Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tips
Data Factory i Microsoft Fabric är nästa generations Azure Data Factory, med en enklare arkitektur, inbyggd AI och nya funktioner. Om dataintegrering är nytt för dig börjar du med Fabric Data Factory. Befintliga ADF-arbetsbelastningar kan uppgraderas till Fabric för att få åtkomst till nya funktioner inom datavetenskap, realtidsanalys och rapportering.
I den här självstudien använder du Azure-portalen för att skapa en Azure Data Factory pipeline som kör en Databricks-notebook-fil mot Databricks-jobbklustret. Den skickar även Azure Data Factory-parametrar till Databricks-notebooken under körningen.
I de här självstudierna går du igenom följande steg:
Skapa en datafabrik.
Skapa en pipeline som använder en Databricks Notebook-aktivitet.
Utlös en pipelinekörning.
Övervaka pipelinekörningen.
Om du inte har någon Azure prenumeration skapar du ett free-konto innan du börjar.
Kommentar
Fullständig information om hur du använder Databricks Notebook-aktiviteten, inklusive att använda bibliotek och skicka indata- och utdataparametrar, finns i dokumentationen för Databricks Notebook Activity .
Förutsättningar
- Azure Databricks arbetsyta. Skapa en ny Azure Databricks-arbetsyta eller använd en befintlig. Du skapar en Python notebook-fil på din Azure Databricks arbetsyta. Sedan kör du notebook-filen och skickar parametrar till den med hjälp av Azure Data Factory.
Skapa en datafabrik
Starta Microsoft Edge eller Google Chrome webbläsare. Data Factory-användargränssnittet stöds för närvarande endast i Microsoft Edge- och Google Chrome-webbläsare.
Välj Skapa en resurs på Azure-portalmenyn och välj sedan Analytics>Data Factory:
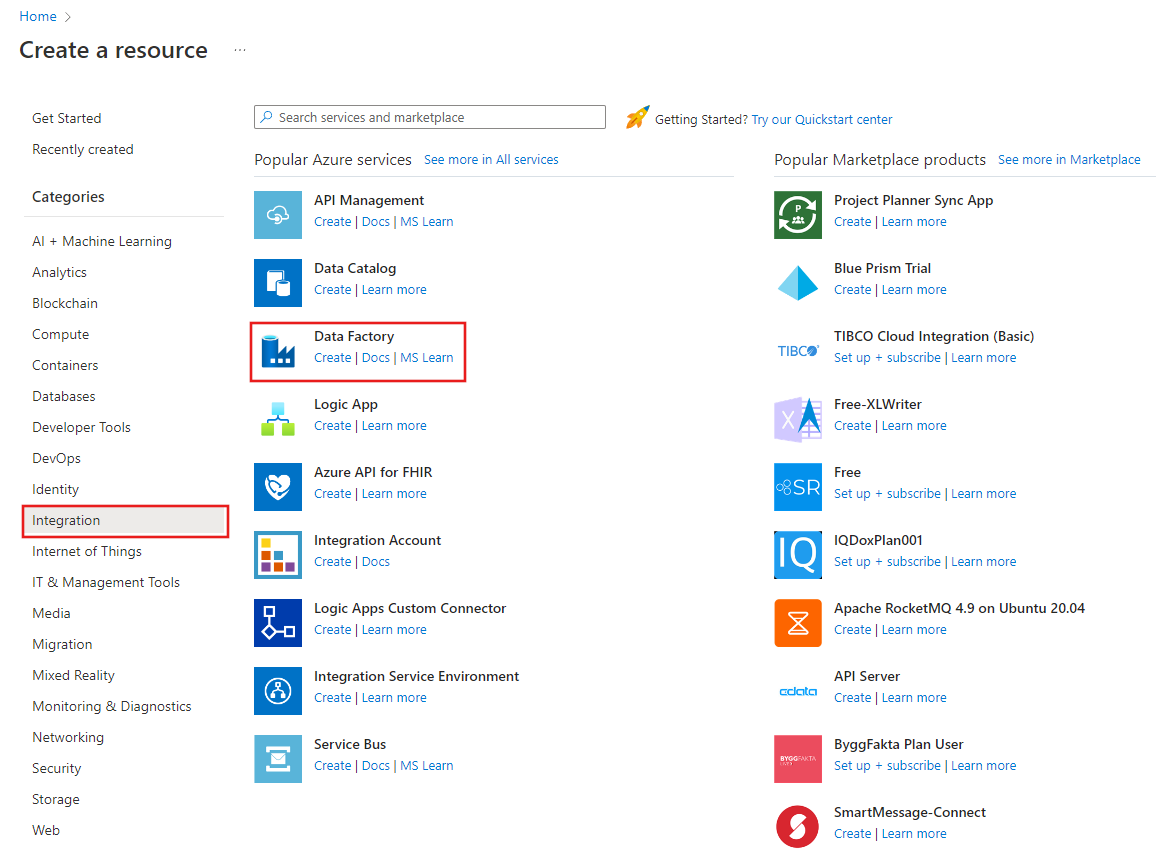
På sidan Skapa datafabrik under fliken Basics väljer du fliken Azure Prenumerationer där du vill skapa datafabriken.
