Översikt över uppdateringsprincip
Uppdateringsprinciper är automatiseringsmekanismer som utlöses när nya data skrivs till en tabell. De eliminerar behovet av särskild orkestrering genom att köra en fråga för att transformera inmatade data och spara resultatet i en måltabell. Flera uppdateringsprinciper kan definieras i en enda tabell, vilket möjliggör olika transformeringar och sparar data till flera tabeller samtidigt. Måltabellerna kan ha ett annat schema, en kvarhållningsprincip och andra principer från källtabellen.
En spårningskälltabell med hög hastighet kan till exempel innehålla data som är formaterade som en fritextkolumn. Måltabellen kan innehålla specifika spårningsrader, med ett välstrukturerat schema som genereras från en transformering av källtabellens fritextdata med parsningsoperatorn. Mer information finns i vanliga scenarier.
Följande diagram visar en övergripande vy över en uppdateringsprincip. Den visar två uppdateringsprinciper som utlöses när data läggs till i den andra källtabellen och resulterar i att transformerade data läggs till i de två måltabellerna.
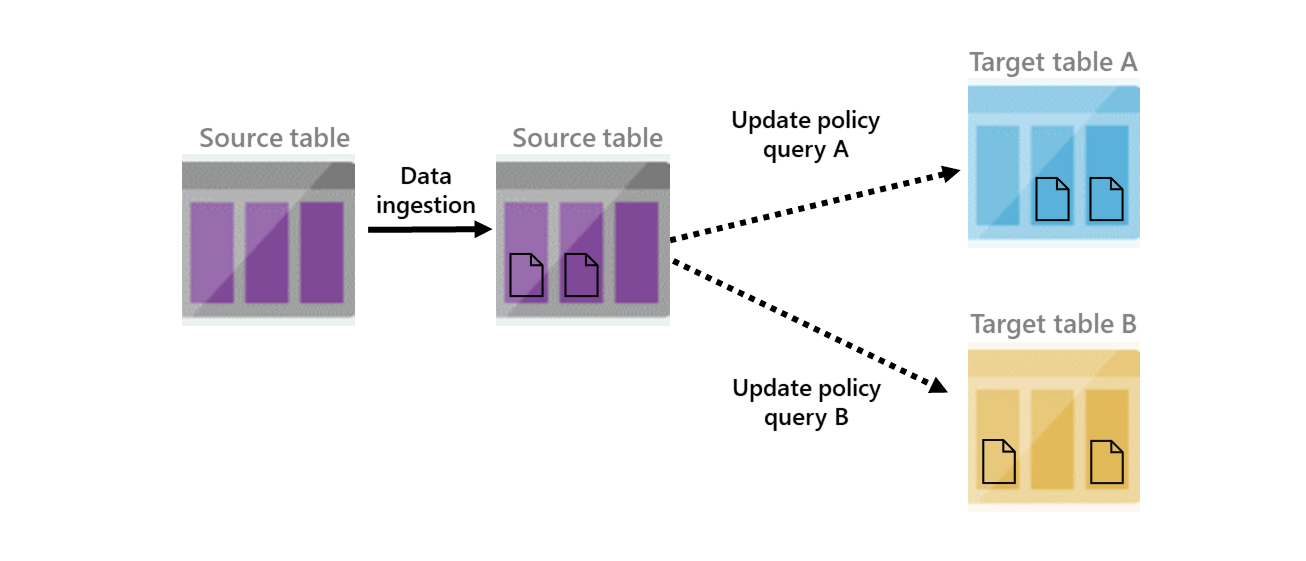
En uppdateringsprincip omfattas av samma begränsningar och metodtips som vanlig inmatning. Principen skalas ut enligt klusterstorleken och är mer effektiv vid hantering av massinmatning.
Anteckning
- Käll- och måltabellen måste finnas i samma databas.
- Uppdateringsprincipens funktionsschema och måltabellschemat måste matcha i kolumnnamn, typer och ordning.
Inmatning av formaterade data förbättrar prestanda och CSV rekommenderas på grund av att det är ett väldefinierat format. Ibland har du dock ingen kontroll över dataformatet, eller så vill du utöka inmatade data, till exempel genom att koppla poster med en statisk dimensionstabell i databasen.
Uppdatera principfråga
Om uppdateringsprincipen har definierats i måltabellen kan flera frågor köras på data som matas in i en källtabell. Om det finns flera uppdateringsprinciper är körningsordningen inte nödvändigtvis känd.
Frågebegränsningar
- Den principrelaterade frågan kan anropa lagrade funktioner, men:
- Den kan inte köra frågor mellan kluster.
- Den kan inte komma åt externa data eller externa tabeller.
- Det går inte att göra pratbubblan (med hjälp av ett plugin-program).
- Frågan har inte läsbehörighet till tabeller som har RestrictedViewAccess-principen aktiverad.
