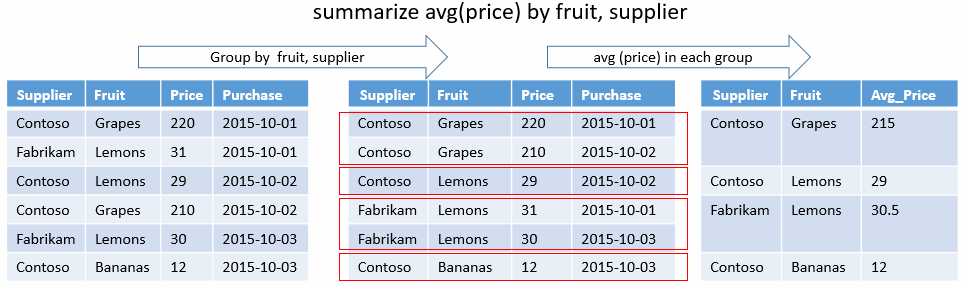
summarize-operatorn
Skapar en tabell som aggregerar innehållet i indatatabellen.
Syntax
T| summarize [ SummarizeParameters ] [[Column=] Aggregation [, ...]] [by [Column=] GroupExpression [, ...]]
Läs mer om syntaxkonventioner.
Parametrar
| Namn | Typ | Obligatorisk | Beskrivning |
|---|---|---|---|
| Kolumn | string |
Namnet på resultatkolumnen. Standardvärdet är ett namn som härletts från uttrycket. | |
| Aggregering | string |
✔️ | Ett anrop till en sammansättningsfunktion som count() eller avg(), med kolumnnamn som argument. |
| GroupExpression | Skalär | ✔️ | Ett skalärt uttryck som kan referera till indata. Utdata har lika många poster som det finns distinkta värden för alla grupputtryck. |
| SummarizeParameters | string |
Noll eller flera blankstegsavgränsade parametrar i form av Namnvärde= som styr beteendet. Se parametrar som stöds. |
Anteckning
När indatatabellen är tom beror utdata på om GroupExpression används:
- Om GroupExpression inte anges blir utdata en enda (tom) rad.
- Om GroupExpression anges har utdata inga rader.
Parametrar som stöds
| Name | Beskrivning |
|---|---|
hint.num_partitions |
Anger antalet partitioner som används för att dela frågebelastningen på klusternoder. Se shuffle-fråga |
hint.shufflekey=<key> |
Frågan shufflekey delar frågebelastningen på klusternoder med hjälp av en nyckel för att partitioneras data. Se shuffle-fråga |
hint.strategy=shuffle |
Strategifrågan shuffle delar frågebelastningen på klusternoder, där varje nod bearbetar en partition av data. Se shuffle-fråga |
Returer
Indataraderna ordnas i grupper som har samma värden för uttrycken by . Sedan beräknas de angivna aggregeringsfunktionerna över varje grupp och skapar en rad för varje grupp. Resultatet innehåller kolumnerna by och även minst en kolumn för varje beräknad aggregering. (Vissa aggregeringsfunktioner returnerar flera kolumner.)
Resultatet har så många rader som det finns distinkta kombinationer av by värden (som kan vara noll). Om det inte finns några gruppnycklar har resultatet en enda post.
Om du vill sammanfatta över intervall med numeriska värden använder du bin() för att minska intervall till diskreta värden.
Anteckning
- Även om du kan ange godtyckliga uttryck för både sammansättnings- och grupperingsuttrycken är det mer effektivt att använda enkla kolumnnamn eller tillämpa på
bin()en numerisk kolumn. - De automatiska intervallen för datetime-kolumner stöds inte längre. Använd explicit diskretisering i stället. Till exempel
summarize by bin(timestamp, 1h).
Standardvärden för sammansättningar
I följande tabell sammanfattas standardvärdena för sammansättningar:
| Operator | Standardvärde |
|---|---|
count(), countif(), dcount(), dcountif(), count_distinct(), sum(), sumif(), variance(), varianceif(), stdev(), stdevif() |
0 |
make_bag(), make_bag_if(), make_list(), make_list_if(), make_set(), make_set_if() |
tom dynamisk matris ([]) |
| Alla andra | null |
Anteckning
När du tillämpar dessa aggregeringar på entiteter som innehåller null-värden ignoreras null-värdena och tas inte med i beräkningen. Exempel finns i Aggregera standardvärden.
