Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
GÄLLER FÖR: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Om du inte har använt Azure Data Factory tidigare kan du läsa Introduktion till Azure Data Factory.
I den här självstudien använder du Användargränssnittet för Data Factory för att skapa en pipeline som kopierar och transformerar data från en Azure Data Lake Storage Gen2-källa till en Data Lake Storage Gen2-mottagare (båda ger åtkomst till endast valda nätverk) med hjälp av mappning av dataflödet i Data Factory Managed Virtual Network. Du kan expandera konfigurationsmönstret i den här självstudien när du transformerar data med hjälp av mappning av dataflöde.
I den här självstudien gör du följande:
- Skapa en datafabrik.
- Skapa en pipeline med en dataflödesaktivitet.
- Skapa ett mappningsdataflöde med fyra transformeringar.
- Testkör pipelinen.
- Övervaka en dataflödesaktivitet.
Förutsättningar
- Azure-prenumeration. Om du inte har en Azure-prenumeration kan du skapa ett kostnadsfritt Azure-konto innan du börjar.
- Azure Storage-konto. Du använder Data Lake Storage som käll- och mottagardatalager . Om du inte har ett lagringskonto finns det anvisningar om hur du skapar ett i Skapa ett Azure Storage-konto. Kontrollera att lagringskontot endast tillåter åtkomst från valda nätverk.
Filen som vi ska transformera i den här självstudien är moviesDB.csv, som finns på den här GitHub-innehållswebbplatsen. Om du vill hämta filen från GitHub kopierar du innehållet till valfri textredigerare för att spara den lokalt som en .csv fil. Information om hur du laddar upp filen till ditt lagringskonto finns i Ladda upp blobar med Azure Portal. Exemplen refererar till en container med namnet sample-data.
Skapa en datafabrik
I det här steget skapar du en datafabrik och öppnar användargränssnittet för Data Factory för att skapa en pipeline i datafabriken.
Öppna Microsoft Edge eller Google Chrome. För närvarande stöder endast Microsoft Edge- och Google Chrome-webbläsare Data Factory-användargränssnittet.
Välj Skapa en resurs>Analys>Data Factory i menyn till vänster.
I fönstret Ny datafabrik, under Namn anger du ADFTutorialDataFactory.
Namnet på datafabriken måste vara globalt unikt. Om du får ett felmeddelande om namnvärdet anger du ett annat namn för datafabriken (till exempel dittnamnADFTutorialDataFactory). Se artikeln om namnregler för datafabriker för namnregler för datafabriksartefakter.
Välj den Azure-prenumeration som du vill skapa den nya datafabriken i.
Gör något av följande för Resursgrupp:
- Välj Använd befintlig och välj en befintlig resursgrupp i listrutan.
- Välj Skapa ny och ange namnet på en resursgrupp.
Mer information om resursgrupper finns i Använda resursgrupper för att hantera Azure-resurser.
Under Version väljer du V2.
Under Plats väljer du en plats för datafabriken. Endast platser som stöds visas i listrutan. Datalager (till exempel Azure Storage och Azure SQL Database) och beräkningar (till exempel Azure HDInsight) som används av datafabriken kan finnas i andra regioner.
Välj Skapa.
När skapandet är klart visas meddelandet i meddelandecentret. Välj Gå till resurs för att gå till sidan DataFabrik .
Välj Öppna Azure Data Factory Studio för att starta Data Factory-användargränssnittet på en separat flik.
Skapa en Azure IR i Data Factory Managed Virtual Network
I det här steget skapar du en Azure IR och aktiverar Data Factory Managed Virtual Network.
I Data Factory-portalen går du till Hantera och väljer Ny för att skapa en ny Azure IR.
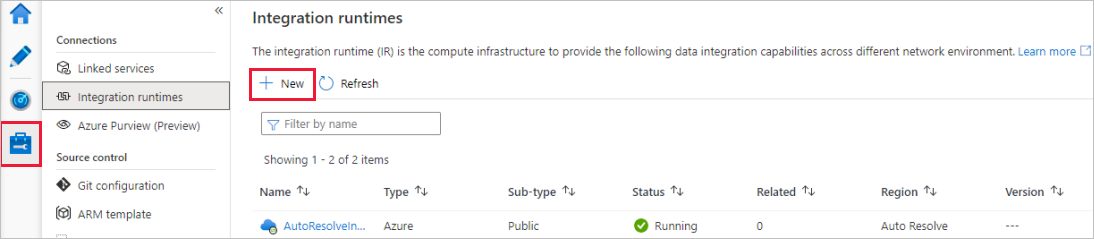
På sidan Installation av integrationskörning väljer du vilken integrationskörning som ska skapas baserat på de funktioner som krävs. I den här självstudien väljer du Azure, Lokalt installerad och klickar sedan på Fortsätt.
Välj Azure och klicka sedan på Fortsätt för att skapa en Azure Integration-körning.
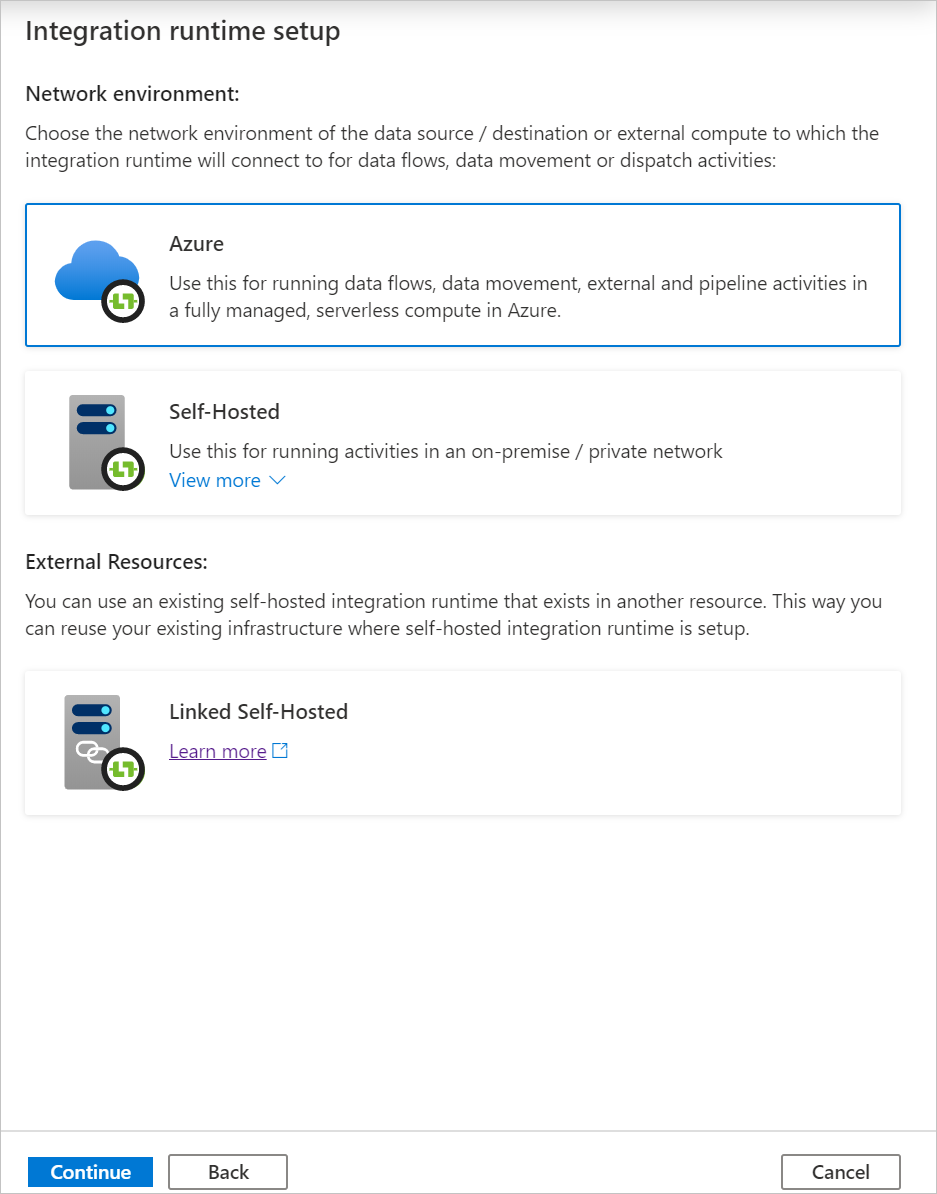
Under Konfiguration av virtuellt nätverk (förhandsversion) väljer du Aktivera.
