Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
Dataflöden är tillgängliga i både Azure Data Factory pipelines och Azure Synapse Analytics pipelines. Den här artikeln gäller för mappning av dataflöden. Om du inte har använt transformeringar tidigare läser du introduktionsartikeln Transformera data med hjälp av mappning av dataflöden.
Tips
För motsvarande transformering (Sammanfoga frågor) i Dataflöde Gen2, se En guide till Dataflöde Gen2 för mappning av dataflödesanvändare.
Använd kopplingstransformeringen för att kombinera data från två källor eller strömmar i ett mappningsdataflöde. Utdataströmmen innehåller alla kolumner från båda källorna som matchas baserat på ett kopplingsvillkor.
Kopplingstyper
Mappning av dataflöden stöder för närvarande fem olika kopplingstyper.
Inre koppling
Inre koppling matar endast ut rader som har matchande värden i båda tabellerna.
Vänster yttre
Vänster yttre koppling returnerar alla rader från den vänstra strömmen och matchade poster från den högra strömmen. Om en rad från den vänstra strömmen inte har någon matchning anges utdatakolumnerna från den högra strömmen till NULL. Utdata är de rader som returneras av en inre koppling plus de omatchade raderna från den vänstra strömmen.
Kommentar
Spark-motorn som används av dataflöden misslyckas ibland på grund av möjliga kartesiska produkter i dina kopplingsvillkor. Om detta inträffar kan du växla till en anpassad korskoppling och manuellt ange ditt kopplingsvillkor. Detta kan leda till långsammare prestanda i dina dataflöden eftersom körningsmotorn kan behöva beräkna alla rader från båda sidor av relationen och sedan filtrera rader.
Höger yttre
Höger yttre koppling returnerar alla rader från den högra strömmen och matchade poster från den vänstra strömmen. Om en rad från den högra strömmen inte har någon matchning är utdatakolumnerna från den vänstra dataströmmen inställda på NULL. Utdata är de rader som returneras av en inre koppling plus de omatchade raderna från rätt ström.
Fullständig yttre
Fullständig yttre koppling matar ut alla kolumner och rader från båda sidor med NULL-värden för kolumner som inte matchas.
Anpassad korskoppling
Cross join returnerar korsprodukten av de två strömmarna beroende på ett villkor. Om du använder ett villkor som inte är likhet anger du ett anpassat uttryck som villkor för korskoppling. Utdataströmmen är alla rader som uppfyller kopplingsvillkoret.
Du kan använda den här kopplingstypen för icke-equi-kopplingar och OR villkor.
Om du uttryckligen vill skapa en fullständig kartesisk produkt, använd transformationen Derived Column i var och en av de två oberoende strömmarna före kopplingen för att skapa en syntetisk nyckel att matcha med. Skapa till exempel en ny kolumn i Härledd kolumn i varje ström som heter SyntheticKey och ange den som 1. Använd a.SyntheticKey == b.SyntheticKey sedan som ditt anpassade kopplingsuttryck.
Kommentar
Se till att inkludera minst en kolumn från varje sida av din vänstra och högra relation i en anpassad korskoppling. Att köra korskopplingar med statiska värden i stället för kolumner från varje sida resulterar i fullständiga genomsökningar av hela datamängden, vilket gör att dataflödet fungerar dåligt.
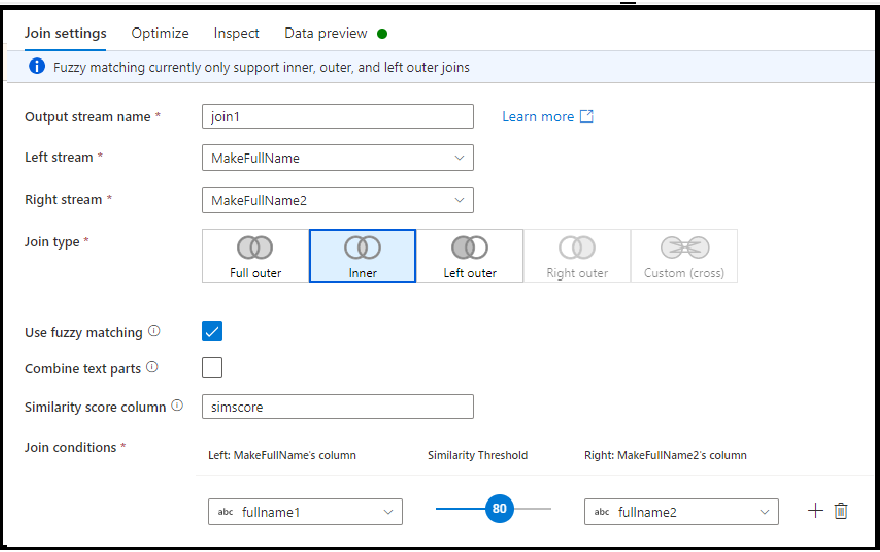
Fuzzy-koppling
Du kan välja att ansluta baserat på fuzzy-kopplingslogik i stället för exakt kolumnvärdesmatchning genom att aktivera kryssrutan "Använd fuzzy-matchning".
