Not
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln beskriver hur du mäter prestanda för ett RAG-program för kvaliteten på hämtning, svar och systemprestanda.
Hämtning, svar och prestanda
Med en utvärderingsuppsättning kan du mäta prestandan för ditt RAG-program över ett antal olika dimensioner, inklusive:
- Hämtningskvalitet: Hämtningsmått utvärderar hur rag-programmet hämtar relevanta stöddata. Precision och återkallande är två viktiga hämtningsmått.
- Svarskvalitet: Mått för svarskvalitet utvärderar hur väl RAG-programmet svarar på en användares begäran. Mätningsmetoder kan till exempel mäta om det resulterande svaret är korrekt enligt grundsanningen, hur välgrundat svaret var utifrån den hämtade kontexten (t.ex. om LLM hallucinerade?) eller hur säkert svaret var (med andra ord, utan toxicitet).
- Systemprestanda (kostnad och svarstid): Måtten samlar in den totala kostnaden och prestandan för RAG-program. Övergripande svarstid och tokenförbrukning är exempel på kedjeprestandamått.
Det är mycket viktigt att samla in både svars- och hämtningsmått. Ett RAG-program kan svara dåligt trots att rätt kontext hämtas. Det kan också ge bra svar baserat på felaktiga hämtningar. Endast genom att mäta båda komponenterna kan vi korrekt diagnostisera och åtgärda problem i programmet.
Metoder för att mäta prestanda
Det finns två viktiga metoder för att mäta prestanda i dessa mått:
- Deterministisk mätning: Kostnads- och svarstidsmått kan beräknas deterministiskt baserat på programmets utdata. Om utvärderingsuppsättningen innehåller en lista över dokument som innehåller svaret på en fråga kan en delmängd av hämtningsmåtten också beräknas deterministiskt.
- LLM-bedömningsbaserad mätning: I den här metoden fungerar en separat LLM som domare för att utvärdera kvaliteten på RAG-programmets hämtning och svar. Vissa LLM-domare, såsom korrekthet av svar, jämför människomärkta faktasanningar med appens resultat. Andra bedömningsmodeller för LLM, såsom grundadhet, kräver inte mänskligt märkt sanningsdata för att bedöma resultaten av deras appar.
Viktigt!
För att en LLM-domare ska vara effektiv måste den optimeras för att förstå den specifika användningen. Att göra det kräver noggrann uppmärksamhet för att förstå var domaren fungerar och inte fungerar bra, och sedan justera domaren för att förbättra den i fall där den misslyckas.
Mosaic AI Agent Evaluation tillhandahåller en out-of-the-box-implementering med värdbaserade LLM-domarmodeller för varje mått som beskrivs på den här sidan. Dokumentationen för agentutvärderingen beskriver information om hur dessa mått och domare implementeras och ger funktioner för att finjustera domarna med dina data för att öka deras noggrannhet
Översikt över mått
Nedan visas en sammanfattning av de mått som Databricks rekommenderar för att mäta kvalitet, kostnad och svarstid för ditt RAG-program. Dessa mått implementeras i Mosaic AI Agent Evaluation.
| Mått | Metriknamn | Fråga | Mätt enligt | Behöver du grundsanning? |
|---|---|---|---|---|
| Hämtning | chunk_relevance/precision | Vilka % av de hämtade segmenten är relevanta för begäran? | LLM-domare | Nej |
| Hämtning | dokumentåterkallelse | Vilka % av faktadokumenten representeras i de hämtade segmenten? | Deterministisk | Ja |
| Hämtning | kontexttillräcklighet | Är de hämtade segmenten tillräckligt för att generera det förväntade svaret? | LLM-domare | Ja |
| Svar | korrekthet | Sammantaget, genererade agenten ett korrekt svar? | LLM-domare | Ja |
| Svar | relevans_till_förfrågan | Är svaret relevant för begäran? | LLM-domare | Nej |
| Svar | grundstötning | Är svaret en hallucination eller grundad i sitt sammanhang? | LLM-domare | Nej |
| Svar | säkerhet | Finns det skadligt innehåll i svaret? | LLM-domare | Nej |
| Kostnad | total_antal_token, totalt_antal_inmatningstoken, totalt_antal_utmatningstoken | Vad är det totala antalet token för LLM-generationer? | Deterministisk | Nej |
| Svarstid | latens_sekunder | Vad är svarstiden för att köra appen? | Deterministisk | Nej |
Så här fungerar sökmått
Hämtningsmått hjälper dig att förstå om din retriever levererar relevanta resultat. Hämtningsmått baseras på precision och träffsäkerhet.
