Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure Monitor samlar in och aggregerar mått och loggar från systemet för att övervaka tillgänglighet, prestanda och motståndskraft och meddela dig om problem som påverkar systemet. Du kan använda Azure-portalen, PowerShell, Azure CLI, REST API eller klientbibliotek för att konfigurera och visa övervakningsdata.
Olika mått och loggar är tillgängliga för olika resurstyper. Den här artikeln beskriver de typer av övervakningsdata som du kan samla in för den här tjänsten och hur du analyserar dessa data.
Samla in data med Azure Monitor
Den här tabellen beskriver hur du kan samla in data för att övervaka din tjänst och vad du kan göra med data när de har samlats in:
| Data att samla in | Beskrivning | Så här samlar du in och dirigerar data | Var du kan visa data | Data som stöds |
|---|---|---|---|---|
| Måttdata | Mått är numeriska värden som beskriver en aspekt av ett system vid en viss tidpunkt. Aggregera mått med hjälp av algoritmer, jämföra mått med andra mått och analysera mått för trender över tid. | - Samlas in automatiskt med jämna mellanrum.
– Du kan dirigera en del plattformsmått till en Log Analytics-arbetsyta för att analysera tillsammans med annan data. Kontrollera inställningen DS export för varje mått för att se om du kan använda en diagnostikinställning för att dirigera måttdata. |
Metrikutforskare | Azure Data Explorer-mått som stöds av Azure Monitor |
| Resursloggdata | Loggar är registrerade systemhändelser med en tidsstämpel. Loggar kan innehålla olika typer av data och vara strukturerade eller friformstext. Du kan dirigera resursloggdata till Log Analytics-arbetsytor för frågor och analys. | Skapa en diagnostikinställning för att samla in och dirigera resursloggdata. | Log Analytics | Azure Data Explorer-resursloggdata som stöds av Azure Monitor |
| Data för aktivitetslogg | Azure Monitor-aktivitetsloggen ger insikter om händelser på prenumerationsnivå. Aktivitetsloggen innehåller information som när en resurs ändras eller en virtuell dator startas. | - Samlas in automatiskt.
- Skapa en diagnostikinställning till en Log Analytics-arbetsyta utan kostnad. |
aktivitetslogg |
Listan över alla data som stöds av Azure Monitor finns i:
Inbyggd övervakning för Azure Data Explorer
Azure Data Explorer erbjuder mått och loggar för att övervaka tjänsten.
Övervaka prestanda, hälsa och användning i Azure Data Explorer med hjälp av mått
Azure Data Explorer-mått ger viktiga indikatorer om hälsotillståndet och prestandan för Azure Data Explorer-klusterresurserna. Använd måtten för att övervaka användning, hälsa och prestanda i Azure Data Explorer-kluster i ditt specifika scenario som fristående mått. Du kan också använda mått som grund för Azure-instrumentpaneler och Azure-aviseringar.
Så här använder du mått för att övervaka dina Azure Data Explorer-resurser i Azure-portalen:
- Logga in på Azure-portalen.
- I den vänstra panelen i ditt Azure Data Explorer-kluster söker du efter mått.
- Välj Mått för att öppna måttpanelen och påbörja analysen av klustret.
I fönstret Mått väljer du specifika mått att spåra, väljer hur du aggregerar dina data och skapar måttdiagram som ska visas på instrumentpanelen.
Resource och Metric Namespace-väljare är förvalda för ditt Azure Data Explorer-kluster. Siffrorna i följande bild motsvarar den numrerade listan. De vägleder dig genom olika alternativ för att konfigurera och visa dina mått.

- Om du vill skapa ett måttdiagram, välj Mått namn och relevant aggregation för varje mått. Mer information om olika mått finns i Azure Data Explorer-mått som stöds.
- Välj Lägg till mått för att se flera mått ritade i samma diagram.
- Välj + Nytt diagram för att se flera diagram i en vy.
- Använd tidsväljaren för att ändra tidsintervallet (standard: senaste 24 timmarna).
- Använd Lägg till filter och Använd delning för mått som har dimensioner.
- Välj Fäst på instrumentpanelen för att lägga till diagramkonfigurationen på instrumentpanelerna så att du kan visa den igen.
