Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
När du har skapat och felsökt dataflödet vill du schemalägga att dataflödet ska köras enligt ett schema inom ramen för en pipeline. Du kan schemalägga pipelinen med utlösare. För att testa och felsöka dataflödet från en pipeline kan du använda felsökningsknappen i menyfliksområdet i verktygsfältet eller alternativet Utlösa nu från Pipeline Builder för att köra en körning med en körning för att testa dataflödet i pipelinekontexten.
När du kör din pipeline kan du övervaka pipelinen och alla aktiviteter som finns i pipelinen, inklusive Dataflöde-aktiviteten. Välj övervakningsikonen i den vänstra användargränssnittspanelen. Du kan se en skärm som liknar den som följer. Med de markerade ikonerna kan du öka detaljnivån för aktiviteterna i pipelinen, inklusive aktiviteten Dataflöde.
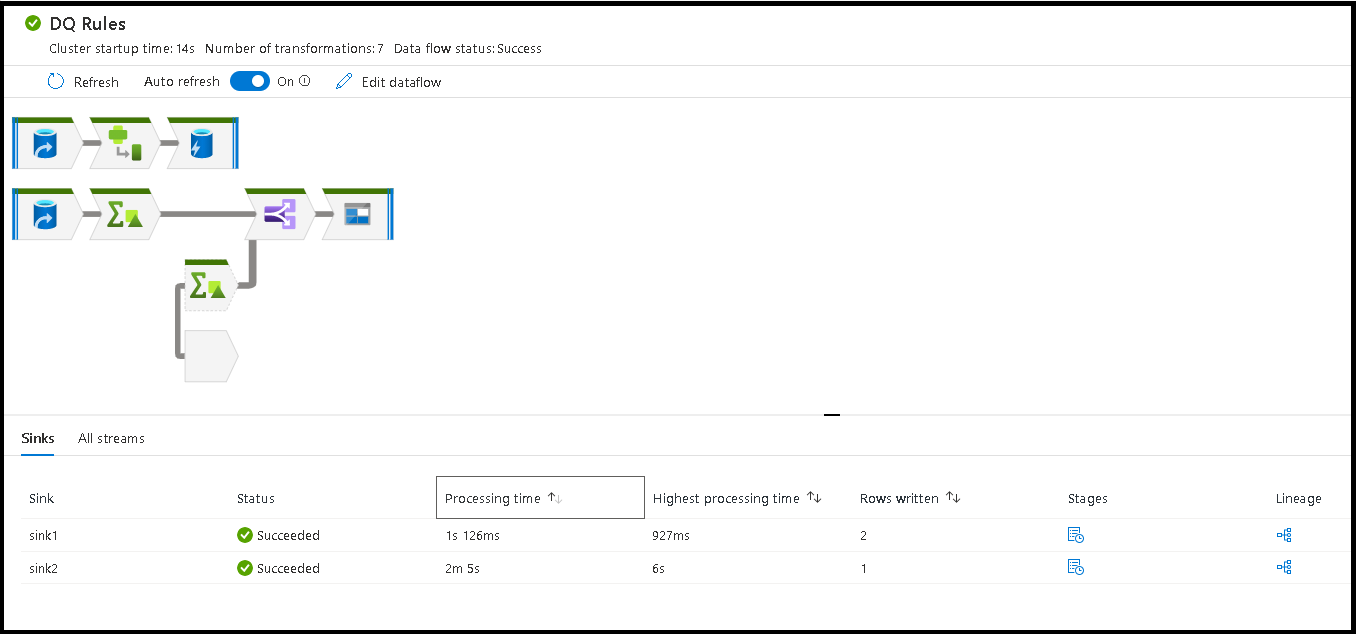
Du ser statistik på den här nivån samt körningstider och status. Körnings-ID på aktivitetsnivå skiljer sig från körnings-ID:t på pipelinenivå. Körnings-ID:t på föregående nivå är för pipelinen. Genom att välja glasögon får du detaljerad information om dataflödeskörningen.

När du är i den grafiska nodövervakningsvyn kan du se en förenklad vyversion av dataflödesdiagrammet. Om du vill se informationsvyn med större grafnoder som innehåller omvandlingsstegsetiketter använder du zoomreglaget till höger på arbetsytan. Du kan också använda sökknappen till höger för att hitta delar av dataflödeslogik i diagrammet.
