Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
Den här funktionen finns i Beta.
Den här artikeln beskriver hur du skapar en generativ AI-agent för informationsextrahering med hjälp av Agent Bricks: Information Extraction.
Agent Bricks tillhandahåller en enkel metod utan kod för att skapa och optimera domänspecifika AI-agentsystem av hög kvalitet för vanliga AI-användningsfall.
Vad är Agent Bricks: Information Extrahering?
Agent Bricks stöder extrahering av information och förenklar processen med att omvandla en stor mängd omärkta textdokument till en strukturerad tabell med extraherad information för varje dokument.
Exempel på extrahering av information är:
- Extrahera priser och leasinginformation från kontrakt.
- Organisera data från kundanteckningar.
- Få viktig information från nyhetsartiklar.
Agentstenar: Informationsextrahering utnyttjar automatiserade utvärderingsfunktioner, inklusive MLflow och agentutvärdering, för att möjliggöra snabb utvärdering av kostnadskvalitetsavvägningen för din specifika extraheringsuppgift. Med den här utvärderingen kan du fatta välgrundade beslut om balansen mellan noggrannhet och resursinvesteringar.
Kravspecifikation
- En arbetsyta som innehåller följande:
- Mosaic AI Agent Bricks Preview (Beta) aktiverad. Se Hantera förhandsversioner av Azure Databricks.
- Serverlös beräkning aktiverad. Se Aktivera serverlös beräkning.
- Unity Catalog aktiverat. Se Aktivera en arbetsyta för Unity Catalog.
- En arbetsyta i någon av de regioner som stöds:
eastus,eastus2,westus,centralusellernorthcentralus. - Åtkomst till grundmodeller i Unity Catalog via
system.aischemat. - Åtkomst till en serverlös budgetprincip med en icke-nollbudget.
- Möjlighet att använda SQL-funktionen
ai_query. - Filer som du vill extrahera data från. Filerna måste finnas i en Unity Catalog-volym eller -tabell.
- Om du vill använda PDF-filer konverterar du dem först till en Unity Catalog-tabell. Se Använda PDF-filer i Agent Bricks.
- För att skapa din agent behöver du minst 1 omärkt dokument i Unity Catalog-volymen eller en rad i tabellen.
- Om du vill optimera din agent ((valfritt) steg 4: Granska och distribuera en optimerad agent måste du ha minst 75 omärkta dokument i Unity Catalog-volymen eller minst 75 rader i tabellen.
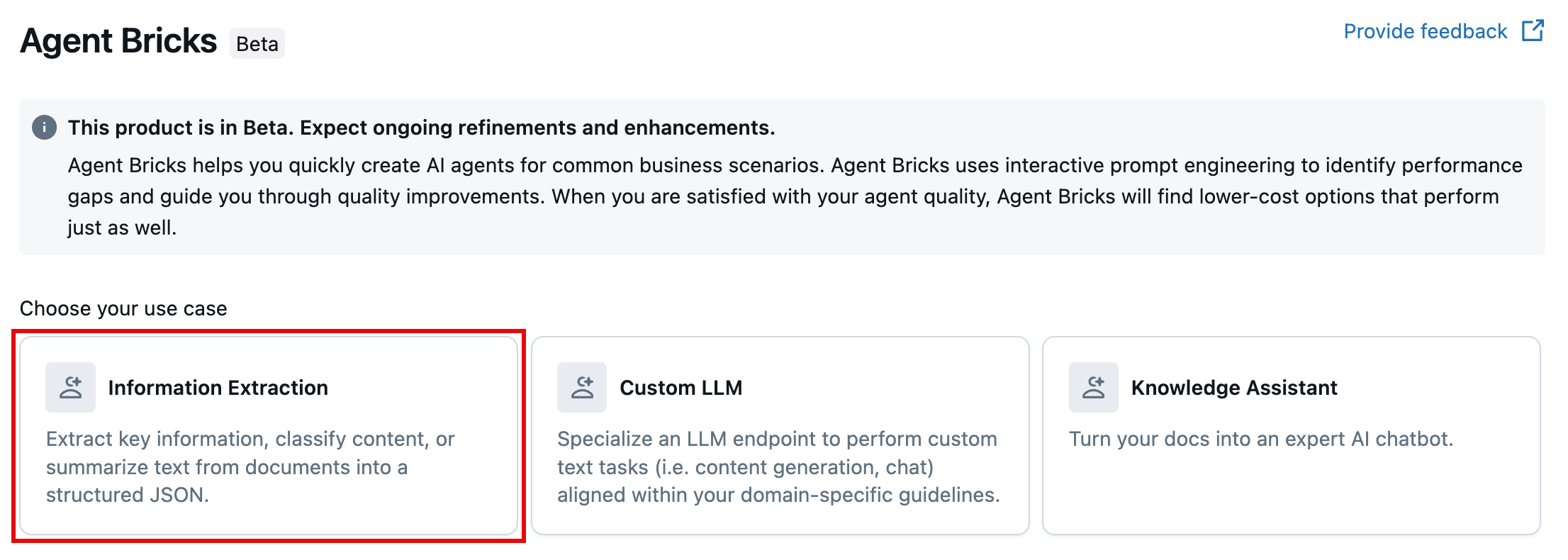
Skapa en informationsextraheringsagent
Gå till ![]() Agenter i det vänstra navigeringsfönstret på arbetsytan och klickar på Extrahering av information.
Agenter i det vänstra navigeringsfönstret på arbetsytan och klickar på Extrahering av information.