- Ange Ny aviseringsregel för att visualisera dina mått med hjälp av de angivna kriterierna. Den nya aviseringsregeln omfattar din målresurs, måttet, delnings- och filterdimensionerna från diagrammet. Ändra de här inställningarna i skapandepanelen för aviseringsregel .
Övervaka Azure Data Explorer-inmatning, kommandon, frågor och tabeller med hjälp av diagnostikloggar
Azure Data Explorer är en snabb, fullständigt hanterad dataanalystjänst för realtidsanalys på stora mängder dataströmning från program, webbplatser, IoT-enheter med mera. Azure Monitor-resursloggar innehåller data om driften av Azure-resurser. Azure Data Explorer använder diagnostikloggar för insikter om inmatning, kommandon, frågor och tabeller. Du kan exportera åtgärdsloggar till Azure Storage, händelsehubben eller Log Analytics för att övervaka inmatning, kommandon och frågestatus. Loggar från Azure Storage och Azure Event Hubs kan dirigeras till en tabell i ditt Azure Data Explorer-kluster för ytterligare analys.
Viktig
Diagnostikloggdata kan innehålla känsliga data. Begränsa behörigheter för loggdestinationen enligt dina övervakningsbehov.
Not
På Azure-portalen lagras rådata för sidorna Metrics och Insights i Azure Monitor. Frågeställningarna på dessa sidor hämtar rådata för metriker direkt för att tillhandahålla de mest exakta resultaten. När du använder diagnostikinställningsfunktionen kan du migrera råmetrikdata till Log Analytics-arbetsytan. Under migreringen kan viss dataprecision gå förlorad på grund av avrundning. Därför kan frågeresultaten variera något från de ursprungliga data. Felmarginalen är mindre än en procent.
Du kan använda diagnostikloggar för att konfigurera insamlingen av följande loggdata:
Not
- Inmatningsloggar stöder köad inmatning till Data ingestion URI med Kusto-klientbibliotek och dataanslutningar.
- Inmatningsloggar stöder inte strömmande inmatning, direkt inmatning till kluster-URI, inmatning från fråga eller
.set-or-appendkommandon.
Not
Misslyckade inmatningsloggar rapporterar endast det slutliga tillståndet för en inmatningsåtgärd, till skillnad från inmatningsresultatmåttet , som genereras för tillfälliga fel som görs om internt.
- Lyckade inmatningsåtgärder: Dessa loggar innehåller information om slutförda inmatningsåtgärder.
- Misslyckade inmatningsåtgärder: Dessa loggar innehåller detaljerad information om misslyckade inmatningsåtgärder, inklusive felinformation.
- Batchbearbetningsåtgärder för inmatning: Dessa loggar innehåller detaljerad statistik över batchar som är redo för inmatning, till exempel varaktighet, batchstorlek, antal blobbar och batchbearbetningstyper).
Du kan skicka loggdata till en Log Analytics-arbetsyta, ett lagringskonto eller strömma dem till en händelsehubb.
Diagnostikloggar är inaktiverade som standard. Använd följande steg för att aktivera diagnostikloggar för klustret:
I Azure-portalenväljer du den klusterresurs som du vill övervaka.
Under Övervakningväljer du Diagnostikinställningar.
Välj Lägg till diagnostikinställning.
