Skapa storskaliga datakopieringspipelines med metadatadriven metod i verktyget kopiera data
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
När du vill kopiera stora mängder objekt (till exempel tusentals tabeller) eller läsa in data från många olika källor är det lämpligt att ange namnlistan för objekten med nödvändiga kopieringsbeteenden i en kontrolltabell och sedan använda parametriserade pipelines för att läsa samma från kontrolltabellen och tillämpa dem på jobben i enlighet därmed. På så sätt kan du underhålla (till exempel lägga till/ta bort) objektlistan som ska kopieras enkelt genom att bara uppdatera objektnamnen i kontrolltabellen i stället för att distribuera om pipelines. Dessutom har du en enda plats för att enkelt kontrollera vilka objekt som kopieras med vilka pipelines/utlösare med definierade kopieringsbeteenden.
Verktyget Kopiera data i ADF underlättar processen med att skapa sådana metadatadrivna datakopieringspipelines. När du har genomgått ett intuitivt flöde från en guidebaserad upplevelse kan verktyget generera parametriserade pipelines och SQL-skript så att du kan skapa externa kontrolltabeller i enlighet med detta. När du har kört de genererade skripten för att skapa kontrolltabellen i SQL-databasen läser dina pipelines metadata från kontrolltabellen och tillämpar dem automatiskt på kopieringsjobben.
Skapa metadatadrivna kopieringsjobb från verktyget kopiera data
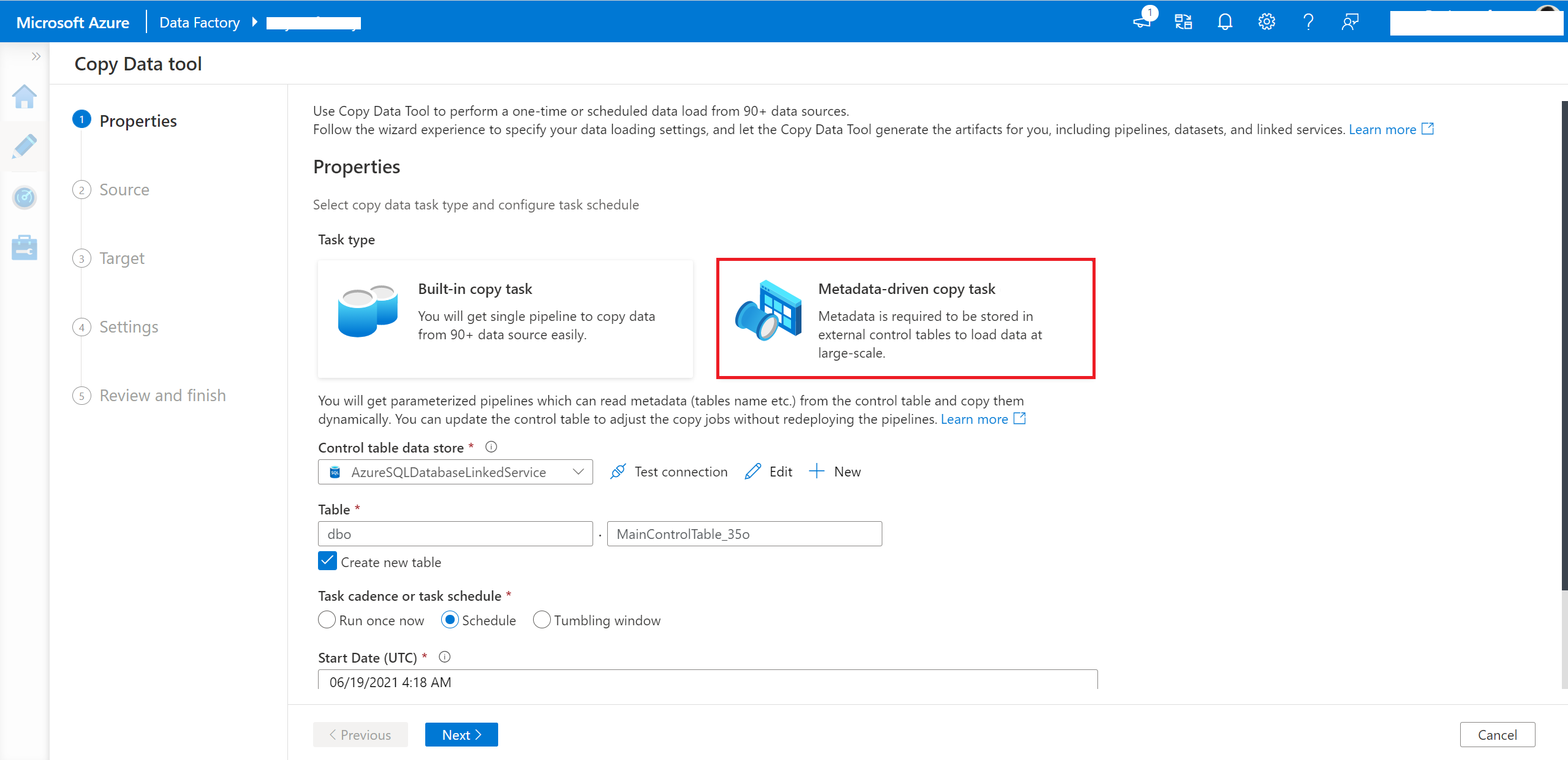
Välj Metadatadriven kopieringsaktivitet i verktyget kopiera data.
Du måste ange anslutnings- och tabellnamnet för kontrolltabellen, så att den genererade pipelinen läser metadata från den.
Ange anslutningen för källdatabasen. Du kan också använda parametriserad länkad tjänst .