Steg 1: Lägg till indata och utdataexempel
På fliken Konfigurera klickar du på Visa ett exempel > för att expandera ett exempel på indata och modellsvar för en informationsextraheringsagent.
I fönstret nedan konfigurerar du din agent:
I fältet Källdokument väljer du den mapp eller tabell som du vill använda från Unity Catalog-volymen. Om du har valt en tabell väljer du den kolumn som innehåller textdata från listrutan.
Mappen måste innehålla dokument i dokumentformat som stöds och tabellkolumnen måste innehålla data i ett dataformat som stöds. Den här datauppsättningen används för att skapa din agent.
Om du vill använda PDF-filer konverterar du dem först till en Unity Catalog-tabell. Se Använda PDF-filer i Agent Bricks.
Följande är en exempelvolym:
/Volumes/main/info-extraction/bbc_articles/I fältet Exempelutdata anger du ett exempelsvar:
{ "title": "Economy Slides to Recession", "category": "Politics", "paragraphs": [ { "summary": "GDP fell by 0.1% in the last three months of 2004.", "word_count": 38 }, { "summary": "Consumer spending had been depressed by one-off factors such as the unseasonably mild winter.", "word_count": 42 } ], "tags": ["Recession", "Economy", "Consumer Spending"], "estimate_time_to_read_min": 1, "published_date": "2005-01-15", "needs_review": false }Ange ett namn för din agent. Du kan lämna standardnamnet om du inte vill ändra det.
Välj Skapa agent.
Dokumentformat som stöds
I följande tabell visas de dokumentfiltyper som stöds för källdokumenten om du anger en Unity Catalog-volym.
| Kodfiler | Dokumentfiler | Loggfiler |
|---|---|---|
|
|
|
dataformat som stöds
Agentstenar: Extrahering av information stöder följande datatyper och scheman för dina källdokument om du tillhandahåller en Unity Catalog-tabell. Agent Bricks kan också extrahera dessa datatyper från varje dokument.
strintfloatboolean- Anpassade kapslade fält
- Matriser med ovanstående datatyper
Steg 2: Skapa och förbättra din agent
På fliken Utforma i panelen Agentkonfiguration förbättrar du schemadefinitionen för bättre resultat.
(Valfritt) Lägg till globala instruktioner för din agent, till exempel en fråga som kan gälla för alla fält.
Justera beskrivningarna av de schemafält som du vill att agenten ska använda för utdatasvar. Dessa beskrivningar är vad agenten förlitar sig på för att förstå vad du vill extrahera.

Klicka på Uppdatera agent.
Till vänster på fliken Skapa granskar du rekommendationer och exempelutdata.
Granska modellutdataexempel baserat på specifikationerna för varje fält.
Granska Databricks-rekommendationerna för att optimera agentprestanda.
