Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln beskriver hur du skapar en beräkningsresurs som tilldelats en grupp med hjälp av åtkomstläget Dedikerad.
Med det dedikerade läget för gruppåtkomst kan användarna få drifteffektivitet för ett standardkluster för åtkomstläge samtidigt som de på ett säkert sätt stöder språk och arbetsbelastningar som inte stöds av standardåtkomstläget, till exempel Databricks Runtime för ML, RDD-API:er och R.
Krav
Så här använder du det dedikerade åtkomstläget för grupper:
- Arbetsytan måste vara aktiverad för Unity Catalog.
- Du måste använda Databricks Runtime 15.4 eller senare.
- Den tilldelade gruppen måste ha
CAN MANAGEbehörigheter för en arbetsytamapp där de kan behålla anteckningsfiler, ML-experiment och andra arbetsytaartefakter som används av gruppklustret.
Vad är dedikerat åtkomstläge?
Dedikerat åtkomstläge är den senaste versionen av enanvändarläget. Med dedikerad åtkomst kan en beräkningsresurs tilldelas till en enskild användare eller grupp, vilket endast ger de tilldelade användarna åtkomst att använda beräkningsresursen.
När en användare är ansluten till en beräkningsresurs som är dedikerad till en grupp (ett gruppkluster) minskar användarens behörigheter automatiskt till gruppens behörigheter, vilket gör att användaren på ett säkert sätt kan dela resursen med de andra medlemmarna i gruppen.
Skapa en beräkningsresurs som är dedikerad till en grupp
- På din Azure Databricks-arbetsyta går du till Compute och klickar på Skapa beräkning.
- Expandera avsnittet Avancerat.
- Under Åtkomstlägeklickar du på Manuell och väljer sedan Dedicated (tidigare: En användare) på den nedrullningsbara menyn.
- I fältet Enskild användare eller grupp väljer du den grupp som du vill tilldela den här resursen.
- Konfigurera de andra önskade beräkningsinställningarna och klicka sedan på Skapa.
Metodtips för att hantera gruppkluster
Eftersom användarbehörigheter begränsas till gruppen när du använder gruppkluster rekommenderar Databricks att du skapar en /Workspace/Groups/<groupName> mapp för varje grupp som du planerar att använda med ett gruppkluster. Tilldela sedan CAN MANAGE behörigheter för mappen till gruppen. På så sätt kan grupper undvika behörighetsfel. Alla gruppens notebook-filer och arbetsytetillgångar ska hanteras i gruppmappen.
Du måste också ändra följande arbetsbelastningar så att de körs på gruppkluster:
- MLflow: Kontrollera att du kör anteckningsboken från gruppmappen eller kör
mlflow.set_tracking_uri("/Workspace/Groups/<groupName>"). - AutoML: Ange den valfria parametern
experiment_dirtill“/Workspace/Groups/<groupName>”för dina AutoML-körningar. -
dbutils.notebook.run: Kontrollera att gruppen harREADbehörighet för anteckningsboken som utförs.
Behörighetsbeteende för gruppkluster
Alla kommandon, frågor och andra åtgärder som utförs i ett gruppkluster använder de behörigheter som tilldelats gruppen, inte den enskilda användaren.
Det går inte att tillämpa enskilda användarbehörigheter eftersom alla gruppmedlemmar har fullständig åtkomst till Spark-API:erna och den delade beräkningsmiljön. Om användarbaserade behörigheter tillämpades kan en medlem köra frågor mot begränsade data och en annan medlem utan åtkomst kan fortfarande hämta resultaten via den delade miljön. Därför måste själva gruppen, inte användaren som är medlem i gruppen, ha de behörigheter som krävs för att åtgärden ska kunna utföras.
Gruppen behöver till exempel explicit behörighet för att fråga en tabell, komma åt ett hemligt omfång eller en hemlighet, använda en Anslutningsautentiseringsuppgift för Unity Catalog, komma åt en Git-mapp eller skapa ett arbetsyteobjekt.
Exempel på gruppbehörigheter
När du skapar ett dataobjekt med hjälp av gruppklustret tilldelas gruppen som objektets ägare.