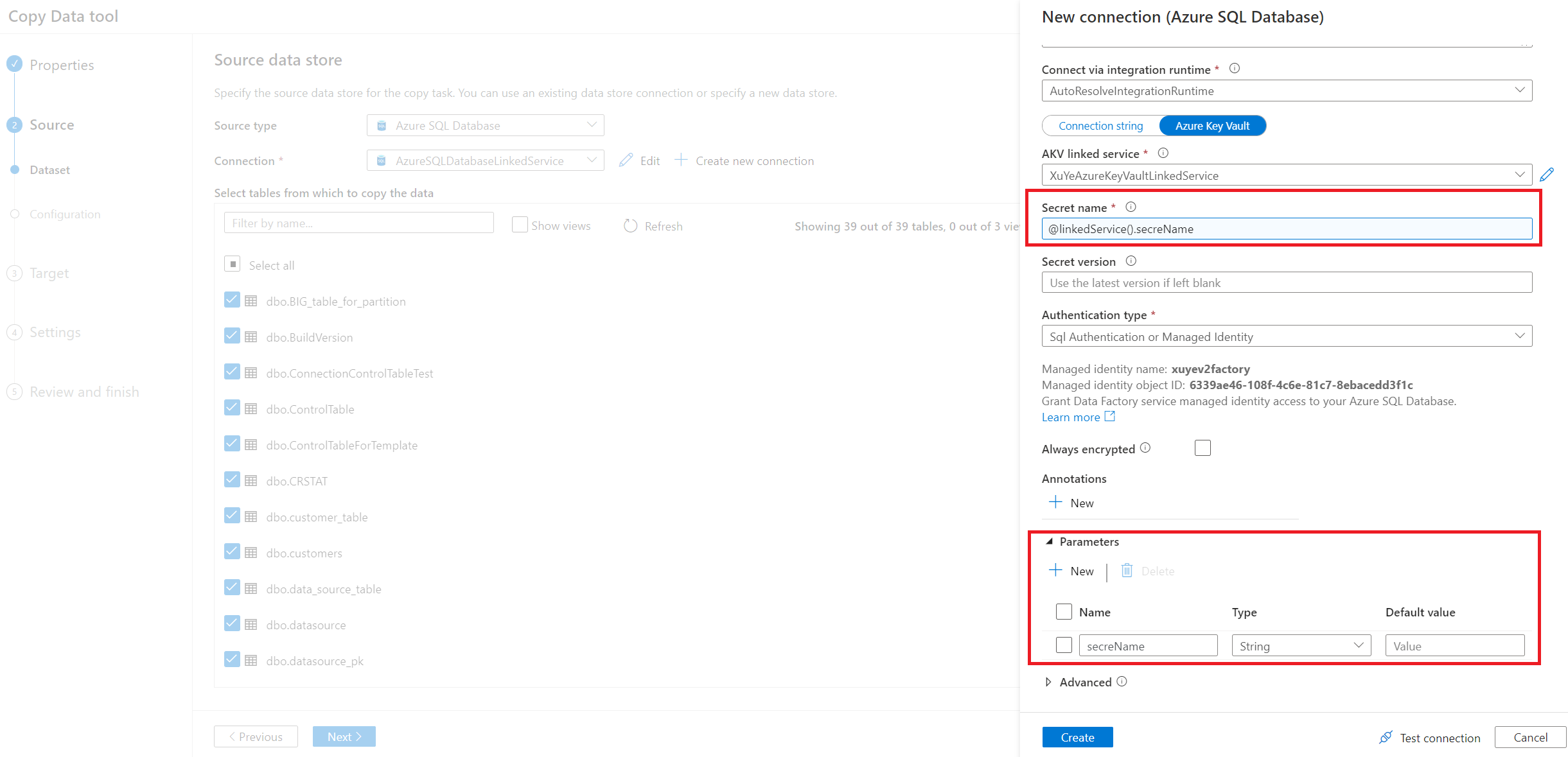
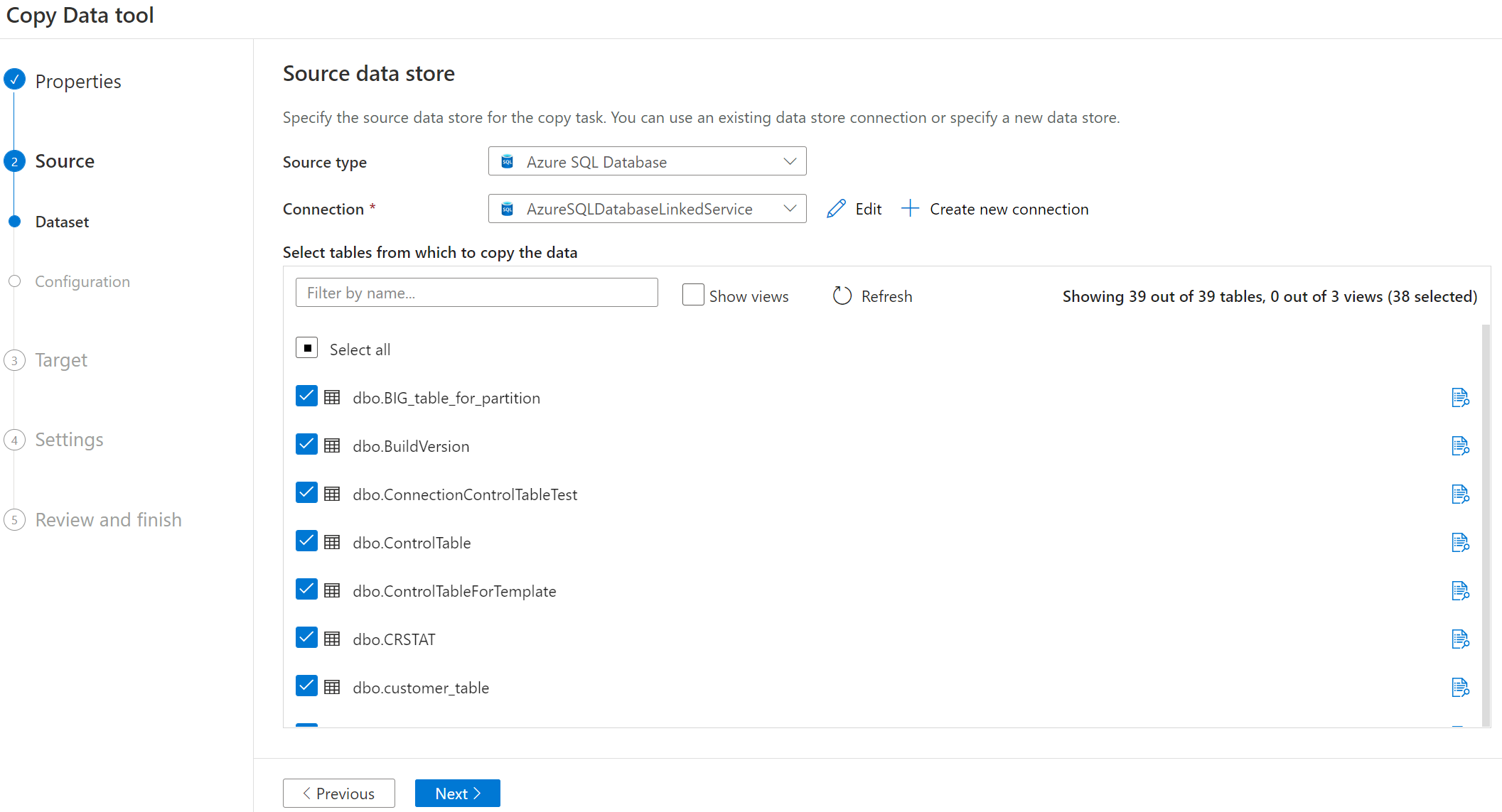
Välj det tabellnamn som ska kopieras.