Gör något av följande för Resursgrupp:
Välj en befintlig resursgrupp i listrutan.
Välj Skapa ny och ange namnet på en ny resursgrupp.
Mer information om resursgrupper finns i Använda resursgrupper för att hantera dina Azure resurser.
För Region väljer du platsen för datafabriken.
Listan visar endast platser som Data Factory stöder och var dina Azure Data Factory metadata kommer att lagras. De associerade datalager (till exempel Azure Storage och Azure SQL Database) och beräkningar (till exempel Azure HDInsight) som Data Factory använder kan köras i andra regioner.
Som Namn anger du ADFTutorialDataFactory.
Namnet på Azure datafabrik måste vara globalt unikt. Om du ser följande fel ändrar du namnet på datafabriken (använd <till exempel ditt namn>ADFTutorialDataFactory). Namngivningsregler för Data Factory-artefakter finns i artikeln Data Factory – namnregler.
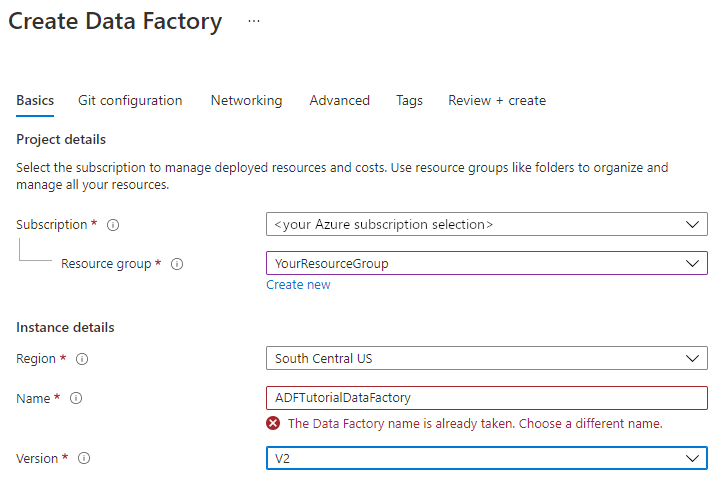
För Version väljer du V2.
Välj Nästa: Git-konfiguration och markera sedan kryssrutan Konfigurera Git senare.
Välj Granska + skapa och välj Skapa när valideringen har godkänts.
När skapandet är klart väljer du Gå till resurs för att navigera till sidan Data Factory . Välj panelen Open Azure Data Factory Studio för att starta Azure Data Factory användargränssnittsprogrammet (UI) på en separat webbläsarflik.

Skapa länkade tjänster
I det här avsnittet skapar du en Databricks-länkad tjänst. Den här länkade tjänsten innehåller anslutningsinformation till Databricks-klustret:
Skapa en Azure Databricks länkad tjänst
På startsidan växlar du till fliken Hantera i den vänstra panelen.
Välj Länkade tjänster under Anslutningar och välj sedan + Ny.
I fönstret Ny länkad tjänst väljer du Compute>Azure Databricks och väljer sedan Continue.

