Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Schemautveckling syftar på ett systems förmåga att anpassa sig till ändringar i datastrukturen över tid. Dessa ändringar är vanliga när du arbetar med halvstrukturerade data, händelseströmmar eller källor från tredje part där nya fält läggs till, datatyper flyttas eller kapslade strukturer utvecklas.
Vanliga ändringar är:
- Nya kolumner: Ytterligare fält har inte definierats tidigare, ibland med ett anpassat återfyllnadsvärde.
-
Kolumnbyte: Ändra ett kolumnnamn, till exempel från
nametillfull_name. - Borttagna kolumner: Ta bort kolumner från tabellschemat.
-
Typbreddning: Ändra en kolumns typ till en bredare. Ett
INT-fält blirDOUBLEtill exempel. -
Andra typändringar: Ändra en kolumns typ. Ett
INT-fält blirSTRINGtill exempel.
Stöd för schemautveckling är avgörande för att skapa motståndskraftiga, långvariga pipelines som kan hantera föränderliga data utan frekventa manuella uppdateringar.
Components
Azure Databricks-schemautvecklingen omfattar fyra huvudkomponentkategorier, där varje hanteringsschema ändras oberoende av varandra:
- Anslutningsappar: Komponenter som matar in data från externa källor. Dessa inkluderar kopplingar för automatisk inläsning, Kafka, Kinesis och Lakeflow.
-
Formatparsers: Funktioner som avkodar råformat, inklusive
from_json,from_avro,from_xmlochfrom_protobuf. - Motorer: Bearbetningsmotorer som utför förfrågningar, inklusive Structured Streaming.
- Datauppsättningar: Strömmande tabeller, materialiserade vyer, Delta-tabeller och vyer som bevarar och hanterar data.
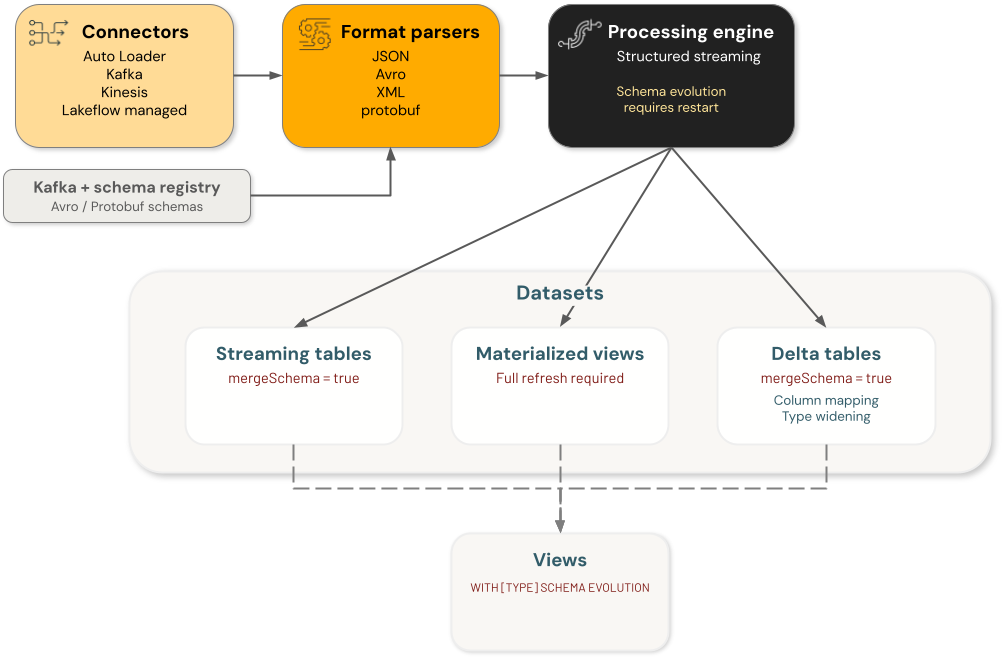
Varje komponent i datateknikarkitekturens schemautveckling är oberoende. Du ansvarar för att konfigurera schemautvecklingen i enskilda komponenter för att uppnå önskat beteende i databehandlingsflödet.
