Ändra radtransformering i dataflödesmappning
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Dataflöden är tillgängliga både i Azure Data Factory och Azure Synapse Pipelines. Den här artikeln gäller för mappning av dataflöden. Om du är nybörjare på transformeringar kan du läsa den inledande artikeln Transformera data med hjälp av ett mappningsdataflöde.
Använd transformeringen Alter Row för att ange principer för infoga, ta bort, uppdatera och upsert på rader. Du kan lägga till ett-till-många-villkor som uttryck. Dessa villkor bör anges i prioritetsordning, eftersom varje rad markeras med principen som motsvarar det första matchande uttrycket. Vart och ett av dessa villkor kan resultera i att en rad (eller rader) infogas, uppdateras, tas bort eller uppgraderas. Alter Row kan generera både DDL- och DML-åtgärder mot databasen.
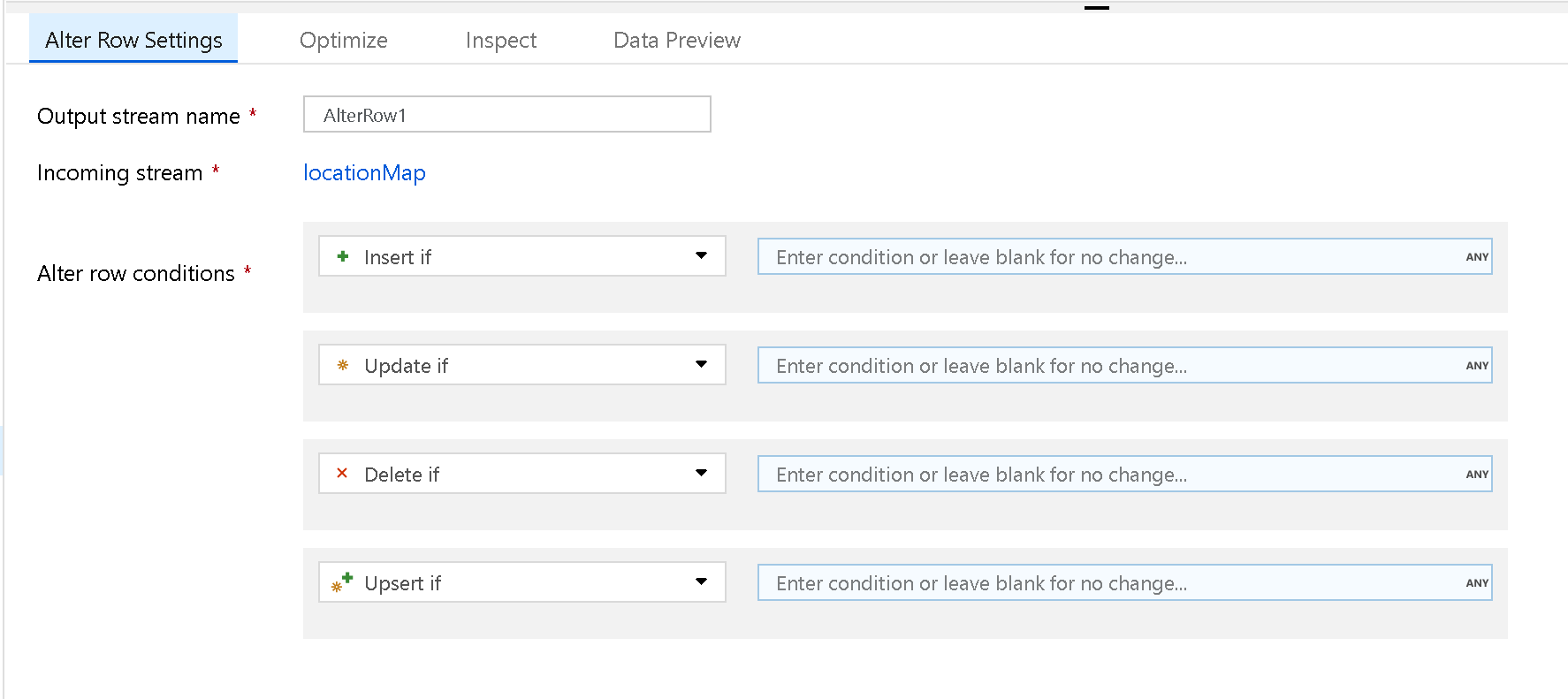
Ändra radtransformeringar fungerar endast på databas-, REST- eller Azure Cosmos DB-mottagare i ditt dataflöde. De åtgärder som du tilldelar rader (infoga, uppdatera, ta bort, upsert) sker inte under felsökningssessioner. Kör en Körning av dataflödesaktivitet i en pipeline för att implementera ändringsradsprinciperna i databastabellerna.
Kommentar
En Alter Row-transformering behövs inte för dataflöden för ändringsdatainsamling som använder inbyggda CDC-källor som SQL Server eller SAP. I dessa fall identifierar ADF automatiskt radmarkören, så Alter Row-principer är onödiga.