Kommentar
Om du väljer tabelldatalager kan du välja antingen fullständig belastning eller deltainläsning på nästa sida. Om du väljer lagringslager kan du välja fullständig belastning ytterligare på nästa sida. Inkrementell inläsning av nya filer från lagringsarkivet stöds för närvarande inte.
Välj inläsningsbeteende.
Dricks
Om du vill göra en fullständig kopia av alla tabeller väljer du Fullständig inläsning av alla tabeller. Om du vill göra inkrementell kopiering kan du välja konfigurera för varje tabell individuellt och välja Deltainläsning samt kolumnnamn och värde för vattenstämpeln som ska startas för varje tabell.
Välj Måldatalager.
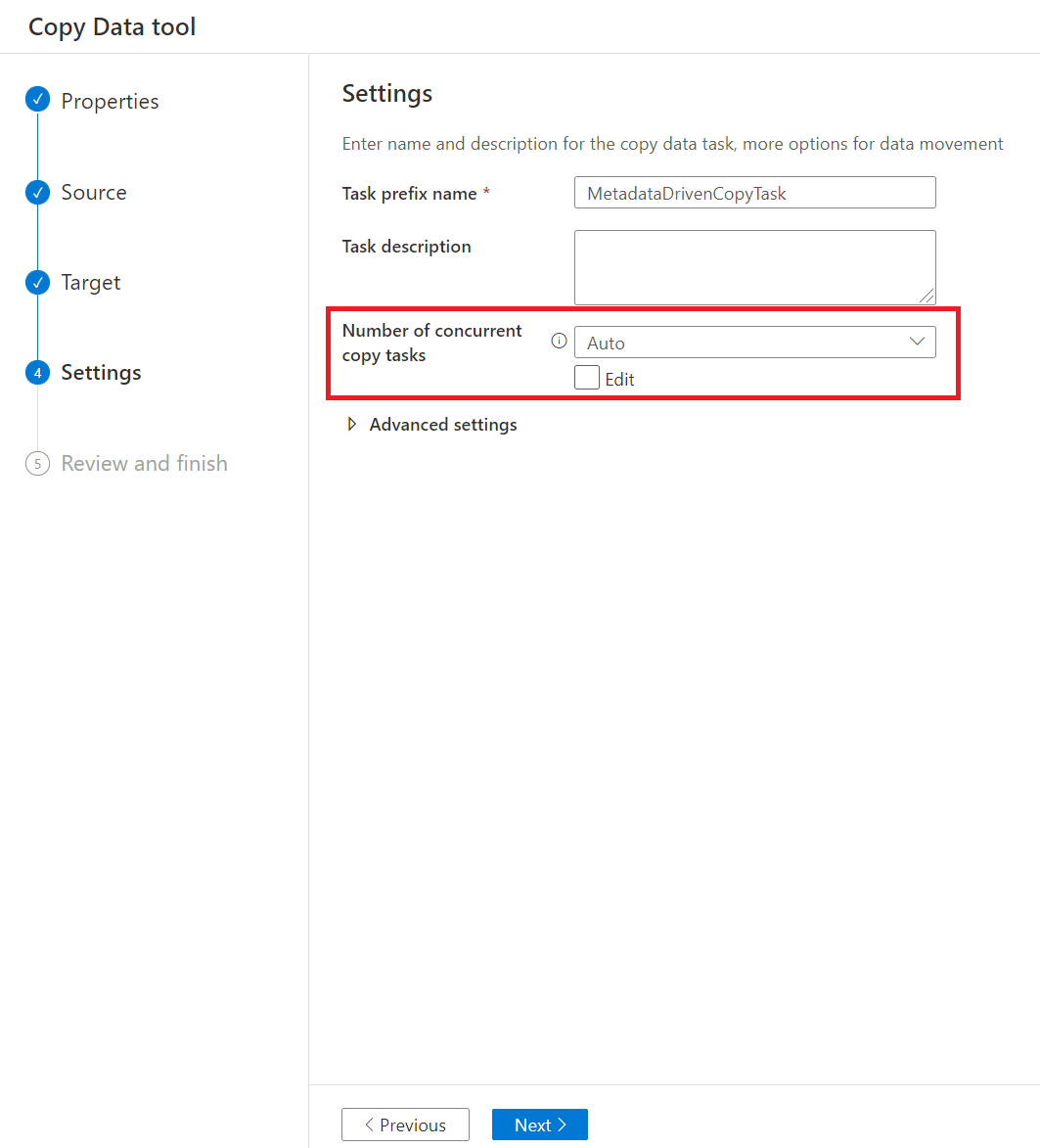
På sidan Inställningar kan du bestämma det maximala antalet kopieringsaktiviteter för att kopiera data från källarkivet samtidigt via Antal samtidiga kopieringsuppgifter. Standardvärdet är 20.
Efter pipelinedistributionen kan du kopiera eller ladda ned SQL-skripten från användargränssnittet för att skapa kontrolltabell och lagringsprocedur.