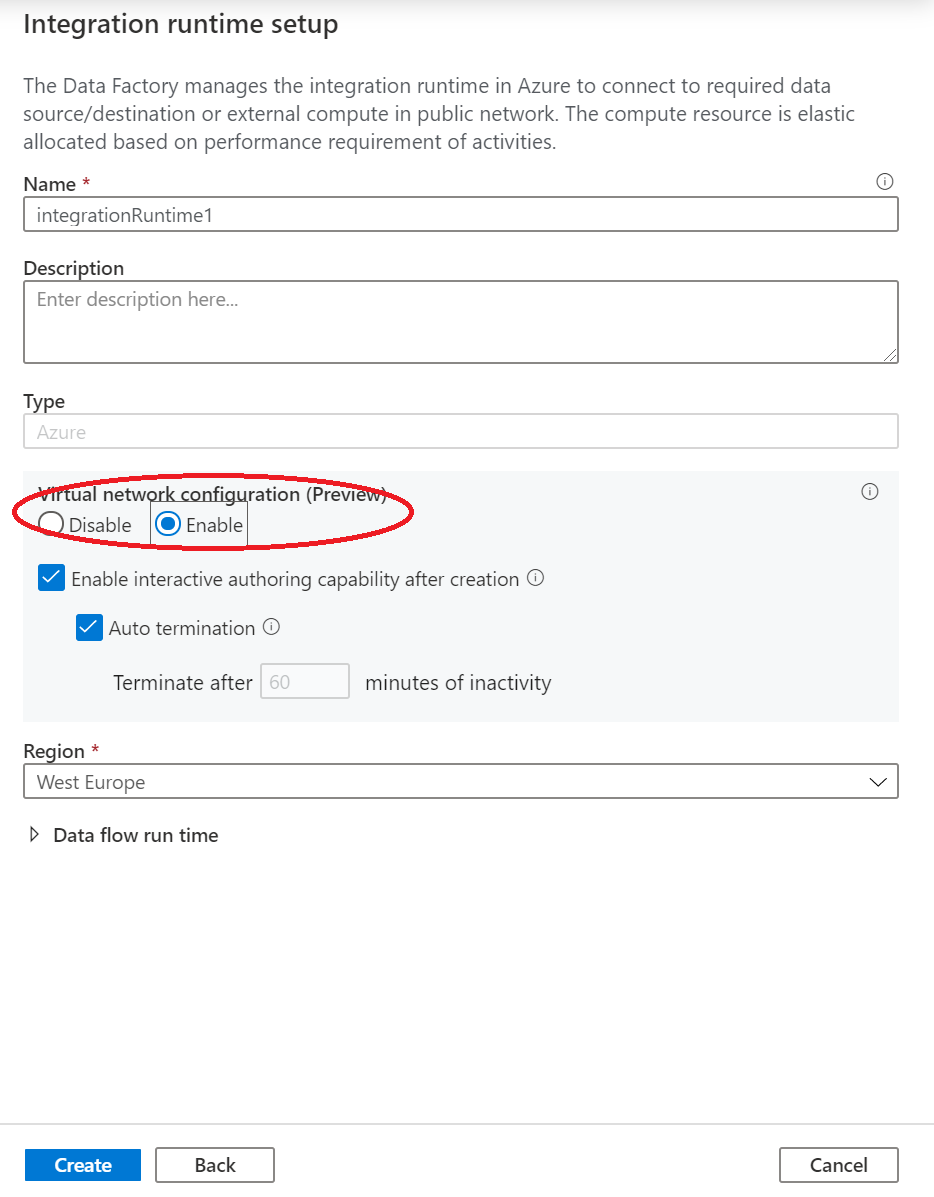
Välj Skapa.
Skapa en pipeline med en dataflödesaktivitet
I det här steget skapar du en pipeline som innehåller en dataflödesaktivitet.
På startsidan för Azure Data Factory väljer du Orchestrate.
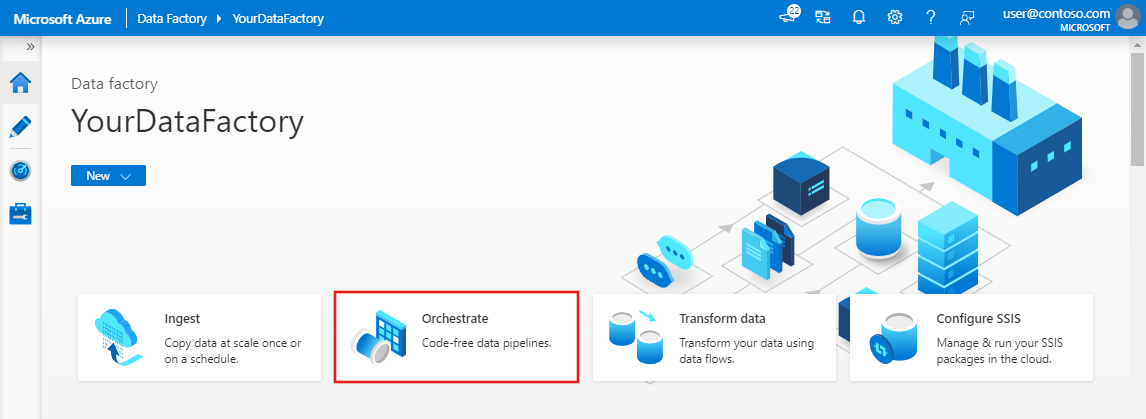
I egenskapsfönstret för pipelinen anger du TransformMovies som pipelinenamn.
I fönstret Aktiviteter expanderar du Flytta och transformera. Dra aktiviteten Dataflöde från fönstret till pipelinearbetsytan.
I popup-fönstret Lägg till dataflöde väljer du Skapa nytt dataflöde och sedan Mappa Dataflöde. Välj OK när du är klar.
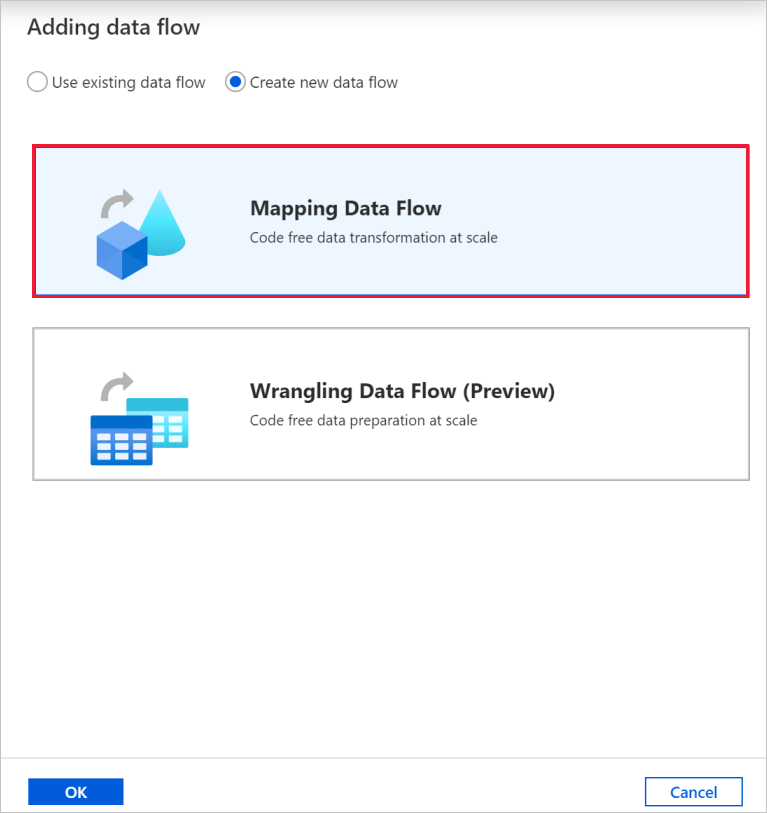
Ge dataflödet namnet TransformMovies i egenskapsfönstret .
