Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Anmärkning
Den här artikeln gäller för Databricks Connect för Databricks Runtime 13.3 LTS och senare.
Med Databricks Connect kan du ansluta populära IDE:er såsom PyCharm, notebook-servrar och andra anpassade applikationer till Azure Databricks-beräkningar. Se Databricks Connect.
Den här artikeln visar hur du snabbt kommer igång med Databricks Connect för Python med hjälp av PyCharm. Du skapar ett projekt i PyCharm, installerar Databricks Connect för Databricks Runtime 13.3 LTS och senare och kör enkel kod på klassisk beräkning i Databricks-arbetsytan från PyCharm.
Kravspecifikation
För att slutföra den här självstudien måste du uppfylla följande krav:
- Din arbetsyta, lokala miljö och beräkning uppfyller kraven för Databricks Connect för Python. Se Användningskrav för Databricks Connect.
- Du har Installerat PyCharm . Den här självstudien har testats med PyCharm Community Edition 2023.3.5. Om du använder en annan version eller utgåva av PyCharm kan följande instruktioner variera.
- Om du använder klassisk beräkning behöver du klustrets ID. Om du vill hämta ditt kluster-ID klickar du på Beräkning i sidofältet i arbetsytan och klickar sedan på klustrets namn. Kopiera teckensträngen mellan
clustersochconfigurationi URL:en i webbläsarens adressfält.
Steg 1: Konfigurera Azure Databricks autentisering
I den här självstudien används Azure Databricks OAuth-användare-till-maskin (U2M) autentisering och en Azure Databricks-konfigurationsprofil för att autentisera mot din Azure Databricks-arbetsyta. Information om hur du använder en annan autentiseringstyp finns i Konfigurera anslutningsegenskaper.
För att konfigurera OAuth U2M-autentisering krävs Databricks CLI. Information om hur du installerar Databricks CLI finns i Installera eller uppdatera Databricks CLI.
Initiera OAuth U2M-autentisering på följande sätt:
Använd Databricks CLI för att initiera OAuth-tokenhantering lokalt genom att köra följande kommando för varje målarbetsyta.
I följande kommando ersätter du
<workspace-url>med url:en Azure Databricks per-workspace, till exempelhttps://adb-1234567890123456.7.azuredatabricks.net.databricks auth login --configure-cluster --host <workspace-url>Tips/Råd
Information om hur du använder serverlös beräkning med Databricks Connect finns i Konfigurera en anslutning till serverlös beräkning.
Databricks CLI uppmanar dig att spara den information som du angav som en Azure Databricks konfigurationsprofil. Tryck
Enterför att acceptera det föreslagna profilnamnet eller ange namnet på en ny eller befintlig profil. Alla befintliga profiler med samma namn skrivs över med den information som du angav. Du kan använda profiler för att snabbt växla autentiseringskontext över flera arbetsytor.Om du vill hämta en lista över befintliga profiler i en separat terminal eller kommandotolk använder du Databricks CLI för att köra kommandot
databricks auth profiles. Om du vill visa en specifik profils befintliga inställningar kör du kommandotdatabricks auth env --profile <profile-name>.I webbläsaren slutför du anvisningarna på skärmen för att logga in på din Azure Databricks arbetsyta.
I listan över tillgängliga kluster som visas i terminalen eller kommandotolken använder du upppilen och nedåtpilen för att välja målet Azure Databricks klustret på arbetsytan och tryck sedan på
Enter. Du kan också ange valfri del av klustrets visningsnamn för att filtrera listan över tillgängliga kluster.Om du vill visa en profils aktuella OAuth-tokenvärde och tokens kommande förfallotidsstämpel kör du något av följande kommandon:
databricks auth token --host <workspace-url>databricks auth token -p <profile-name>databricks auth token --host <workspace-url> -p <profile-name>
Om du har flera profiler med samma
--hostvärde kan du behöva ange--hostalternativen och-ptillsammans för att hjälpa Databricks CLI att hitta rätt matchande OAuth-tokeninformation.
Steg 2: Skapa projektet
- Starta PyCharm.