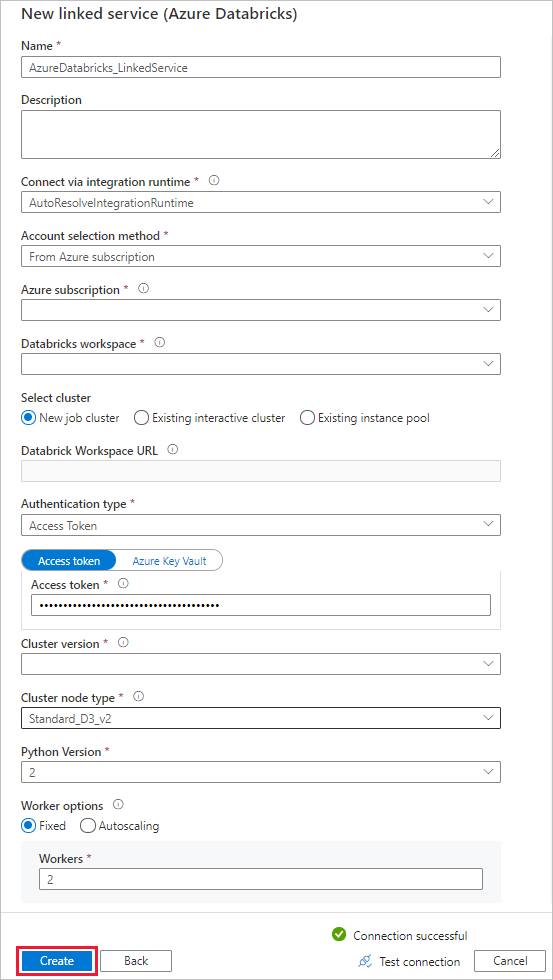
Slutför följande steg i fönstret Ny länkad tjänst :
Ange Namn som AzureDatabricks_LinkedService.
Välj lämplig Databricks-arbetsyta som du ska köra anteckningsboken i.
För Välj kluster väljer du Nytt jobbkluster.
För Databricks-arbetsytans URL bör informationen fyllas i automatiskt.
För Authentication type, om du väljer Access Token, genererar du den från Azure Databricks arbetsyta. Du hittar anvisningar här. För Hanterad tjänstidentitet och Användare tilldelad hanterad identitet, bevilja Contributor-rollen till båda identiteterna i Azure Databricks resursens Access-kontroll-meny.
För Klusterversion väljer du den version som du vill använda.
För Klusternodtyp väljer du Standard_D3_v2 under kategorin Generell användning (HDD) för den här självstudien.
För Arbetare anger du 2.
Välj Skapa.
