Diagnostisera och felsöka för stora undantag (429) för Azure Cosmos DB-begärandefrekvens
GÄLLER FÖR: ![]() NoSQL
NoSQL
Den här artikeln innehåller kända orsaker och lösningar för olika 429-statuskodsfel för API:et för NoSQL. Om du använder API:et för MongoDB kan du läsa artikeln Felsöka vanliga problem i API för MongoDB för att felsöka statuskod 16500.
Ett undantag för "Begärandefrekvensen är för stor", även kallat felkod 429, anger att dina begäranden mot Azure Cosmos DB är hastighetsbegränsade.
När du använder etablerat dataflöde anger du det dataflöde som mäts i enheter för programbegäran per sekund (RU/s) som krävs för din arbetsbelastning. Databasåtgärder mot tjänsten, till exempel läsningar, skrivningar och frågor, förbrukar ett visst antal enheter för programbegäran (RU:er). Läs mer om enheter för begäranden.
Om åtgärderna på en viss sekund förbrukar mer än de etablerade enheter för programbegäran returnerar Azure Cosmos DB ett 429-undantag. Varje sekund återställs antalet enheter för programbegäran som är tillgängliga att använda.
Innan du vidtar en åtgärd för att ändra RU:erna är det viktigt att förstå rotorsaken till hastighetsbegränsning och åtgärda det underliggande problemet.
Tips
Vägledningen i den här artikeln gäller databaser och containrar med hjälp av etablerat dataflöde – både autoskalning och manuellt dataflöde.
Det finns olika felmeddelanden som motsvarar olika typer av 429 undantag:
- Begärandefrekvensen är stor. Fler enheter för programbegäran kan behövas, så inga ändringar har gjorts.
- Begäran slutfördes inte på grund av en hög frekvens av metadatabegäranden.
- Begäran slutfördes inte på grund av ett tillfälligt tjänstfel.
Begärandefrekvensen är stor
Det här är det vanligaste scenariot. Det inträffar när de enheter för programbegäran som används av åtgärder på data överskrider det etablerade antalet RU/s. Om du använder manuellt dataflöde inträffar detta när du har förbrukat fler RU/s än det etablerade manuella dataflödet. Om du använder autoskalning inträffar detta när du har förbrukat mer än det maximala antalet RU:er som har etablerats. Om du till exempel har en resurs etablerad med ett manuellt dataflöde på 400 RU/s visas 429 när du använder mer än 400 enheter för begäran på en enda sekund. Om du har en resurs etablerad med max RU/s för autoskalning på 4 000 RU/s (skalar mellan 400 RU/s – 4 000 RU/s) visas 429 svar när du använder mer än 4 000 enheter för begäran på en enda sekund.
Tips
Alla åtgärder debiteras baserat på antalet resurser som de förbrukar. Dessa avgifter mäts i enheter för programbegäran. Dessa avgifter omfattar begäranden som inte slutförs korrekt på grund av programfel som 400, 412, 449osv. När du tittar på begränsning eller användning är det en bra idé att undersöka om något mönster har ändrats i din användning, vilket skulle leda till en ökning av dessa åtgärder. Mer specifikt söker du efter taggar 412 eller 449 (faktisk konflikt).
Mer information om etablerat dataflöde finns i etablerat dataflöde i Azure Cosmos DB.
Steg 1: Kontrollera måtten för att fastställa procentandelen begäranden med 429-fel
Att se 429 felmeddelanden betyder inte nödvändigtvis att det är problem med databasen eller containern. En liten procentandel av 429 svar är normalt oavsett om du använder manuellt dataflöde eller autoskalningsdataflöde och är ett tecken på att du maximerar de RU/er som du har etablerat.
Undersök så här
Ta reda på vilken procent av dina begäranden till databasen eller containern som resulterade i 429 svar, jämfört med det totala antalet lyckade begäranden. Från ditt Azure Cosmos DB-konto går du till Insights>Requests>Total Requests by Status Code (Totalt antal begäranden per statuskod). Filtrera till en specifik databas och container.
Som standard försöker Azure Cosmos DB-klient-SDK:er och dataimportverktyg som Azure Data Factory och massexekutorbibliotek automatiskt begäranden på 429-enheter. De försöker vanligtvis igen upp till nio gånger. Även om du kan se 429 svar i måtten kanske dessa fel inte ens har returnerats till ditt program.