När du till exempel använder automatisk inläsning för att mata in data i en Delta-tabell finns det två bevarade scheman – ett hanteras av Auto Loader på dess schemaplats och det andra är schemat för deltatabellen för målet. I ett stabilt tillstånd är dessa två samma. När Auto Loader utvecklar sitt schema, baserat på inkommande data, måste deltatabellen också utveckla sitt schema, annars misslyckas frågan. I så fall kan du (a) uppdatera mål-deltatabellens schema genom att aktivera schemaevolution eller använda ett direkt DDL-kommando, eller (b) göra en fullständig omskrivning av mål-deltatabellen.
Stöd för schemaevolution via anslutning
I följande avsnitt beskrivs hur varje Azure Databricks-komponent hanterar olika typer av schemaändringar.
Automatisk Laddare
Automatisk inläsning stöder kolumnändringar, men inte typändringar. Konfigurera automatisk schemautveckling med cloudFiles.schemaEvolutionMode och rescuedDataColumn. Du kan ange schemaHints eller en oföränderlig schemamanuellt . När schemat utvecklas automatiskt misslyckas strömmen från början. Vid omstart används det utvecklade schemat. Se Hur fungerar schemautveckling för automatisk inläsning?.
-
Nya kolumner: Stöds, beroende på vilka kolumner som har valts
schemaEvolutionMode. Misslyckas med en manuell omstart som krävs för att lägga till nya kolumner i schemat. -
Kolumnbyte: Stöds, beroende på vilken kolumn som har valts
schemaEvolutionMode. Den omdöpta kolumnen behandlas som en ny kolumn som läggs till och den gamla kolumnen fylls i medNULLför nya rader. Misslyckas med en manuell omstart som krävs för att uppdatera schemat. -
Borttagna kolumner: Stöds. Behandlas som mjuka borttagningar, där nya rader för den borttagna kolumnen är inställda på
NULL. -
Typbreddning: Stöds inte. Typändringar registreras i
rescuedDataColumnomrescueDataColumnhar angetts ochschemaEvolutionModehar angetts tillrescue. Annars krävs en manuell schemaändring. -
Andra typändringar: Stöds inte. Typändringar registreras i
rescuedDataColumnomrescueDataColumnhar angetts ochschemaEvolutionModehar angetts tillrescue. Annars krävs en manuell schemaändring.
Deltaanslutning
Delta-anslutningsappen kan stödja schemautveckling. Om du läser från en Delta-tabell med kolumnmappning och schemaTrackingLocation aktiverat stöder det schemautveckling för kolumnbyte och borttagna kolumner. Du måste ange rätt Spark-konfiguration för var och en av dessa ändringar för att utveckla schemat utan att stoppa strömmen. Annars utvecklar strömmen sitt spårade schema när en ändring identifieras och sedan stoppas. Du måste sedan starta om strömningsfrågan manuellt för att återuppta bearbetningen.
-
Nya kolumner: Stöds. Med
mergeSchemaaktiverad läggs nya kolumner till automatiskt. Annars misslyckas frågan och du måste starta om dataströmmen för att lägga till de nya kolumnerna i schemat, men deltatabellen kräver ingen omskrivning. -
Kolumnbyte: Stöds. Med
mergeSchemaaktiverad hanteras namnbytet automatiskt. Annars kan du utveckla schemat i en direktuppspelningsfråga med Spark-konfigurationenspark.databricks.delta.streaming.allowSourceColumnRename. -
Borttagna kolumner: Stöds. Med
mergeSchemaaktiverad hanteras borttagna kolumner automatiskt. Annars kan du utveckla schemat i en direktuppspelningsfråga med Spark-konfigurationenspark.databricks.delta.streaming.allowSourceColumnDrop. -
Typbreddning: Stöds i Databricks Runtime 16.4 LTS och senare. Med
mergeSchemaaktiverad och typbreddning aktiverad i måltabellen hanteras typändringar automatiskt. Du kan aktivera typbreddning med tabellegenskapentype widening. - Andra typändringar: Stöds inte.
SaaS- och CDC-anslutningsappar
SaaS- och CDC-anslutningsapparna utvecklar schemat automatiskt när kolumnerna ändras. Detta hanteras via en automatisk omstart när en ändring identifieras. Typändringar kräver en fullständig uppdatering.