Använd rekommendationer och justera dina beskrivningar och instruktioner i fönstret Agentkonfiguration efter behov.
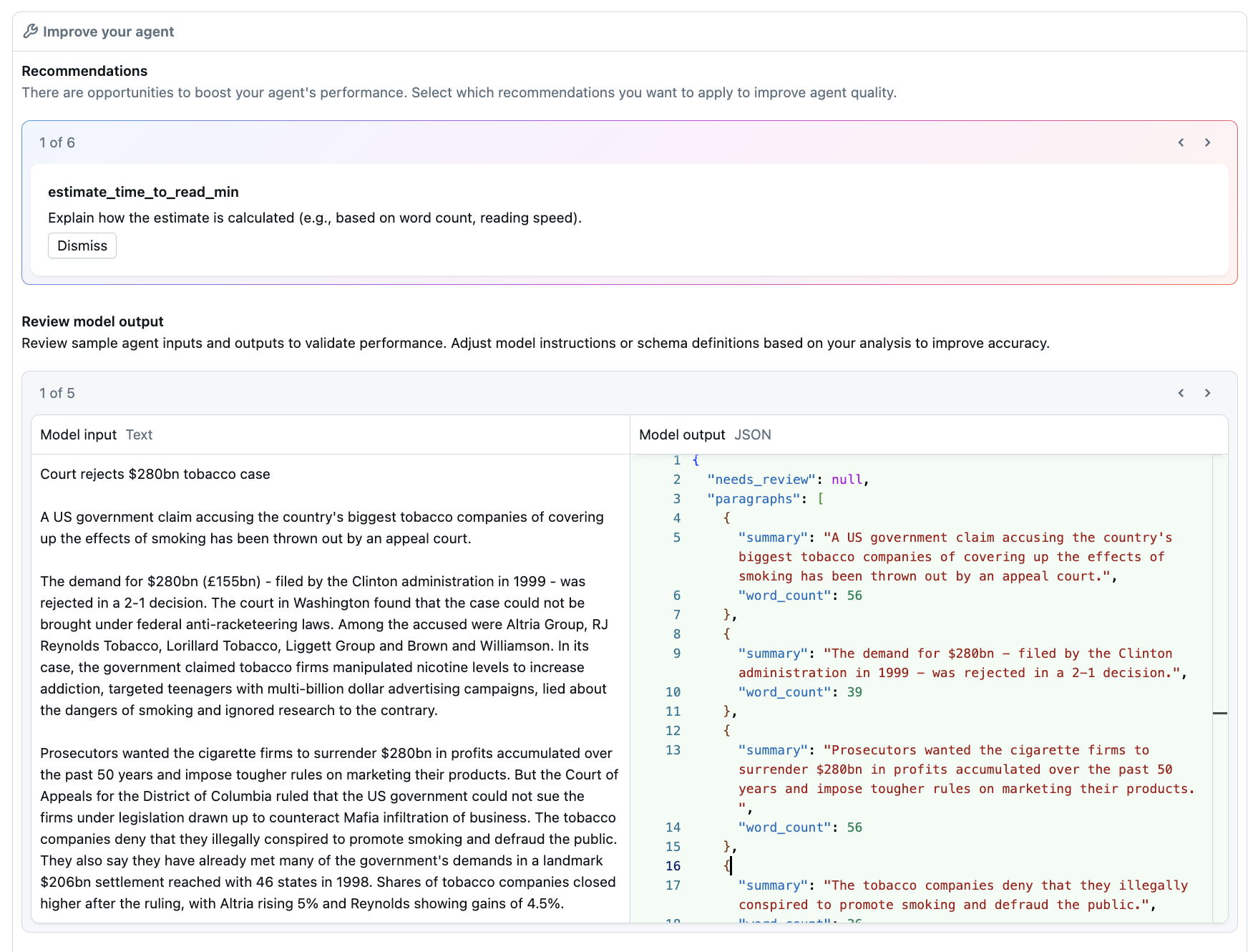
När du har tillämpat ändringar och rekommendationer väljer du Uppdatera agenten för att spara ändringarna i din agent. Förbättra agentens fönsteruppdateringar för att visa nya exempelmodellutdata. Rekommendationerna i det här fönstret uppdateras inte.