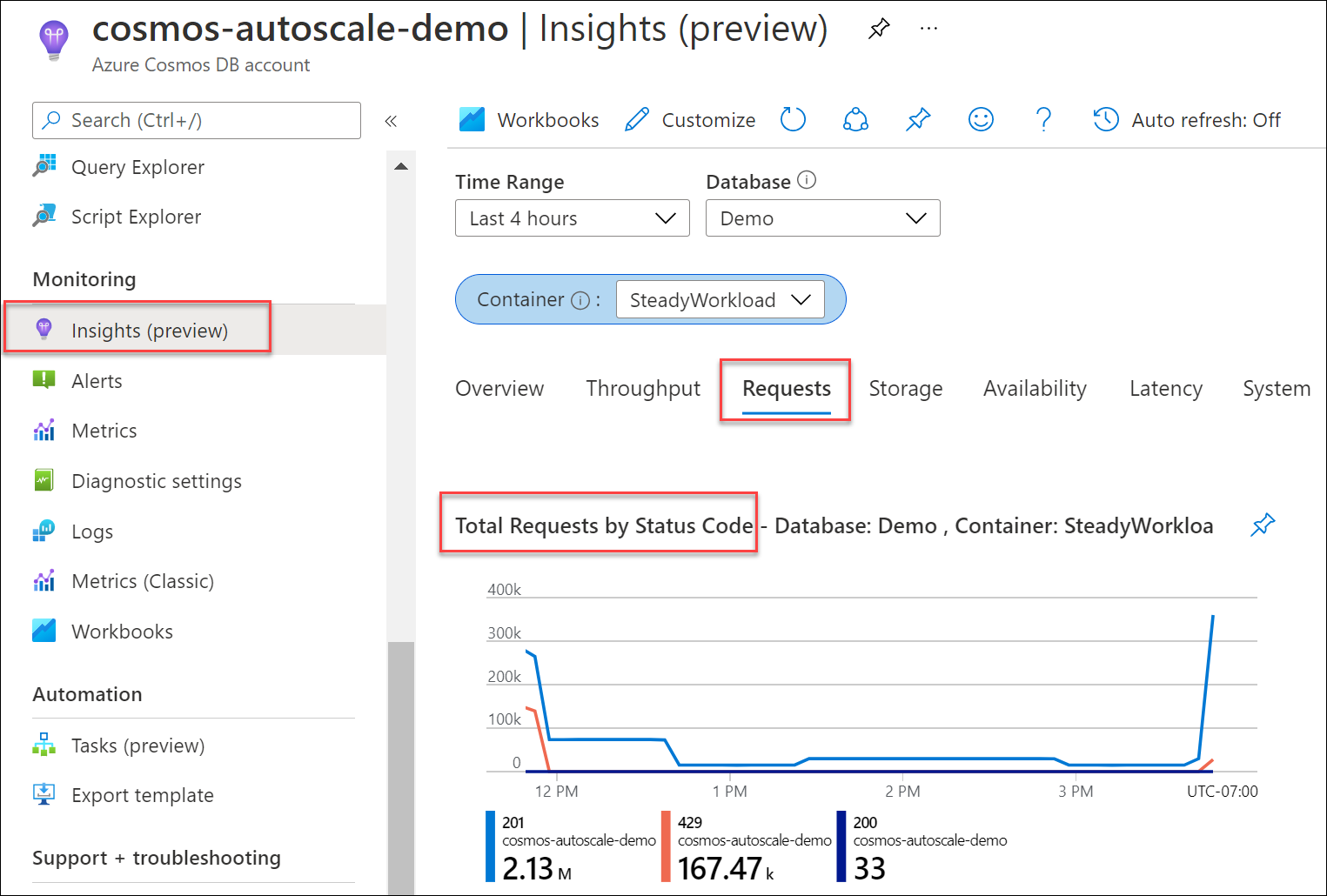
Rekommenderad lösning
Om du ser mellan 1–5 % av begäranden med 429 svar för en produktionsarbetsbelastning och svarstiden från slutpunkt till slutpunkt är acceptabel är detta i allmänhet ett felfritt tecken på att RU:erna används fullt ut. Ingen åtgärd krävs. Annars går du vidare till nästa felsökningssteg.