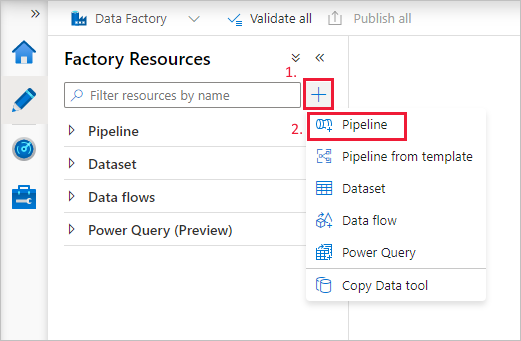
Skapa en pipeline
Välj knappen + (plus) och sedan Pipeline från menyn.
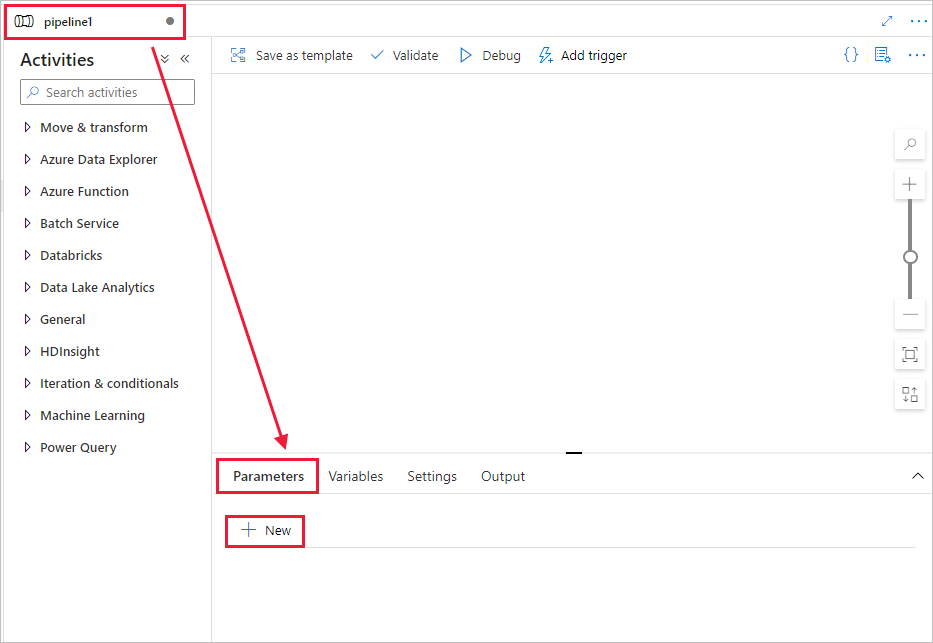
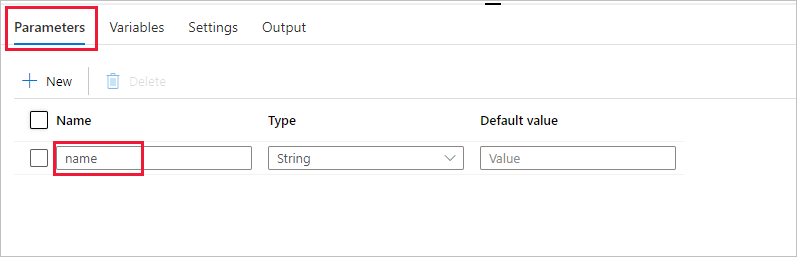
Skapa en parameter som ska användas i pipelinen. Senare kan du skicka den här parametern till Databricks Notebook-aktiviteten. I den tomma pipelinen väljer du fliken Parametrar och väljer sedan + Ny och namnger den som "namn".
Gå till verktygsfältet Aktiviteter och expandera Databricks. Dra aktiviteten Notebook från verktygsfältet Aktiviteter till ytan för pipeline-designern.
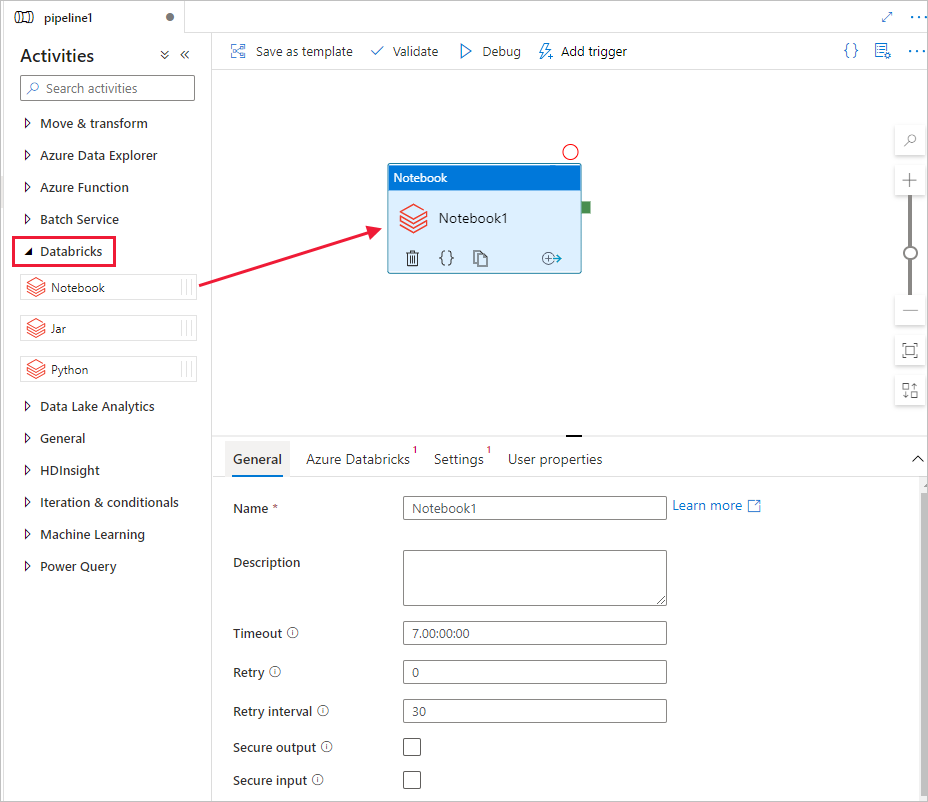
I egenskaperna för aktivitetsfönstret DatabricksNotebook längst ned utför du följande steg:
Växla till fliken Azure Databricks.
Välj AzureDatabricks_LinkedService (som du skapade i föregående procedur).
Växla till fliken Settings (Inställningar).
