Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
Azure Cosmos DB for PostgreSQL stöds inte längre för nya projekt. Använd inte den här tjänsten för nya projekt. Använd i stället en av dessa två tjänster:
Använd Azure Cosmos DB för NoSQL för en distribuerad databaslösning som är utformad för storskaliga scenarier med ett serviceavtal på 99,999% tillgänglighet , omedelbar autoskalning och automatisk redundans i flera regioner.
Använd funktionen Elastiska kluster i Azure Database For PostgreSQL för fragmenterad PostgreSQL med citus-tillägget med öppen källkod.
Klientorganisations-ID som shardnyckel
Hyresgästs-ID:t är kolumnen vid arbetsbelastningens grund eller högst upp i hierarkin i din datamodell. I det här SaaS-e-handelsschemat skulle det till exempel vara butiks-ID:t:
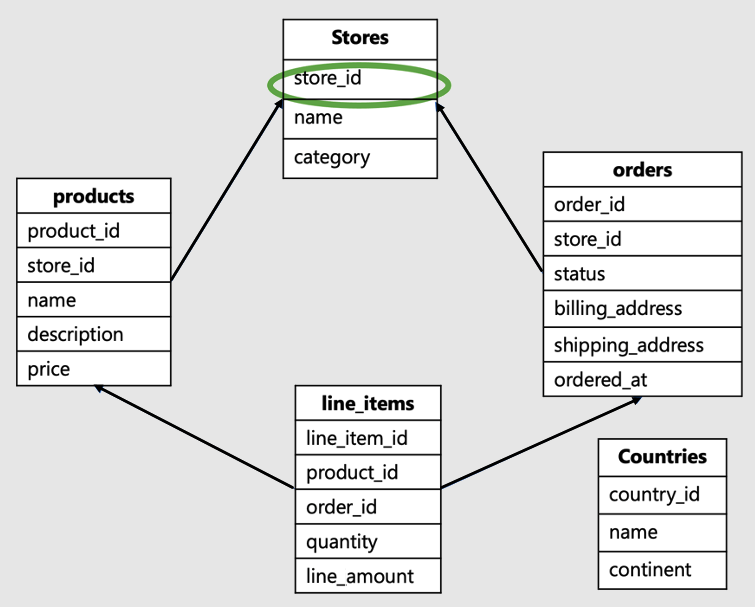
Den här datamodellen skulle vara typisk för ett företag som Shopify. Den är värd för webbplatser för flera onlinebutiker, där varje butik interagerar med sina egna data.
- Den här datamodellen har en massa tabeller: butiker, produkter, beställningar, radobjekt och länder.
- Tabellen "butiker" finns överst i hierarkin. Produkter, order och radobjekt är alla associerade med butiker, vilket är lägre i hierarkin.
- Tabellen länder är inte relaterad till enskilda butiker, den är bland alla butiker.
I det här exemplet store_id, som finns överst i hierarkin, är identifieraren för klientorganisationen. Det är den korrekta shardnyckeln. Genom att välja store_id som shardnyckel kan du samla in data i alla tabeller för ett enda lager på en enda arbetare.
Att samplacera tabeller efter butik har fördelar:
- Tillhandahåller SQL-täckning, till exempel sekundärnycklar, JOIN. Transaktioner för en enskild hyresgäst lokaliseras på en enda arbetsnod där varje hyresgäst finns.
- Uppnår ensiffriga millisekunders prestanda. Förfrågningar för en enskild hyresgäst dirigeras till en enda nod istället för att parallelliseras, vilket hjälper till att optimera nätverkshopp och samtidigt upprätthålla skalbarhet i beräkning och minne.
- Den skalar. När antalet hyresgäster växer kan du lägga till noder och balansera om hyresgästerna till nya noder, eller till och med isolera större hyresgäster till sina egna noder. Med hyresgästisolering kan du tillhandahålla dedikerade resurser.
Optimal datamodell för appar med flera klientorganisationer
I det här exemplet bör vi distribuera de butiksspecifika tabellerna efter butiks-ID och skapa countries en referenstabell.