Viktigt
Det här intervallet på 1–5 % förutsätter att dina kontopartitioner är jämnt fördelade. Om partitionerna inte är jämnt fördelade kan problempartitionen returnera en stor mängd 429 fel medan den totala hastigheten kan vara låg.
Om du använder autoskalning kan du se 429 svar i databasen eller containern, även om RU:erna inte har skalats till maximalt antal RU:er. Se avsnittet Begärandefrekvensen är stor med autoskalning för en förklaring.
En vanlig fråga som uppstår är : "Varför ser jag 429 svar i Azure Monitor-måtten, men ingen i min egen programövervakning?" Om Azure Monitor Metrics visar att du har 429 svar, men du inte har sett några i ditt eget program, beror det på att Azure Cosmos DB-klient-SDK:erna automatically retried internally on the 429 responses och begäran lyckades i efterföljande återförsök som standard. Därför returneras inte statuskoden 429 till programmet. I dessa fall är den totala frekvensen på 429 svar vanligtvis minimal och kan ignoreras på ett säkert sätt, förutsatt att den totala frekvensen är mellan 1–5 % och svarstiden från slutpunkt till slutpunkt är acceptabel för ditt program.
Steg 2: Avgöra om det finns en frekvent partition
En frekvent partition uppstår när en eller några logiska partitionsnycklar förbrukar en oproportionerlig mängd av det totala antalet RU/s på grund av en högre begärandevolym. Detta kan orsakas av en partitionsnyckeldesign som inte distribuerar begäranden jämnt. Det resulterar i att många begäranden dirigeras till en liten delmängd av logiska (vilket innebär fysiska) partitioner som blir "heta". Eftersom alla data för en logisk partition finns på en fysisk partition och total RU/s fördelas jämnt mellan de fysiska partitionerna kan en frekvent partition leda till 429 svar och ineffektiv användning av dataflödet.
Här är några exempel på partitioneringsstrategier som leder till frekventa partitioner:
- Du har en container som lagrar IoT-enhetsdata för en skrivintensiv arbetsbelastning som partitioneras av
date. Alla data för ett enda datum finns på samma logiska och fysiska partition. Eftersom alla data som skrivs varje dag har samma datum resulterar detta i en frekvent partition varje dag.- I det här scenariot ger i stället en partitionsnyckel som
id(antingen ett GUID eller enhets-ID) eller en syntetisk partitionsnyckel som kombineraridochdateger högre kardinalitet för värden och bättre distribution av begärandevolymen.
- I det här scenariot ger i stället en partitionsnyckel som
- Du har ett scenario med flera klientorganisationer med en container partitionerad av
tenantId. Om en klientorganisation är mycket mer aktiv än de andra resulterar den i en frekvent partition. Om den största klientorganisationen till exempel har 100 000 användare, men de flesta klienter har färre än 10 användare, har du en frekvent partition när den partitioneras avtenantID.- I det här föregående scenariot bör du överväga att ha en dedikerad container för den största klientorganisationen, partitionerad av en mer detaljerad egenskap, till exempel
UserId.