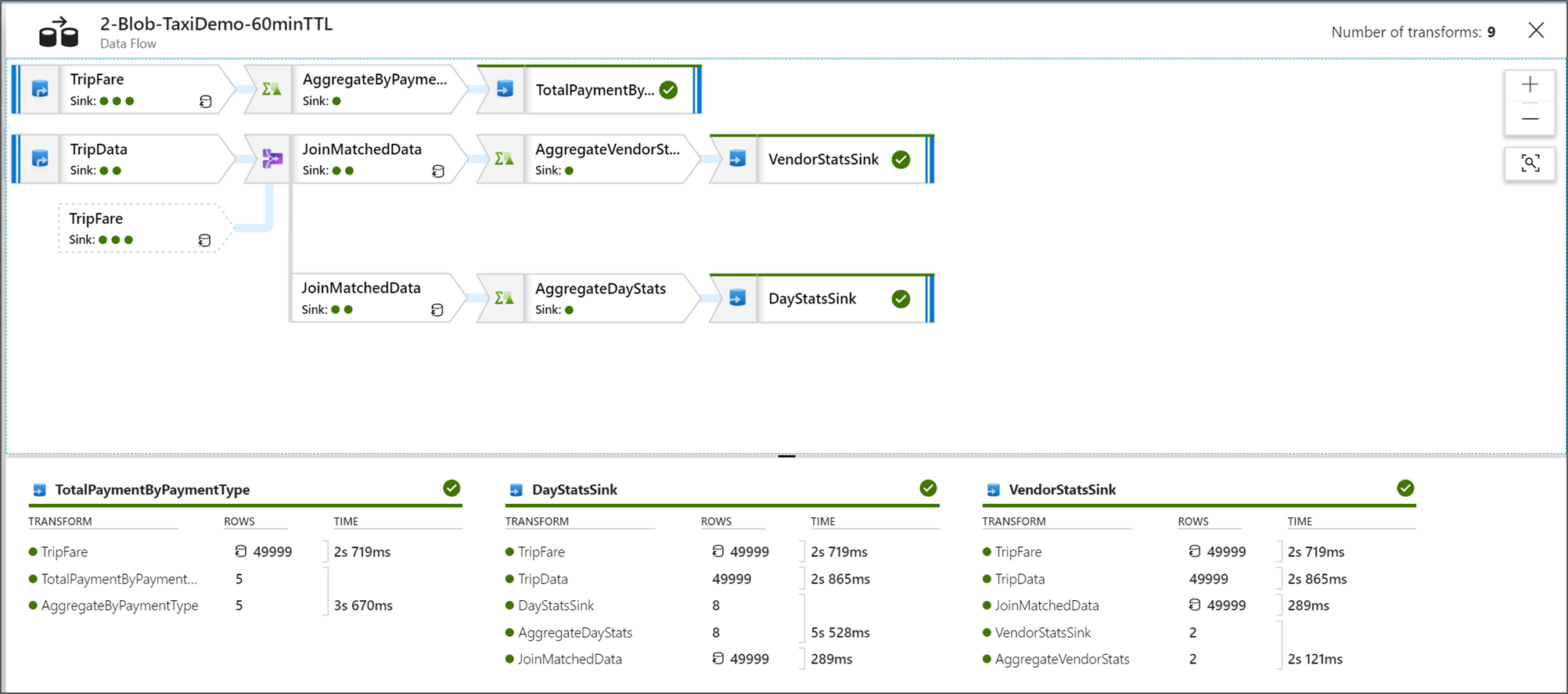
Visa Dataflöde körningsplaner
När din Dataflöde körs i Spark avgör tjänsten optimala kodsökvägar baserat på hela dataflödet. Dessutom kan körningssökvägarna inträffa på olika skalbara noder och datapartitioner. Övervakningsdiagrammet representerar därför designen av ditt flöde, med hänsyn till körningssökvägen för dina omvandlingar. När du väljer enskilda noder kan du se "faser" som representerar kod som kördes tillsammans i klustret. De tidsinställningar och antal som du ser representerar dessa grupper eller faser i stället för de enskilda stegen i din design.