Nu har du en agent för informationsextrahering.
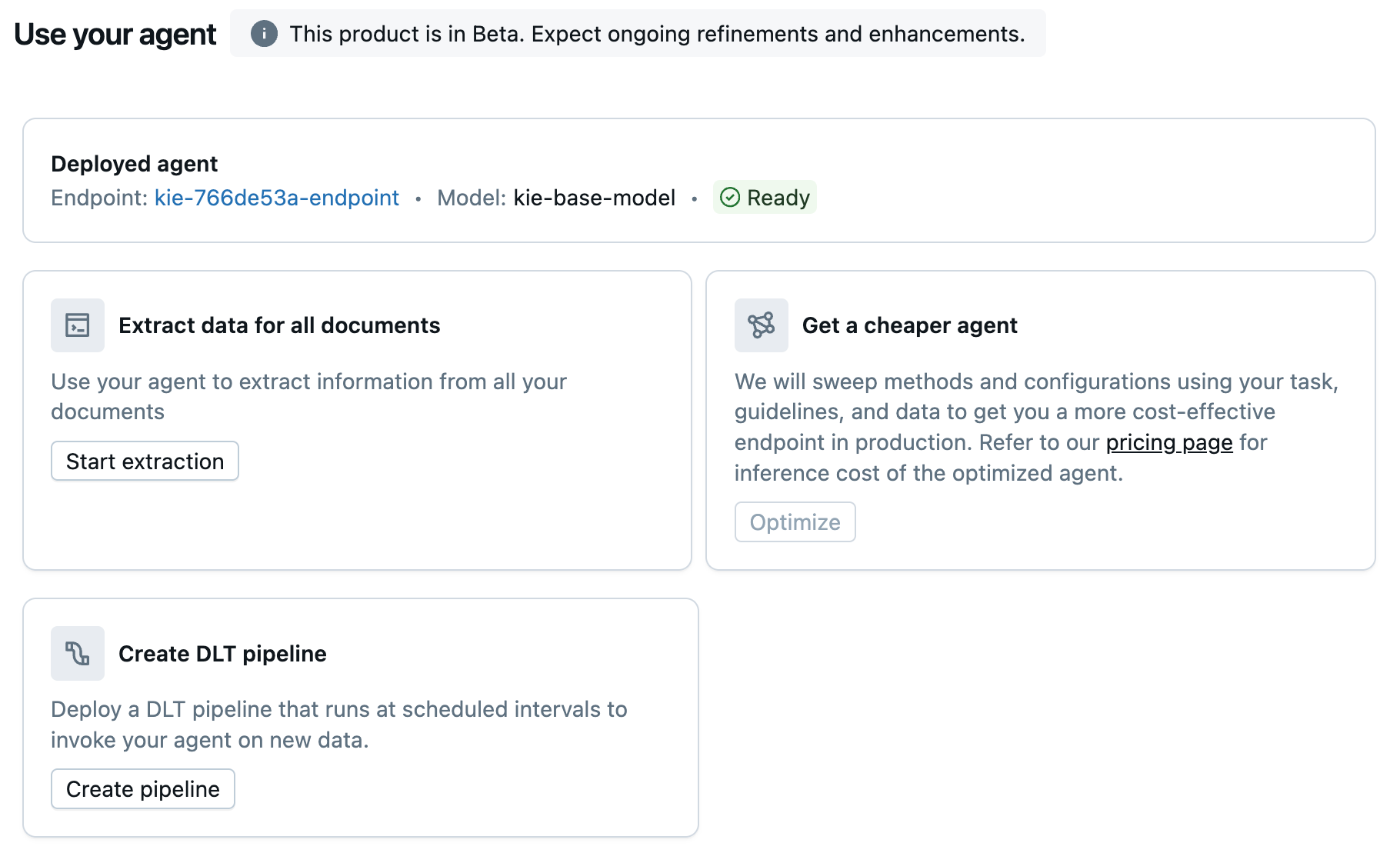
Steg 3: Använd din agent
Du kan använda din agent i arbetsflöden i Databricks.