- I det här föregående scenariot bör du överväga att ha en dedikerad container för den största klientorganisationen, partitionerad av en mer detaljerad egenskap, till exempel
Så här identifierar du den frekventa partitionen
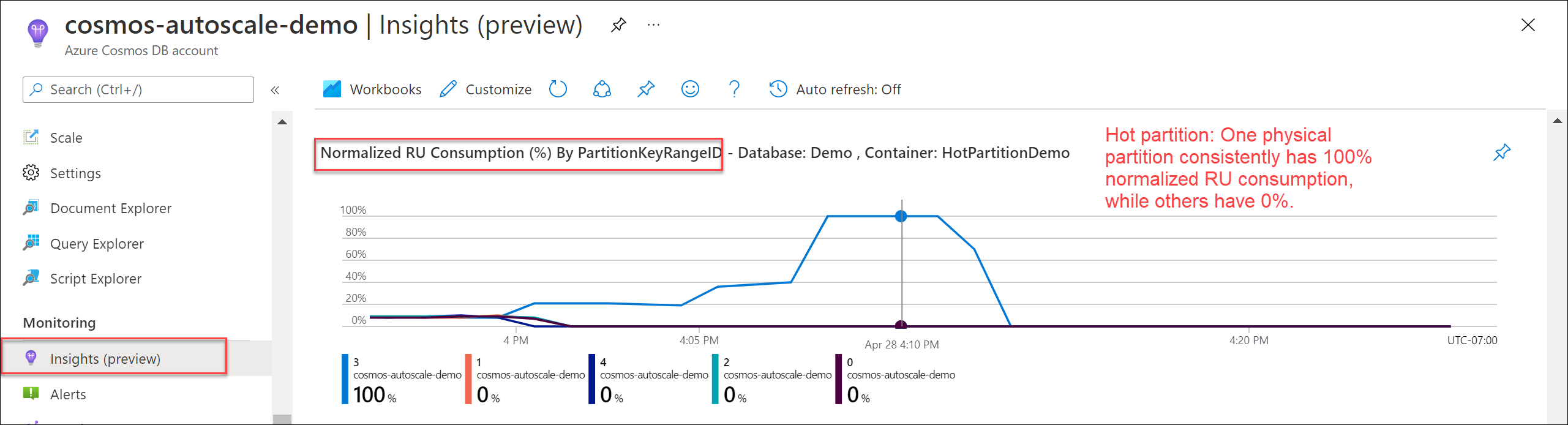
Om du vill kontrollera om det finns en frekvent partition går du till Insights>Throughput>Normalized RU Consumption (%) By PartitionKeyRangeID. Filtrera till en specifik databas och container.
Varje PartitionKeyRangeId mappar till en fysisk partition. Om det finns ett PartitionKeyRangeId som har mycket högre normaliserad RU-förbrukning än andra (till exempel en är konsekvent på 100 %, men andra ligger på 30 % eller mindre), kan detta vara ett tecken på en frekvent partition. Läs mer om måttet Normaliserad RU-förbrukning.
Om du vill se vilka logiska partitionsnycklar som förbrukar mest RU/s använder du Azure Diagnostic Logs. Den här exempelfrågan summerar det totala antalet enheter för programbegäran som förbrukas per sekund på varje logisk partitionsnyckel.
Viktigt
Aktivering av diagnostikloggar medför en separat avgift för Log Analytics-tjänsten, som debiteras baserat på mängden data som matas in. Vi rekommenderar att du aktiverar diagnostikloggar under en begränsad tid för felsökning och inaktiverar när det inte längre behövs. Mer information finns på prissidan .
CDBPartitionKeyRUConsumption
| where TimeGenerated >= ago(24hour)
| where CollectionName == "CollectionName"
| where isnotempty(PartitionKey)
// Sum total request units consumed by logical partition key for each second
| summarize sum(RequestCharge) by PartitionKey, OperationName, bin(TimeGenerated, 1s)
| order by sum_RequestCharge desc
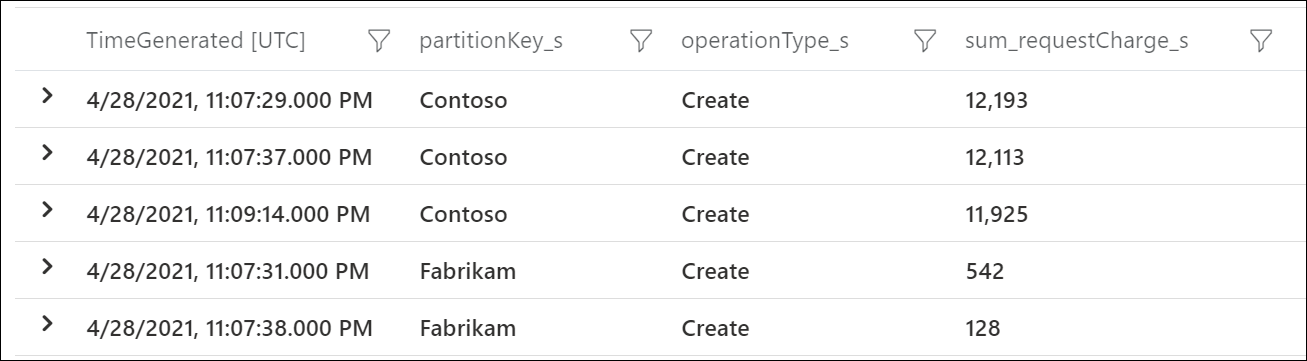
Det här exemplet visar att den logiska partitionsnyckeln med värdet "Contoso" förbrukade cirka 12 000 RU/s under en viss minut, medan den logiska partitionsnyckeln med värdet "Fabrikam" förbrukade mindre än 600 RU/s. Om det här mönstret var konsekvent under den tidsperiod då hastighetsbegränsningen inträffade, skulle detta indikera en frekvent partition.