| Måttnamn | Besvarad fråga | Detaljer |
|---|---|---|
| Noggrannhet | Vilka % av de hämtade segmenten är relevanta för begäran? | Precision är andelen hämtade dokument som faktiskt är relevanta för användarens begäran. En LLM-domare kan användas för att bedöma relevansen för varje hämtat segment för användarens begäran. |
| Kom ihåg | Vilka % av faktadokumenten representeras i de hämtade segmenten? | Återkallningsgrad är andelen av de sanna dokumenten som representeras i de hämtade segmenten. Det här är ett mått på resultatets fullständighet. |
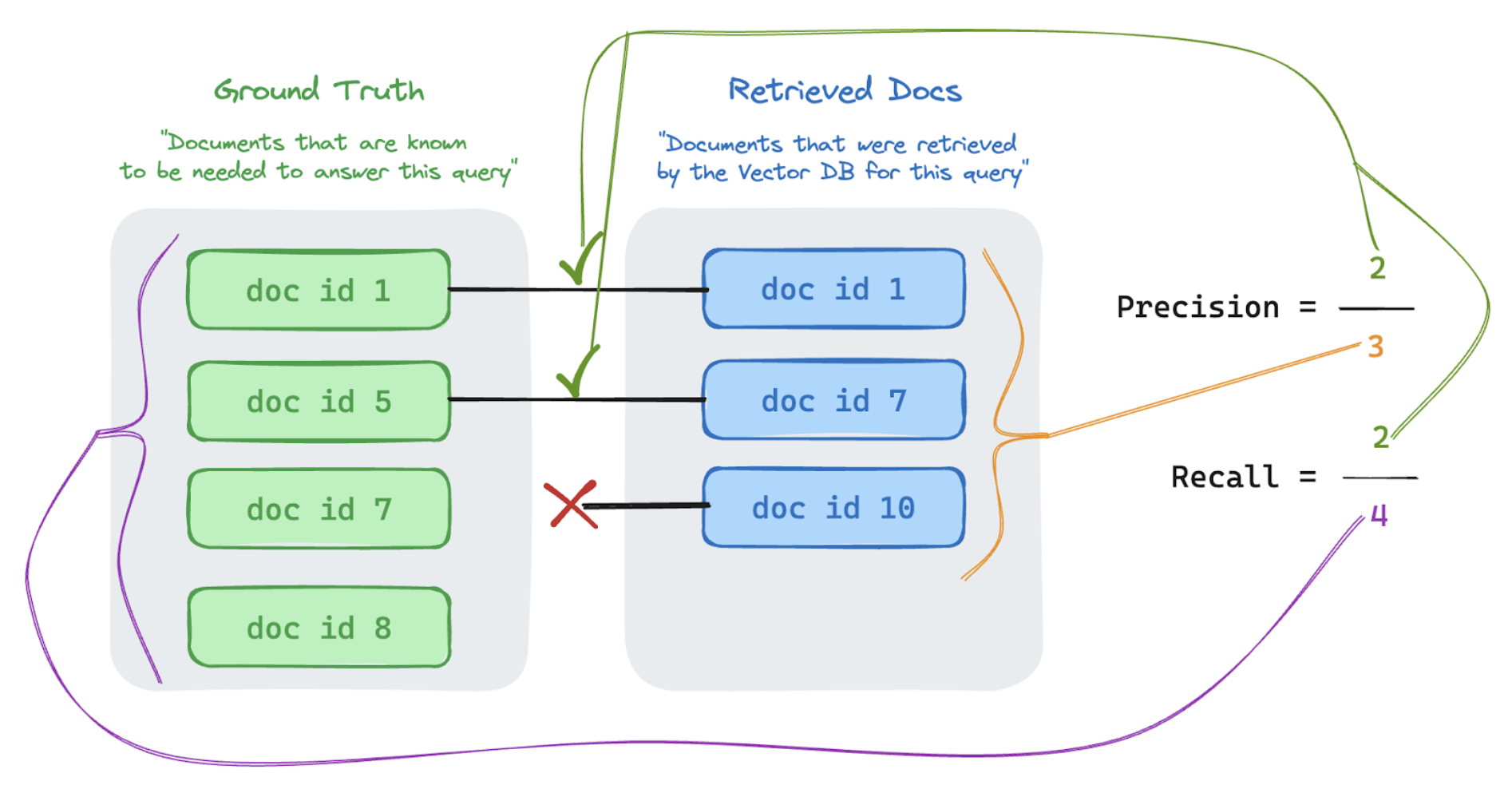
Precision och återkallning
Nedan visas en snabb introduktion till precision och minnesåtergivning anpassad från den utmärkta Wikipedia-artikeln.