På fliken Använd,
Välj Starta extrahering för att öppna SQL-redigeraren och använd
ai_queryför att skicka begäranden till din nya informationsextraheringsagent.(Valfritt) Välj Optimera om du vill optimera din agent för kostnad.
- Optimering kräver minst 75 filer.
- Optimering kan ta ungefär en timme.
- Ändringar i din aktiva agent blockeras när optimering pågår.
När optimeringen är klar dirigeras du till fliken Granska för att visa en jämförelse av din aktiva agent och en agent som är optimerad för kostnad. Se (valfritt) Steg 4: Granska och distribuera en optimerad agent.
- (Valfritt) Välj Skapa pipeline för att distribuera en pipeline som körs med schemalagda intervall för att använda din agent på nya data. För mer information om Lakeflow Declarative Pipelines och pipelines.
(valfritt) Steg 4: Granska och distribuera en optimerad agent
När du väljer Optimera på fliken Använd jämför Databricks flera olika optimeringsstrategier för att skapa och rekommendera en optimerad agent. Dessa strategier inkluderar finjustering av grundmodell som använder Databricks Geos.
På fliken Granska,
I Utvärderingsresultatkan du visuellt jämföra den optimerade agenten och din aktiva agent. För att utföra utvärderingen väljer Databricks ett mått baserat på varje fälts datatyp och använder en utvärderingsdatauppsättning för att jämföra din aktiva agent och agenten som är optimerad för kostnad. Den här utvärderingsuppsättningen baseras på en delmängd av de data som du använde för att skapa din ursprungliga agent.
- Mått loggas till din MLflow-körning per fält (aggregerat till huvudnivåfältet).
- Välj kolumnerna
overall_scoreochis_schema_matchi listrutan Kolumner.
När du har granskat dessa resultat klickar du på Distribuera om du vill distribuera den optimerade agenten i stället för din aktiva agent.
Använda PDF-filer i Agent Bricks
PDF-filer stöds ännu inte internt i Agent Bricks: Information Extraction och Custom LLM. Du kan dock använda Agent Bricks gränssnittsarbetsflöde för att konvertera en mapp med PDF-filer till markdown och sedan använda den resulterande Unity Catalog-tabellen som indata när du skapar din agent. Det här arbetsflödet använder ai_parse_document för konverteringen. Följ dessa steg:
Klicka på Agenter i det vänstra navigeringsfönstret för att öppna Agentstenar i Databricks.
I det övre högra hörnet klickar du på
 Använd PDF-filer i Agent Bricks.
Använd PDF-filer i Agent Bricks.I panelen som öppnas anger du följande fält för att skapa ett nytt arbetsflöde för att konvertera dina PDF-filer:
- Välj mapp med PDF-filer: Välj mappen Unity Catalog som innehåller de PDF-filer som du vill använda.
- Välj måltabell: Välj målschemat för den konverterade markdown-tabellen och om du vill kan du justera tabellnamnet i fältet nedan.
- Välj aktivt SQL-lager: Välj SQL-lagret för att köra arbetsflödet.