Tips
I alla arbetsbelastningar kommer det att finnas en naturlig variation i begärandevolymen mellan logiska partitioner. Du bör avgöra om den frekventa partitionen orsakas av en grundläggande snedställning på grund av valet av partitionsnyckel (vilket kan kräva att nyckeln ändras) eller en tillfällig topp på grund av naturlig variation i arbetsbelastningsmönster.
Rekommenderad lösning
Läs vägledningen om hur du väljer en bra partitionsnyckel.
Om det finns hög procent av hastighetsbegränsade begäranden och ingen frekvent partition:
- Du kan öka RU/s i databasen eller containern med hjälp av klient-SDK:er, Azure Portal, PowerShell, CLI eller ARM-mall. Följ metodtipsen för att skala etablerat dataflöde (RU/s) för att fastställa rätt RU/s att ange.
Om det finns hög procent av hastighetsbegränsade begäranden och det finns en underliggande frekvent partition:
- Överväg att ändra partitionsnyckeln för bästa kostnad och prestanda på lång sikt. Partitionsnyckeln kan inte uppdateras på plats, så detta kräver migrering av data till en ny container med en annan partitionsnyckel. Azure Cosmos DB har stöd för ett direktmigreringsverktyg för detta ändamål.
- På kort sikt kan du tillfälligt öka den totala RU/s för resursen för att tillåta mer dataflöde till den frekventa partitionen. Detta rekommenderas inte som en långsiktig strategi eftersom det leder till överetablering av RU/s och högre kostnader.
- På kort sikt kan du använda dataflödesdistributionen mellan partitionsfunktionen (förhandsversion) för att tilldela fler RU/s till den fysiska partition som är frekvent. Detta rekommenderas endast när den fysiska frekventa partitionen är förutsägbar och konsekvent.
Tips
När du ökar dataflödet slutförs uppskalningsåtgärden antingen omedelbart eller upp till 5–6 timmar för att slutföras, beroende på hur många RU/s du vill skala upp till. Om du vill veta det högsta antalet RU/s som du kan ange utan att utlösa den asynkrona skalningsåtgärden (som kräver att Azure Cosmos DB etablerar fler fysiska partitioner) multiplicerar du antalet distinkta PartitionKeyRangeIds med 10 0000 RU/s. Om du till exempel har 30 000 RU/s etablerade och 5 fysiska partitioner (6 000 RU/s allokerade per fysisk partition) kan du öka till 50 000 RU/s (10 000 RU/s per fysisk partition) i en omedelbar uppskalningsåtgärd. Om du ökar till >50 000 RU/s krävs en asynkron uppskalningsåtgärd. Läs mer om metodtips för skalning av etablerat dataflöde (RU/s).
Steg 3: Avgöra vilka begäranden som returnerar 429 svar
Så här undersöker du begäranden med 429 svar
Använd Azure Diagnostic Logs för att identifiera vilka begäranden som returnerar 429 svar och hur många RU:er de förbrukade. Den här exempelfrågan aggregeras på minutnivå.
Viktigt
Aktivering av diagnostikloggar medför en separat avgift för Log Analytics-tjänsten, som debiteras baserat på mängden data som matas in. Vi rekommenderar att du aktiverar diagnostikloggar under en begränsad tid för felsökning och inaktiverar när det inte längre behövs. Mer information finns på prissidan .