I det övre fältet på pipelinearbetsytan skjuter du Dataflöde felsökningsreglaget på. Felsökningsläget möjliggör interaktiv testning av omvandlingslogik mot ett Live Spark-kluster. Dataflöde kluster tar 5–7 minuter att värma upp och användarna rekommenderas att aktivera felsökning först om de planerar att utföra Dataflöde utveckling. Mer information finns i Felsökningsläge.

Skapa transformeringslogik på dataflödesarbetsytan
När du har skapat dataflödet skickas du automatiskt till dataflödesarbetsytan. I det här steget skapar du ett dataflöde som tar moviesDB.csv-filen i Data Lake Storage och aggregerar det genomsnittliga omdömet för komedier från 1910 till 2000. Sedan skriver du tillbaka den här filen till Data Lake Storage.
Lägg till källtransformeringen
I det här steget konfigurerar du Data Lake Storage Gen2 som källa.
I dataflödesarbetsytan lägger du till en källa genom att välja rutan Lägg till källa .
Ge källan namnet MoviesDB. Välj Ny för att skapa en ny källdatauppsättning.
Välj Azure Data Lake Storage Gen2 och välj sedan Fortsätt.
Välj AvgränsadText och välj sedan Fortsätt.
Ge datauppsättningen namnet MoviesDB. I listrutan länkad tjänst väljer du Nytt.
På skärmen för att skapa länkad tjänst namnger du den länkade tjänsten ADLSGen2 för Data Lake Storage Gen2 och anger din autentiseringsmetod. Ange sedan dina autentiseringsuppgifter för anslutningen. I den här självstudien använder vi kontonyckeln för att ansluta till vårt lagringskonto.
Se till att du aktiverar interaktiv redigering. Det kan ta en minut att aktivera.
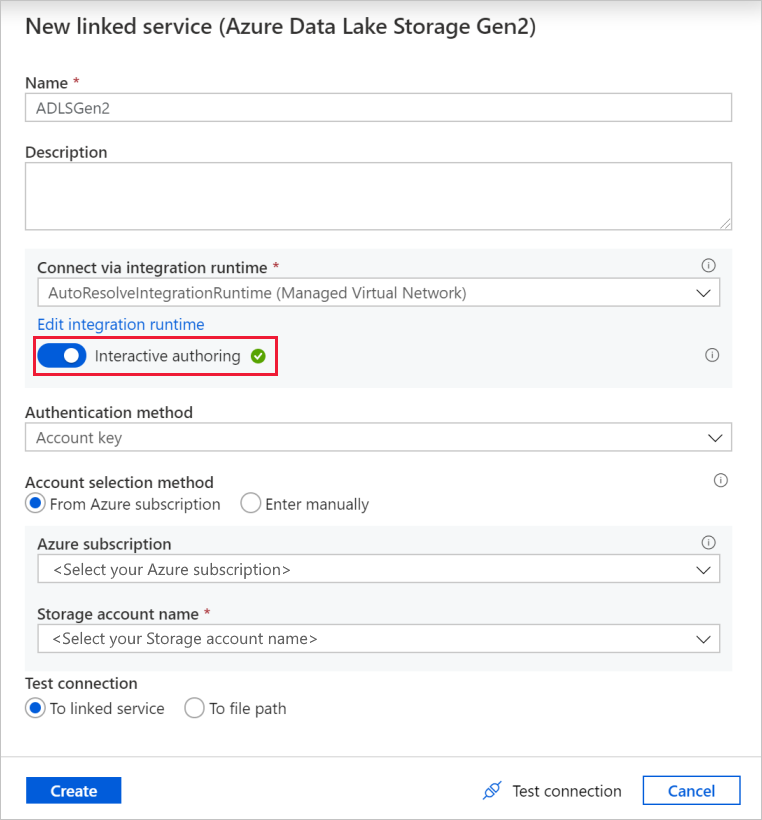
Välj Testanslutning. Det bör misslyckas eftersom lagringskontot inte aktiverar åtkomst till det utan att en privat slutpunkt skapas och godkänns. I felmeddelandet bör du se en länk för att skapa en privat slutpunkt som du kan följa för att skapa en hanterad privat slutpunkt. Ett alternativ är att gå direkt till fliken Hantera och följa anvisningarna i det här avsnittet för att skapa en hanterad privat slutpunkt.
Håll dialogrutan öppen och gå sedan till ditt lagringskonto.
Följ anvisningarna i det här avsnittet för att godkänna den privata länken.
Gå tillbaka till dialogrutan. Välj Testa anslutning igen och välj Skapa för att distribuera den länkade tjänsten.
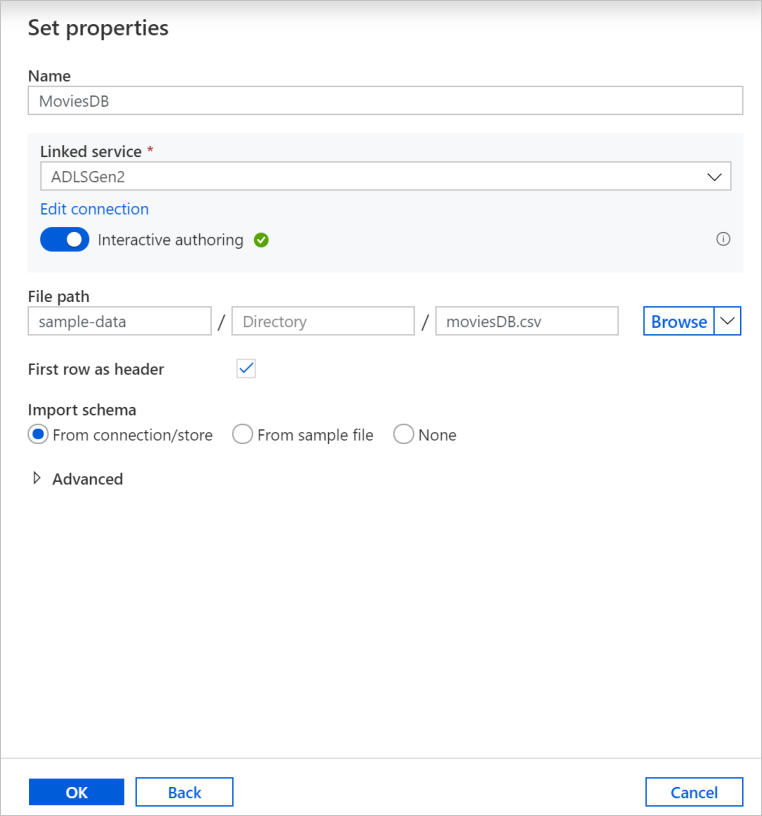
På skärmen för att skapa datauppsättning anger du var filen finns under fältet Filsökväg . I den här självstudien finns filen moviesDB.csv i containern sample-data. Eftersom filen har rubriker markerar du kryssrutan Första raden som rubrik . Välj Från anslutning/arkiv för att importera rubrikschemat direkt från filen i lagringen. Välj OK när du är klar.