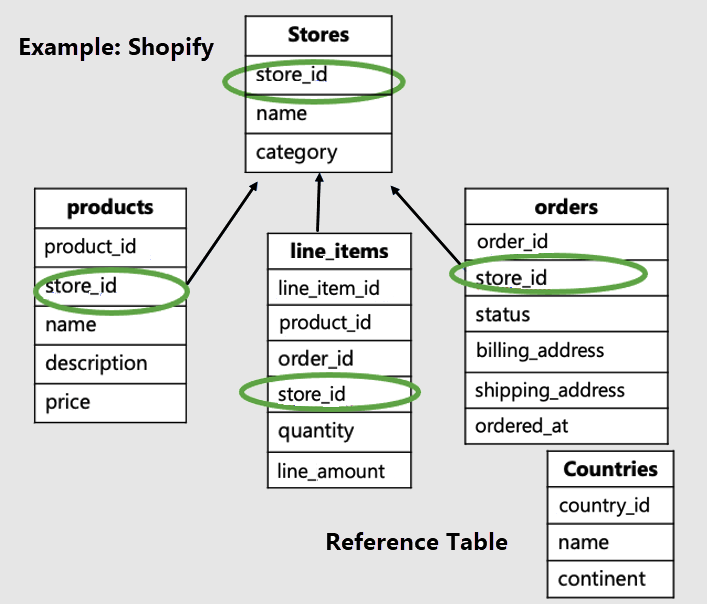
Observera att hyresgästspecifika tabeller har hyresgäst-ID och är distribuerade. I vårt exempel distribueras butiker, produkter och line_items. Resten av tabellerna är referenstabeller. I vårt exempel är tabellen länder en referenstabell.
-- Distribute large tables by the tenant ID
SELECT create_distributed_table('stores', 'store_id');
SELECT create_distributed_table('products', 'store_id', colocate_with => 'stores');
-- etc for the rest of the tenant tables...
-- Then, make "countries" a reference table, with a synchronized copy of the
-- table maintained on every worker node
SELECT create_reference_table('countries');
Alla stora tabeller bör ha klientorganisations-ID:t.
- Om du migrerar en befintlig app för flera klientorganisationer till Azure Cosmos DB för PostgreSQL kan du behöva avnormalisera lite och lägga till kolumnen klient-ID i stora tabeller om den saknas och sedan fylla på de saknade värdena i kolumnen.
- För nya appar i Azure Cosmos DB för PostgreSQL kontrollerar du att klientorganisations-ID:t finns i alla klientspecifika tabeller.
Se till att inkludera klientorganisations-ID på primära, unika och främmande nyckelbegränsningar i distribuerade tabeller i form av en sammansatt nyckel. Om en tabell till exempel har en primärnyckel på id, omvandlar du den till den sammansatta nyckeln (tenant_id,id).
Du behöver inte ändra nycklar för referenstabeller.
Frågeöverväganden för bästa prestanda
Distribuerade frågor som filtrerar på klientorganisations-ID:t körs mest effektivt i appar för flera klientorganisationer. Se till att dina frågor alltid är begränsade till en enda klientorganisation.
SELECT *
FROM orders
WHERE order_id = 123
AND store_id = 42; -- ← tenant ID filter
Det är nödvändigt att lägga till klient-ID-filtret även om de ursprungliga filtervillkoren entydigt identifierar de rader du vill ha. Klient-ID-filtret, även om det är till synes redundant, talar om för Azure Cosmos DB for PostgreSQL hur frågan dirigeras till en enda arbetsnod.
När du kopplar ihop två distribuerade tabeller, se på samma sätt till att båda tabellerna är begränsade till en enda klientorganisation. Avgränsning kan utföras genom att säkerställa att anslutningsvillkoren inkluderar hyresgäst-ID:t.
SELECT sum(l.quantity)
FROM line_items l
INNER JOIN products p
ON l.product_id = p.product_id
AND l.store_id = p.store_id -- ← tenant ID in join
WHERE p.name='Awesome Wool Pants'
AND l.store_id='8c69aa0d-3f13-4440-86ca-443566c1fc75';
-- ↑ tenant ID filter
Det finns hjälpbibliotek för flera populära programramverk som gör det enkelt att inkludera ett klient-ID i frågor. Här följer instruktioner:
Nästa steg
Nu har vi utforskat datamodellering för skalbara appar. Nästa steg är att ansluta och fråga databasen med valfritt programmeringsspråk.