Om du till exempel har en notebook-fil kopplad till ett gruppkluster och kör följande kommando:
use catalog main;
create schema group_cluster_group_schema;
Kör sedan den här frågan för att kontrollera schemats ägare:
describe schema group_cluster_group_schema;
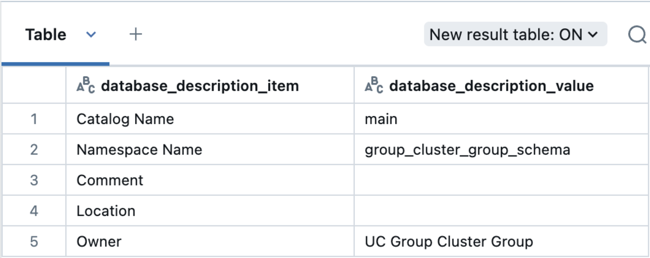
Dedikerad beräkningsaktivitet för granskningsgrupp
Det finns två viktiga identiteter när ett gruppkluster kör en arbetsbelastning:
- Den användare som hanterar arbetsbördan på gruppklustret
- Den grupp vars behörigheter används för att utföra de faktiska arbetsbelastningsåtgärderna
Systemtabellen revisionslogg registrerar dessa identiteter under följande parametrar:
-
identity_metadata.run_by: Den autentiserande användare som utför åtgärden -
identity_metadata.run_as: Den auktoriseringsgrupp vars behörigheter används för åtgärden.
I följande exempelfråga hämtas identitetsmetadata för en åtgärd som vidtas med gruppklustret:
select action_name, event_time, user_identity.email, identity_metadata
from system.access.audit
where user_identity.email = "uc-group-cluster-group" AND service_name = "unityCatalog"
order by event_time desc limit 100;
Visa systemtabellreferensen för granskningsloggen för fler exempelfrågor. Se systemtabellreferens för granskningsloggar.
Kända problem
Arbetsytans filer och mappar som skapats från gruppkluster leder till att den tilldelade objektägaren blir Unknown. Efterföljande åtgärder på dessa objekt, till exempel read, writeoch delete, misslyckas med behörighetsnekande fel.
Kända begränsningar
Dedikerad gruppåtkomst har följande begränsningar:
- Jobb som skapats med hjälp av API:et och SDK kan inte tilldelas gruppåtkomst. Det beror på att jobbets
run_asparameter endast stöder en enskild användare eller tjänstehuvudnamn. - Jobb som använder Git misslyckas eftersom den temporära katalog som jobbet använder för att checka ut Git-lagringsplatsen inte kan skrivas. Använd Git-mappar i stället.
- Linjalsystemtabeller registrerar inte
identity_metadata.run_as(auktoriseringsgruppen) elleridentity_metadata.run_by(den autentiserande användaren) för arbetsbelastningar som körs i ett gruppkluster. - Granskningsloggar som levereras till kundens lagring registrerar inte
identity_metadata.run_as(auktoriseringsgruppen) elleridentity_metadata.run_by(den autentiserande användaren) för arbetsbelastningar som körs i ett gruppkluster. Du måste använda tabellensystem.access.auditför att visa identitetsmetadata. - När katalogutforskaren är ansluten till ett gruppkluster filtreras den inte efter tillgångar som endast är tillgängliga för gruppen.
- Gruppchefer som inte är gruppmedlemmar kan inte skapa, redigera eller ta bort gruppkluster. Endast arbetsyteadministratörer och gruppmedlemmar kan göra det.
- Om en grupp har bytt namn måste du manuellt uppdatera alla beräkningsprinciper som refererar till gruppnamnet.
- Gruppkluster stöds inte för arbetsytor med ACL:er inaktiverade (isWorkspaceAclsEnabled == false) på grund av den inneboende bristen på säkerhets- och dataåtkomstkontroller när arbetsyte-ACL:er inaktiveras.
- Kommandot
%runoch andra åtgärder som körs i notebook-kontexten använder alltid användarens behörigheter i stället för gruppens behörigheter. Det beror på att dessa åtgärder hanteras av notebook-miljön, inte klustrets miljö. Alternativa kommandon somdbutils.notebook.run()körs i klustret och använder därför gruppens behörigheter. - Funktionen
is_member(<group>)returnerarfalsenär den anropas i ett gruppkluster eftersom gruppen inte är medlem i sig själv. Om du vill kontrollera medlemskapet i både gruppkluster och andra åtkomstlägen använder duis_member(<group>) OR current_user() == <group>. - Beräkningsloggar kan inte levereras till volymer.
- Att skapa och komma åt modellserveringsslutpunkter stöds inte.
- Det går inte att skapa och komma åt slutpunkter eller index för vektorsökning.
- Fil- och mappborttagning stöds inte i gruppkluster.