Ange en standardprincip för rad
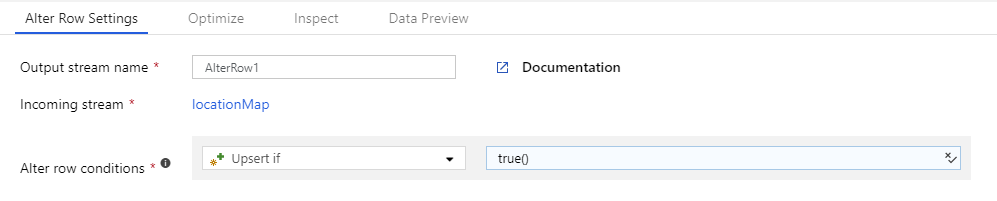
Skapa en Alter Row-transformering och ange en radprincip med villkoret true(). Varje rad som inte matchar något av de tidigare definierade uttrycken markeras för den angivna radprincipen. Som standard markeras varje rad som inte matchar något villkorsuttryck för Insert.
Kommentar
Om du vill markera alla rader med en princip kan du skapa ett villkor för principen och ange villkoret som true().
Visa principer i förhandsversionen av data
Använd felsökningsläget för att visa resultatet av dina alter row-principer i fönstret för förhandsgranskning av data. En dataförhandsvisning av en ändringsradtransformering genererar inte DDL- eller DML-åtgärder mot ditt mål.
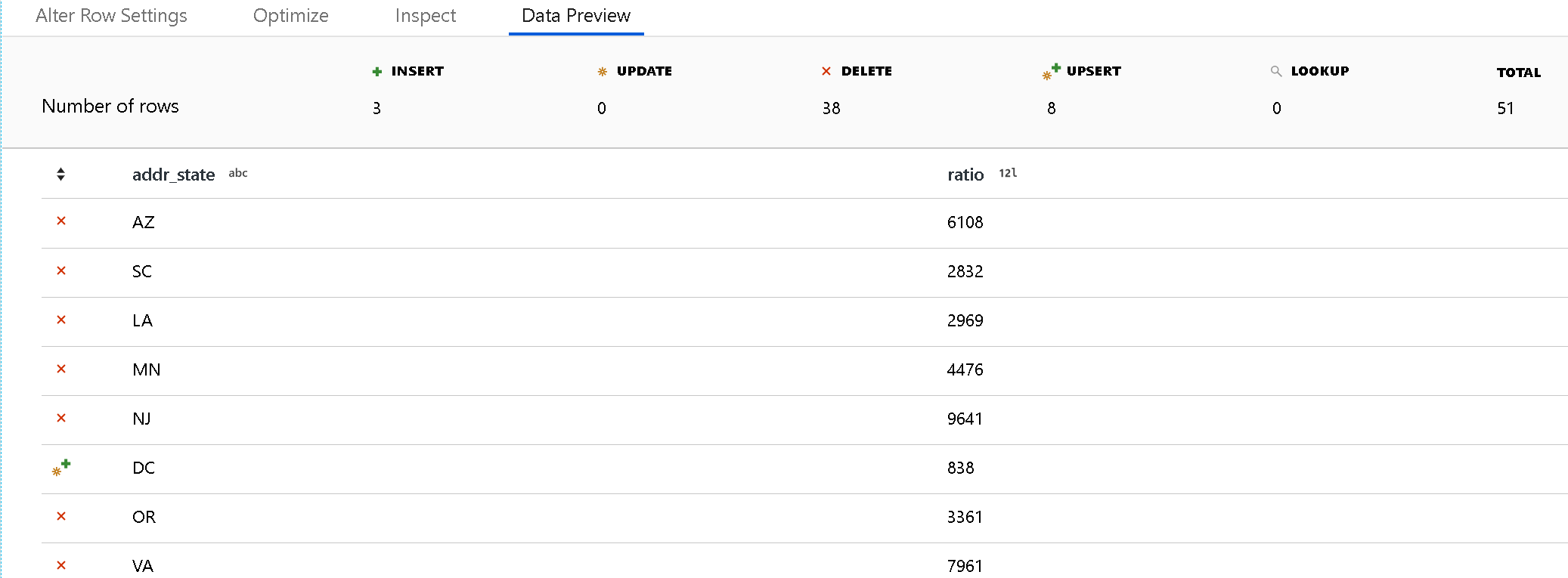
Varje ändringsradsprincip representeras av en ikon som anger om en infognings-, uppdaterings-, upsert- eller borttagen åtgärd ska utföras. Det översta huvudet visar hur många rader som påverkas av varje princip i förhandsversionen.
Tillåt ändring av radprinciper i mottagare
För att alter row-principerna ska fungera måste dataströmmen skriva till en databas eller En Azure Cosmos DB-mottagare. På fliken Inställningar i mottagaren aktiverar du vilka ändringsradsprinciper som tillåts för mottagaren.