Precisionsformel
Precisionsmått "Vilka % av de här objekten är faktiskt relevanta för min användares fråga av de segment jag hämtade?" Databehandlingsprecision kräver inte att du känner till alla relevanta objekt.
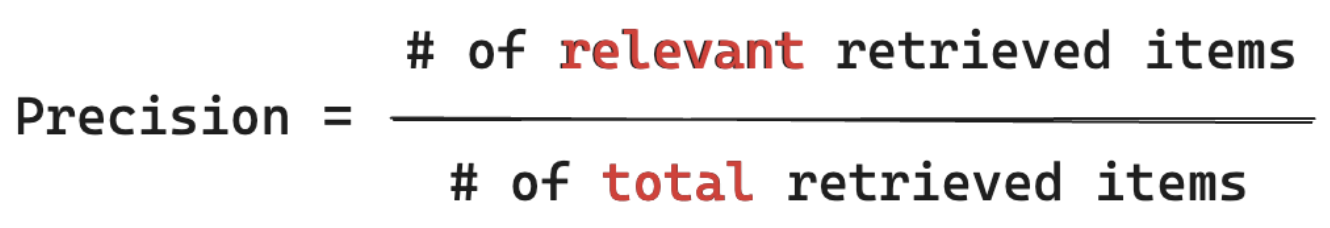
Återkallningsformel
Återkalla mått "Av alla dokument som jag vet är relevanta för användarens fråga, vilka % hämtade jag ett segment från?" Databehandlingsåterkallning kräver att din grundsanning innehåller alla relevanta objekt. Objekt kan antingen vara ett dokument eller ett segment av ett dokument.
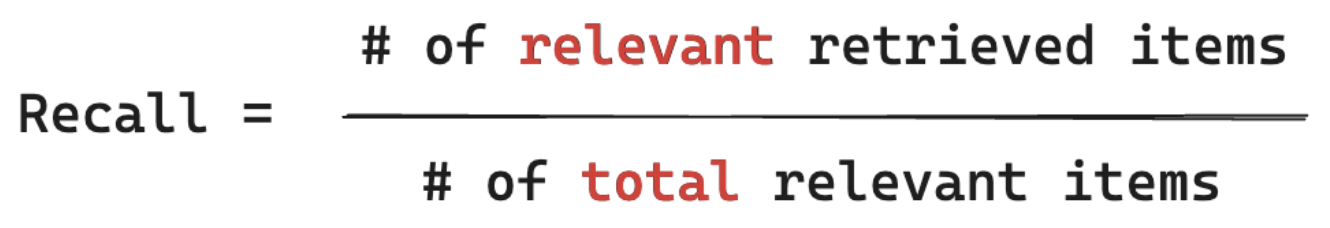
I exemplet nedan var två av de tre hämtade resultaten relevanta för användarens fråga, så precisionen var 0,66 (2/3). De hämtade dokumenten innehöll två av totalt fyra relevanta dokument, så återkallelsen var 0,5 (2/4).