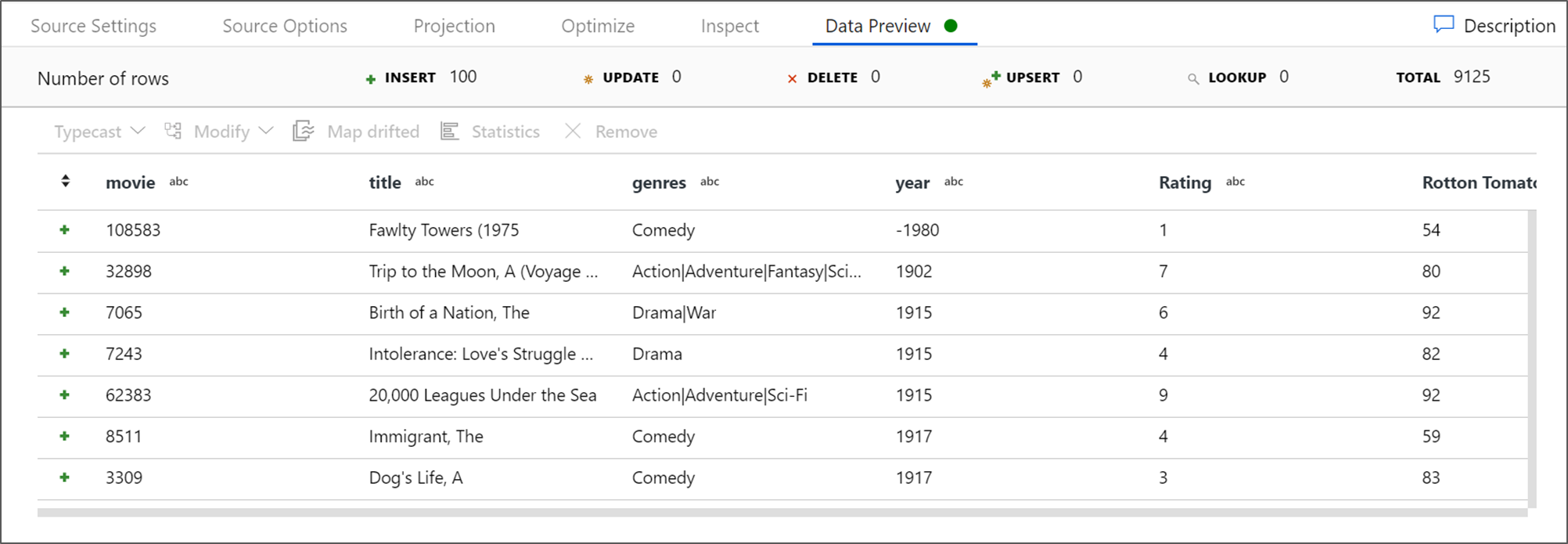
Om felsökningsklustret har startat går du till fliken Förhandsgranskning av data i källomvandlingen och väljer Uppdatera för att få en ögonblicksbild av data. Du kan använda dataförhandsgranskningen för att kontrollera att omvandlingen är korrekt konfigurerad.
Skapa en hanterad privat slutpunkt
Om du inte använde hyperlänken när du testade den föregående anslutningen följer du sökvägen. Nu måste du skapa en hanterad privat slutpunkt som du ska ansluta till den länkade tjänst som du skapade.
Gå till fliken Hantera .
Kommentar
Fliken Hantera kanske inte är tillgänglig för alla Data Factory-instanser. Om du inte ser den kan du komma åt privata slutpunkter genom att välja Skapa>>
Gå till avsnittet Hanterade privata slutpunkter .
Välj + Ny under Hanterade privata slutpunkter.
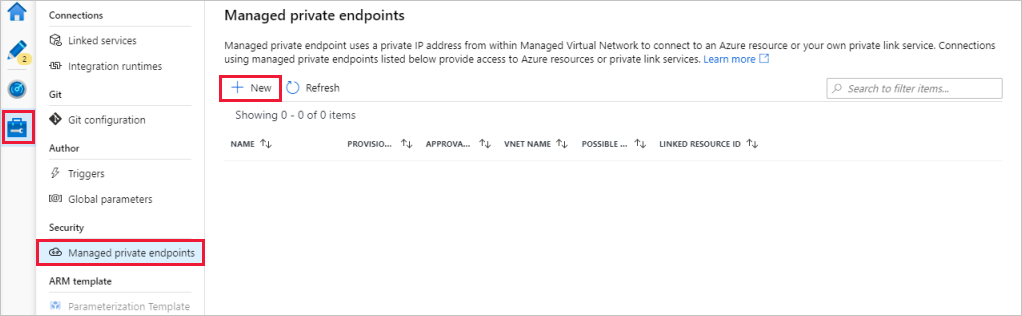
Välj panelen Azure Data Lake Storage Gen2 i listan och välj Fortsätt.
Ange namnet på lagringskontot som du skapade.
Välj Skapa.
Efter några sekunder bör du se att den privata länken som skapats behöver ett godkännande.
Välj den privata slutpunkt som du skapade. Du kan se en hyperlänk som gör att du godkänner den privata slutpunkten på lagringskontonivå.
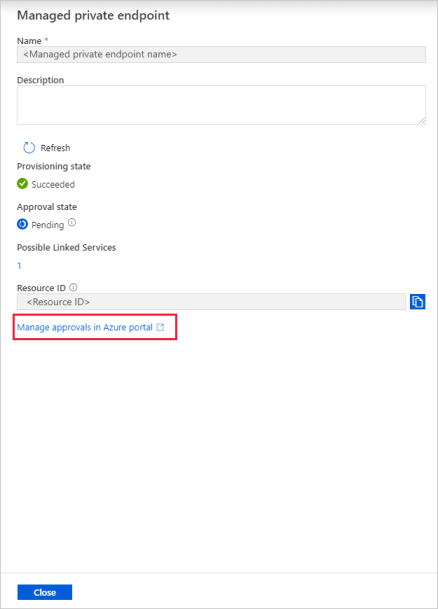
Godkännande av en privat länk i ett lagringskonto
I lagringskontot går du till Privata slutpunktsanslutningar under avsnittet Inställningar .
Markera kryssrutan för den privata slutpunkt som du skapade och välj Godkänn.
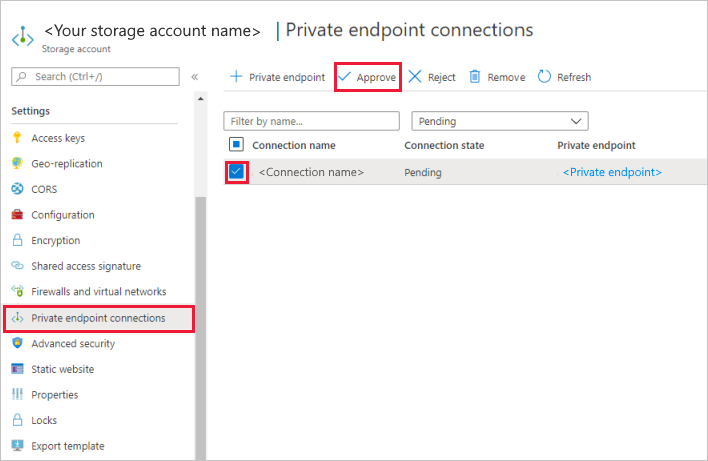
Lägg till en beskrivning och välj Ja.
Gå tillbaka till Avsnittet Hanterade privata slutpunkter på fliken Hantera i Data Factory.
Efter ungefär en minut bör godkännandet visas för din privata slutpunkt.
Lägg till filtertransformeringen
Bredvid källnoden på dataflödesarbetsytan väljer du plusikonen för att lägga till en ny transformering. Den första omvandlingen som du lägger till är ett filter.
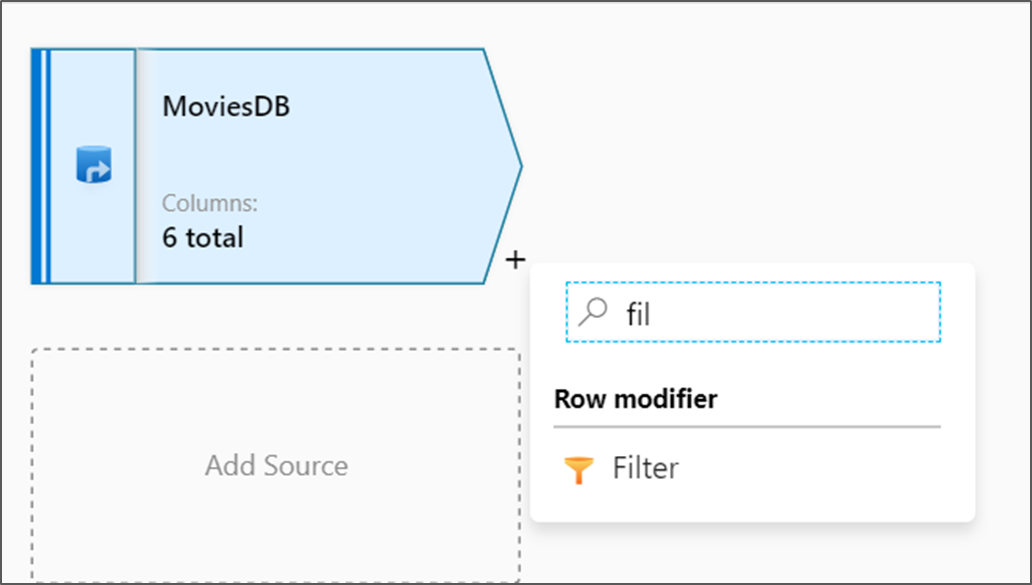
Ge filtertransformeringen namnet FilterYears. Välj uttrycksrutan bredvid Filtrera på för att öppna uttrycksverktyget. Här anger du filtreringsvillkoret.