CDBDataPlaneRequests
| where TimeGenerated >= ago(24h)
| summarize throttledOperations = dcountif(ActivityId, StatusCode == 429), totalOperations = dcount(ActivityId), totalConsumedRUPerMinute = sum(RequestCharge) by DatabaseName, CollectionName, OperationName, RequestResourceType, bin(TimeGenerated, 1min)
| extend averageRUPerOperation = 1.0 * totalConsumedRUPerMinute / totalOperations
| extend fractionOf429s = 1.0 * throttledOperations / totalOperations
| order by fractionOf429s desc
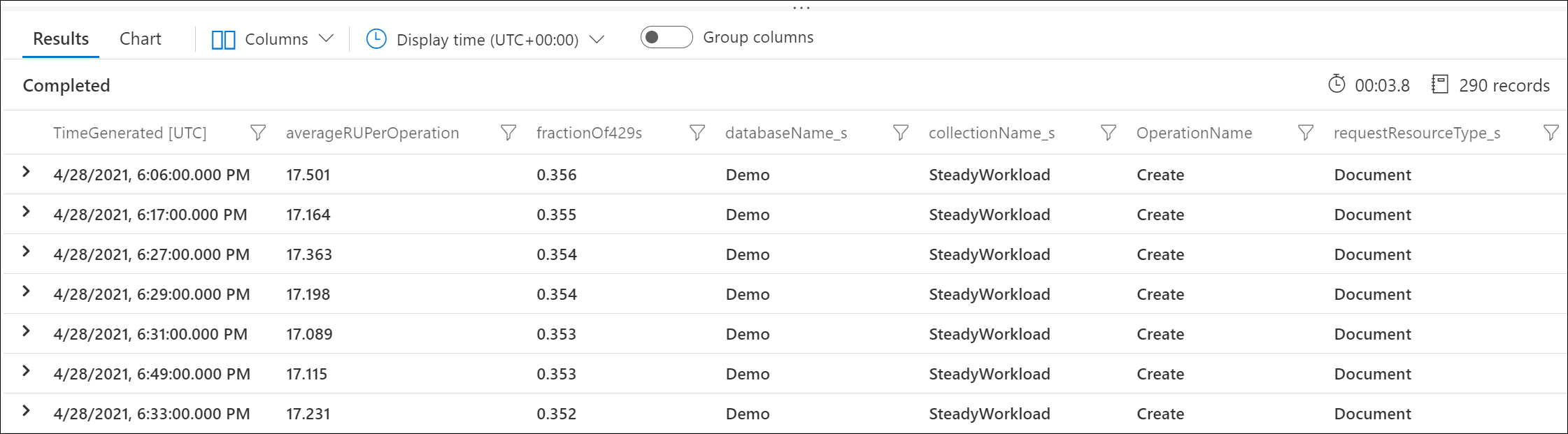
Exempelutdata visar till exempel att varje minut var 30 % av begäranden om att skapa dokument begränsade, och varje begäran förbrukade i genomsnitt 17 RU:er.
Rekommenderad lösning
Använda Kapacitetsplaneraren för Azure Cosmos DB
Du kan använda Kapacitetshanteraren för Azure Cosmos DB för att förstå vad som är det bästa etablerade dataflödet baserat på din arbetsbelastning (volym och typ av åtgärder och dokumentstorlek). Du kan anpassa beräkningarna ytterligare genom att tillhandahålla exempeldata för att få en mer exakt uppskattning.
429 svar på begäranden om att skapa, ersätta eller distribuera dokument
- Som standard indexeras alla egenskaper som standard i API:et för NoSQL. Justera indexeringsprincipen så att endast de egenskaper som behövs indexeras. Detta sänker de enheter för programbegäran som krävs per åtgärd för att skapa dokument, vilket minskar sannolikheten för att se 429 svar eller gör att du kan uppnå högre åtgärder per sekund för samma mängd etablerade RU/s.
429 svar på begäranden om frågedokument
- Följ vägledningen för att felsöka frågor med hög RU-avgift
429 svar om att köra lagrade procedurer
- Lagrade procedurer är avsedda för åtgärder som kräver skrivtransaktioner över ett partitionsnyckelvärde. Vi rekommenderar inte att du använder lagrade procedurer för ett stort antal läs- eller frågeåtgärder. För bästa prestanda bör dessa läs- eller frågeåtgärder utföras på klientsidan med hjälp av Azure Cosmos DB SDK:er.
Begärandefrekvensen är stor med autoskalning
All vägledning i den här artikeln gäller både manuellt dataflöde och autoskalningsdataflöde.
När du använder autoskalning uppstår en vanlig fråga: "Är det fortfarande möjligt att se 429 svar med autoskalning?"
Ja. Det finns två huvudsakliga scenarier där detta kan inträffa.