Bläddra och välj en Databricks Notebook-sökväg. Nu ska vi skapa en anteckningsbok och ange sökvägen här. Du får Notebook-sökvägen genom att följa några få enkla steg.
Starta din Azure Databricks-arbetsyta.
Skapa en Ny mapp i arbetsplatsen och ge den namnet adftutorial.
Skapa en ny anteckningsbok, låt oss kalla den mynotebook. Högerklicka på mappen adftutorial och välj Skapa.
I din nyligen skapade notebook, ”mynotebook”, lägger du till följande kod:
# Creating widgets for leveraging parameters, and printing the parameters dbutils.widgets.text("input", "","") y = dbutils.widgets.get("input") print ("Param -\'input':") print (y)Notebook-sökvägen i det här fallet är /adftutorial/mynotebook.
Växla tillbaka till redigeringsverktyget för Data Factory-användargränssnittet. Gå till fliken Inställningar under aktiviteten Notebook1 .
a. Lägg till en parameter i notebook-aktiviteten. Du använder samma parameter som du lade till tidigare i Pipeline.
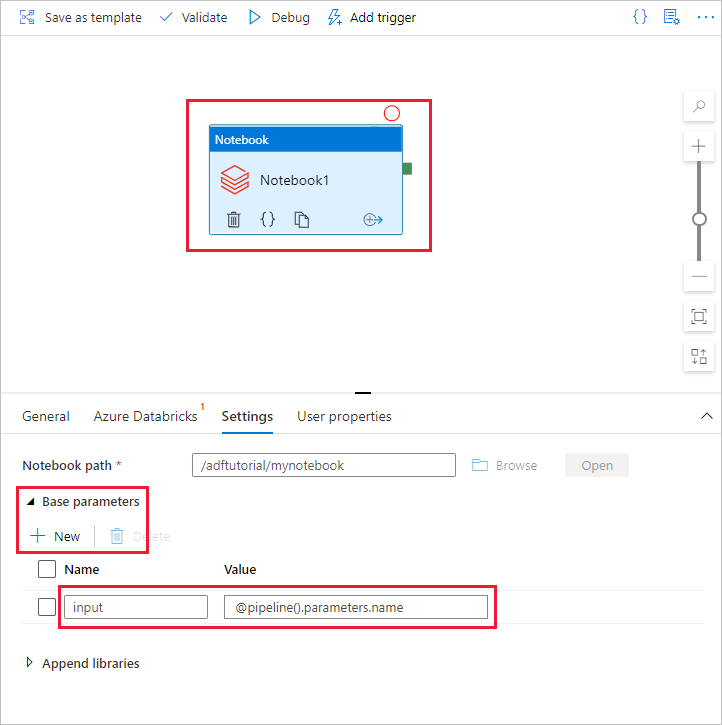
b) Namnge parametern som indata och ange värdet som uttryck @pipeline().parameters.name.
Verifiera pipelinen genom att välja knappen Verifiera i verktygsfältet. Stäng valideringsfönstret genom att välja knappen Stäng .
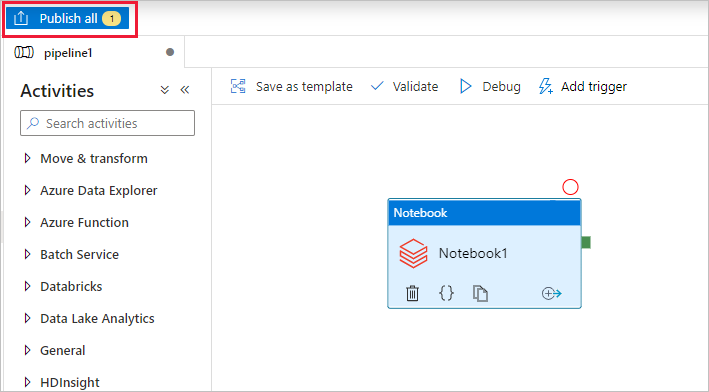
Markera Publicera alla. Användargränssnittet för Data Factory publicerar entiteter (länkade tjänster och pipeline) till Azure Data Factory-tjänsten.
Utlös en pipelinekörning
Välj Lägg till utlösare i verktygsfältet och välj sedan Utlösare nu.