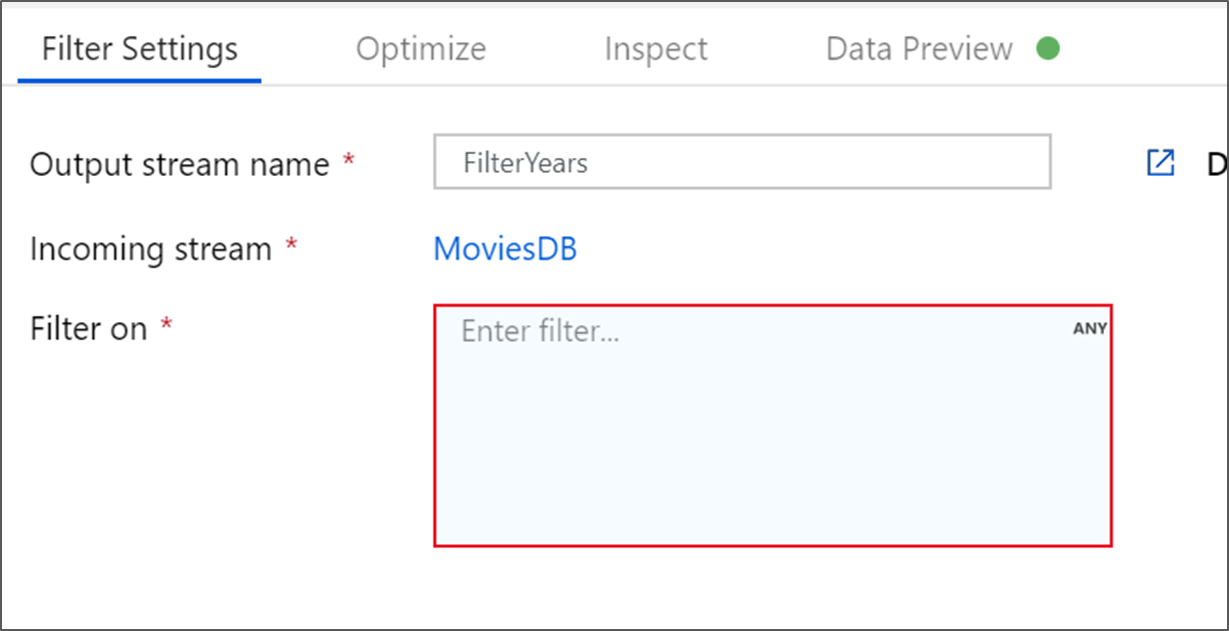
Med dataflödesuttrycksverktyget kan du interaktivt skapa uttryck som ska användas i olika transformeringar. Uttryck kan innehålla inbyggda funktioner, kolumner från indataschemat och användardefinierade parametrar. Mer information om hur du skapar uttryck finns i byggare för dataflödesuttryck.
I den här självstudien vill du filtrera filmer i komedigenren som kom ut mellan åren 1910 och 2000. Eftersom året för närvarande är en sträng måste du konvertera det till ett heltal med hjälp
toInteger()av funktionen. Använd operatorerna större än eller lika med (>=) och mindre än eller lika med (<=) för att jämföra med läsårsvärdena 1910 och 2000. Koppla dessa uttryck tillsammans med operatorn och (&&). Uttrycket kommer ut som:toInteger(year) >= 1910 && toInteger(year) <= 2000Om du vill ta reda på vilka filmer som är komedier kan du använda
rlike()funktionen för att hitta mönstret "Comedy" i kolumngenren. Union uttrycketrlikemed årsjämförelsen för att få:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')Om du har ett felsökningskluster aktivt kan du verifiera logiken genom att välja Uppdatera för att se uttryckets utdata jämfört med de indata som används. Det finns mer än ett rätt svar på hur du kan åstadkomma den här logiken med hjälp av dataflödesuttrycksspråket.
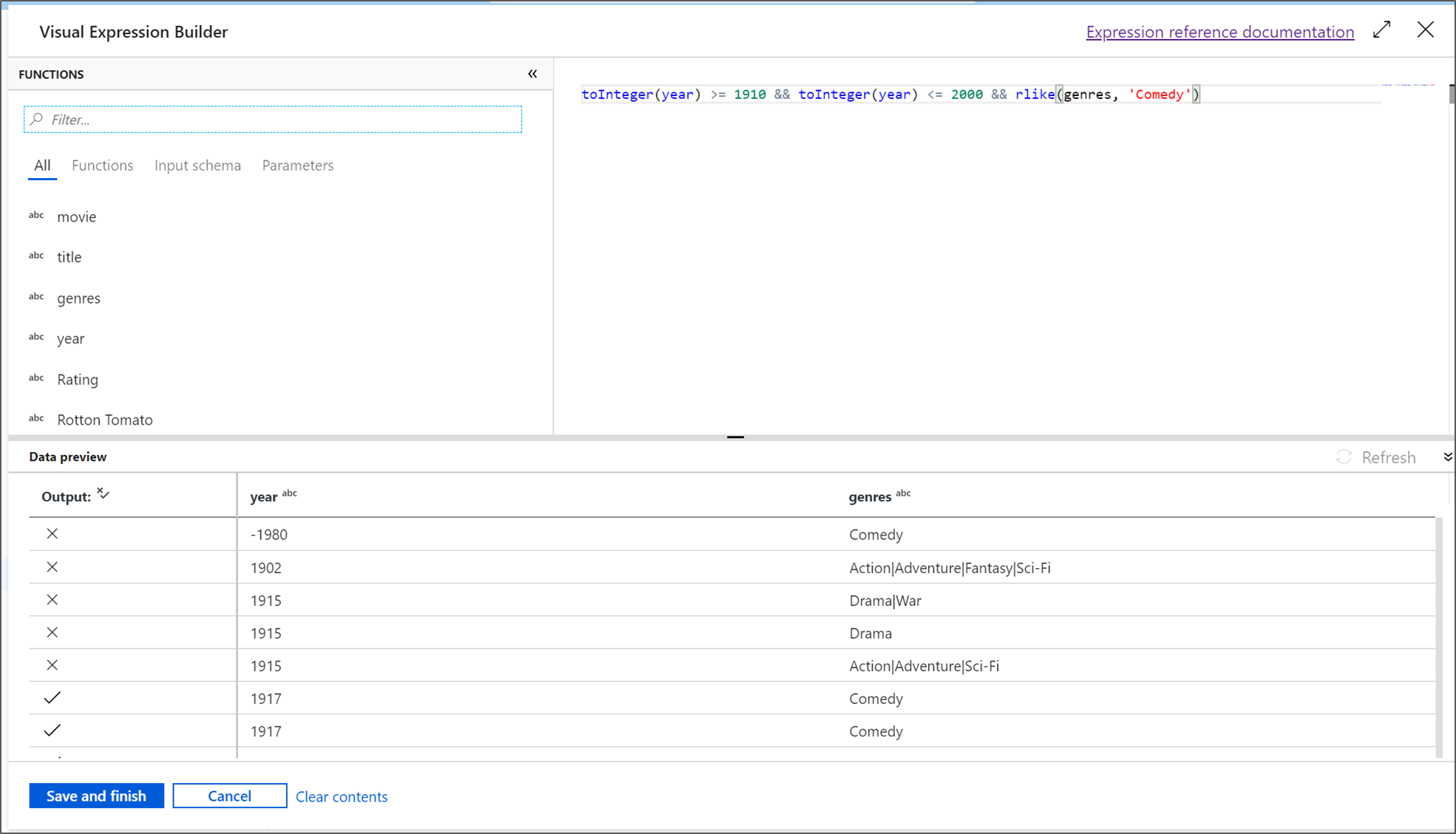
Välj Spara och slutför när du är klar med uttrycket.