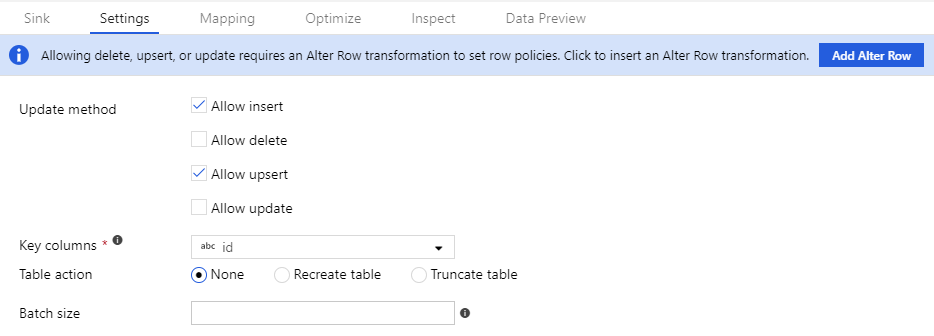
Standardbeteendet är att endast tillåta infogningar. Om du vill tillåta uppdateringar, upserts eller borttagningar markerar du kryssrutan i mottagaren som motsvarar det villkoret. Om uppdateringar, upserts eller borttagningar är aktiverade måste du ange vilka nyckelkolumner i mottagaren som ska matchas.
Kommentar
Om dina infogningar, uppdateringar eller upserts ändrar schemat för måltabellen i mottagaren misslyckas dataflödet. Om du vill ändra målschemat i databasen väljer du Återskapa tabell som tabellåtgärd. Detta släpper och återskapar tabellen med den nya schemadefinitionen.
Mottagartransformeringen kräver antingen en enskild nyckel eller en serie nycklar för unik radidentifiering i måldatabasen. För SQL-mottagare anger du nycklarna på fliken inställningar för mottagare. För Azure Cosmos DB anger du partitionsnyckeln i inställningarna och anger även azure Cosmos DB-systemfältet "id" i din mottagarmappning. För Azure Cosmos DB är det obligatoriskt att inkludera systemkolumnen "ID" för uppdateringar, upserts och borttagningar.
Sammanslagningar och upserts med Azure SQL Database och Azure Synapse
Dataflöden stöder sammanslagningar mot Azure SQL Database och Azure Synapse-databaspoolen (informationslager) med alternativet upsert.
Du kan dock stöta på scenarier där måldatabasschemat använde identitetsegenskapen för nyckelkolumner. Tjänsten kräver att du identifierar de nycklar som du ska använda för att matcha radvärdena för uppdateringar och upserts. Men om målkolumnen har angett identitetsegenskapen och du använder upsert-principen tillåter inte måldatabasen att du skriver till kolumnen. Du kan också stöta på fel när du försöker upsert mot en distribuerad tabells distributionskolumn.
Här är några sätt att åtgärda detta:
Gå till inställningar för sinktransformering och ange "Hoppa över att skriva nyckelkolumner". Då uppmanas tjänsten att inte skriva den kolumn som du har valt som nyckelvärde för din mappning.
Om nyckelkolumnen inte är den kolumn som orsakar problemet för identitetskolumner kan du använda sql-alternativet Förbearbetning av mottagartransformation:
SET IDENTITY_INSERT tbl_content ON. Stäng sedan av den med sql-egenskapen efter bearbetning:SET IDENTITY_INSERT tbl_content OFF.För både identitetsfallet och distributionskolumnfallet kan du växla logiken från Upsert till att använda ett separat uppdateringsvillkor och ett separat insert-villkor med hjälp av en transformering av villkorsstyrd delning. På så sätt kan du ange mappningen på uppdateringssökvägen för att ignorera nyckelkolumnmappningen.
Dataflödesskript
Syntax
<incomingStream>
alterRow(
insertIf(<condition>?),
updateIf(<condition>?),
deleteIf(<condition>?),
upsertIf(<condition>?),
) ~> <alterRowTransformationName>
Exempel
Exemplet nedan är en ändringsradtransformering med namnet CleanData som tar en inkommande ström SpecifyUpsertConditions och skapar tre ändringsradsvillkor. I den föregående omvandlingen beräknas en kolumn med namnet alterRowCondition som avgör om en rad infogas, uppdateras eller tas bort i databasen eller inte. Om värdet för kolumnen har ett strängvärde som matchar regeln alter row tilldelas den principen.
I användargränssnittet ser den här omvandlingen ut som bilden nedan:
Dataflödesskriptet för den här omvandlingen finns i kodfragmentet nedan:
SpecifyUpsertConditions alterRow(insertIf(alterRowCondition == 'insert'),
updateIf(alterRowCondition == 'update'),
deleteIf(alterRowCondition == 'delete')) ~> AlterRow
Relaterat innehåll
Efter alter row-omvandlingen kanske du vill sänka dina data till ett måldatalager.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för