Äldre MLflow-modellbetjäning på Azure Databricks
Viktigt!
Den här funktionen finns som allmänt tillgänglig förhandsversion.
Viktigt!
- Den här dokumentationen har dragits tillbaka och kanske inte uppdateras. De produkter, tjänster eller tekniker som nämns i det här innehållet stöds inte längre.
- Vägledningen i den här artikeln gäller för äldre MLflow-modellservering. Databricks rekommenderar att du migrerar din modell som betjänar arbetsflöden till Modellservering för förbättrad modellslutpunktsdistribution och skalbarhet. Mer information finns i Distribuera modeller med hjälp av Mosaic AI Model Serving.
Med äldre MLflow Model Serving kan du vara värd för maskininlärningsmodeller från Model Registry som REST-slutpunkter som uppdateras automatiskt baserat på tillgängligheten för modellversioner och deras faser. Den använder ett kluster med en nod som körs under ditt eget konto inom det som nu kallas det klassiska beräkningsplanet. Det här beräkningsplanet innehåller det virtuella nätverket och dess associerade beräkningsresurser, till exempel kluster för notebook-filer och jobb, pro och klassiska SQL-lager och äldre modell som betjänar slutpunkter.
När du aktiverar modellservering för en viss registrerad modell skapar Azure Databricks automatiskt ett unikt kluster för modellen och distribuerar alla icke-arkiverade versioner av modellen i klustret. Azure Databricks startar om klustret om ett fel inträffar och avslutar klustret när du inaktiverar modellservern för modellen. Modellen som betjänar synkroniseras automatiskt med Model Registry och distribuerar alla nya registrerade modellversioner. Distribuerade modellversioner kan efterfrågas med en REST API-standardbegäran. Azure Databricks autentiserar begäranden till modellen med sin standardautentisering.
Även om den här tjänsten är i förhandsversion rekommenderar Databricks att den används för låg dataflöde och icke-kritiska program. Målets dataflöde är 200 qps och måltillgängligheten är 99,5 %, men ingen garanti görs om det heller. Dessutom finns det en storleksgräns för nyttolasten på 16 MB per begäran.
Varje modellversion distribueras med MLflow-modelldistribution och körs i en Conda-miljö som anges av dess beroenden.
Kommentar
- Klustret underhålls så länge servering är aktiverat, även om det inte finns någon aktiv modellversion. Om du vill avsluta serverklustret inaktiverar du modellservern för den registrerade modellen.
- Klustret betraktas som ett kluster för alla syften, med förbehåll för prissättning för arbetsbelastningar för alla syften.
- Globala init-skript körs inte på modell som betjänar kluster.
Viktigt!
Anaconda Inc. uppdaterade sina tjänstvillkor för anaconda.org kanaler. Baserat på de nya tjänstvillkoren kan du kräva en kommersiell licens om du förlitar dig på Anacondas paketering och distribution. Mer information finns i Vanliga frågor och svar om Anaconda Commercial Edition. Din användning av Anaconda-kanaler styrs av deras användarvillkor.
MLflow-modeller som loggades före v1.18 (Databricks Runtime 8.3 ML eller tidigare) loggades som standard med conda-kanalen defaults (https://repo.anaconda.com/pkgs/) som ett beroende. På grund av den här licensändringen defaults har Databricks stoppat användningen av kanalen för modeller som loggats med MLflow v1.18 och senare. Standardkanalen som loggas är nu conda-forge, som pekar på den communityhanterade https://conda-forge.org/.
Om du loggade en modell före MLflow v1.18 utan att utesluta defaults kanalen från conda-miljön för modellen, kan den modellen ha ett beroende av den defaults kanal som du kanske inte har tänkt dig.