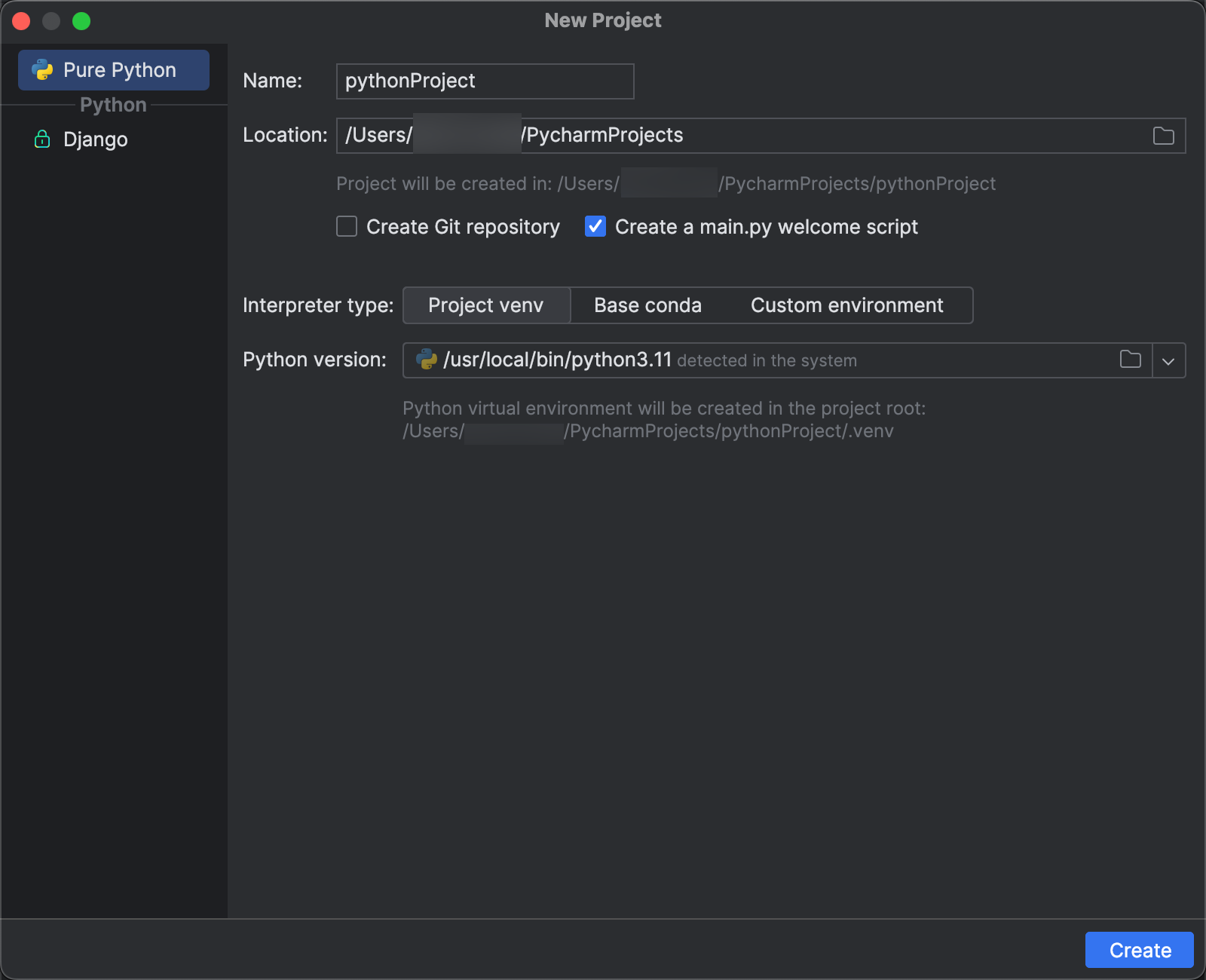
- På huvudmenyn klickar du på File > New Project.
- I dialogrutan Ny Project klickar du på Pure Python.
- För Location klickar du på mappikonen och slutför anvisningarna på skärmen för att ange sökvägen till det nya Python projektet.
- Låt Skapa ett main.py välkomstskript vara valt.
- För Interpreter type klickar du på Project venv.
- Expandera Python version och använd mappikonen eller listrutan för att ange sökvägen till den Python tolken från ovanstående krav.
- Klicka på Skapa.
Steg 3: Lägg till Databricks Connect-paketet
- På PyCharms huvudmeny klickar du på View > Tool Windows > Python Packages.