Scenario 1: När den totala förbrukade RU/s överskrider maximalt antal RU/s för databasen eller containern begränsar tjänsten begäranden i enlighet med detta. Detta är detsamma som att överskrida det övergripande manuella etablerade dataflödet för en databas eller container.
Scenario 2: Om det finns en frekvent partition, d.v.s. ett logiskt partitionsnyckelvärde som har en oproportionerligt högre mängd begäranden jämfört med andra partitionsnyckelvärden, är det möjligt att den underliggande fysiska partitionen överskrider sin RU/s-budget. För att undvika partitioner med frekvent åtkomstnivå rekommenderar vi att du väljer en bra partitionsnyckel som resulterar i en jämn fördelning av både lagring och dataflöde. Detta liknar när det finns en frekvent partition när du använder manuellt dataflöde.
Om du till exempel väljer alternativet 20 000 RU/s maximalt dataflöde och har 200 GB lagringsutrymme med fyra fysiska partitioner kan varje fysisk partition skalas automatiskt upp till 5 000 RU/s. Om det fanns en frekvent partition på en viss logisk partitionsnyckel visas 429 svar när den underliggande fysiska partitionen som den finns i överskrider 5 000 RU/s, d.v.s. överskrider 100 % normaliserad användning.
Följ vägledningen i steg 1, steg 2 och steg 3 för att felsöka dessa scenarier.
En annan vanlig fråga som uppstår är varför normaliserad RU-förbrukning är 100 %, men autoskalningen skalades inte till maximal RU/s?
Detta inträffar vanligtvis för arbetsbelastningar som har tillfälliga eller tillfälliga toppar av användningen. När du använder autoskalning skalar Azure Cosmos DB endast RU:erna till det maximala dataflödet när den normaliserade RU-förbrukningen är 100 % under en varaktig och kontinuerlig tidsperiod i ett intervall på 5 sekunder. Detta görs för att säkerställa att skalningslogiken är kostnadsvänlig för användaren, eftersom den säkerställer att enskilda, momentära toppar inte leder till onödig skalning och högre kostnader. När det finns momentära toppar skalas systemet vanligtvis upp till ett värde som är högre än de som tidigare skalats till RU/s, men lägre än max-RU/s. Läs mer om hur du tolkar det normaliserade RU-förbrukningsmåttet med autoskalning.
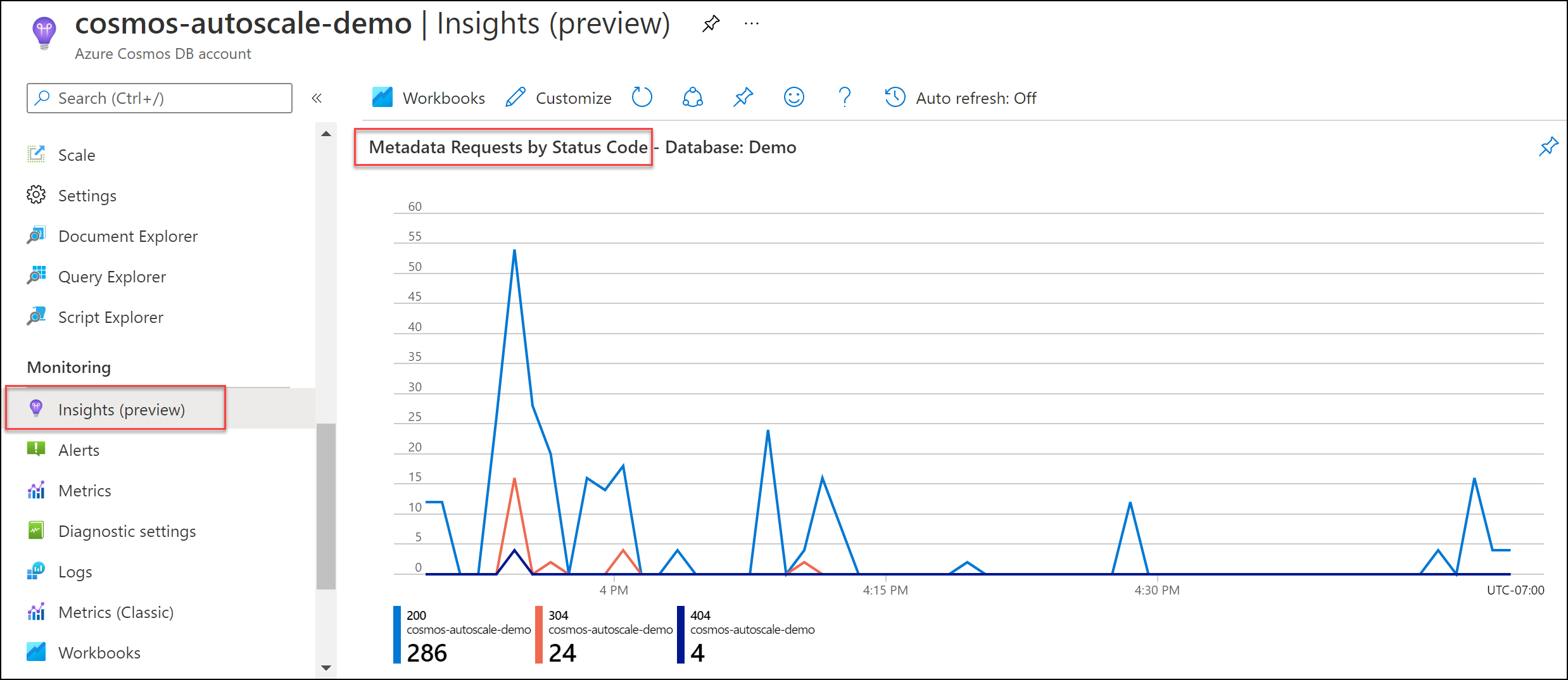
Hastighetsbegränsning för metadatabegäranden