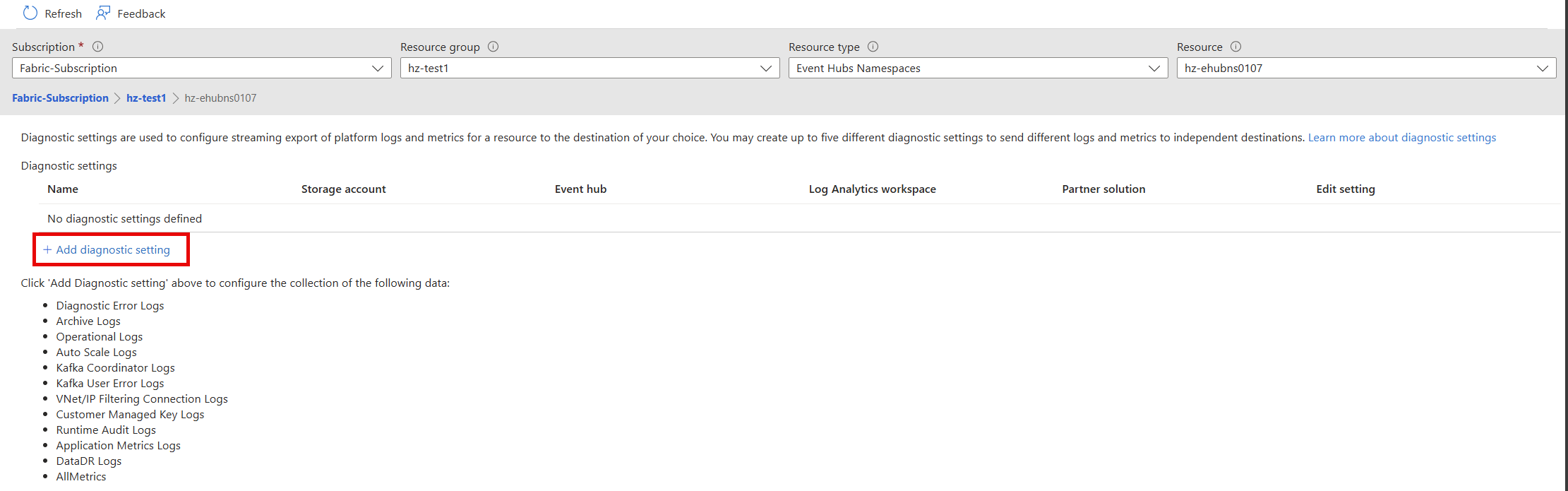
I fönstret Diagnostikinställningar:
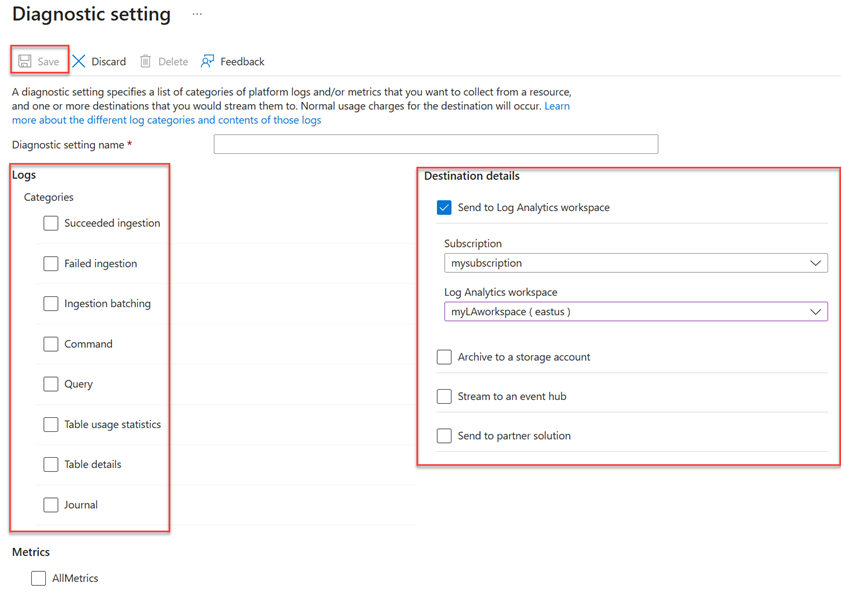
- Ange ett namn för Diagnostikinställning.
- Välj ett eller flera mål: en Log Analytics-arbetsyta, ett lagringskonto eller en händelsehubb.
- Välj loggar att samla in: Slutförd inmatning, Misslyckad inmatning, Inmatningsbatching, Kommando, Fråga, Tabellanvändningsstatistik, Tabellinformation eller Journal.
- Välj mått som ska samlas in (valfritt).
- Välj Spara för att spara de nya inställningarna och måtten för diagnostikloggar.



När du har skapat inställningarna börjar loggarna visas i de konfigurerade målmålen: ett lagringskonto, en händelsehubb eller Log Analytics-arbetsyta.
Not
Om du skickar loggar till en Log Analytics-arbetsyta lagras loggarna SucceededIngestion, FailedIngestion, IngestionBatching, Command, Query, TableUsageStatistics, TableDetailsoch Journal i Log Analytics-tabeller med namnet: SucceededIngestion, FailedIngestion, ADXIngestionBatching, ADXCommand, ADXQuery, ADXTableUsageStatistics, ADXTableDetailsoch ADXJournal.