- Nya kolumner: Stöds. Frågan startas om automatiskt för att lösa schemamatchningsfel.
- Kolumnbyte: Stöds. Frågan startas om automatiskt för att lösa schemamatchningsfel. Den omdöpta kolumnen behandlas som en ny kolumn som läggs till.
-
Borttagna kolumner: Stöds. Borttagna kolumner behandlas som mjuka borttagningar, där nya rader för den borttagna kolumnen är inställda på
NULL. - Typbreddning: Stöds inte. För att uppdatera schemat krävs en fullständig uppdatering.
- Andra typändringar: Stöds inte. För att uppdatera schemat krävs en fullständig uppdatering.
Kopplingar för Kinesis, Kafka, Pub/Sub och Pulsar
Ingen intern schemautveckling stöds. Var och en av anslutningsfunktionerna returnerar en binär blob. Schemautvecklingen hanteras av formatparsern.
- Nya kolumner: Hanteras av formatparsern.
- Kolumnbyte: Hanteras av formatparsern.
- Borttagna kolumner: Hanteras av formatparsern.
- Typbreddning: Hanteras av formatparsern.
- Andra typändringar: Hanteras av formatparsern.
Stöd för schemaevolution av formatparser
from_json Parser
Parsern from_json stöder inte schemautveckling. Du måste uppdatera schemat manuellt. När du använder from_json i Lakeflow Spark Deklarativa pipelines kan automatisk schemautveckling aktiveras med schemaLocationKey och schemaEvolutionMode.
- Nya kolumner: När automatisk schemautveckling är aktiverad, fungerar det som Auto Loader.
- Namnbyte av kolumner: När automatisk schemautveckling är aktiverad fungerar det som Auto Loader.
- Borttagna kolumner: När automatisk schemautveckling är aktiverat beter den sig som Auto Loader.
- Typbreddning: När automatisk schemautveckling är aktiverat fungerar det som Auto Loader.
- Andra typändringar: När automatisk schemautveckling är aktiverat fungerar det som Auto Loader.
from_avro och from_protobuf parsers
Parsarna from_avro och from_protobuf beter sig på samma sätt. Schemat kan hämtas från Confluent Schema Registry, eller så kan användaren ange ett schema och måste uppdatera schemat manuellt. Det finns inget begrepp om schemautveckling inom from_avro funktionen eller from_protobuf . Det måste hanteras av körningsmotorn och schemaregistret.
- Nya kolumner: Stöds med Confluent Schema Registry. Annars måste användaren uppdatera schemat manuellt.
- Kolumnnamnändring: Stöds med Confluent Schema Registry. Annars måste användaren uppdatera schemat manuellt.
- Borttagna kolumner: Stöds med Confluent Schema Registry. Annars måste användaren uppdatera schemat manuellt.
- Typbreddning: Stöds med Confluent Schema Registry. Annars måste användaren uppdatera schemat manuellt.
- Andra typändringar: Stöds med Confluent Schema Registry. Annars måste användaren uppdatera schemat manuellt.
from_csv och from_xml parsers
Parsarna from_csv och from_xml stöder inte schemautveckling.
- Nya kolumner: Stöds inte
- Kolumnbyte: Stöds inte
- Borttagna kolumner: Stöds inte
- Typbreddning: Stöds inte
- Andra typändringar: Stöds inte
Stöd för schemaevolution av motorn
Strukturerad direktuppspelning
En strömmande frågas schema är låst under den pågående planeringsfasen, och alla mikropartier återanvänder den planen utan omplanering. Om källschemat ändras mitt i körningen misslyckas frågan och användaren måste starta om strömningsfrågan så att Spark kan planera om mot det nya schemat.
Datauppsättningen som strömmen skriver till måste också ha stöd för schemautveckling.
- Nya kolumner: Stöds. Frågan misslyckas och du måste starta om strömmen för att lösa schemats matchningsfel.
- Kolumnbyte: Stöds. Frågan misslyckas och du måste starta om strömmen för att lösa schemats matchningsfel.
- Borttagna kolumner: Stöds. Frågan misslyckas och du måste starta om strömmen för att lösa schemats matchningsfel.
- Typbreddning: Stöds. Frågan misslyckas och du måste starta om strömmen för att lösa schemats matchningsfel.