- Kombinera textdelar: Använd det här alternativet för att hitta matchningar genom att ta bort blanksteg mellan ord. Data Factory matchas till exempel med DataFactory om det här alternativet är aktiverat.
- Likhetspoängkolumn: Du kan välja att lagra matchande poäng för varje rad i en kolumn genom att ange ett nytt kolumnnamn här för att lagra det värdet.
- Likhetströskel: Välj ett värde mellan 60 och 100 som en procentuell matchning mellan värden i de kolumner som du har valt.
Kommentar
Fuzzy-matchning fungerar för närvarande endast med strängkolumntyper och med inre, vänster yttre och fullständiga yttre kopplingstyper. Du måste inaktivera sändningsoptimeringen när du använder fuzzing matchande kopplingar.
Konfiguration
- Välj vilken dataström du ansluter till i listrutan Höger ström.
- Välj din kopplingstyp
- Välj vilka nyckelkolumner du vill matcha för ditt kopplingsvillkor. Som standard söker dataflödet efter likhet mellan en kolumn i varje dataström. Om du vill jämföra via ett beräknat värde hovra över listrutan kolumn och välj Beräknad kolumn.
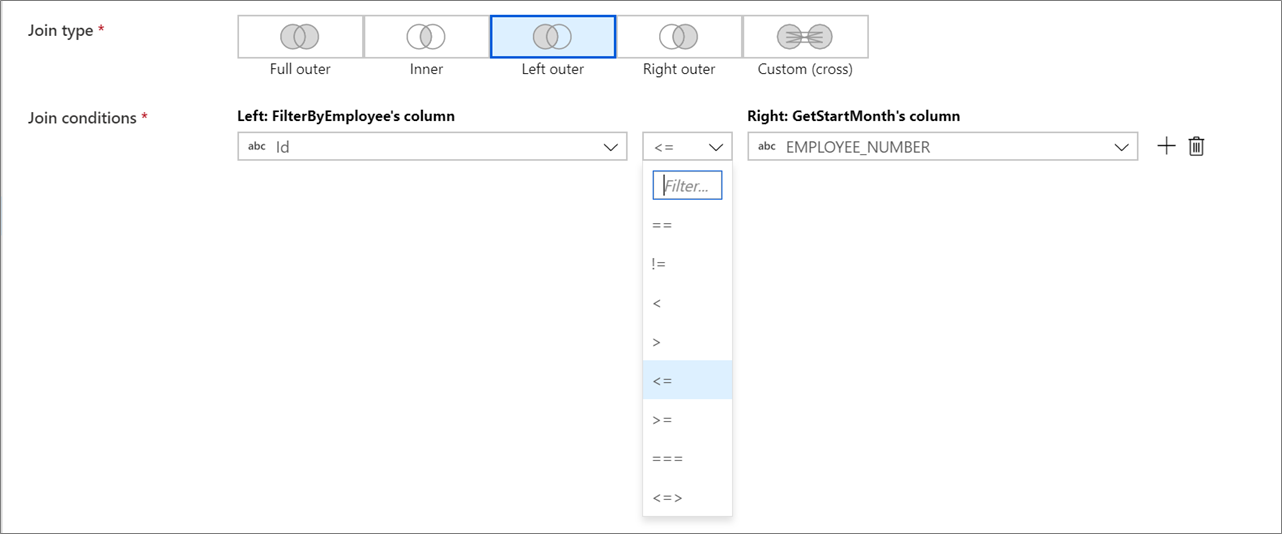
Icke-equi-kopplingar
Om du vill använda en villkorsstyrd operator som inte är lika med (!=) eller större än (>) i kopplingsvillkoren ändrar du listrutan operator mellan de två kolumnerna. Icke-equi-anslutningar kräver att minst en av de två strömmarna sänds med Fast sändning på fliken Optimera.
