Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
Den här dokumentationen har dragits tillbaka och kanske inte uppdateras. De produkter, tjänster eller tekniker som nämns i det här innehållet stöds inte längre. Se Utökad support för Databricks Light 2.4.
Databricks Light är Databricks-paketeringen för öppen källkod Apache Spark-körning. Det ger ett körningsalternativ för jobb som inte behöver de avancerade prestanda-, tillförlitlighets- eller autoskalningsfördelarna som tillhandahålls av Databricks Runtime. I synnerhet stöder Inte Databricks Light:
- Delta Lake
- Autopilot-funktioner som autoskaleringsfunktioner
- Högeffektiva och mångsidiga kluster
- Notebooks, dashboards och samarbetsfunktioner
- Kopplingar till olika datakällor och verksamhetsanalysverktyg
Databricks Light är en körmiljö för uppgifter (eller "automatiserade arbetsbelastningar"). När du kör jobb i Databricks Light-kluster omfattas de av lägre priser för lätt beräkning av jobb. Du kan bara välja Databricks Light när du skapar eller schemalägger ett JAR-, Python- eller spark-submit-jobb och kopplar ett kluster till det jobbet. Du kan inte använda Databricks Light för att köra notebook-jobb eller interaktiva arbetsbelastningar.
Databricks Light kan användas på samma arbetsyta med kluster som körs på andra Databricks-körningsnivåer och prisnivåer. Du behöver inte begära en separat arbetsyta för att komma igång.
Vad finns i Databricks Light?
Utgivningsschemat för Databricks Light-körmiljön följer utgivningsschemat för Apache Spark-körmiljön. Alla Databricks Light-versioner baseras på en specifik version av Apache Spark. Mer information finns i följande utgivningsanteckningar:
- Utökad support för Databricks Light 2.4
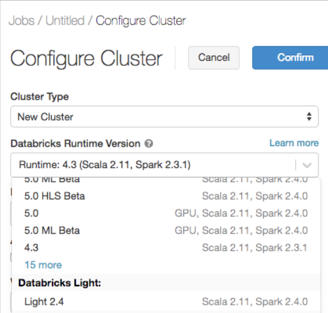
Skapa ett kluster med Databricks Light
När du skapar ett jobbkluster väljer du en Databricks Light-version från listrutan Databricks Runtime Version.
Viktigt!
Stöd för Databricks Light på poolbaserade jobbkluster finns i offentlig förhandsversion.