- Andra typändringar: Stöds. Frågan misslyckas och du måste starta om strömmen för att lösa schemats matchningsfel.
Schemautveckling efter datauppsättning
Strömmande tabeller
Direktuppspelningstabeller stöder som standard beteende för sammanslagningsschemautveckling . Uppdateringen av schemat kräver ingen manuell omstart, men godtyckliga schemaändringar kräver en fullständig uppdatering.
- Nya kolumner: Stöds. Frågan startas om automatiskt för att lösa schemats matchningsfel.
- Kolumnbyte: Stöds. Frågan startas om för att lösa schemats matchningsfel. Den omdöpta kolumnen behandlas som en ny kolumn som läggs till.
- Borttagna kolumner: Stöds. Borttagna kolumner behandlas som mjuka borttagningar, där nya rader för den borttagna kolumnen anges till NULL.
- Typbreddning: Stöds. Typbreddning måste aktiveras antingen på pipeline-nivå eller i tabellen direkt. Se typbreddning i Lakeflow Spark Deklarativa pipelines.
- Andra typändringar: Stöds inte. För att uppdatera schemat krävs en fullständig uppdatering.
Materialiserade vyer
En uppdatering av schemat eller den definierande frågan utlöser en fullständig omkompensering av den materialiserade vyn.
- Nya kolumner: Fullständig omberäkning aktiveras.
- Kolumnnamnsändring: Full omberegning har utlöst.
- Borttagna kolumner: Fullständig omräkning utlöst.
- Typbreddning: Fullständig beräkning startad.
- Andra typändringar: Fullständig omberäkning har utlösts.
Deltatabeller
Deltatabeller stöder en mängd olika konfigurationer för att uppdatera tabellschemat, inklusive att byta namn på, släppa och bredda typen av kolumner utan att skriva om tabelldata. Konfigurationer som stöds är sammanslagningsschemautveckling, kolumnmappning, typbreddning och overwriteSchema.
- Nya kolumner: Stöds. Utvecklas automatiskt när sammanslagningsschemats utveckling är aktiverad, utan att en Delta-tabell skrivs om. Om sammanslagningsschemautvecklingen inte är aktiverad misslyckas uppdateringarna.
-
Kolumnbyte: Stöds. Kan byta namn via manuella
ALTER TABLE DDLkommandon med kolumnmappning aktiverat. Kräver ingen deltatabellomskrivning. -
Borttagna kolumner: Stöds. Kan släppa kolumner via manuella
ALTER TABLE DDLkommandon med kolumnmappning aktiverat. Kräver ingen deltatabellomskrivning. -
Typbreddning: Stöds. Tillämpar automatiskt typändring när typbreddning och sammanslagningsschemautveckling aktiveras. Du kan bredda kolumner via manuella
ALTER TABLE DDLkommandon när typbreddning är aktiverat. Utan att någon av dem har konfigurerats misslyckas åtgärderna. Se Bredda typer med automatisk schemautveckling. -
Andra typändringar: Stöds, men kräver en fullständig omskrivning av deltatabellen. Du måste aktivera
overwriteSchema, vilket möjliggör en fullständig omskrivning av deltatabellen. Annars misslyckas åtgärderna.
Views
Om vyn har en column_list som inte matchar det nya schemat, eller om den har en fråga som inte kan parsas, blir vyn ogiltig. Om den inte gör det kan du aktivera schemautveckling för typändringar med SCHEMA TYPE EVOLUTION och för typändringar, samt nya, omdöpta och borttagna kolumner med SCHEMA EVOLUTION (vilket är en superuppsättning av typutveckling).