För att manuellt bekräfta om en modell har det här beroendet kan du undersöka channel värdet i conda.yaml filen som är paketerad med den loggade modellen. En modell med conda.yaml ett defaults kanalberoende kan till exempel se ut så här:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Eftersom Databricks inte kan avgöra om din användning av Anaconda-lagringsplatsen för att interagera med dina modeller är tillåten under din relation med Anaconda, tvingar Databricks inte sina kunder att göra några ändringar. Om din användning av Anaconda.com lagringsplats genom användning av Databricks är tillåten enligt Anacondas villkor behöver du inte vidta några åtgärder.
Om du vill ändra den kanal som används i en modells miljö kan du registrera om modellen till modellregistret med en ny conda.yaml. Du kan göra detta genom att ange kanalen i parametern conda_envlog_model()för .
Mer information om API:et finns i log_model() MLflow-dokumentationen för modellsmaken som du arbetar med, till exempel log_model för scikit-learn.
Mer information om conda.yaml filer finns i MLflow-dokumentationen.
Krav
- Äldre MLflow-modellservering är tillgänglig för Python MLflow-modeller. Du måste deklarera alla modellberoenden i conda-miljön. Se Loggmodellberoenden.
- Om du vill aktivera modellservern måste du ha behörighet att skapa kluster.
Modell som betjänar från Modellregister
Modellservern är tillgänglig i Azure Databricks från Model Registry.
Aktivera och inaktivera modellservering
Du aktiverar en modell för servering från dess registrerade modellsida.
Klicka på fliken Servering . Om modellen inte redan är aktiverad för servering visas knappen Aktivera servering .
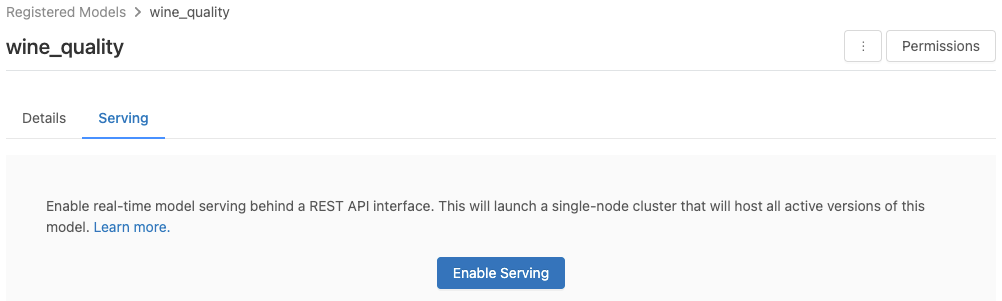
Klicka på Aktivera servering. Fliken Servering visas med Status visas som Väntar. Efter några minuter ändras Status till Klar.
Om du vill inaktivera en modell för servering klickar du på Stoppa.
Verifiera modellservering