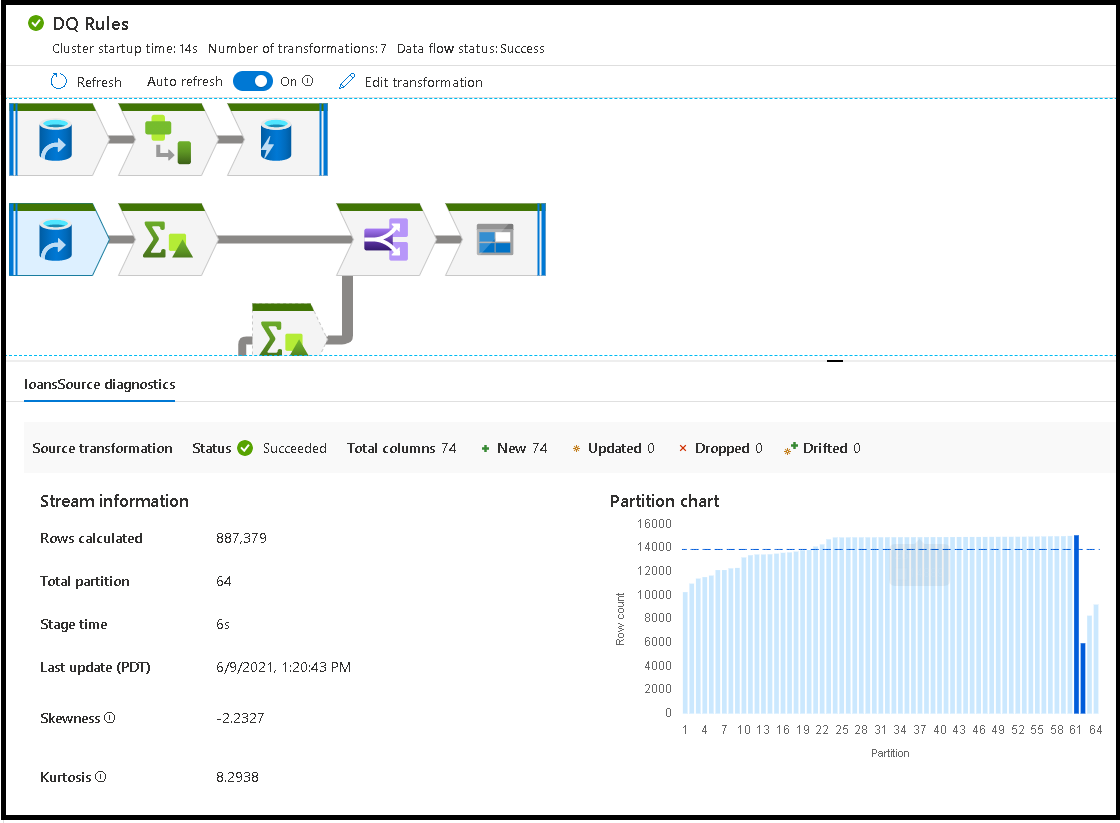
När du väljer det öppna utrymmet i övervakningsfönstret visar statistiken i det nedre fönstret tidsintervall och radantal för varje mottagare och transformeringar som ledde till mottagardata för omvandlings härkomst.
När du väljer enskilda transformeringar får du extra feedback på den högra panelen som visar partitionsstatistik, kolumnantal, skevhet (hur jämnt är data fördelat över partitioner) och kurtos (hur spetsiga är data).
Genom att sortera efter bearbetningstid kan du identifiera vilka steg i dataflödet som tog mest tid.
Om du vill ta reda på vilka transformeringar i varje fas som tog mest tid sorterar du efter högsta bearbetningstid.
De *rader som skrivs kan också sorteras som ett sätt att identifiera vilka strömmar i dataflödet som skriver mest data.
När du väljer mottagare i nodvyn kan du se kolumnraden. Det finns tre olika metoder som kolumner ackumuleras i hela dataflödet för att landa i mottagare. Dessa är:
- Beräknad: Du använder kolumnen för villkorsstyrd bearbetning eller i ett uttryck i dataflödet, men landar den inte i mottagare
- Härledd: Kolumnen är en ny kolumn som du genererade i ditt flöde, det vill sa att den inte fanns i källan
- Mappad: Kolumnen kommer från källan och du mappar den till ett mottagarfält
- Dataflödesstatus: Den aktuella statusen för körningen
- Starttid för kluster: Hur lång tid det tar att hämta JIT Spark-beräkningsmiljön för dataflödeskörningen
- Antal transformeringar: Hur många transformeringssteg som körs i ditt flöde

Total bearbetningstid för mottagare jämfört med bearbetningstid för transformering
Varje transformeringssteg innehåller en total tid för den fasen att slutföras med varje partitionskörningstid som summeras tillsammans. När du väljer mottagare visas "Handfatbearbetningstid". Den här gången inkluderar den totala omvandlingstiden plus den I/O-tid det tog att skriva dina data till mållagret. Skillnaden mellan bearbetningstiden för mottagare och summan av omvandlingen är I/O-tiden för att skriva data.
Du kan också se detaljerad tidsinställning för varje steg för partitionstransformering om du öppnar JSON-utdata från dataflödesaktiviteten i pipelineövervakningsvyn. JSON innehåller millisekunders timing för varje partition, medan UX-övervakningsvyn är en aggregerad tidsinställning för partitioner som läggs till tillsammans:
{
"stage": 4,
"partitionTimes": [
14353,
14914,
14246,
14912,
...