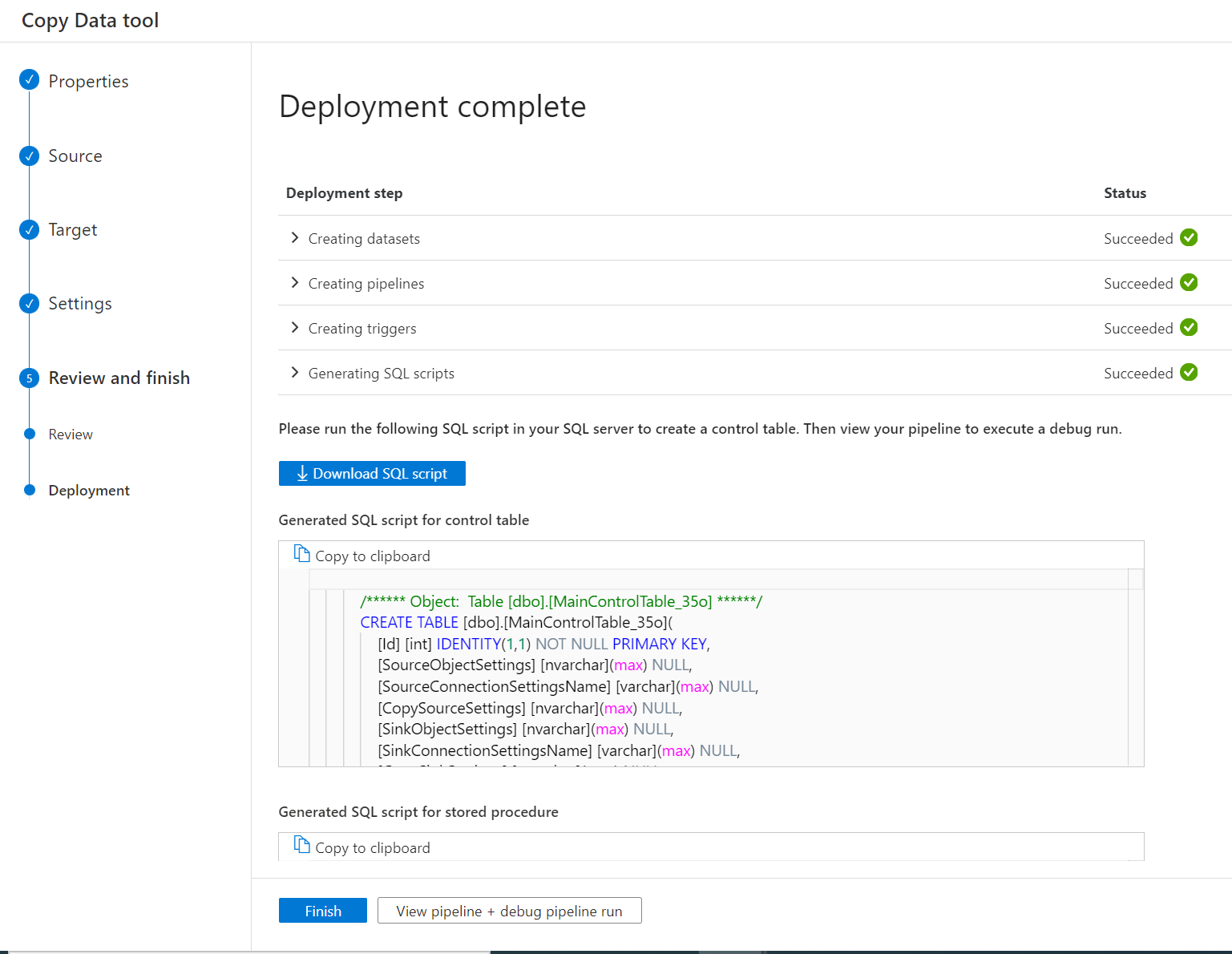
Två SQL-skript visas.
- Det första SQL-skriptet används för att skapa två kontrolltabeller. Huvudkontrolltabellen lagrar tabelllistan, filsökvägen eller kopieringsbeteenden. I anslutningskontrolltabellen lagras anslutningsvärdet för ditt datalager om du använde en parametriserad länkad tjänst.
- Det andra SQL-skriptet används för att skapa en lagringsprocedur. Den används för att uppdatera vattenstämpelvärdet i huvudkontrolltabellen när de inkrementella kopieringsjobben slutförs varje gång.
Öppna SSMS för att ansluta till kontrolltabellservern och kör de två SQL-skripten för att skapa kontrolltabeller och lagra proceduren.
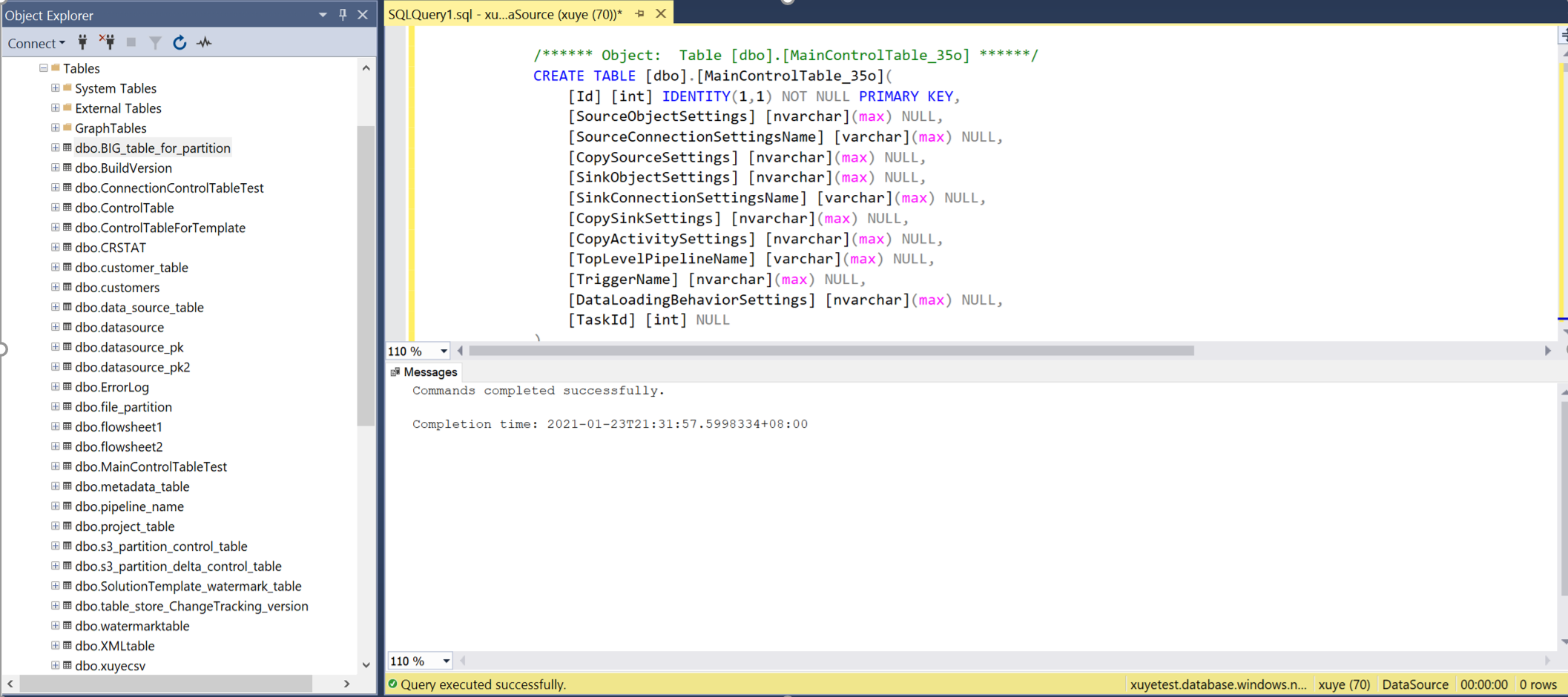
Fråga huvudkontrolltabellen och anslutningskontrolltabellen för att granska metadata i den.