På fliken Servering kan du skicka en begäran till den betjänade modellen och visa svaret.
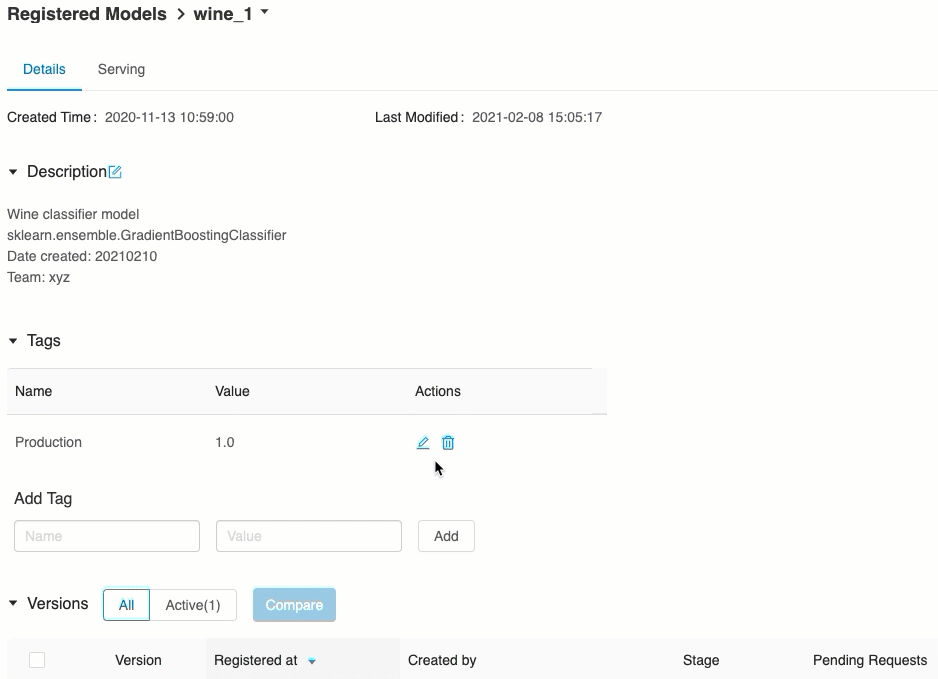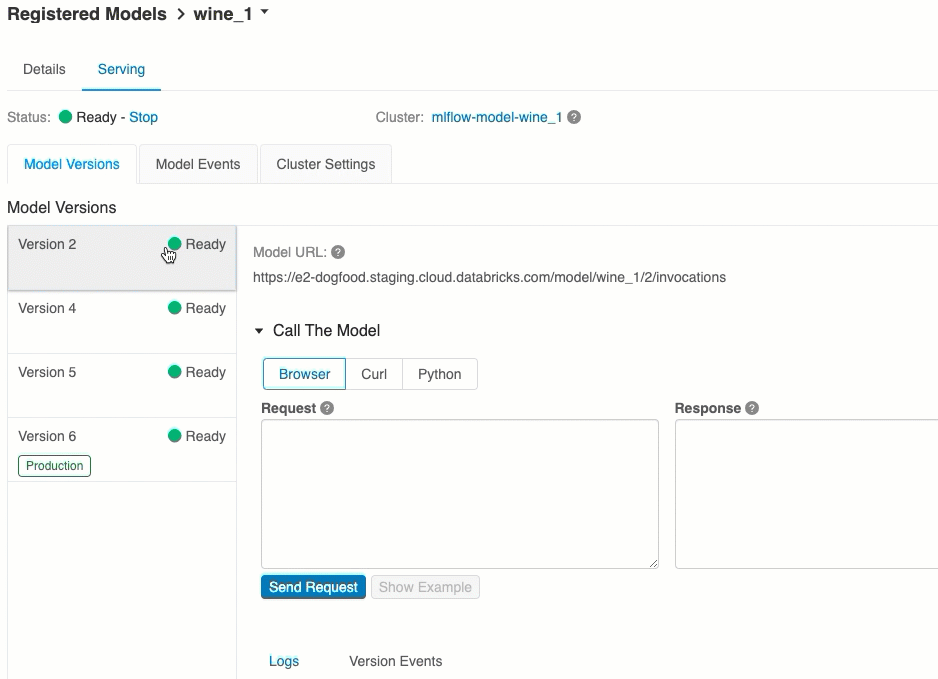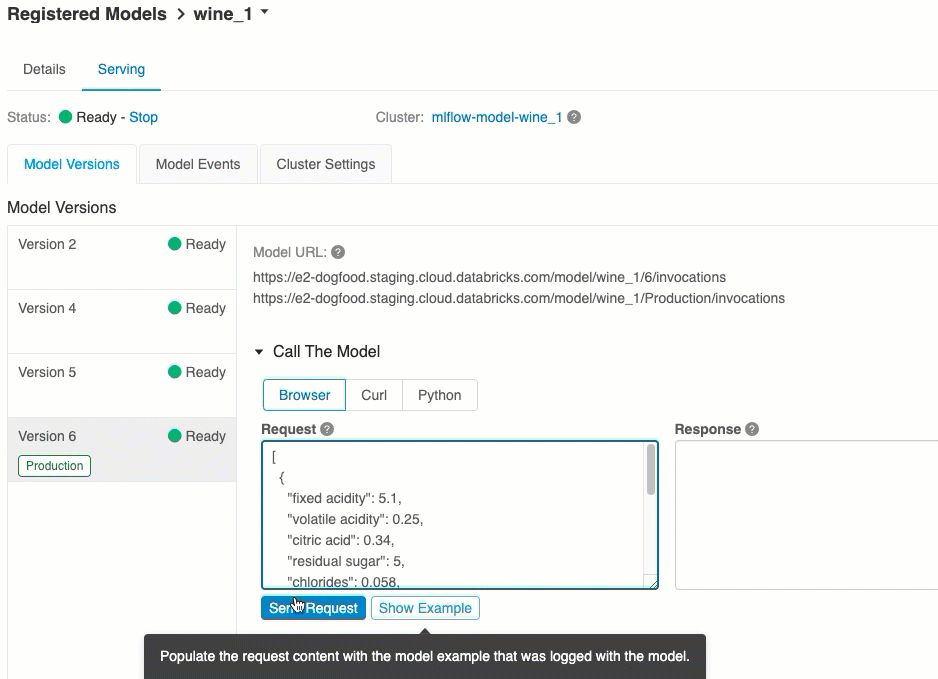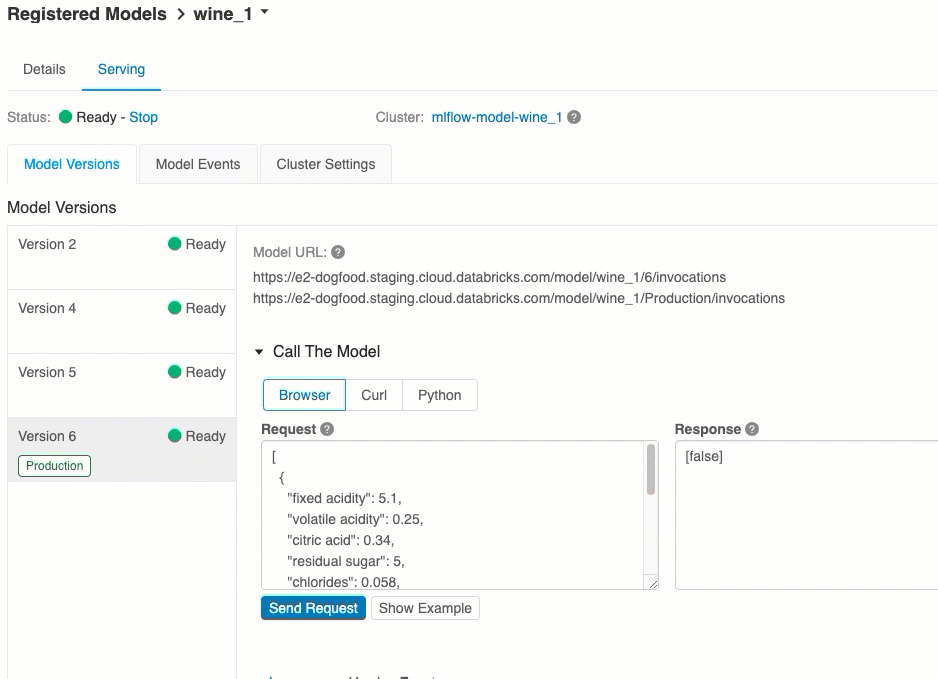
URI:er för modellversion
Varje distribuerad modellversion tilldelas en eller flera unika URI:er. Minst tilldelas varje modellversion en URI som konstruerats på följande sätt:
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
Om du till exempel vill anropa version 1 av en modell som registrerats som iris-classifieranvänder du den här URI:n:
https://<databricks-instance>/model/iris-classifier/1/invocations
Du kan också anropa en modellversion efter dess fas. Om version 1 till exempel är i produktionsfasen kan den också poängsätts med hjälp av den här URI:n:
https://<databricks-instance>/model/iris-classifier/Production/invocations
Listan över tillgängliga modell-URI:er visas överst på fliken Modellversioner på serversidan.
