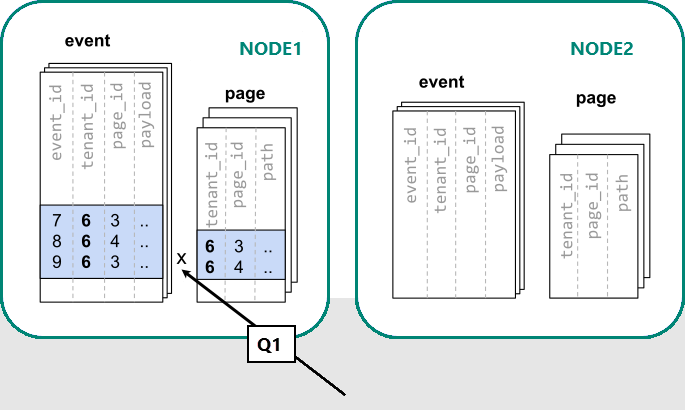
I vissa fall måste frågor och tabellscheman ändras för att inkludera klientorganisations-ID:t i unika begränsningar och kopplingsvillkor. Den här ändringen är vanligtvis enkel.
Nästa steg
- Se hur klientdata samplaceras i självstudien för flera klienter.