Huvudkontrolltabell
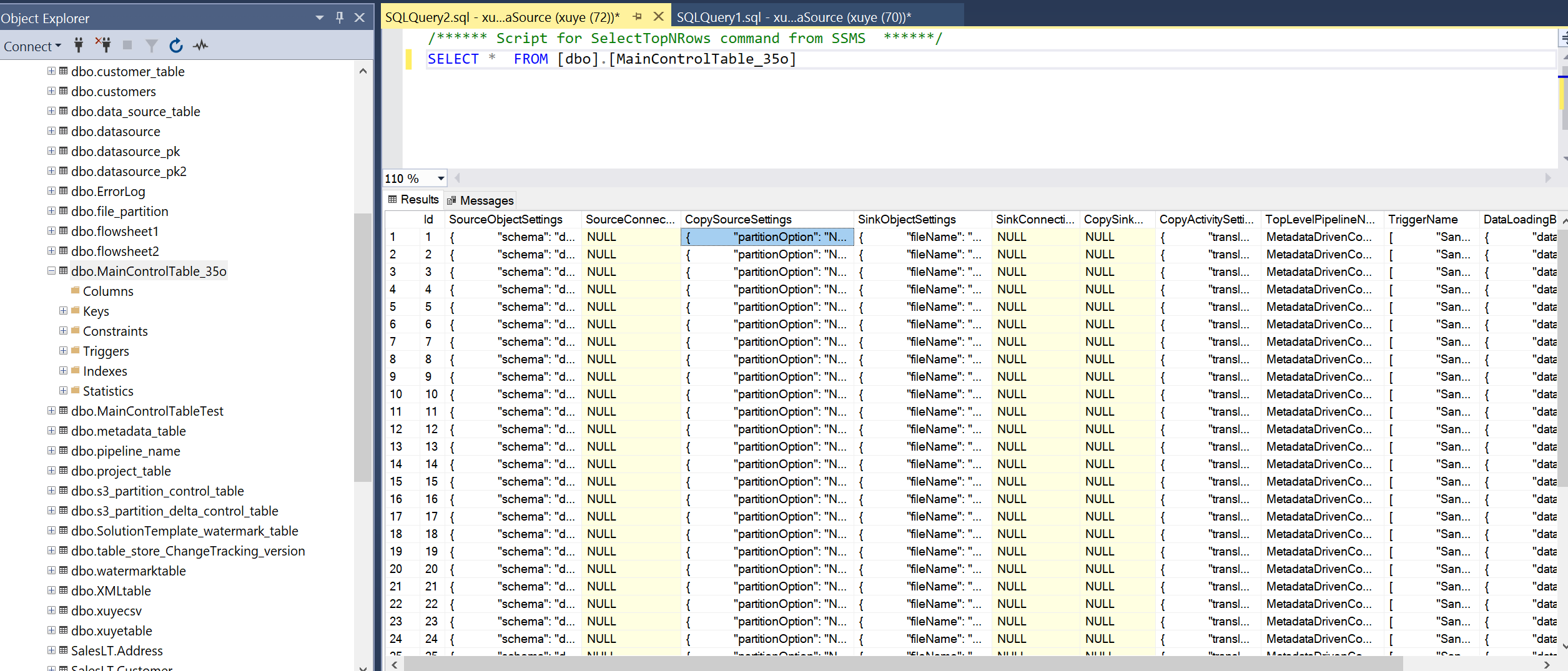
Tabell för anslutningskontroll

Gå tillbaka till ADF-portalen för att visa och felsöka pipelines. En mapp skapas med namnet "MetadataDrivenCopyTask_##########". Klicka på pipelinenamngivningen med "MetadataDrivenCopyTask###_TopLevel" och klicka på Felsökningskörning.
Du måste ange följande parametrar:
Namn på parametrar beskrivning MaxNumberOfConcurrentTasks Du kan alltid ändra det maximala antalet samtidiga kopieringsaktiviteter som körs innan pipelinekörningen. Standardvärdet är det som du anger i verktyget kopiera data. MainControlTableName Du kan alltid ändra huvudnamnet för kontrolltabellen, så att pipelinen hämtar metadata från tabellen innan den körs. ConnectionControlTableName Du kan alltid ändra tabellnamnet för anslutningskontrollen (valfritt), så att pipelinen hämtar metadata relaterade till datalagringsanslutningen innan den körs. MaxNumberOfObjectsReturnedFromLookupActivity För att undvika att nå gränsen för uppslagsaktiviteten för utdata finns det ett sätt att definiera det maximala antalet objekt som returneras av uppslagsaktiviteten. I de flesta fall krävs inte standardvärdet för att ändras. windowStart När du anger dynamiskt värde (till exempel åååå/mm/dd) som mappsökväg används parametern för att skicka den aktuella utlösartiden till pipelinen för att fylla sökvägen för den dynamiska mappen. När pipelinen utlöses av schemautlösare eller rullande windows-utlösare behöver användarna inte ange värdet för den här parametern. Exempelvärde: 2021-01-25T01:49:28Z Aktivera utlösaren för att operationalisera pipelines.
Uppdatera kontrolltabellen genom att kopiera dataverktyget
Du kan alltid uppdatera kontrolltabellen direkt genom att lägga till eller ta bort objektet som ska kopieras eller ändra kopieringsbeteendet för varje tabell. Vi skapar även användargränssnittsupplevelse i verktyget för kopieringsdata för att underlätta redigeringen av kontrolltabellen.
Högerklicka på pipelinen på den översta nivån: MetadataDrivenCopyTask_xxx_TopLevel och välj sedan Redigera kontrolltabell.