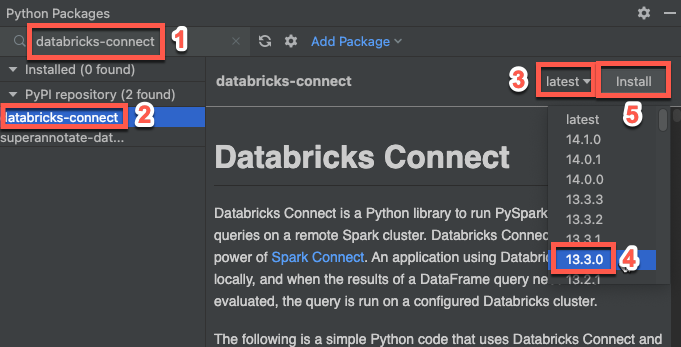
- Skriv
databricks-connecti sökrutan. - I listan över PyPI-lagringsplatser klickar du på databricks-connect.
- I resultatfönstrets senaste listruta väljer du den version som matchar klustrets Databricks Runtime-version. Om klustret till exempel har Databricks Runtime 14.3 installerat väljer du 14.3.1.
- Klicka på Installera paket.
- När paketet har installerats kan du stänga fönstret Python Packages.
Steg 4: Lägg till kod
I verktygsfönstret Project högerklickar du på rotmappen för project och klickar på Ny > Python fil.
Ange
main.pyoch dubbelklicka på filen Python.Ange följande kod i filen och spara sedan filen, beroende på namnet på konfigurationsprofilen.
Om konfigurationsprofilen från steg 1 heter
DEFAULTanger du följande kod i filen och sparar sedan filen:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)Om konfigurationsprofilen från steg 1 inte heter
DEFAULTanger du följande kod i filen i stället. Ersätt platshållaren<profile-name>med namnet på konfigurationsprofilen från steg 1 och spara sedan filen:from databricks.connect import DatabricksSession spark = DatabricksSession.builder.profile("<profile-name>").getOrCreate() df = spark.read.table("samples.nyctaxi.trips") df.show(5)
Steg 5: Kör koden
- Starta målklustret på din fjärranslutna Azure Databricks arbetsyta.
- När klustret har startat, klicka på Kör 'main'> på huvudmenyn.
- I verktygsfönstret Run (View > Tool Windows > Run), i fliken Run under huvudpanelen main visas de första 5 raderna i
samples.nyctaxi.trips.
Steg 6: Felsöka koden
- Med klustret fortfarande igång, klickar du i föregående kod på marginalen bredvid
df.show(5)för att ställa in en brytpunkt. - På huvudmenyn klickar du på >.
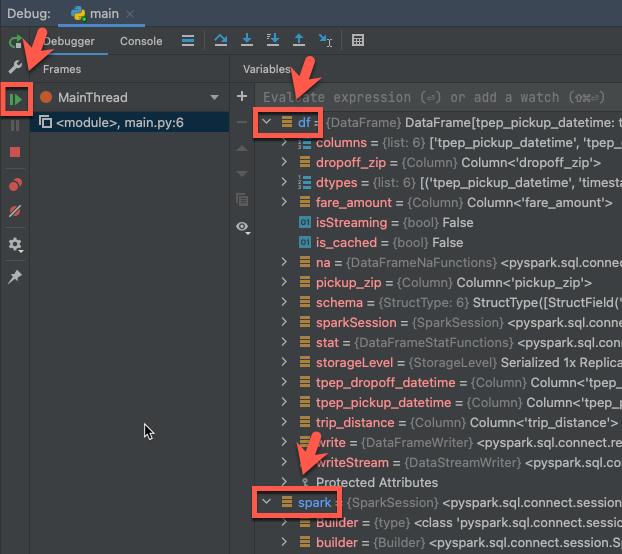
- I verktygsfönstret Debug (Visa > Verktygsfönster > Debug), i fliken DebuggerVariables, expandera df och spark variabelnodernas för att bläddra genom information om kodens
dfochsparkvariabler. - I sidofältet för felsökningsverktyget klickar du på den gröna pilen (Återuppta program).
- På fliken Felsökare i fönstret Konsol visas de första 5 raderna
samples.nyctaxi.trips.