Optimera kopplingsprestanda
Till skillnad från sammanslagningskoppling i verktyg som SSIS är kopplingstransformeringen inte en obligatorisk kopplingsåtgärd. Kopplingsnycklarna kräver inte sortering. Kopplingsoperationen sker baserat på den optimala kopplingsoperationen i Spark, antingen broadcast- eller map-side join.
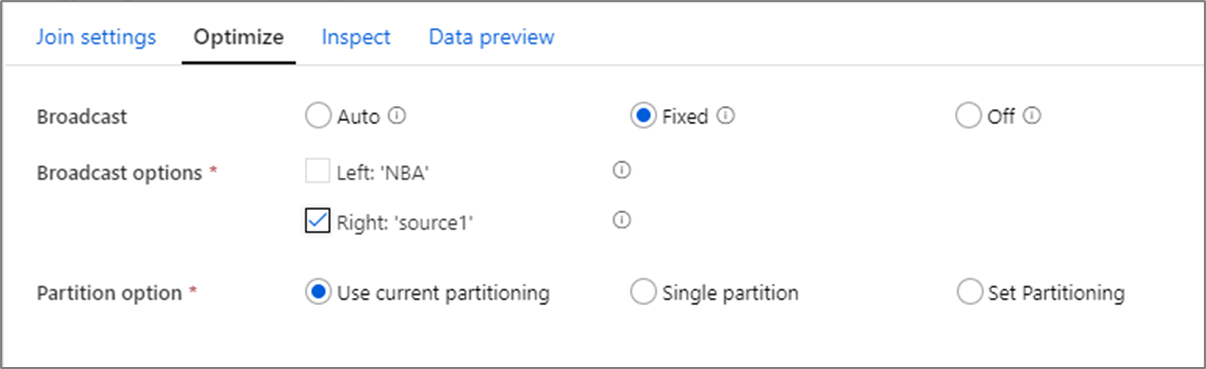
I kopplingar, uppslag och existens-transformering, om en eller båda dataströmmarna får plats i arbetsnodens minne, kan du optimera prestanda genom att aktivera Sändning. Som standard avgör spark-motorn automatiskt om ena sidan ska sändas eller inte. Om du vill välja vilken sida som ska sändas manuellt väljer du Fast.
Vi rekommenderar inte att du inaktiverar sändning via alternativet Av om inte dina kopplingar får timeout-fel.
Självanslutning
Om du vill koppla en dataström själv till sig själv kan du skapa ett alias för en befintlig dataström med en 'select'-transformering. Skapa en ny gren genom att klicka på plusikonen bredvid en transformering och välja Ny gren. Lägg till en select-transformation för att skapa ett alias för den ursprungliga strömmen. Lägg till en kopplingstransformering och välj den ursprungliga strömmen som vänsterström och välj transformering som högerström.
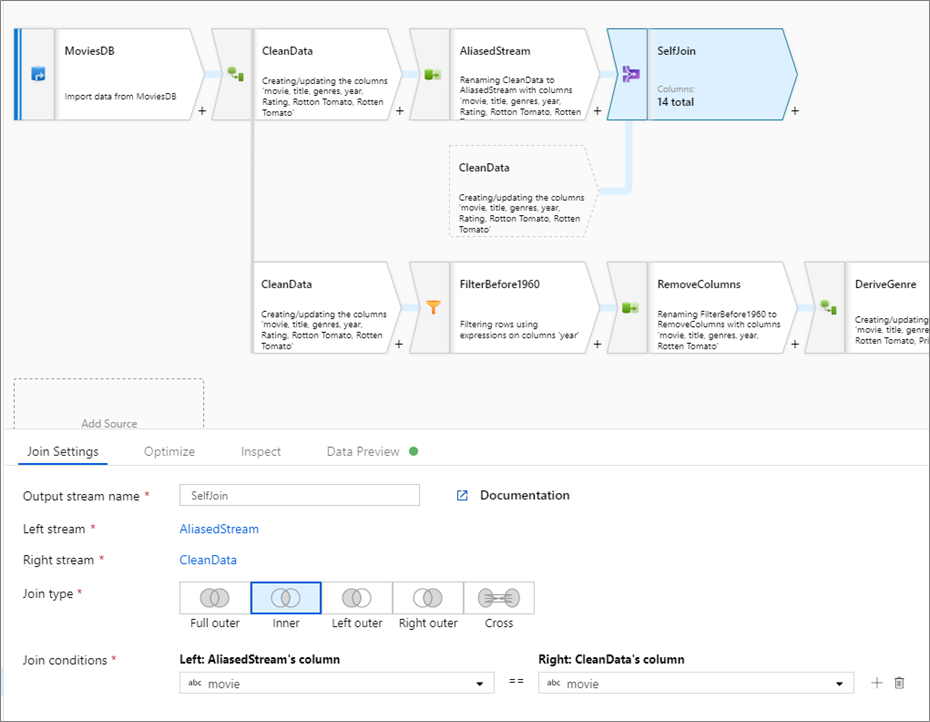
Testa kopplingsvillkor
När du testar kopplingstransformeringar med dataförhandsvisning i felsökningsläge använder du en liten uppsättning kända data. När du samplar rader från en stor datamängd kan du inte förutsäga vilka rader och nycklar som ska läsas för testning. Resultatet är icke-terministiskt, vilket innebär att dina kopplingsvillkor kanske inte returnerar några matchningar.