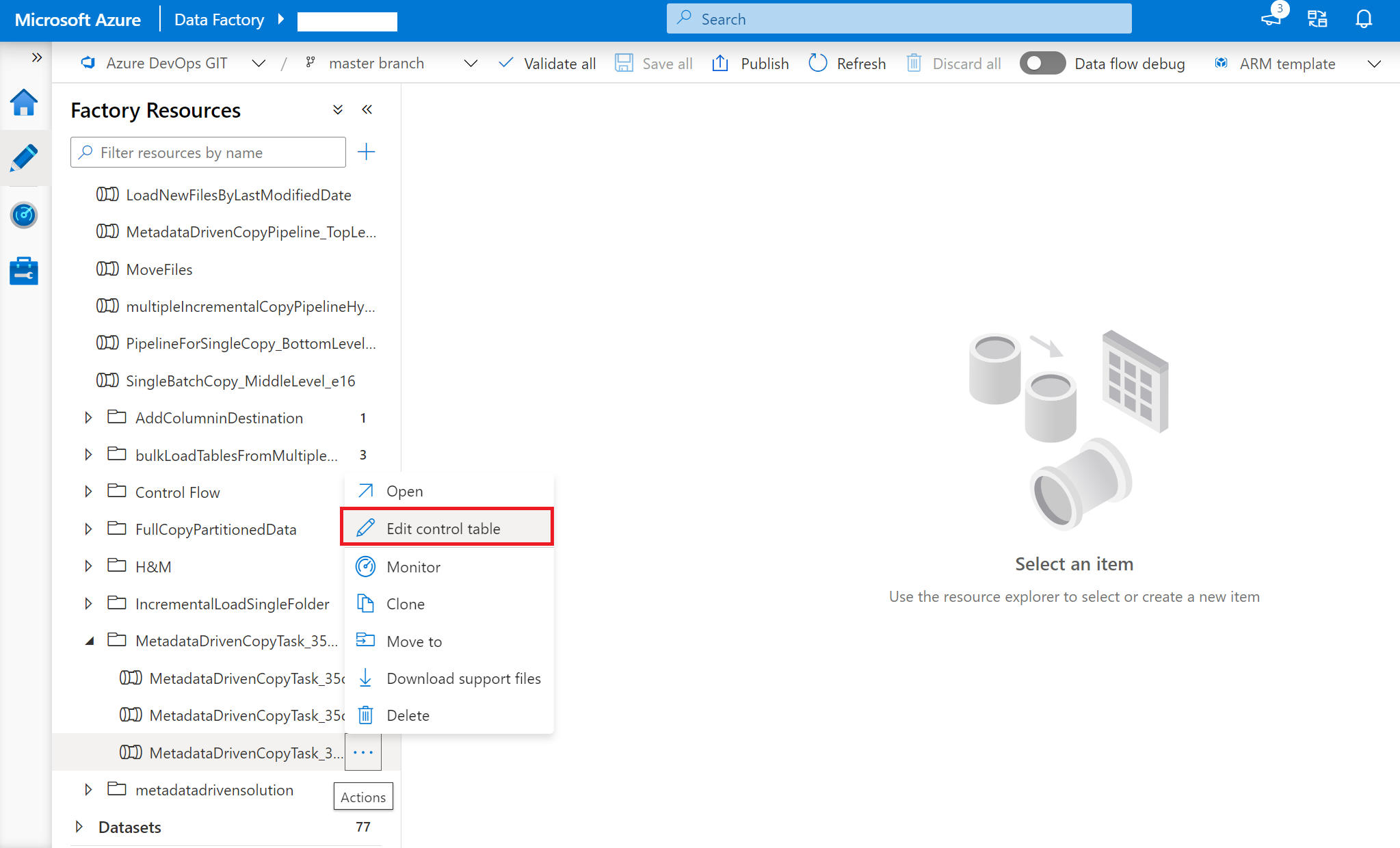
Välj rader från kontrolltabellen som ska redigeras.
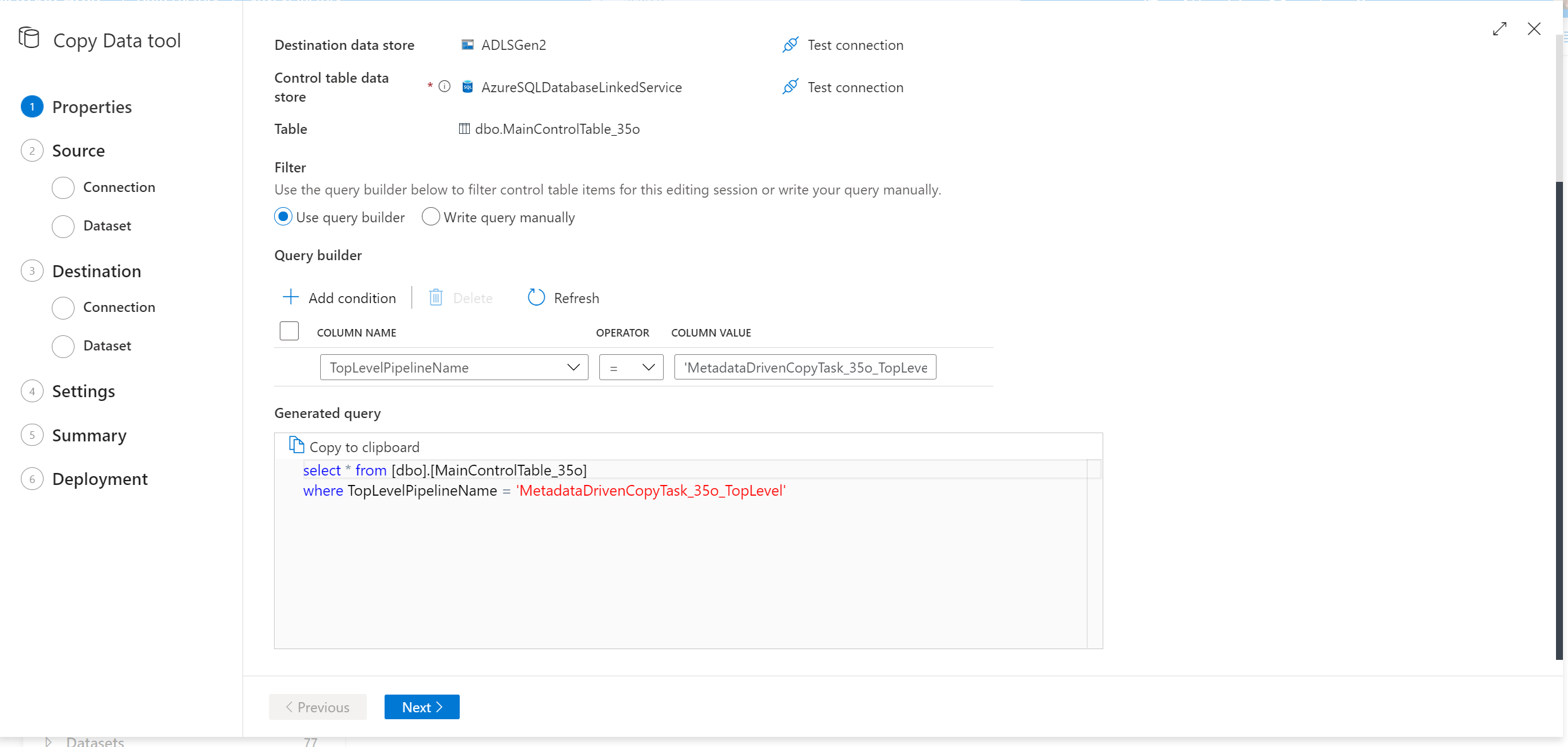
Gå igenom dataflödet för verktyget för kopieringsdata så kommer det att komma med ett nytt SQL-skript åt dig. Kör SQL-skriptet igen för att uppdatera kontrolltabellen.