Begränsning av metadatahastighet kan inträffa när du utför en stor mängd metadataåtgärder på databaser och/eller containrar. Metadataåtgärder inkluderar:
- Skapa, läsa, uppdatera eller ta bort en container eller databas
- Lista databaser eller containrar i ett Azure Cosmos DB-konto
- Fråga efter erbjudanden för att se aktuellt etablerat dataflöde
Det finns en systemreserverad RU-gräns för dessa åtgärder, så att öka de etablerade RU:erna för databasen eller containern påverkar inte och rekommenderas inte. Se Kontrollplanstjänstgränser.
Undersök så här
Gå till Insightssystemmetadatabegäranden>> efter statuskod. Filtrera till en specifik databas och container om du vill.
Rekommenderad lösning
Om ditt program behöver utföra metadataåtgärder bör du överväga att implementera en backoff-princip för att skicka dessa begäranden till en lägre hastighet.
Använd statiska Azure Cosmos DB-klientinstanser. När DocumentClient eller CosmosClient initieras hämtar Azure Cosmos DB SDK metadata om kontot, inklusive information om konsekvensnivån, databaser, containrar, partitioner och erbjudanden. Den här initieringen kan förbruka ett stort antal enheter för programbegäran och bör inte utföras ofta. Använd en enda instans av DocumentClient och använd den under hela ditt programs livslängd.
Cachelagrar namnen på databaser och containrar. Hämta namnen på dina databaser och containrar från konfigurationen eller cachelagrar dem vid start. Anrop som ReadDatabaseAsync/ReadDocumentCollectionAsync eller CreateDatabaseQuery/CreateDocumentCollectionQuery resulterar i metadataanrop till tjänsten, som förbrukar från den systemreserverade RU-gränsen. Dessa åtgärder bör utföras sällan.
Hastighetsbegränsning på grund av tillfälligt tjänstfel
Det här 429-felet returneras när begäran påträffar ett tillfälligt tjänstfel. Att öka RU:erna i databasen eller containern påverkar inte och rekommenderas inte.
Rekommenderad lösning
Försök igen med begäran. Om felet kvarstår i flera minuter kan du skicka ett supportärende från Azure Portal.
Nästa steg
- Övervaka normaliserad RU/s-förbrukning av databasen eller containern.
- Diagnostisera och felsöka problem när du använder Azure Cosmos DB .NET SDK.
- Läs mer om prestandariktlinjer för .NET v3 och .NET v2.
- Diagnostisera och felsöka problem när du använder Azure Cosmos DB Java v4 SDK.
- Läs mer om prestandariktlinjer för Java v4 SDK.