- Information om begränsningar för uppdateringsprinciper vid inmatning av direktuppspelning finns i begränsningar för inmatning av strömning.
Varning
En felaktig fråga kan förhindra datainmatning i källtabellen. Det är viktigt att notera att begränsningar, samt kompatibiliteten mellan frågeresultaten och schemat för käll- och måltabellerna, kan orsaka en felaktig fråga för att förhindra datainmatning i källtabellen.
Dessa begränsningar verifieras när principen skapas och körs, men inte när godtyckliga lagrade funktioner som frågan kan referera till uppdateras. Därför är det viktigt att göra ändringar med försiktighet för att säkerställa att uppdateringsprincipen förblir intakt.
När du refererar Source till tabellen i Query delen av principen, eller i funktioner som refereras av Query delen:
- Använd inte tabellens kvalificerade namn. Använd
TableNamei stället . - Använd
database("DatabaseName").TableNameinte ellercluster("ClusterName").database("DatabaseName").TableName.
Uppdateringsprincipobjektet
En tabell kan ha noll eller flera associerade uppdateringsprincipobjekt. Varje sådant objekt representeras som en JSON-egenskapsuppsättning med följande egenskaper definierade.
| Egenskap | Typ | Description |
|---|---|---|
| IsEnabled | bool |
Tillstånd om uppdateringsprincipen är true – aktiverad eller falsk – inaktiverad |
| Källa | string |
Namnet på den tabell som utlöser anrop av uppdateringsprincipen |
| Söka i data | string |
En fråga som används för att skapa data för uppdateringen |
| IsTransactional | bool |
Anger om uppdateringsprincipen är transaktionell eller inte, standardvärdet är falskt. Om principen är transaktionell och uppdateringsprincipen misslyckas uppdateras inte källtabellen. |
| PropagateIngestionProperties | bool |
Tillstånd om egenskaper som anges under inmatningen till källtabellen, till exempel utrymmestaggar och skapandetid, gäller för måltabellen. |
| ManagedIdentity | string |
Den hanterade identiteten för vilken uppdateringsprincipen körs. Den hanterade identiteten kan vara ett objekt-ID eller det system reserverade ordet. Uppdateringsprincipen måste konfigureras med en hanterad identitet när frågan refererar till tabeller i andra databaser eller tabeller med en aktiverad säkerhetsprincip på radnivå. Mer information finns i Använda en hanterad identitet för att köra en uppdateringsprincip. |
Anteckning
I produktionssystem anger du IsTransactional:true för att säkerställa att måltabellen inte förlorar data vid tillfälliga fel.
Anteckning
Sammanhängande uppdateringar tillåts, till exempel från tabell A till tabell B, till tabell C. Men om uppdateringsprinciper definieras på ett cirkulärt sätt identifieras detta vid körning och uppdateringskedjan klipps ut. Data matas bara in en gång till varje tabell i kedjan.
Kommandon för hantering
Kommandon för hantering av uppdateringsprinciper omfattar:
.show table *TableName* policy updatevisar den aktuella uppdateringsprincipen för en tabell..alter table *TableName* policy updatedefinierar den aktuella uppdateringsprincipen för en tabell..alter-merge table *TableName* policy updatelägger till definitioner i den aktuella uppdateringsprincipen för en tabell..delete table *TableName* policy updatetar bort den aktuella uppdateringsprincipen för en tabell.
Uppdateringsprincipen initieras efter inmatning
Uppdateringsprinciper börjar gälla när data matas in eller flyttas till en källtabell eller omfång skapas i en källtabell med något av följande kommandon:
- .ingest (pull)
- .ingest (infogad)
- .set | .append | .set-or-append | .set-or-replace
- .move-utrymme
- .replace-utrymme
- Kommandot
PropagateIngestionPropertiesbörjar bara gälla vid inmatningsåtgärder. När uppdateringsprincipen utlöses som en del av ett.move extents- eller.replace extents-kommando har det här alternativet ingen effekt.
- Kommandot
Varning
När uppdateringsprincipen anropas som en del av ett .set-or-replace kommando ersätts som standard data i härledda tabeller på samma sätt som i källtabellen.
Data kan gå förlorade i alla tabeller med en uppdateringsprinciprelation om replace kommandot anropas.
Överväg att använda .set-or-append i stället.
Ta bort data från källtabellen
När du har matat in data till måltabellen kan du ta bort dem från källtabellen. Ange en period för mjuk borttagning av 0sec (eller 00:00:00) i källtabellens kvarhållningsprincip och uppdateringsprincipen som transaktionell. Följande villkor gäller:
- Källdata kan inte frågas från källtabellen
- Källdata bevaras inte i beständig lagring som en del av inmatningsåtgärden
- Driftprestandan förbättras. Resurser efter inmatning minskas för bakgrundsrensningsåtgärder i utrymmen i källtabellen.