Hantera serverade versioner
Alla aktiva (icke-arkiverade) modellversioner distribueras och du kan köra frågor mot dem med hjälp av URI:erna. Azure Databricks distribuerar automatiskt nya modellversioner när de registreras och tar automatiskt bort gamla versioner när de arkiveras.
Kommentar
Alla distribuerade versioner av en registrerad modell delar samma kluster.
Hantera åtkomsträttigheter för modeller
Behörigheter för modellåtkomst ärvs från modellregistret. Aktivering eller inaktivering av serveringsfunktionen kräver "hantera"-behörighet för den registrerade modellen. Alla med läsbehörighet kan poängsätta någon av de distribuerade versionerna.
Poängsätta distribuerade modellversioner
Om du vill poängsätta en distribuerad modell kan du använda användargränssnittet eller skicka en REST API-begäran till modell-URI:n.
Poäng via användargränssnitt
Det här är det enklaste och snabbaste sättet att testa modellen. Du kan infoga modellens indata i JSON-format och klicka på Skicka begäran. Om modellen har loggats med ett indataexempel (som visas i bilden ovan) klickar du på Läs in exempel för att läsa in indataexemplet.
Poäng via REST API-begäran
Du kan skicka en bedömningsbegäran via REST-API:et med hjälp av standardautentisering med Databricks. Exemplen nedan visar autentisering med hjälp av en personlig åtkomsttoken med MLflow 1.x.
Kommentar
När du autentiserar med automatiserade verktyg, system, skript och appar rekommenderar Databricks att du använder personliga åtkomsttoken som tillhör tjänstens huvudnamn i stället för arbetsyteanvändare. Information om hur du skapar token för tjänstens huvudnamn finns i Hantera token för tjänstens huvudnamn.
Med en MODEL_VERSION_URI som https://<databricks-instance>/model/iris-classifier/Production/invocations (där <databricks-instance> är namnet på din Databricks-instans) och en Databricks REST API-token med namnet DATABRICKS_API_TOKENvisar följande exempel hur du frågar efter en hanterad modell:
Följande exempel återspeglar bedömningsformatet för modeller som skapats med MLflow 1.x. Om du föredrar att använda MLflow 2.0 måste du uppdatera nyttolastformatet för begäran.
Bash
Kodfragment för att fråga en modell som accepterar dataramsindata.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
Kodfragment för att fråga en modell som accepterar tensor-indata. Tensor-indata ska formateras enligt beskrivningen i TensorFlow Servings API-dokument.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
Power BI
Du kan poängsätta en datauppsättning i Power BI Desktop med hjälp av följande steg:
Öppna datauppsättningen som du vill poängsätta.
Gå till Transformera data.
Högerklicka på den vänstra panelen och välj Skapa ny fråga.
Gå till Visa > Avancerad redigerare.
Ersätt frågetexten med kodfragmentet nedan när du har fyllt i en lämplig
DATABRICKS_API_TOKENochMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionNamnge frågan med önskat modellnamn.
Öppna den avancerade frågeredigeraren för datamängden och tillämpa modellfunktionen.