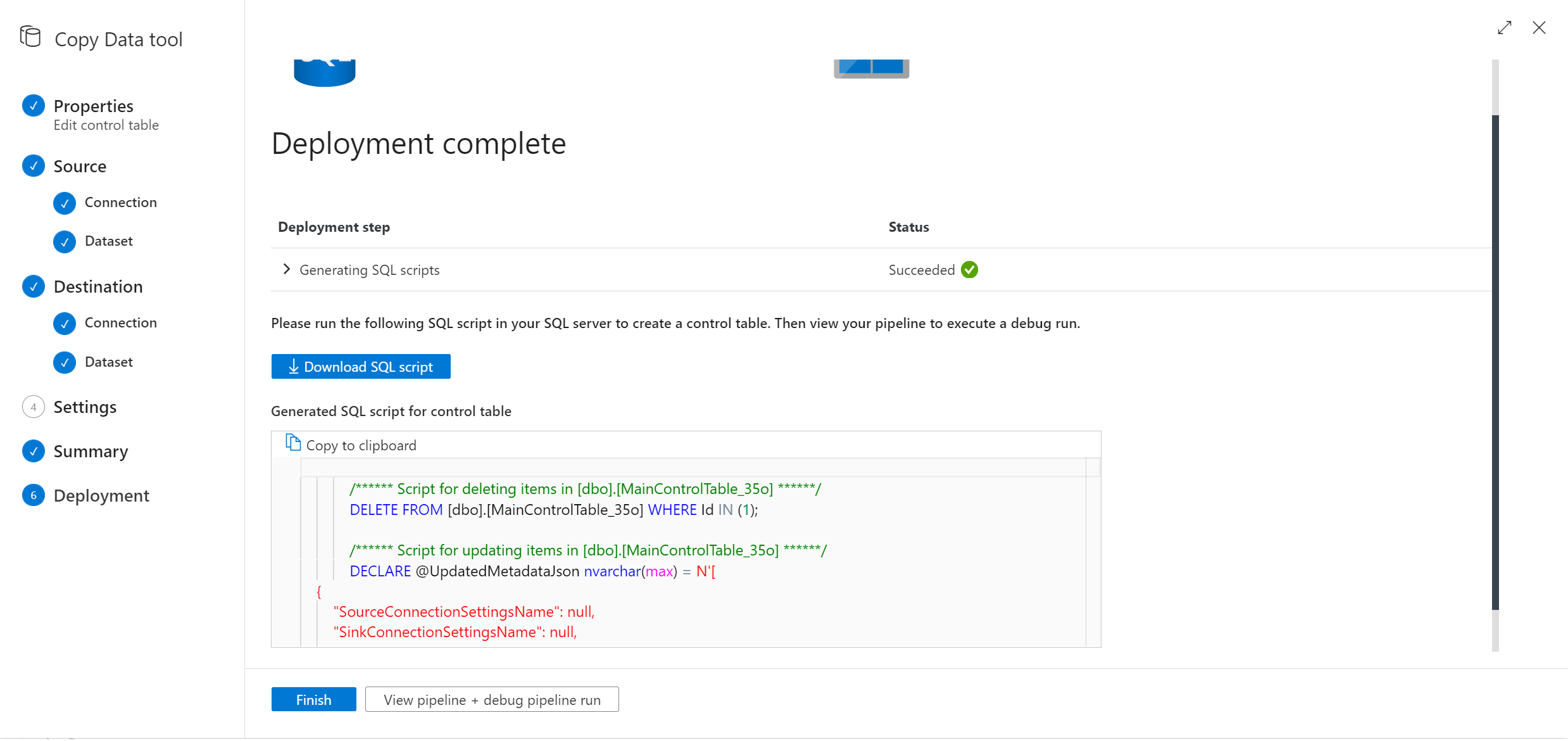
Kommentar
Pipelinen distribueras INTE om. Med det nya SQL-skriptet kan du endast uppdatera kontrolltabellen.
Kontrollera tabeller
Huvudkontrolltabell
Varje rad i kontrolltabellen innehåller metadata för ett objekt (till exempel en tabell) som ska kopieras.
| Kolumnnamn | Beskrivning |
|---|---|
| ID | Unikt ID för det objekt som ska kopieras. |
| SourceObjectSettings | Metadata för källdatauppsättningen. Det kan vara schemanamn, tabellnamn osv. Här är ett exempel. |
| SourceConnectionSettingsName | Namnet på källanslutningsinställningen i anslutningskontrolltabellen. Det är valfritt. |
| CopySourceSettings | Metadata för källegenskapen i kopieringsaktiviteten. Det kan vara fråga, partitioner osv. Här är ett exempel. |
| SinkObjectSettings | Metadata för måldatauppsättningen. Det kan vara filnamn, mappsökväg, tabellnamn osv. Här är ett exempel. Om dynamisk mappsökväg anges skrivs inte variabelvärdet här i kontrolltabellen. |
| SinkConnectionSettingsName | Namnet på målanslutningsinställningen i anslutningskontrolltabellen. Det är valfritt. |
| CopySinkSettings | Metadata för mottagaregenskapen i kopieringsaktiviteten. Det kan vara preCopyScript, tableOption osv. Här är ett exempel. |
| CopyActivitySettings | Metadata för translator-egenskapen i kopieringsaktivitet. Den används för att definiera kolumnmappning. |
| TopLevelPipelineName | Det översta pipelinenamnet, som kan kopiera det här objektet. |
| TriggerName | Utlösarnamn, som kan utlösa pipelinen för att kopiera det här objektet. Om felsökningen körs är namnet Sandbox. Om manuell körning är namnet Manuell. Om schemalagd körning är namnet det associerade utlösarnamnet. Det kan vara indata för flera namn. |
| DataLoadingBehaviorSettings | Fullständig belastning jämfört med deltabelastning. |
| TaskId | Ordningen på objekt som ska kopieras efter TaskId i kontrolltabellen (ORDER BY [TaskId] DESC). Om du har stora mängder objekt som ska kopieras men endast begränsat antal samtidiga kopierade tillåtna objekt kan du ändra TaskId för varje objekt för att bestämma vilka objekt som kan kopieras tidigare. Standardvärdet är 0. |
| CopyEnabled | Ange om objektet är aktiverat i datainmatningsprocessen. Tillåtna värden: 1 (aktiverad), 0 (inaktiverad). Standardvärdet är 1. |
Tabell för anslutningskontroll
Varje rad i kontrolltabellen innehåller en anslutningsinställning för datalagret.
| Kolumnnamn | beskrivning |
|---|---|
| Name | Namnet på den parametriserade anslutningen i huvudkontrolltabellen. |
| AnslutningarInställningar | Anslutningsinställningarna. Det kan vara db-namn, servernamn och så vidare. |
Pipelines
Du ser att tre nivåer av pipelines genereras av verktyget kopiera data.