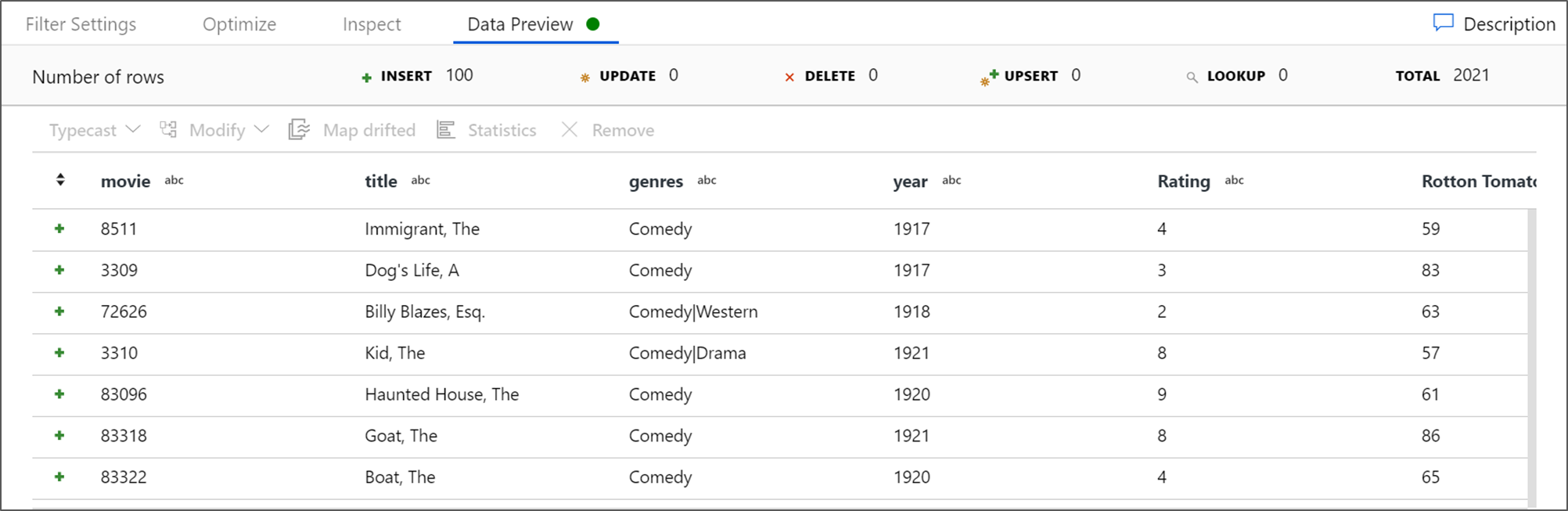
Hämta en dataförhandsgranskning för att kontrollera att filtret fungerar korrekt.
Lägg till den aggregerade omvandlingen
Nästa transformering som du lägger till är en aggregeringstransformering under Schemamodifierare.
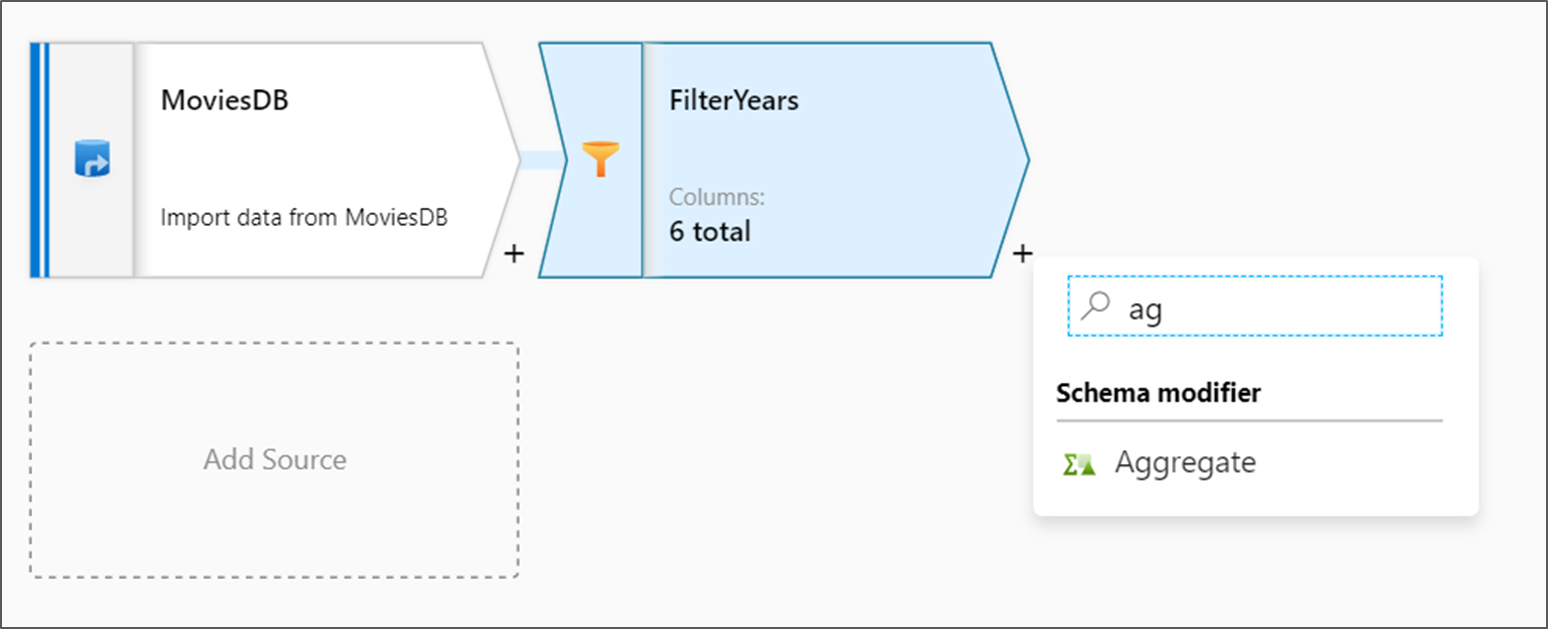
Ge din aggregerade omvandling namnet AggregateComedyRating. På fliken Gruppera efter väljer du år i listrutan för att gruppera aggregeringarna efter året då filmen kom ut.
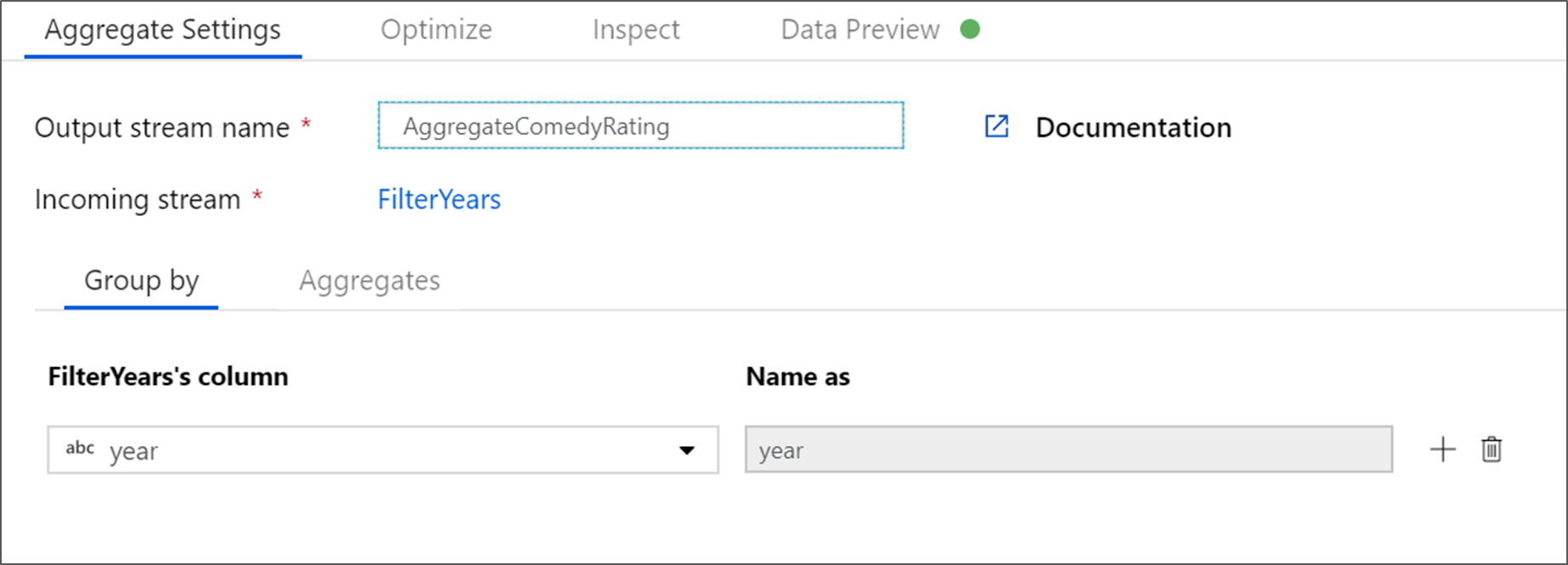
Gå till fliken Aggregeringar . I den vänstra textrutan namnger du samlingskolumnen AverageComedyRating. Välj den högra uttrycksrutan för att ange samlingsuttrycket via uttrycksverktyget.