]
}
Bearbetningstid för mottagare
När du väljer en transformeringsikon för mottagare på kartan visar bildpanelen till höger en extra datapunkt med namnet "efter bearbetningstid" längst ned. Det här är den tid som ägnas åt att köra jobbet i Spark-klustret efter att dina data har lästs in, transformerats och skrivits. Den här gången kan omfatta stängning av anslutningspooler, avstängning av drivrutin, borttagning av filer, sammankoppling av filer osv. När du utför åtgärder i ditt flöde som "flytta filer" och "utdata till en enskild fil" ser du sannolikt en ökning av tidsvärdet efter bearbetningen.
- Varaktighet för skrivfasen: Tiden det går att skriva data till en mellanlagringsplats för Synapse SQL
- Sql-varaktighet för tabellåtgärd: Den tid som ägnas åt att flytta data från temporära tabeller till måltabellen
- Varaktighet före SQL och efter SQL-varaktighet: Den tid som ägnas åt att köra SQL-kommandon före/efter
- Varaktighet före kommandon & efter kommandon: Den tid som ägnas åt att köra eventuella åtgärder före/efter för filbaserad källa/mottagare. Till exempel flytta eller ta bort filer efter bearbetning.
- Varaktighet för sammanslagning: Den tid det tar att slå samman filen, sammanslagningsfiler används för filbaserade mottagare när du skriver till en enskild fil eller när "Filnamn som kolumndata" används. Om betydande tid spenderas i det här måttet bör du undvika att använda dessa alternativ.
- Fastid: Total tid i Spark för att slutföra åtgärden som en fas.
- Tillfälligt mellanlagringsstabilt: Namnet på den temporära tabell som används av dataflöden för att mellanlagra data i databasen.
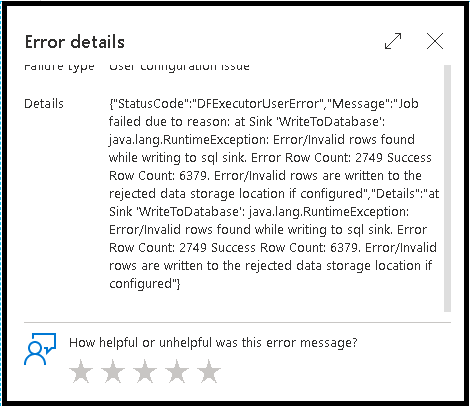
Felrader
Aktivering av felradshantering i dataflödesmottagaren återspeglas i övervakningsutdata. När du ställer in mottagaren på "rapportera lyckat fel" visar övervakningsutdata antalet lyckade och misslyckade rader när du väljer noden för övervakning av mottagare.
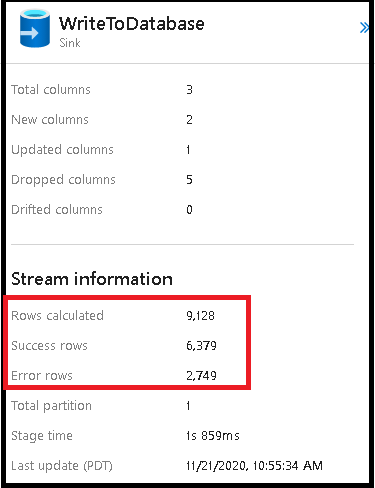
När du väljer "rapportfel vid fel" visas samma utdata endast i utdatatexten för aktivitetsövervakning. Det beror på att dataflödesaktiviteten returnerar fel vid körning och att den detaljerade övervakningsvyn inte är tillgänglig.
Övervakningsikoner
Den här ikonen innebär att transformeringsdata redan har cachelagrats i klustret, så tidsinställningar och körningssökväg har tagit hänsyn till detta:
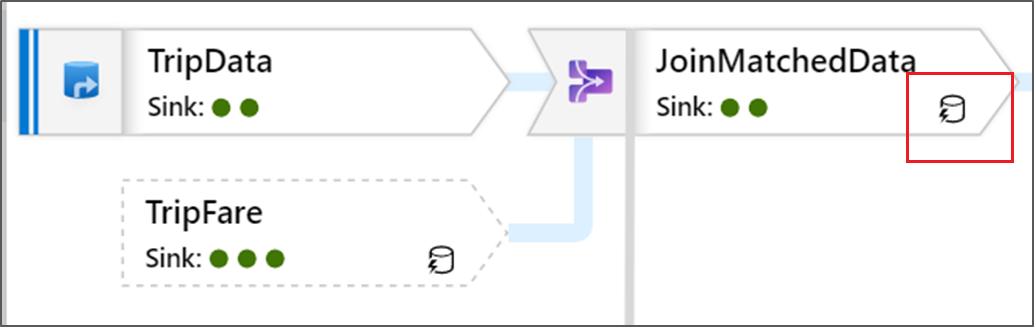
Du ser även gröna cirkelikoner i omvandlingen. De representerar antalet mottagare som data flödar in i.