MetadataDrivenCopyTask_xxx_TopLevel
Den här pipelinen beräknar det totala antalet objekt (tabeller osv.) som krävs för att kopieras i den här körningen, kommer med antalet sekventiella batchar baserat på den maximala tillåtna samtidiga kopieringsaktiviteten och kör sedan en annan pipeline för att kopiera olika batchar sekventiellt.
Parametrar
| Namn på parametrar | beskrivning |
|---|---|
| MaxNumberOfConcurrentTasks | Du kan alltid ändra det maximala antalet samtidiga kopieringsaktiviteter som körs innan pipelinekörningen. Standardvärdet är det som du anger i verktyget kopiera data. |
| MainControlTableName | Tabellnamnet för huvudkontrolltabellen. Pipelinen hämtar metadata från den här tabellen innan den körs |
| ConnectionControlTableName | Tabellnamnet för anslutningskontrolltabellen (valfritt). Pipelinen hämtar metadata relaterade till datalagringsanslutningen före körning |
| MaxNumberOfObjectsReturnedFromLookupActivity | För att undvika att nå gränsen för uppslagsaktiviteten för utdata finns det ett sätt att definiera det maximala antalet objekt som returneras av uppslagsaktiviteten. I de flesta fall krävs inte standardvärdet för att ändras. |
| windowStart | När du anger dynamiskt värde (till exempel åååå/mm/dd) som mappsökväg används parametern för att skicka den aktuella utlösartiden till pipelinen för att fylla sökvägen för den dynamiska mappen. När pipelinen utlöses av schemautlösare eller rullande windows-utlösare behöver användarna inte ange värdet för den här parametern. Exempelvärde: 2021-01-25T01:49:28Z |
Aktiviteter
| Aktivitetsnamn | Aktivitetstyp | beskrivning |
|---|---|---|
| GetSumOfObjectsToCopy | Sökning | Beräkna det totala antalet objekt (tabeller osv.) som krävs för att kopieras i den här körningen. |
| CopyBatchesOfObjectsSequentially | ForEach | Kom fram till antalet sekventiella batchar baserat på maximalt tillåtna samtidiga kopieringsuppgifter och kör sedan en annan pipeline för att kopiera olika batchar sekventiellt. |
| CopyObjectsInOneBtach | Kör pipeline | Kör en annan pipeline för att kopiera en batch med objekt. Objekten som tillhör den här batchen kopieras parallellt. |
MetadataDrivenCopyTask_xxx_ Mellannivå
Den här pipelinen kopierar en batch med objekt. Objekten som tillhör den här batchen kopieras parallellt.
Parametrar
| Namn på parametrar | beskrivning |
|---|---|
| MaxNumberOfObjectsReturnedFromLookupActivity | För att undvika att nå gränsen för uppslagsaktiviteten för utdata finns det ett sätt att definiera det maximala antalet objekt som returneras av uppslagsaktiviteten. I de flesta fall krävs inte standardvärdet för att ändras. |
| TopLevelPipelineName | Namnet på den översta lagerpipelinen. |
| TriggerName | Namnet på utlösaren. |
| CurrentSequentialNumberOfBatch | ID för sekventiell batch. |
| SumOfObjectsToCopy | Det totala antalet objekt som ska kopieras. |
| SumOfObjectsToCopyForCurrentBatch | Antalet objekt som ska kopieras i den aktuella batchen. |
| MainControlTableName | Namnet på huvudkontrolltabellen. |
| ConnectionControlTableName | Namnet på anslutningskontrolltabellen. |
Aktiviteter
| Aktivitetsnamn | Aktivitetstyp | beskrivning |
|---|---|---|
| DivideOneBatchIntoMultipleGroups | ForEach | Dela upp objekt från en batch i flera parallella grupper för att undvika att nå utdatagränsen för uppslagsaktivitet. |
| GetObjectsPerGroupToCopy | Sökning | Hämta objekt (tabeller osv.) från kontrolltabellen som krävs för att kopieras i den här gruppen. Ordningen på objekt som ska kopieras efter TaskId i kontrolltabellen (ORDER BY [TaskId] DESC). |
| CopyObjectsInOneGroup | Kör pipeline | Kör en annan pipeline för att kopiera objekt från en grupp. Objekten som tillhör den här gruppen kopieras parallellt. |
MetadataDrivenCopyTask_xxx_ BottomLevel
Den här pipelinen kopierar objekt från en grupp. Objekten som tillhör den här gruppen kopieras parallellt.
Parametrar
| Namn på parametrar | beskrivning |
|---|---|
| ObjectsPerGroupToCopy | Antalet objekt som ska kopieras i den aktuella gruppen. |
| ConnectionControlTableName | Namnet på anslutningskontrolltabellen. |
| windowStart | Den använde för att skicka den aktuella utlösartiden till pipelinen för att fylla sökvägen för den dynamiska mappen om den konfigurerades av användaren. |
Aktiviteter
| Aktivitetsnamn | Aktivitetstyp | beskrivning |
|---|---|---|
| ListObjectsFromOneGroup | ForEach | Lista objekt från en grupp och iterera var och en av dem till underordnade aktiviteter. |
| RouteJobsBasedOnLoadingBehavior | Växling | Kontrollera inläsningsbeteendet för varje objekt. Om det är standard- eller FullLoad-skiftläge utför du full belastning. Om det är DeltaLoad-fall utför du inkrementell belastning via vattenstämpelkolumnen för att identifiera ändringar |
| FullLoadOneObject | Kopiera | Ta en fullständig ögonblicksbild av det här objektet och kopiera det till målet. |
| DeltaLoadOneObject | Kopiera | Kopiera endast ändrade data från förra gången genom att jämföra värdet i vattenstämpelkolumnen för att identifiera ändringar. |
| GetMaxWatermarkValue | Sökning | Fråga källobjektet för att hämta maxvärdet från vattenstämpelkolumnen. |
| UpdateWatermarkColumnValue | StoreProcedure | Skriv tillbaka det nya vattenstämpelvärdet för att styra tabellen som ska användas nästa gång. |
Kända begränsningar
- IR-namn, databastyp, filformattyp kan inte parametriseras i ADF. Om du till exempel vill mata in data från både Oracle Server och SQL Server behöver du två olika parametriserade pipelines. Men den enskilda kontrolltabellen kan delas av två uppsättningar pipelines.
- OPENJSON används i genererade SQL-skript genom att kopiera dataverktyget. Om du använder SQL Server som värd för kontrolltabellen måste det vara SQL Server 2016 (13.x) och senare för att stödja funktionen OPENJSON.
Relaterat innehåll
Prova de här självstudierna som använder verktyget Kopiera data:
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för