Använda Azure Monitor-verktyg för att analysera data
Dessa Azure Monitor-verktyg är tillgängliga i Azure-portalen för att hjälpa dig att analysera övervakningsdata:
Vissa Azure-tjänster har en inbyggd instrumentpanel för övervakning i Azure-portalen. Dessa instrumentpaneler kallas insikteroch du hittar dem i avsnittet insikter i Azure Monitor på Azure-portalen.
Metrics Explorer kan du visa och analysera mått för Azure-resurser. Mer information finns i Analysera mått med Azure Monitor-måttutforskaren.
Med Log Analytics kan du söka och analysera loggdata med hjälp av Kusto-frågespråk (KQL). Mer information finns i Komma igång med loggfrågor i Azure Monitor.
Azure-portalen har ett användargränssnitt för visning och grundläggande sökningar i aktivitetsloggen. Om du vill göra mer djupgående analys dirigerar du data till Azure Monitor-loggar och kör mer komplexa frågor i Log Analytics.
Application Insights övervakar tillgänglighet, prestanda och användning av dina webbprogram, så att du kan identifiera och diagnostisera fel utan att vänta på att en användare ska rapportera dem.
Application Insights innehåller anslutningspunkter till olika utvecklingsverktyg och integreras med Visual Studio för att stödja dina DevOps-processer. Mer information finns i Programövervakning för App Service.
Verktyg som möjliggör mer komplex visualisering är:
- Dashboard som gör att du kan kombinera olika typer av data på en enda panel i Azure-portalen.
- arbetsböcker, anpassningsbara rapporter som du kan skapa i Azure-portalen. Arbetsböcker kan innehålla text-, mått- och loggfrågor.
- Grafana, ett öppet plattformsverktyg som utmärker sig i driftinstrumentpaneler. Du kan använda Grafana för att skapa instrumentpaneler som innehåller data från flera andra källor än Azure Monitor.
- Power BI, en företagsanalystjänst som tillhandahåller interaktiva visualiseringar mellan olika datakällor. Du kan konfigurera Power BI för att automatiskt importera loggdata från Azure Monitor för att dra nytta av dessa visualiseringar.
Exportera Azure Monitor-data
Du kan exportera data från Azure Monitor till andra verktyg med hjälp av:
Mått: Använd REST API för att extrahera mätdata från Azure Monitor-måttdatabasen. Mer information finns i REST API-referens för Azure Monitor.
Loggar: Använd REST-API:et eller de associerade klientbiblioteken.
Dataexporten för Log Analytics-arbetsytan.
Information om hur du kommer igång med REST-API:t för Azure Monitor finns i guide för REST API för Azure Monitor.
Använda Kusto-frågor för att analysera loggdata
Du kan analysera Azure Monitor-loggdata med hjälp av Kusto-frågespråket (KQL). Mer information finns i Loggfrågor i Azure Monitor.
Använda Azure Monitor-aviseringar för att meddela dig om problem
Azure Monitor-aviseringar gör att du kan identifiera och åtgärda problem i systemet och meddela dig proaktivt när specifika villkor finns i dina övervakningsdata innan kunderna märker dem. Du kan avisera om valfritt mått eller loggdatakälla på Azure Monitor-dataplattformen. Det finns olika typer av Azure Monitor-aviseringar beroende på vilka tjänster du övervakar och vilka övervakningsdata du samlar in. Se Välja rätt typ av aviseringsregel.
Exempel på vanliga aviseringar för Azure-resurser finns i Exempelloggaviseringsfrågor.
Implementera aviseringar i stor skala
För vissa tjänster kan du övervaka i stor skala genom att tillämpa samma måttaviseringsregel på flera resurser av samma typ som finns i samma Azure-region. Azure Monitor Baseline Alerts (AMBA) tillhandahåller en halvautomatiserad metod för att implementera viktiga plattformsmåttaviseringar, instrumentpaneler och riktlinjer i stor skala.
Få anpassade rekommendationer med Hjälp av Azure Advisor
För vissa tjänster, om kritiska villkor eller överhängande ändringar inträffar under resursåtgärder, visas en avisering på sidan Översikt i portalen. Du hittar mer information och rekommenderade korrigeringar för aviseringen i Advisor-rekommendationer under Övervakning i den vänstra menyn. Under normal drift visas inga advisor-rekommendationer.
Mer information om Azure Advisor finns i Översikt över Azure Advisor.