Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
Azure Cosmos DB for PostgreSQL stöds inte längre för nya projekt. Använd inte den här tjänsten för nya projekt. Använd i stället en av dessa två tjänster:
Använd Azure Cosmos DB för NoSQL för en distribuerad databaslösning som är utformad för storskaliga scenarier med ett serviceavtal på 99,999% tillgänglighet , omedelbar autoskalning och automatisk redundans i flera regioner.
Använd funktionen Elastiska kluster i Azure Database For PostgreSQL för fragmenterad PostgreSQL med citus-tillägget med öppen källkod.
Samlokalisera stora tabeller med shardnyckel
Följ dessa riktlinjer om du vill välja shardnyckeln för ett driftanalysprogram i realtid:
- Välj en kolumn som är vanlig i stora tabeller
- Välj en kolumn som är en naturlig dimension i data eller en central del av programmet. Några exempel:
- I finansvärlden skulle ett program som analyserar säkerhetstrender förmodligen använda
security_id. - I ett användaranalysarbete där du vill analysera webbplatsanvändningsstatistik är
user_iden bra distributionskolumn.
- I finansvärlden skulle ett program som analyserar säkerhetstrender förmodligen använda
Genom att samlokalisera stora tabeller kan du skicka SQL-frågor till arbetsnoder parallellt. Genom att trycka ned frågor undviker du att blanda data mellan noder i nätverket. Åtgärder som JOIN:er, aggregeringar, summeringar, filter och begränsningar kan köras effektivt.
Om du vill visualisera parallella distribuerade frågor i samlokaliserade tabeller bör du överväga det här diagrammet:
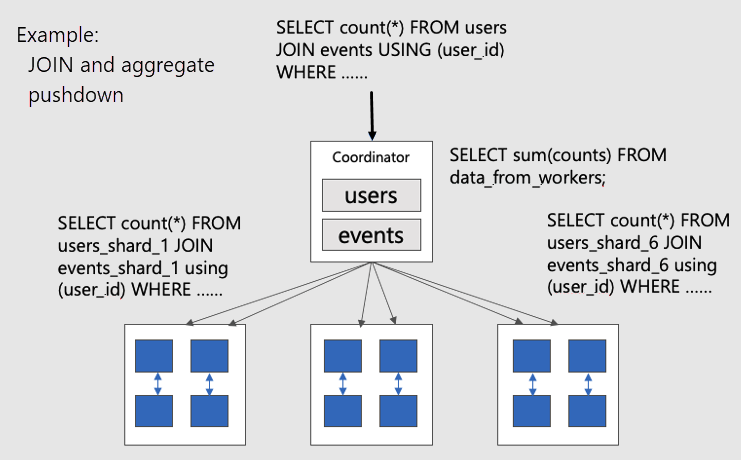
Tabellerna users och events är båda fragmenterade av user_id, så relaterade rader för samma användar-ID placeras tillsammans på samma arbetsnod. SQL JOINs kan genomföras utan att behöva utbyta information mellan arbetare.
Optimal datamodell för realtidsappar
Låt oss fortsätta med exemplet på ett program som analyserar besök och mått på användarwebbplatser. Det finns två "faktatabeller" – användare och händelser – och andra mindre "dimensionstabeller".
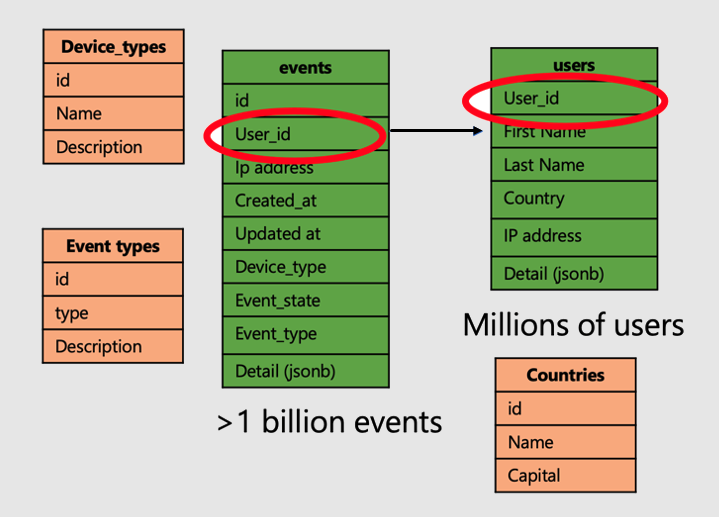
Följ följande steg för att tillämpa superkraften för distribuerade tabeller i Azure Cosmos DB for PostgreSQL:
- Distribuera stora faktatabeller i en gemensam kolumn. I vårt fall distribueras användare och händelser på
user_id. - Markera tabellerna small/dimension (
device_types,countriesoch 'event_types) som referenstabeller. - Se till att inkludera distributionskolumnen i primära, unika och sekundärnyckelbegränsningar i distribuerade tabeller. Att inkludera kolumnen kan kräva att nycklarna blir sammansatta. Det finns behov av att uppdatera nycklar för referenstabeller.
- När du ansluter till stora distribuerade tabeller måste du ansluta med hjälp av shardnyckeln.
-- Distribute the fact tables
SELECT create_distributed_table('users', 'user_id');
SELECT create_distributed_table('products', 'user_id', colocate_with => 'users');
-- Turn dimension tables into reference tables, with synchronized copies
-- maintained on every worker node
SELECT create_reference_table('countries');
-- similarly for device_types and event_types...
Nästa steg
Nu har vi utforskat datamodellering för skalbara appar. Nästa steg är att ansluta och fråga databasen med valfritt programmeringsspråk.