Dataflödesskript
Syntax
<leftStream>, <rightStream>
join(
<conditionalExpression>,
joinType: { 'inner'> | 'outer' | 'left_outer' | 'right_outer' | 'cross' }
broadcast: { 'auto' | 'left' | 'right' | 'both' | 'off' }
) ~> <joinTransformationName>
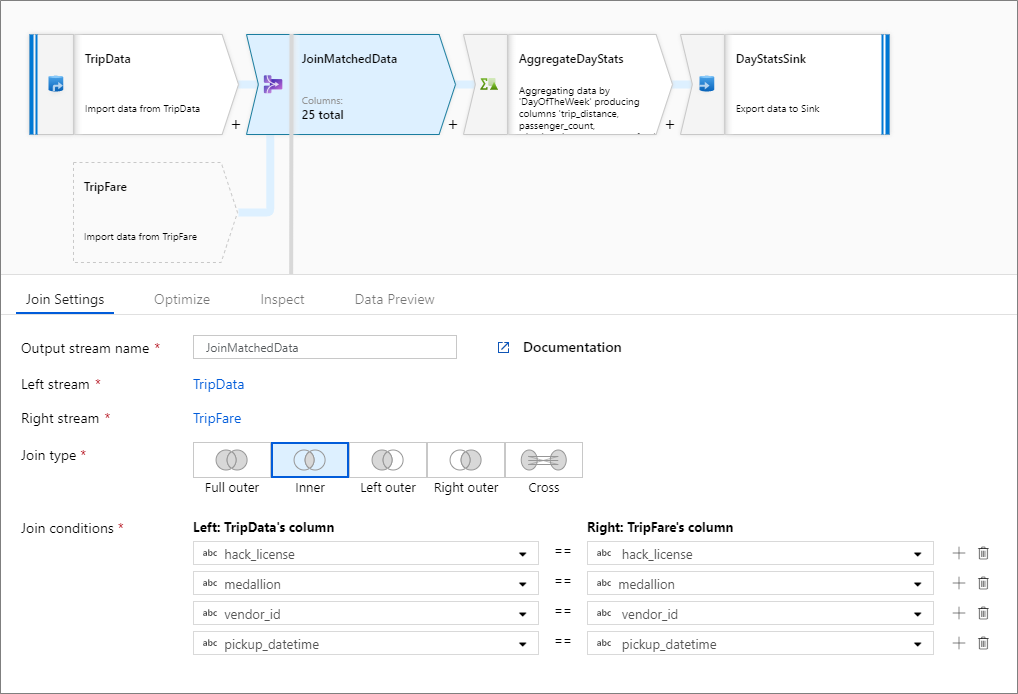
Exempel på inre koppling
Det här exemplet är en kopplingstransformering med namnet JoinMatchedData som tar vänster ström TripData och höger ström TripFare. Kopplingsvillkoret är det uttryck hack_license == { hack_license} && TripData@medallion == TripFare@medallion && vendor_id == { vendor_id} && pickup_datetime == { pickup_datetime} som returnerar sant om kolumnerna hack_license, medallion, vendor_idoch pickup_datetime i varje dataström matchar.
joinType är 'inner'. Vi aktiverar sändning i endast den vänstra dataströmmen så broadcast har värdet 'left'.