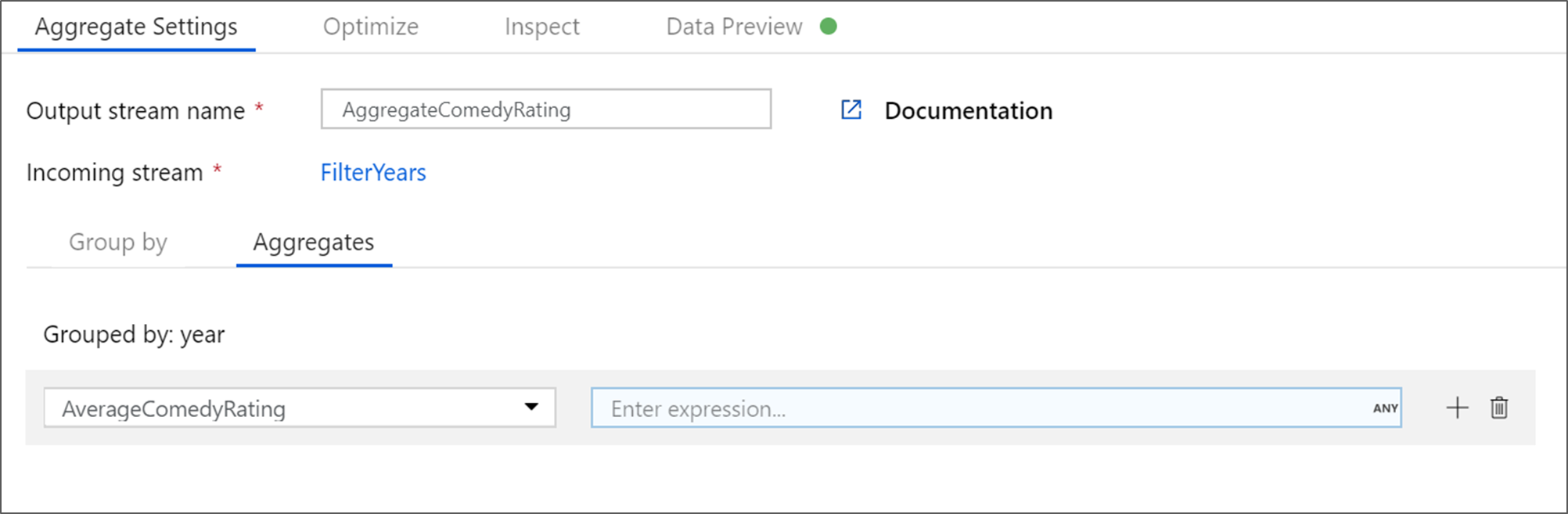
Om du vill få medelvärdet av kolumnklassificering använder du aggregeringsfunktionen
avg(). Eftersom Klassificering är en sträng ochavg()tar in numeriska indata måste vi konvertera värdet till ett tal viatoInteger()funktionen. Det här uttrycket ser ut så här:avg(toInteger(Rating))Välj Spara och slutför när du är klar.

Gå till fliken Dataförhandsgranskning för att visa transformeringsutdata. Observera att endast två kolumner finns där, year och AverageComedyRating.
Lägg till mottagartransformeringen
Sedan vill du lägga till en sink-transformering under Mål.
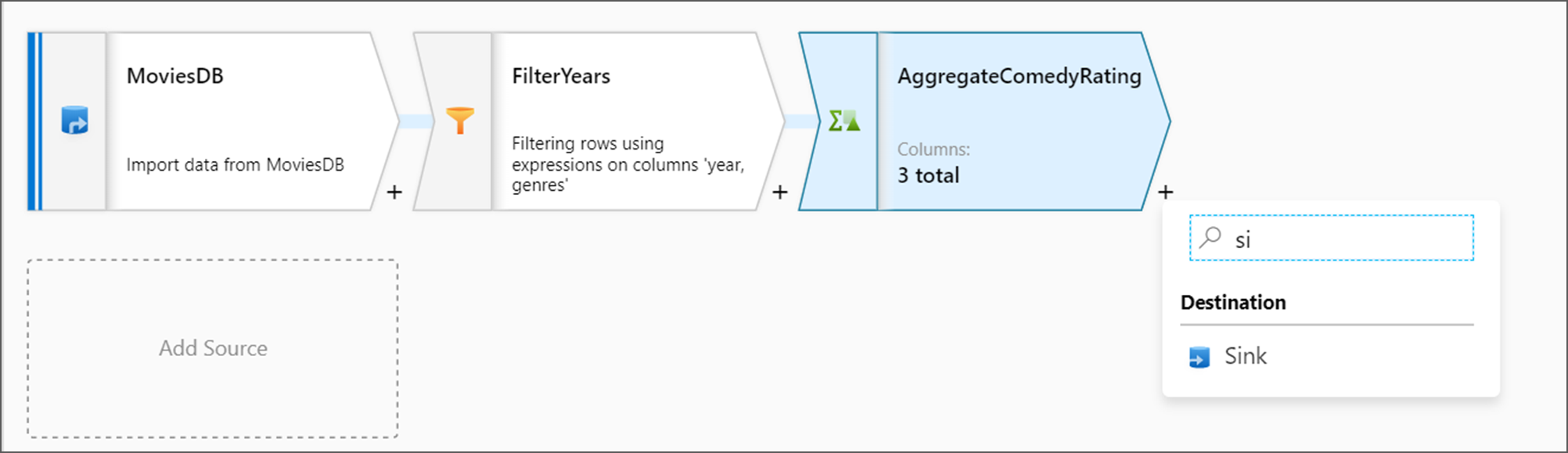
Ge mottagaren namnet Sink. Välj Ny för att skapa datauppsättningen för mottagare.
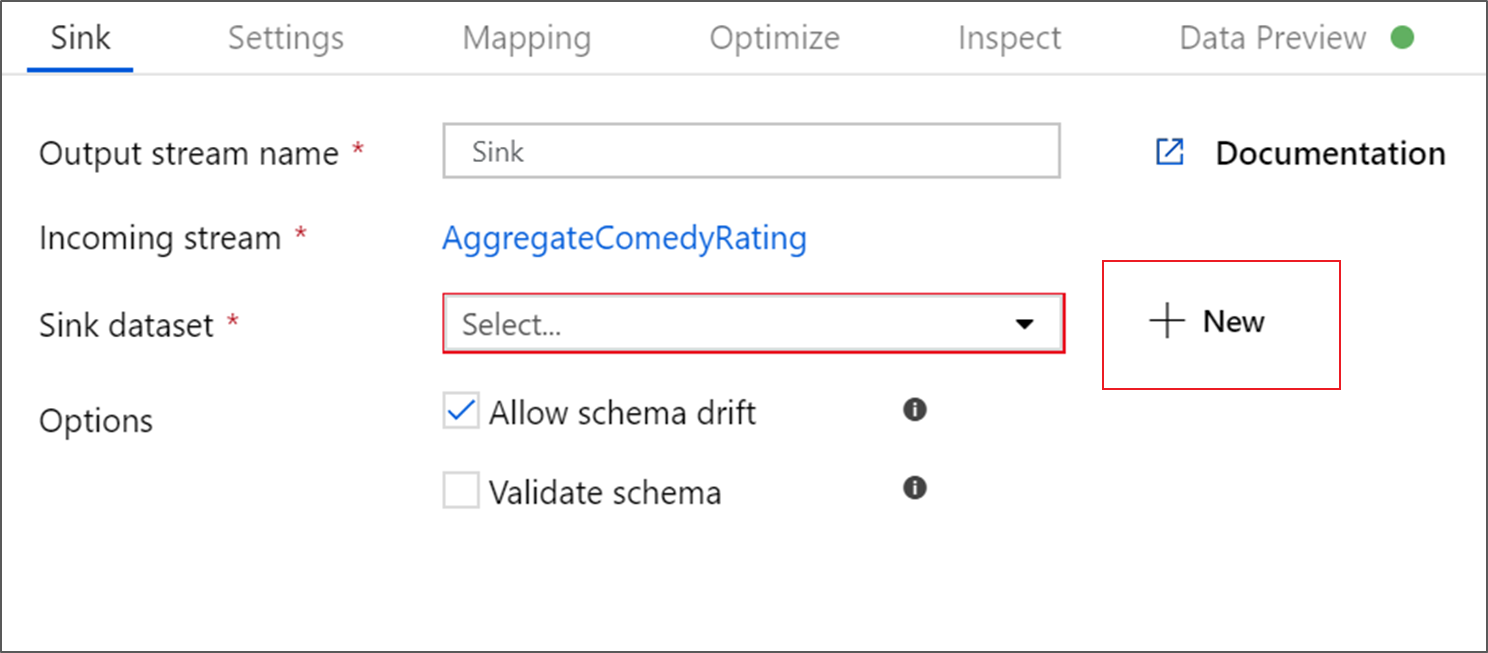
På sidan Ny datauppsättning väljer du Azure Data Lake Storage Gen2 och sedan Fortsätt.
