Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln beskriver hur du använder det interna beräkningsmåttverktyget i Azure Databricks-användargränssnittet för att samla in viktig maskinvara och Spark-mått. Gränssnittet för mätningar är tillgängligt för beräkningar för alla ändamål och jobb.
Mått är tillgängliga i nästan realtid med en normal fördröjning på mindre än en minut. Mätvärden lagras i Azure Databricks-hanterad lagring, inte i kundens lagring.
Serverlös beräkning för notebook-filer och jobb använder frågeinsikter i stället för måttgränssnittet. Mer information om serverlösa beräkningsmått finns i Visa frågeinsikter.
Åtkomst till användargränssnittet för beräkningsmått
Så här visar du användargränssnittet för beräkningsmått:
- Klicka på Beräkna i sidofältet.
- Klicka på den beräkningsresurs som du vill visa mått för.
- Klicka på fliken Mått .
Maskinvarumått för alla noder visas som standard. Om du vill visa Spark-mått klickar du på den nedrullningsbara menyn med etiketten Maskinvara och väljer Spark. Du kan också välja GPU om instansen är GPU-aktiverad.
Filtrera mått efter tidsperiod
Du kan visa historiska mått genom att välja ett tidsintervall med hjälp av datumväljarens filter. Mått samlas in varje minut, så du kan filtrera efter valfritt intervall av dag, timme eller minut från de senaste 30 dagarna. Klicka på kalenderikonen för att välja mellan fördefinierade dataintervall eller klicka i textrutan för att definiera anpassade värden.
Kommentar
Tidsintervallen som visas i diagrammen justeras baserat på den tidsperiod du tittar på. De flesta mått är medelvärden baserat på det tidsintervall som du för närvarande visar.
Du kan också hämta de senaste måtten genom att klicka på knappen Uppdatera .
Visa mått på nodnivå
Som standard visar måttsidan mått för alla noder i ett kluster (inklusive drivrutinen) i genomsnitt under tidsperioden.
Du kan visa mått för enskilda noder genom att klicka på listrutan Alla noder och välja den nod som du vill visa mått för. GPU-mått är endast tillgängliga på nivån enskild nod. Spark-mått är inte tillgängliga för enskilda noder.
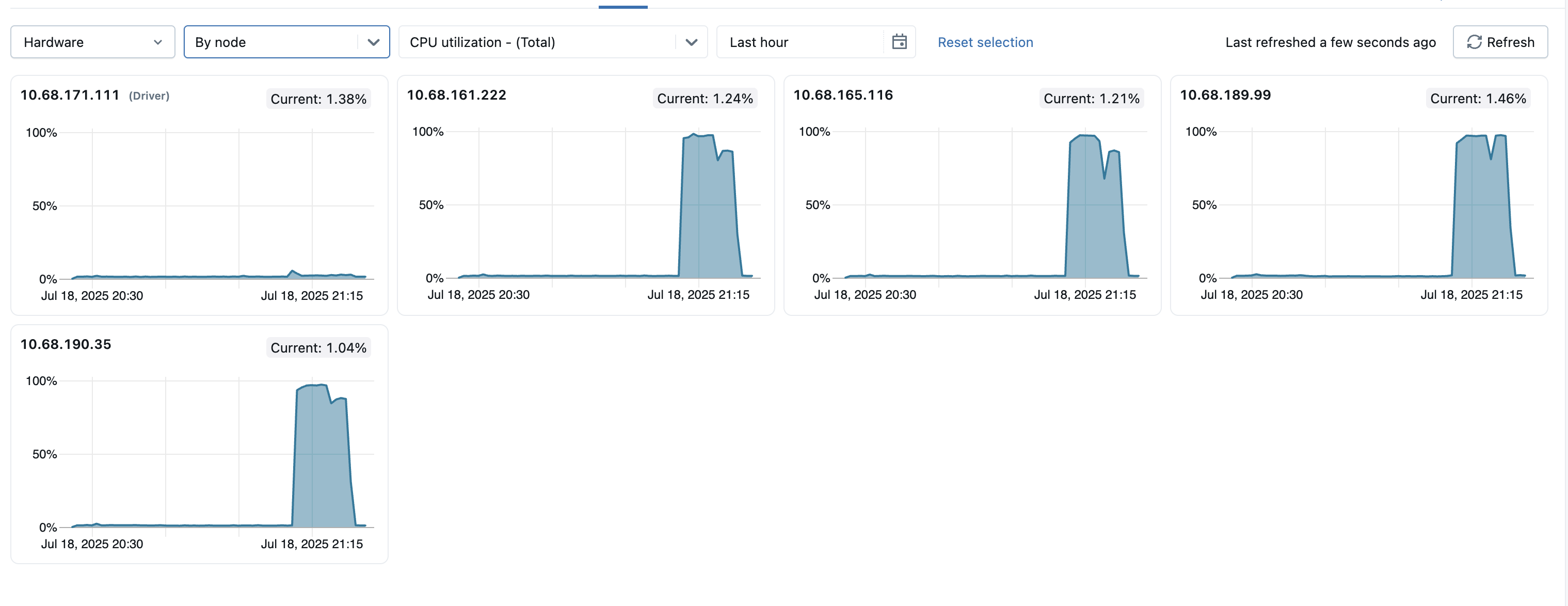
För att identifiera avvikande noder i klustret kan du även visa mått för alla enskilda noder på en enda sida. Om du vill komma åt den här vyn klickar du på listrutan Alla noder och väljer Efter nod och väljer sedan den måttunderkategori som du vill visa.