I användargränssnittet ser den här omvandlingen ut så här:
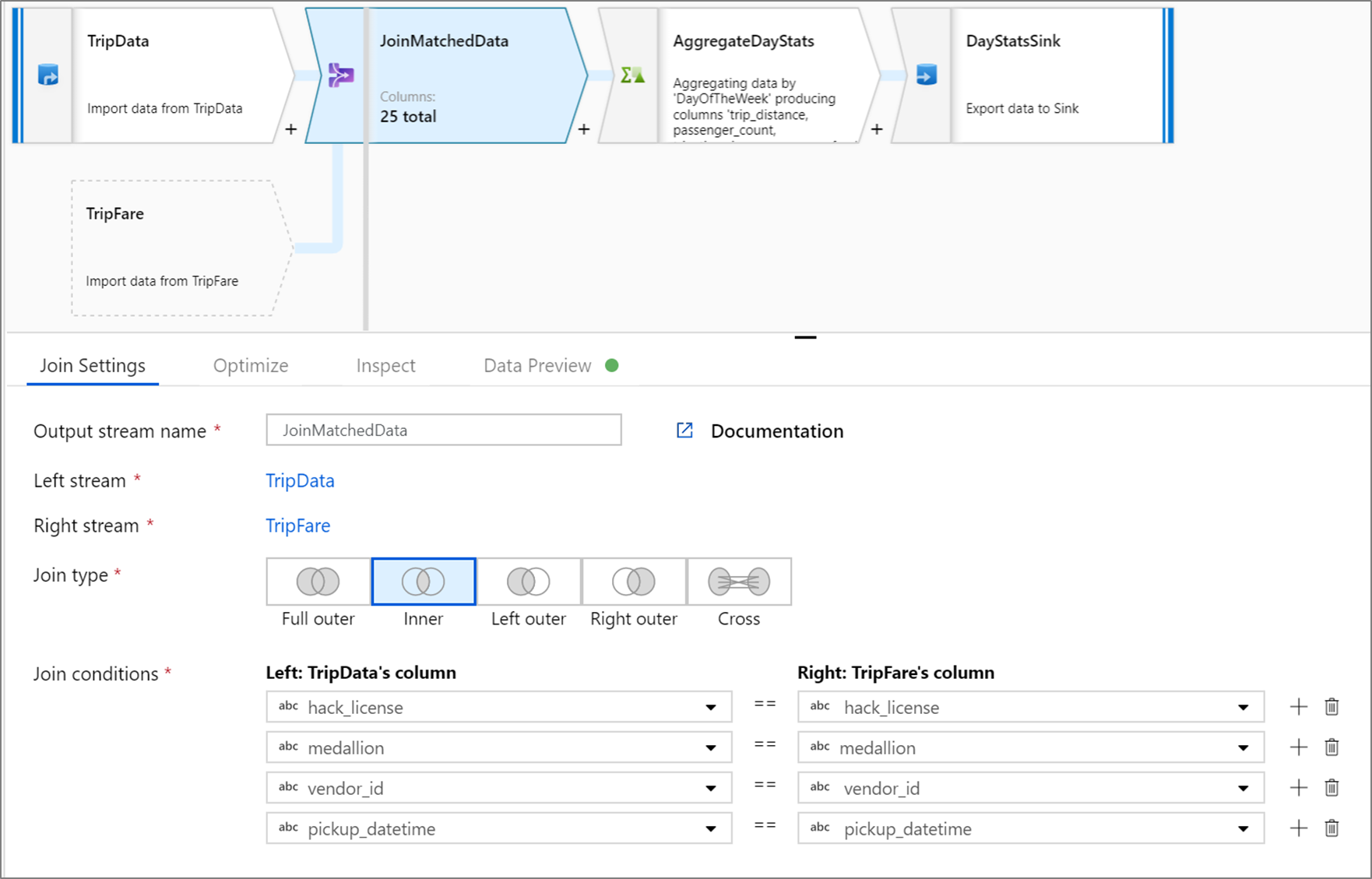
Dataflödesskriptet för den här omvandlingen finns i det här kodfragmentet:
TripData, TripFare
join(
hack_license == { hack_license}
&& TripData@medallion == TripFare@medallion
&& vendor_id == { vendor_id}
&& pickup_datetime == { pickup_datetime},
joinType:'inner',
broadcast: 'left'
)~> JoinMatchedData
Exempel på anpassad korskoppling
Det här exemplet är en sammanfogningstransformation med namnet JoiningColumns som tar vänsterström LeftStream och högerström RightStream. Den här omvandlingen tar in två strömmar och sammanfogar alla rader där kolumnen leftstreamcolumn är större än kolumnen rightstreamcolumn.
joinType är cross. Sändning är inte aktiverad broadcast har värdet 'none'.