Övervaka serverade modeller
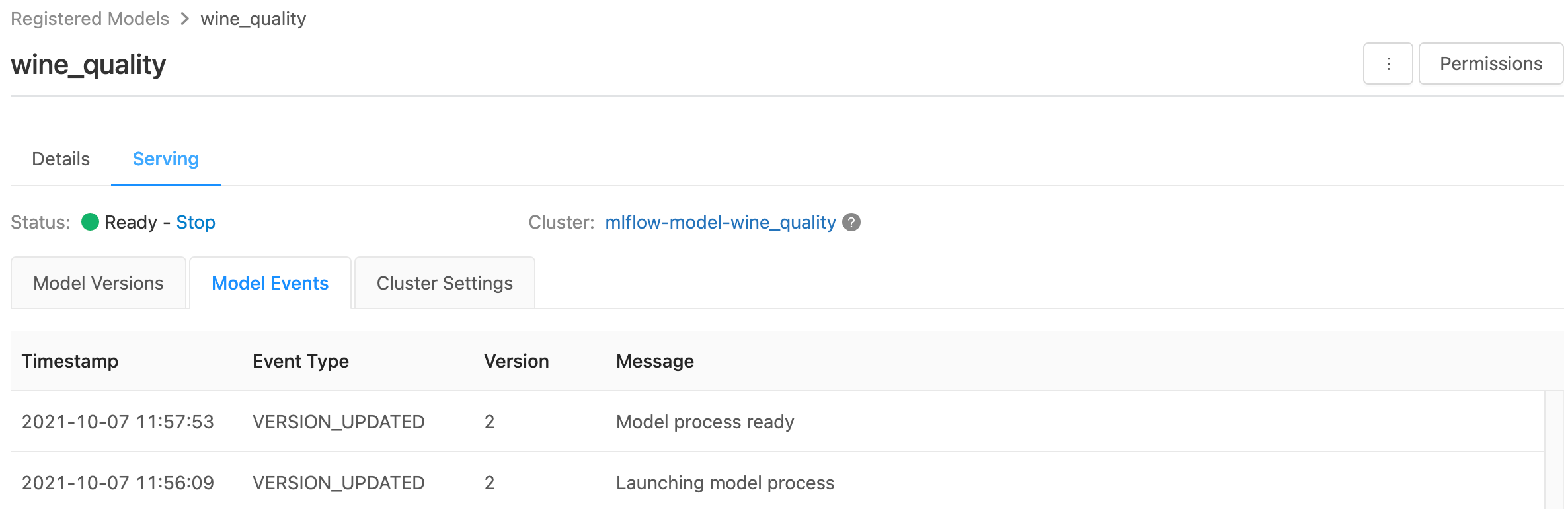
På serversidan visas statusindikatorer för det betjänande klustret samt enskilda modellversioner.
- Om du vill kontrollera tillståndet för serverdelsklustret använder du fliken Modellhändelser, som visar en lista över alla serveringshändelser för den här modellen.
- Om du vill kontrollera tillståndet för en enskild modellversion klickar du på fliken Modellversioner och bläddrar för att visa flikarna Loggar eller Versionshändelser.
Anpassa serverklustret
Om du vill anpassa serverklustret använder du fliken Klusterinställningar på fliken Servering .
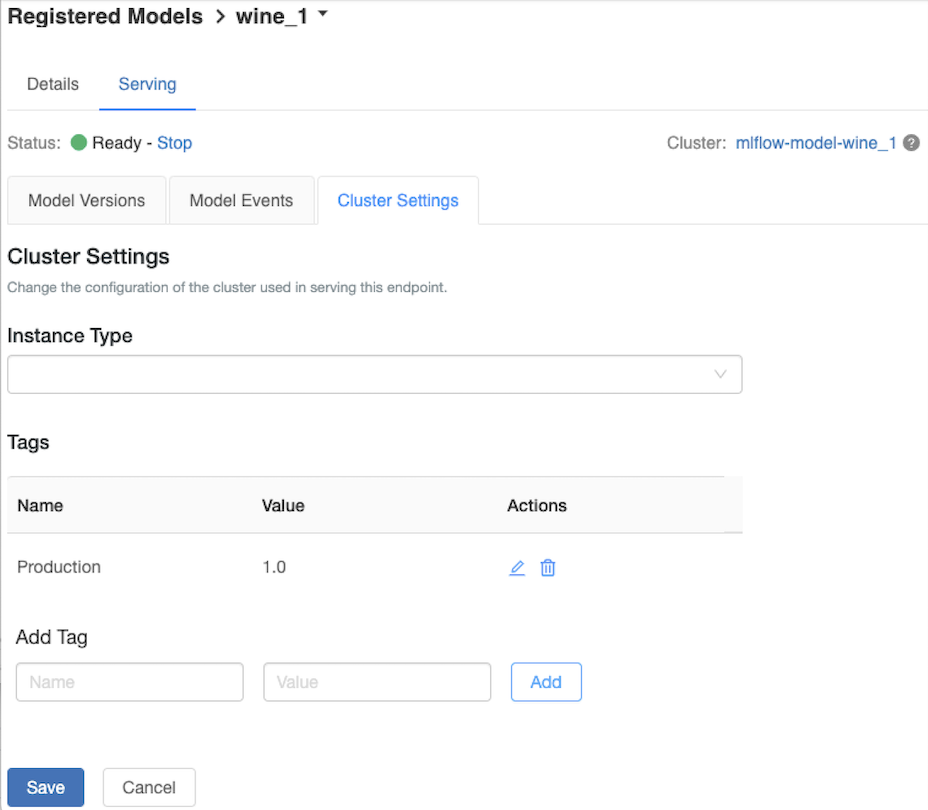
- Om du vill ändra minnesstorleken och antalet kärnor i ett serverkluster använder du listrutan Instanstyp för att välja önskad klusterkonfiguration. När du klickar på Spara avslutas det befintliga klustret och ett nytt kluster skapas med de angivna inställningarna.