Maskinvarumåttdiagram
Följande maskinvarumåttdiagram är tillgängliga för visning i användargränssnittet för beräkningsmått:
-
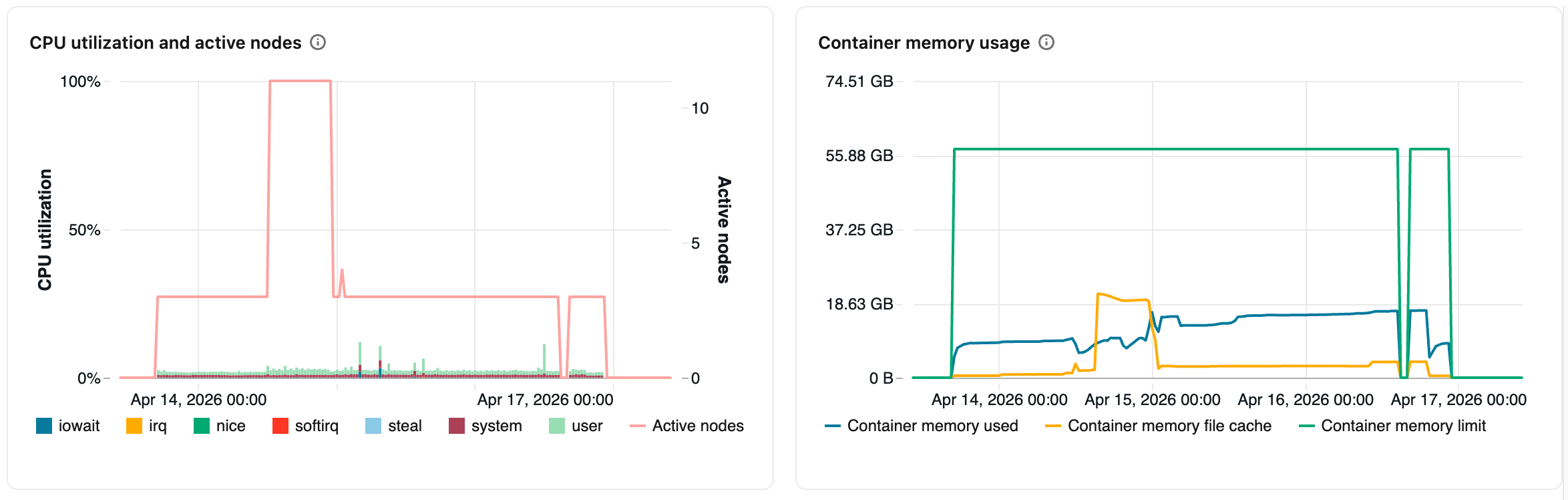
CPU-användning och aktiva noder: Linjediagrammet visar antalet aktiva noder vid varje tidsstämpel för den angivna beräkningen. Stapeldiagrammet visar procentandelen av den tid som processorn spenderade i varje läge, baserat på den totala kostnaden för CPU-sekunder. Följande är de spårade lägena:
-
guest: Om du kör virtuella datorer använder den processor som de virtuella datorerna använder -
iowait: Tid som ägnas åt att vänta på I/O -
idle: Tid då processorn inte hade något att göra -
irq: Tid som ägnas åt avbrottsbegäranden -
nice: Tid som används av processer med ett positivt niceness-värde, vilket innebär en lägre prioritet än andra processer. -
softirq: Tidsåtgång för programavbrottsförfrågningar -
steal: Om du är en virtuell dator, tid som andra virtuella datorer tog i anspråk från dina processorer -
system: Den tid som spenderas i kerneln -
user: Den tid som tillbringas i användarlandet
-
-
Användning av containerminne: Det minne som förbrukas av Spark-containern, i genomsnitt för alla tillämpliga noder. Innehåller medelvärden för minne som inte kan frigöras (
Container memory used), os-filsidans cache (Container memory file cache) och den konfigurerade minnesgränsen (Container memory limit). - JVM-heapanvändning: JVM-heapminnesanvändningen, i genomsnitt för alla tillämpliga noder. Innehåller genomsnitt för den faktiska heapanvändningen, heapkapaciteten och den konfigurerade maximala heapgränsen.