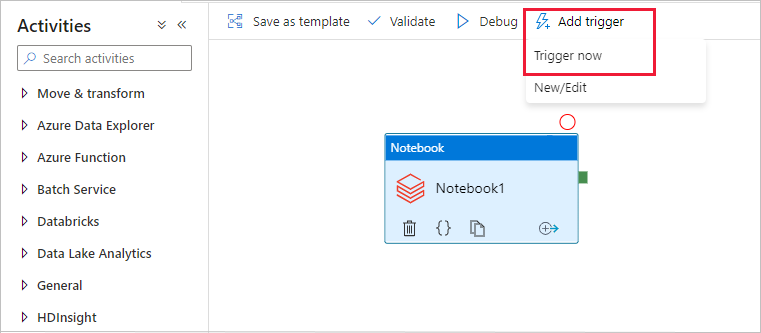
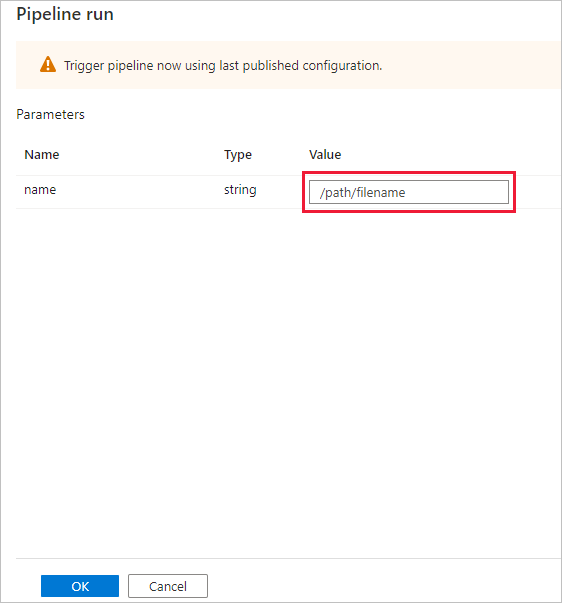
Dialogrutan Pipelinekörning frågar om namnparametern. Använd /path/filename som den här parametern. Välj OK.
Övervaka pipelinekörningen
Växla till fliken Övervaka . Bekräfta att du ser en pipelinekörning. Det tar cirka 5–8 minuter att skapa ett Databricks-jobbkluster där en notebook körs.
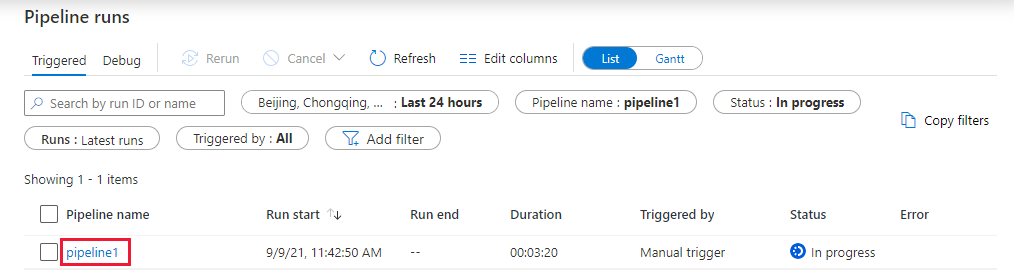
Klicka på Uppdatera då och då så att du ser pipelinekörningens status.
För att se aktivitetskörningar associerade med pipelinekörningen, välj pipeline1 i kolumnen Pipelinenamn.
På sidan Aktivitetskörningar väljer du Utdata i kolumnen Aktivitetsnamn för att visa utdata för varje aktivitet. Du hittar länken till Databricks-loggar i fönstret Utdata för mer detaljerade Spark-loggar.
Du kan växla tillbaka till pipelinekörningsvyn genom att välja länken Alla pipelinekörningar i menyn breadcrumb längst upp.
Verifiera utdata
Du kan logga in på arbetsytan Azure Databricks, gå till Job Runs och se Job-statusen som väntar på att köras, körs, eller avslutad.
Du kan välja jobbnamnet och navigera för att se mer information. Vid lyckad exekvering kan du verifiera de parametrar som har skickats och utdata-n för Python notebook.
Sammanfattning
Pipelinen i det här exemplet utlöser en Databricks Notebook-aktivitet och skickar en parameter till den. Du har lärt dig att:
Skapa en datafabrik.
Skapa en pipeline som använder en Databricks Notebook-aktivitet.
Utlös en pipelinekörning.
Övervaka pipelinekörningen.