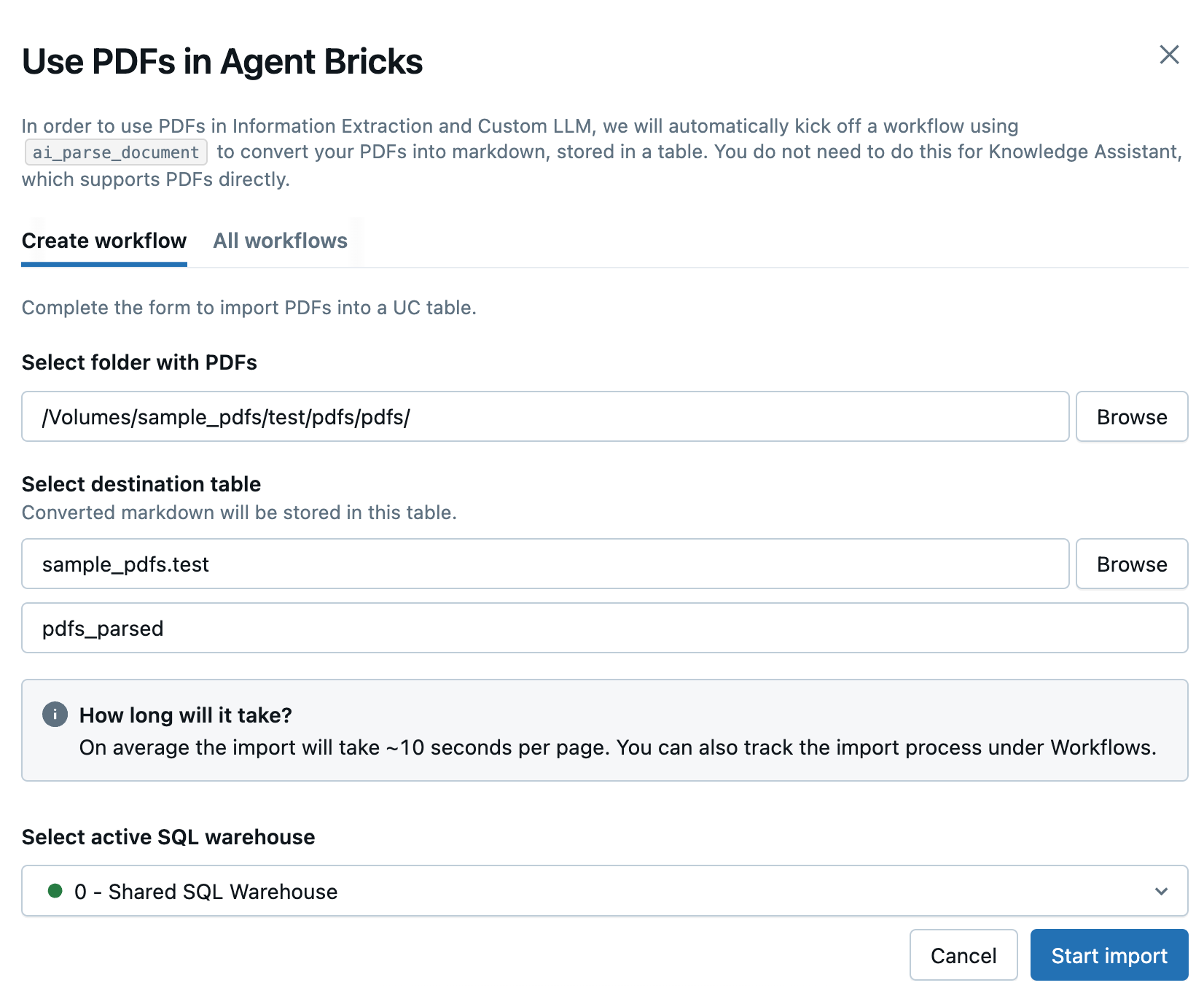
Klicka på Starta import.
Du omdirigeras till fliken Alla arbetsflöden , som visar alla dina PDF-arbetsflöden. Använd den här fliken om du vill övervaka status för dina jobb.
Granska status för arbetsflödet för att använda PDF-filer i Agent Bricks.
Om arbetsflödet misslyckas klickar du på jobbnamnet för att öppna det och visa felmeddelanden som hjälper dig att felsöka.
När arbetsflödet har slutförts klickar du på jobbnamnet för att öppna tabellen i Katalogutforskaren för att utforska och förstå kolumnerna.
Använd tabellen Unity Catalog som indata i Agent Bricks när du konfigurerar din agent.
Begränsningar
- Databricks rekommenderar minst 1 000 dokument för att optimera din agent. När du lägger till fler dokument ökar kunskapsbasen som agenten kan lära sig av, vilket förbättrar agentkvaliteten och dess extraheringsnoggrannhet.
- Om källdokumenten innehåller en fil som är större än 3 MB misslyckas agentskapandet.
- Dokument som är större än 64 kB kan hoppas över under agentbygget.
- Indata- och utdatagränsen är 128 000 token.
- Arbetsytor som använder Azure Private Link, inklusive lagring bakom Azure Private Link, stöds inte.
- Union-schematyper stöds inte.