- Mottagna och skickade data i nätverket: Antalet byte som tas emot och överförs via nätverket av varje enhet.
- Ledigt filsystemutrymme: Den totala filsystemanvändningen per monteringspunkt, mätt i byte.
Klicka på Nodminnesanvändning längst ned på fliken Maskinvara för att expandera följande ytterligare diagram:
-
Minnesanvändning och byte: Linjediagrammet visar den totala minnesväxlingsanvändningen efter läge, mätt i byte. Stapeldiagrammet visar den totala minnesanvändningen efter läge, även mätt i byte. Följande användningstyper spåras:
-
used: Totalt minne på os-nivå som används, inklusive minne som används av bakgrundsprocesser som körs på en beräkning. Eftersom drivrutinen och bakgrundsprocesserna använder minne kan användningen fortfarande visas även när inga Spark-jobb körs. -
other: Minne som används i andra syften änused,bufferellercached -
buffer: Minne som används av kernelbuffertar -
cached: Minne som används av filsystemets cacheminne på OS-nivå -
free: Oanvänd minne. Allt som inte tillskrivs någon av ovanstående kategorier i diagrammet är kostnadsfritt.
-
Spark-måttdiagram
Följande Spark-måttdiagram är tillgängliga för visning i användargränssnittet för beräkningsmått:
- Distribution av serverbelastning: Dessa paneler visar processoranvändningen under den senaste minuten för varje nod i beräkningsresursen. Varje panel är en klickbar länk till den enskilda nodens måttsida.
- Aktiva uppgifter: Det totala antalet aktiviteter som körs vid en viss tidpunkt.
- Totalt antal misslyckade uppgifter: Det totala antalet uppgifter som har misslyckats i utförare.
- Totalt antal slutförda uppgifter: Det totala antalet aktiviteter som har slutförts i köre.
- Totalt antal aktiviteter: Det totala antalet aktiviteter (körs, misslyckades och slutfördes) i exekutorer.
-
Total shuffle-läsning: Den totala storleken på shuffle-läsningsdata, mätt i bytes.
Shuffle readinnebär summan av serialiserade läsdata på alla utförare i början av en fas. -
Total shuffle-skrivning: Den totala storleken på shuffle-skrivdata, mätt i byte.
Shuffle Writeär summan av alla skriftliga serialiserade data på alla utförare innan de överförs (normalt i slutet av ett stadium). - Total aktivitetsvaraktighet: Den totala förflutna tiden som JVM ägnade åt att utföra uppgifter på utförare, mätt i sekunder.
GPU-mätningsdiagram
Kommentar
GPU-mått är endast tillgängliga på Databricks Runtime ML 13.3 och senare.
Följande GPU-måttdiagram är tillgängliga att visa i användargränssnittet för beräkningsmått:
- Distribution av serverbelastning: Det här diagrammet visar processoranvändningen under den senaste minuten för varje nod.
- Per-GPU avkodaranvändning: Procentandelen GPU-avkodaranvändning.
- Per-GPU kodaranvändning: Procentandelen GPU-kodaranvändning.
- Per-GPU bildrutebuffertens minnesanvändningsbyte: Bildrutebuffertens minnesanvändning, mätt i byte.
- Per-GPU minnesanvändning: Procentandelen GPU-minnesanvändning.
- Per-GPU användning: Procentandelen GPU-användning.
Felsökning
Om du ser ofullständiga eller saknade mått under en period kan det vara något av följande problem:
- Ett avbrott i Databricks-tjänsten som ansvarar för att fråga och lagra mått.
- Nätverksproblem på kundens sida.
- Beräkningsprocessen är eller var i ett ohälsosamt tillstånd.