- Om du vill lägga till en tagg skriver du namnet och värdet i fälten Lägg till tagg och klickar på Lägg till.
- Om du vill redigera eller ta bort en befintlig tagg klickar du på en av ikonerna i kolumnen Actions i tabellen Tags.
Integrering av funktionslager
Äldre modellservering kan automatiskt slå upp funktionsvärden från publicerade onlinebutiker.
.. aws:
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Amazon DynamoDB (v0.3.8 and above)
- Amazon Aurora (MySQL-compatible)
- Amazon RDS MySQL
.. azure::
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Azure Cosmos DB (v0.5.0 and above)
- Azure Database for MySQL
Kända fel
ResolvePackageNotFound: pyspark=3.1.0
Det här felet kan inträffa om en modell är beroende av pyspark och loggas med Databricks Runtime 8.x.
Om du ser det här felet anger du pyspark versionen explicit när du loggar modellen med hjälp av parameternconda_env .
Unrecognized content type parameters: format
Det här felet kan inträffa till följd av det nya MLflow 2.0-bedömningsprotokollformatet. Om du ser det här felet använder du förmodligen ett inaktuellt bedömningsbegärandeformat. Du kan lösa felet genom att:
Uppdatera formatet för bedömningsbegäran till det senaste protokollet.
Kommentar
Följande exempel återspeglar bedömningsformatet som introducerades i MLflow 2.0. Om du föredrar att använda MLflow 1.x kan du ändra DINA
log_model()API-anrop så att de inkluderar önskat MLflow-versionsberoende i parameternextra_pip_requirements. Detta säkerställer att rätt bedömningsformat används.mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
Fråga en modell som accepterar pandas-dataramsindata.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'Fråga en modell som accepterar tensor-indata. Tensor-indata ska formateras enligt beskrivningen i TensorFlow Servings API-dokument.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)Power BI
Du kan poängsätta en datauppsättning i Power BI Desktop med hjälp av följande steg:
Öppna datauppsättningen som du vill poängsätta.
Gå till Transformera data.
Högerklicka på den vänstra panelen och välj Skapa ny fråga.
Gå till Visa > Avancerad redigerare.
Ersätt frågetexten med kodfragmentet nedan när du har fyllt i en lämplig
DATABRICKS_API_TOKENochMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionNamnge frågan med önskat modellnamn.
Öppna den avancerade frågeredigeraren för datamängden och tillämpa modellfunktionen.
Om din bedömningsbegäran använder MLflow-klienten, till exempel
mlflow.pyfunc.spark_udf(), uppgraderar du MLflow-klienten till version 2.0 eller senare för att använda det senaste formatet. Läs mer om det uppdaterade MLflow Model-bedömningsprotokollet i MLflow 2.0.
Mer information om indataformat som godkänts av servern (till exempel pandas split-oriented format) finns i MLflow-dokumentationen.