I användargränssnittet ser den här omvandlingen ut så här:
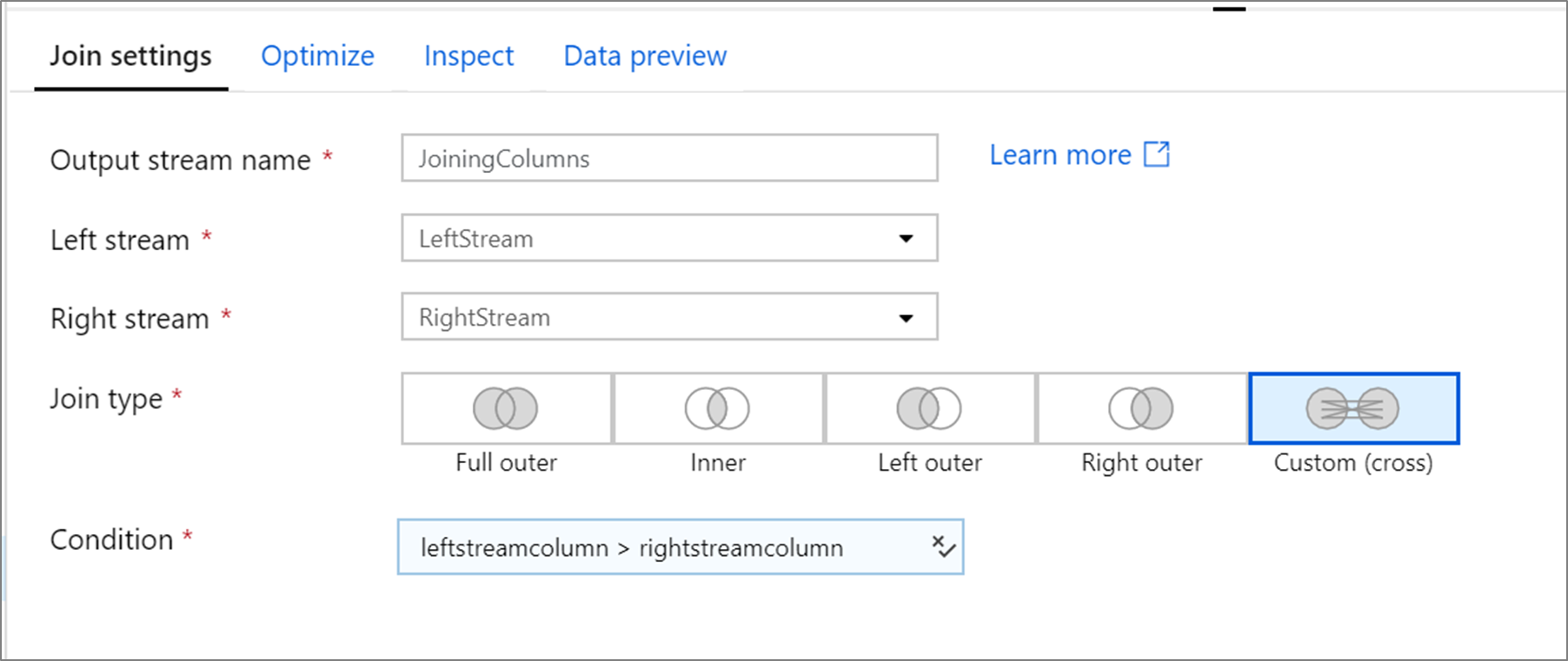
Dataflödesskriptet för den här omvandlingen finns i kodfragmentet:
LeftStream, RightStream
join(
leftstreamcolumn > rightstreamcolumn,
joinType:'cross',
broadcast: 'none'
)~> JoiningColumns
Relaterat innehåll
När du har anslutit data skapar du en härledd kolumn och sänker dina data till ett måldatalager.