Anteckning
När källtabellen har en mjuk borttagningsperiod på 0sec (eller 00:00:00) måste alla uppdateringsprinciper som refererar till den här tabellen vara transaktionella.
Prestandapåverkan
Uppdateringsprinciper kan påverka klusterprestanda och inmatning för datautbredning multipliceras med antalet måltabeller. Det är viktigt att optimera den principrelaterade frågan. Du kan testa prestandapåverkan för en uppdateringsprincip genom att anropa principen i redan befintliga utrymmen, innan du skapar eller ändrar principen eller på den funktion som används med frågan.
Utvärdera resursanvändning
Använd .show queriesför att utvärdera resursanvändning (CPU, minne och så vidare) med följande parametrar:
SourceAnge egenskapen, källtabellens namn, somMySourceTable- Ställ in egenskapen så att den
Queryanropar en funktion med namnetMyFunction()
// '_extentId' is the ID of a recently created extent, that likely hasn't been merged yet.
let _extentId = toscalar(
MySourceTable
| project ExtentId = extent_id(), IngestionTime = ingestion_time()
| where IngestionTime > ago(10m)
| top 1 by IngestionTime desc
| project ExtentId
);
// This scopes the source table to the single recent extent.
let MySourceTable =
MySourceTable
| where ingestion_time() > ago(10m) and extent_id() == _extentId;
// This invokes the function in the update policy (that internally references `MySourceTable`).
MyFunction
Fel
Med standardinställningen IsTransactional:falsekan data fortfarande matas in i källtabellen även om principen inte körs.
Inställningen IsTransactional:true garanterar konsekvens mellan data i käll- och måltabellen. Men om principvillkoren misslyckas matas inte data in i källtabellen. Beroende på villkor matas data ibland in i källtabellen, men inte till måltabellen. Men om principen har definierats felaktigt, eller om det finns ett schemafel, matas inte data in i käll- eller måltabellen. Till exempel kan ett matchningsfel mellan frågeutdataschemat och måltabellen orsakas av att en kolumn tas bort från måltabellen.
Du kan visa fel med kommandot.show ingestion failures .
.show ingestion failures
| where FailedOn > ago(1hr) and OriginatesFromUpdatePolicy == true
Behandling av fel
Icke-transaktionell princip
Om inställningen är inställd IsTransactional:falsepå ignoreras eventuella fel vid körning av principen. Inmatningen försöks inte automatiskt igen. Du kan försöka mata in igen manuellt.
Transaktionsprincip
Om inmatningsmetoden är pullanges till IsTransactional:trueär Datahantering-tjänsten inblandad och inmatningen görs automatiskt på nytt enligt följande villkor:
- Återförsök utförs tills någon av följande konfigurerbara gränsinställningar uppfylls:
DataImporterMaximumRetryPeriodellerDataImporterMaximumRetryAttempts - Som standard är inställningen
DataImporterMaximumRetryPeriodtvå dagar ochDataImporterMaximumRetryAttemptsär 10 - Backoff-perioden börjar på 2 minuter och fördubblas. Så väntan börjar med 2 min, sedan ökar till 4 min, till 8 min, till 16 min och så vidare.
I andra fall kan du manuellt försöka mata in igen.
Exempel på extrahering, transformering, inläsning
Du kan använda uppdateringsprincipinställningar för att extrahera, transformera, läsa in (ETL).
I det här exemplet använder du en uppdateringsprincip med en enkel funktion för att utföra ETL. Först skapar vi två tabeller:
- Källtabellen – innehåller en kolumn med en enda strängtyp som data matas in i.
- Måltabellen – innehåller önskat schema. Uppdateringsprincipen definieras i den här tabellen.
Nu ska vi skapa källtabellen:
.create table MySourceTable (OriginalRecord:string)Skapa sedan måltabellen:
.create table MyTargetTable (Timestamp:datetime, ThreadId:int, ProcessId:int, TimeSinceStartup:timespan, Message:string)Skapa sedan en funktion för att extrahera data:
.create function with (docstring = 'Parses raw records into strongly-typed columns', folder = 'UpdatePolicyFunctions') ExtractMyLogs() { MySourceTable | parse OriginalRecord with "[" Timestamp:datetime "] [ThreadId:" ThreadId:int "] [ProcessId:" ProcessId:int "] TimeSinceStartup: " TimeSinceStartup:timespan " Message: " Message:string | project-away OriginalRecord }Ange nu uppdateringsprincipen så att den anropar funktionen som vi skapade:
.alter table MyTargetTable policy update @'[{ "IsEnabled": true, "Source": "MySourceTable", "Query": "ExtractMyLogs()", "IsTransactional": true, "PropagateIngestionProperties": false}]'Om du vill tömma källtabellen när data har matats in i måltabellen definierar du kvarhållningsprincipen i källtabellen så att den har 0s som dess
SoftDeletePeriod..alter-merge table MySourceTable policy retention softdelete = 0s
Relaterat innehåll
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för