Flödestransformering i mappning av dataflöde
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Dataflöden är tillgängliga både i Azure Data Factory och Azure Synapse Pipelines. Den här artikeln gäller för mappning av dataflöden. Om du är nybörjare på transformeringar kan du läsa den inledande artikeln Transformera data med hjälp av ett mappningsdataflöde.
Använd flödestransformeringen för att köra en tidigare skapad flödesflöde för mappningsdataflöde. En översikt över flödesflöden finns i Flowlets i mappning av dataflöde | Microsoft Docs
Kommentar
Flödestransformeringen i Azure Data Factory- och Synapse Analytics-pipelines är för närvarande i offentlig förhandsversion
Konfiguration
Flödestransformeringen innehåller följande konfigurationsinställningar
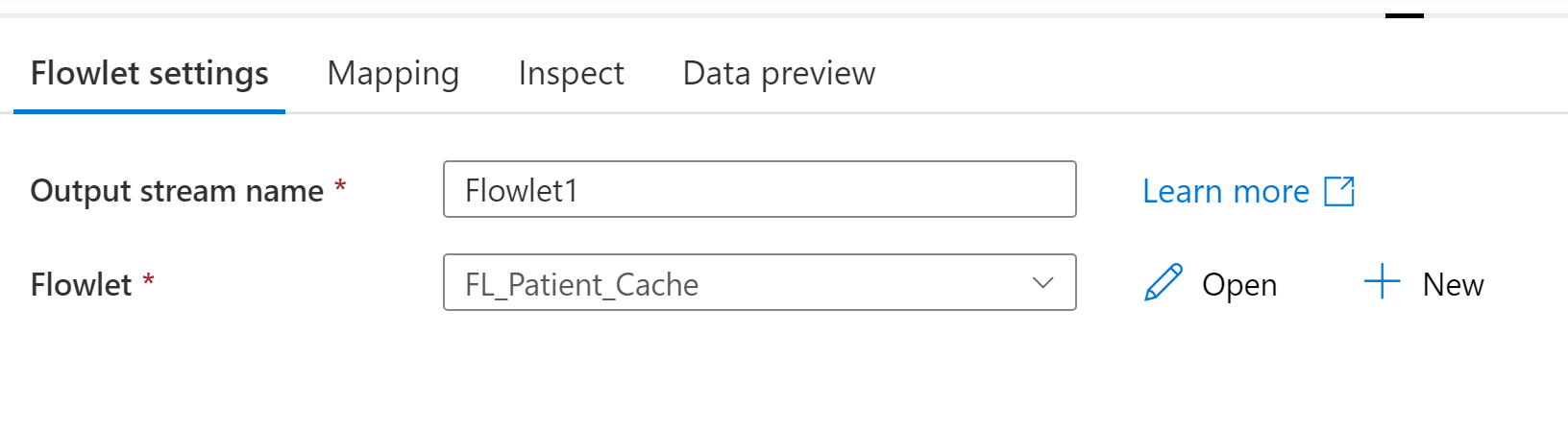
Flowlet
Välj den flowlet som ska köras. När flödesflödet har valts kan du mappa eventuella indatakolumner på mappningsfliken.
Mappning
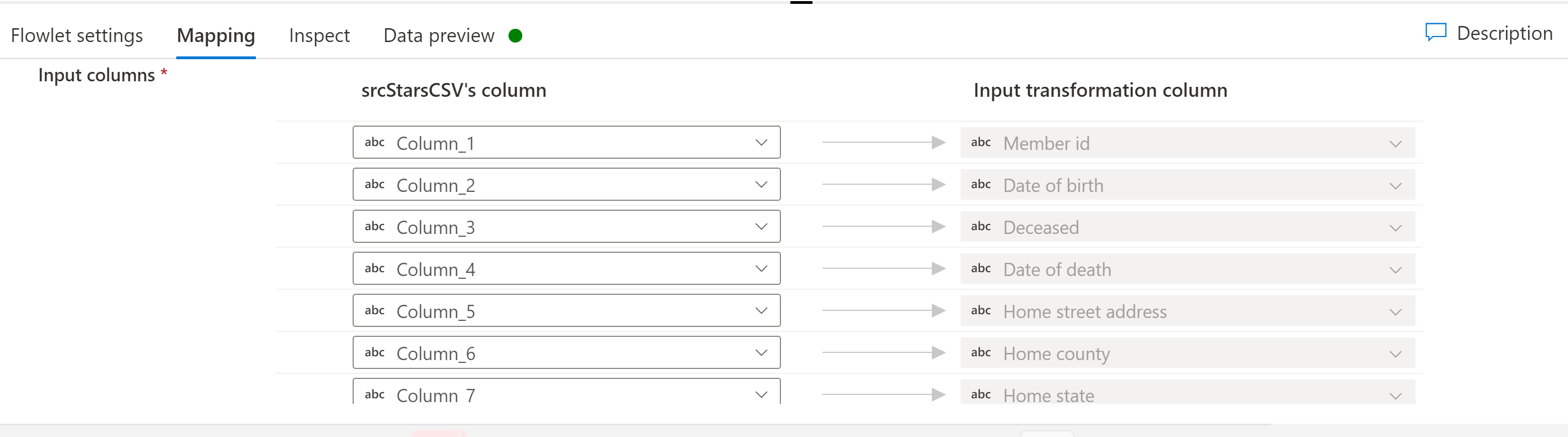
Om det valda flödet har indatakolumner kan du mappa kolumner från indataströmmen till de förväntade indatakolumnerna i flödesflödet. Den här mappningen av dina mappningsdataflödeskolumner till flödesflödet gör det möjligt för flödena att fungera som återanvändbara kodfragment för att mappa dataflödeslogik över potentiellt många mappningsdataflöden.
Dataflödesskript
Syntax
<incomingStream>
<transformation> ~> <transformationName>
<outputStream>
Exempel
source1 derive(Test = "test") ~> DerivedColumn1
DerivedColumn1 output() ~> output1