På sidan Välj format väljer du AvgränsadText och väljer sedan Fortsätt.
Ge mottagarens datauppsättning namnet MoviesSink. För länkad tjänst väljer du samma länkade ADLSGen2-tjänst som du skapade för källtransformering. Ange en utdatamapp att skriva dina data till. I den här självstudien skriver vi till mapputdata i containern sample-data. Mappen behöver inte finnas i förväg och kan skapas dynamiskt. Markera kryssrutan Första raden som rubrik och välj Ingen för importschema. Välj OK.
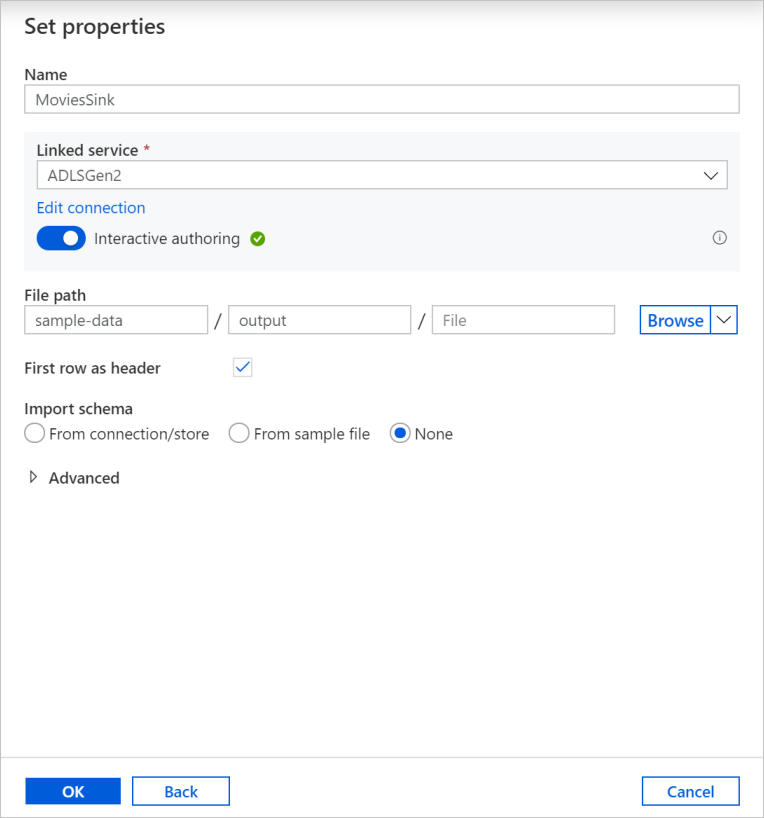
Nu har du skapat dataflödet. Du är redo att köra den i pipelinen.
Köra och övervaka dataflödet
Du kan felsöka en pipeline innan du publicerar den. I det här steget utlöser du en felsökningskörning av dataflödespipelinen. Även om dataförhandsgranskningen inte skriver data, skriver en felsökningskörning data till målmottagaren.
Gå till pipelinearbetsytan. Välj Felsök för att utlösa en felsökningskörning.
Pipeline-felsökning av dataflödesaktiviteter använder det aktiva felsökningsklustret, men det tar fortfarande minst en minut att initiera. Du kan spåra förloppet via fliken Utdata . När körningen är klar väljer du glasögonikonen för körningsinformation.
På informationssidan kan du se antalet rader och den tid som ägnas åt varje transformeringssteg.
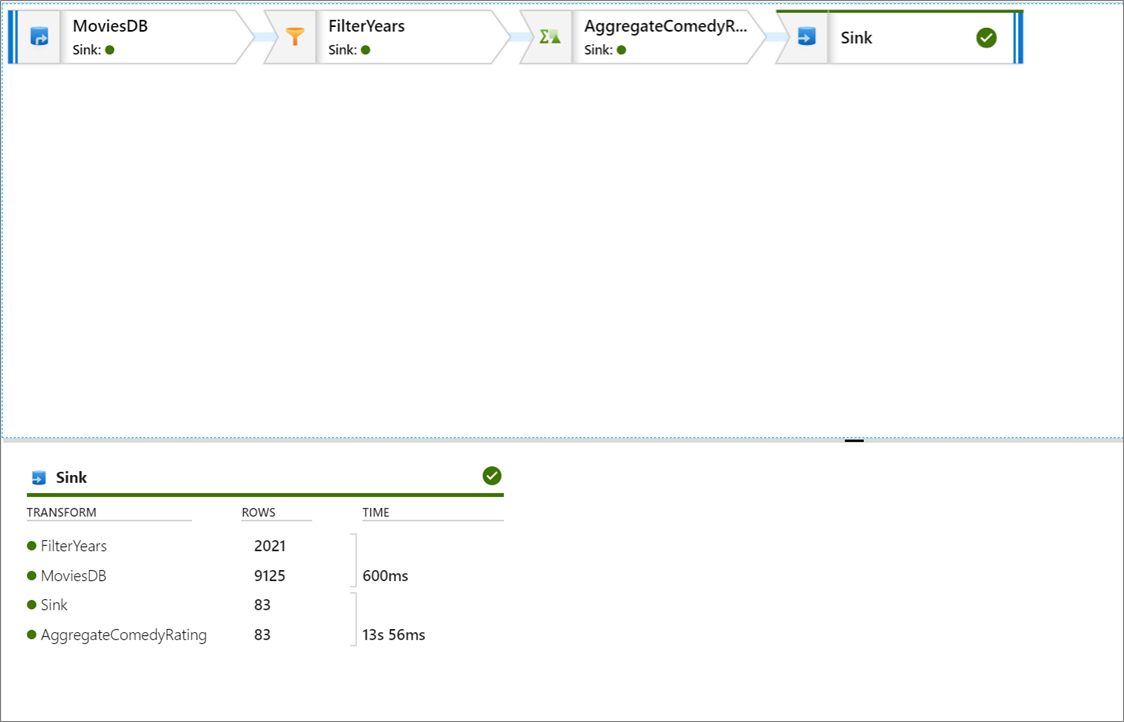
Välj en transformering för att få detaljerad information om kolumnerna och partitioneringen av data.
Om du har följt den här självstudien korrekt bör du ha skrivit 83 rader och 2 kolumner i din mottagarmapp. Du kan kontrollera att data är korrekta genom att kontrollera bloblagringen.
Sammanfattning
I den här självstudien använde du användargränssnittet för Data Factory för att skapa en pipeline som kopierar och transformerar data från en Data Lake Storage Gen2-källa till en Data Lake Storage Gen2-mottagare (båda tillåter åtkomst till endast valda nätverk) med hjälp av mappning av dataflödet i Data Factory Managed Virtual Network.