-
Nya kolumner: Stöds. Med
SCHEMA EVOLUTIONläget utvecklas vyn automatiskt utan manuella åtgärder om det inte finns någon explicitcolumn_list. Annars kan vyn bli ogiltig och användaren kan inte göra en fråga mot den. -
Namnbyte för kolumner: Stöds. Med
SCHEMA EVOLUTIONläget utvecklas vyn automatiskt utan manuella åtgärder om det inte finns någon explicitcolumn_list. Annars kan vyn bli ogiltig. -
Borttagna kolumner: Stöds. Med
SCHEMA EVOLUTIONläget utvecklas vyn automatiskt utan manuella åtgärder om det inte finns någon explicitcolumn_list. Annars kan vyn bli ogiltig. -
Typbreddning: Stöds. Med
SCHEMA TYPE EVOLUTIONläget utvecklas vyn automatiskt för alla typändringar. MedSCHEMA EVOLUTIONläget utvecklas vyn automatiskt utan manuella åtgärder om det inte finns någon explicitcolumn_list. Annars kan vyn bli ogiltig. -
Andra typändringar: Stöds. Med
SCHEMA TYPE EVOLUTIONläget utvecklas vyn automatiskt för alla typändringar. MedSCHEMA EVOLUTIONläget utvecklas vyn automatiskt utan manuella åtgärder om det inte finns någon explicitcolumn_list. Annars kan vyn bli ogiltig.
Example
I följande exempel visas hur du matar in ett Kafka-ämne med Avro-kodade nyttolaster registrerade i Confluent Schema Registry och skriver dem till en hanterad Delta-tabell med schemautveckling aktiverat.
Viktiga punkter illustrerade:
- Integrera med Kafka Connector.
- Avkoda Avro-records med from_avro med ett Kafka-schemaregister.
- Hantera schemautveckling genom att ange
avroSchemaEvolutionMode. - Skriv till en Delta-tabell med
mergeSchemaaktiverad för att tillåta additiva ändringar.
Koden förutsätter att du har ett Kafka-ämne som använder Confluent-schemaregistret och matar ut Avro-kodade data.
# ----- CONFIG: fill these in -----
# Catalog and schema:
CATALOG = "<catalog_name>"
SCHEMA = "<schema_name>"
# Schema Registry:
# (This is where the producer evolves the schema)
SCHEMA_REG = "<schema registry endpoint>"
SR_USER = "<api key>"
SR_PASS = "<api secret>"
# Confluent Cloud: SASL_SSL broker:
BOOTSTRAP = "<server:ip>"
# Kafka topic:
TOPIC = "<topic>"
# ----- end: config -----
BRONZE_TABLE = f"{CATALOG}.{SCHEMA}.bronze_users"
CHECKPOINT = f"/Volumes/{CATALOG}/{SCHEMA}/checkpoints/bronze_users"
# Kafka auth (example for Confluent Cloud SASL/PLAIN over SSL)
KAFKA_OPTS = {
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "PLAIN",
"kafka.sasl.jaas.config": f"kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{SR_USER}' password='{SR_PASS}';"
}
# ----- Evolution knobs -----
# spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled", value = True)
from pyspark.sql.functions import col
from pyspark.sql.avro.functions import from_avro
# Build reader
reader = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", BOOTSTRAP)
.option("subscribe", TOPIC)
.option("startingOffsets", "earliest")
)
# Attach Kafka auth options
for k, v in KAFKA_OPTS.items():
reader = reader.option(k, v)
# --- No native schema evolution supported. Returns a binary blob. ---
raw_df = reader.load()
# Decode Avro with Schema Registry
# --- The format parser handles updating the schema using the schema registry ---
decoded = from_avro(
data=col("value"),
jsonFormatSchema=None, # using SR
subject=f"{TOPIC}-value",
schemaRegistryAddress=SCHEMA_REG,
options={
"confluent.schema.registry.basic.auth.credentials.source": "USER_INFO",
"confluent.schema.registry.basic.auth.user.info": f"{SR_USER}:{SR_PASS}",
# Behavior on schema changes:
"avroSchemaEvolutionMode": "restart", # fail-fast so you can restart and adopt new fields
"mode": "FAILFAST"
}
).alias("payload")
bronze_df = raw_df.select(decoded, "timestamp").select("payload.*", "timestamp")
# Write to a managed Delta table as a STREAM
# --- Need to enable schema evolution separately for streaming to a Delta separately with mergeSchema --
(bronze_df.writeStream
.format("delta")
.option("checkpointLocation", CHECKPOINT)
.option("ignoreChanges", "true")
.outputMode("append")
.option("mergeSchema", "true") # only supports adding new columns. Renaming, dropping, and type changes need to be handled separately.
.trigger(availableNow=True) # Use availableNow trigger for Databricks SQL/Unity Catalog
.toTable(BRONZE_TABLE)
)