Exempel
Unik kombination
Följande fråga avgör vilka unika kombinationer av State och EventType det finns för stormar som resulterade i direkt skada. Det finns inga aggregeringsfunktioner, bara gruppera efter-nycklar. Utdata visar bara kolumnerna för dessa resultat.
StormEvents
| where InjuriesDirect > 0
| summarize by State, EventType
Resultat
I följande tabell visas endast de första 5 raderna. Kör frågan för att se fullständiga utdata.
| Tillstånd | Eventtype |
|---|---|
| TEXAS | Åska vind |
| TEXAS | Flash Flood |
| TEXAS | Vinterväder |
| TEXAS | Hög vind |
| TEXAS | Översvämning |
| ... | ... |
Minsta och högsta tidsstämpel
Hittar de lägsta och högsta kraftiga regnstormarna på Hawaii. Det finns ingen group-by-sats, så det finns bara en rad i utdata.
StormEvents
| where State == "HAWAII" and EventType == "Heavy Rain"
| project Duration = EndTime - StartTime
| summarize Min = min(Duration), Max = max(Duration)
Resultat
| Min | Max |
|---|---|
| 01:08:00 | 11:55:00 |
Distinkt antal
Skapa en rad för varje kontinent som visar antalet städer där aktiviteter sker. Eftersom det finns få värden för "kontinent" behövs ingen grupperingsfunktion i by-satsen:
StormEvents
| summarize TypesOfStorms=dcount(EventType) by State
| sort by TypesOfStorms
Resultat
I följande tabell visas endast de första 5 raderna. Kör frågan om du vill se fullständiga utdata.
| Tillstånd | TypesOfStorms |
|---|---|
| TEXAS | 27 |
| KALIFORNIEN | 26 |
| PENNSYLVANIA | 25 |
| GEORGIEN | 24 |
| ILLINOIS | 23 |
| ... | ... |
Histogram
I följande exempel beräknas ett histogram för stormhändelsetyper som har stormar som varar längre än 1 dag. Eftersom Duration har många värden använder du bin() för att gruppera dess värden i 1-dagarsintervall.
StormEvents
| project EventType, Duration = EndTime - StartTime
| where Duration > 1d
| summarize EventCount=count() by EventType, Length=bin(Duration, 1d)
| sort by Length
Resultat
| Eventtype | Längd | EventCount |
|---|---|---|
| Torka | 30.00:00:00 | 1646 |
| Wildfire | 30.00:00:00 | 11 |
| Värme | 30.00:00:00 | 14 |
| Översvämning | 30.00:00:00 | 20 |
| Kraftigt regn | 29.00:00:00 | 42 |
| ... | ... | ... |
Aggregerar standardvärden
När operatorns summarize indata har minst en tom grupp-by-nyckel är även resultatet tomt.
När indata summarize för operatorn inte har en tom grupp-efter-nyckel är resultatet standardvärdena för de aggregeringar som används i Mer information finns i summarizeStandardvärden för sammansättningar.
datatable(x:long)[]
| summarize any_x=take_any(x), arg_max_x=arg_max(x, *), arg_min_x=arg_min(x, *), avg(x), buildschema(todynamic(tostring(x))), max(x), min(x), percentile(x, 55), hll(x) ,stdev(x), sum(x), sumif(x, x > 0), tdigest(x), variance(x)
Resultat
| any_x | arg_max_x | arg_min_x | avg_x | schema_x | max_x | min_x | percentile_x_55 | hll_x | stdev_x | sum_x | sumif_x | tdigest_x | variance_x |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NaN | 0 | 0 | 0 | 0 |
Resultatet av avg_x(x) beror NaN på att dividera med 0.
datatable(x:long)[]
| summarize count(x), countif(x > 0) , dcount(x), dcountif(x, x > 0)
Resultat
| count_x | Countif_ | dcount_x | dcountif_x |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
datatable(x:long)[]
| summarize make_set(x), make_list(x)
Resultat
| set_x | list_x |
|---|---|
| [] | [] |
Den aggregerade genomsnittssumman summerar alla icke-null-värden och räknar endast de som deltog i beräkningen (tar inte hänsyn till nullvärden).
range x from 1 to 4 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize sum(y), avg(y)
Resultat
| sum_y | avg_y |
|---|---|
| 15 | 5 |
Det vanliga antalet räknar nullvärden:
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize count(y)
Resultat
| count_y |
|---|
| 2 |
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize make_set(y), make_set(y)
Resultat
| set_y | set_y1 |
|---|---|
| [5.0] | [5.0] |
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för