Vägledande principer för sjöhuset
Vägledande principer är nivå-noll-regler som definierar och påverkar din arkitektur. För att skapa ett datasjöhus som hjälper ditt företag att lyckas nu och i framtiden är konsensus mellan intressenter i din organisation avgörande.
Kurera data och erbjuda betrodda data som produkter
Att kurera data är viktigt för att skapa en datasjö med högt värde för BI och ML/AI. Behandla data som en produkt med en tydlig definition, ett schema och en livscykel. Se till att semantisk konsekvens och att datakvaliteten förbättras från lager till lager så att företagsanvändare kan lita fullt ut på data.
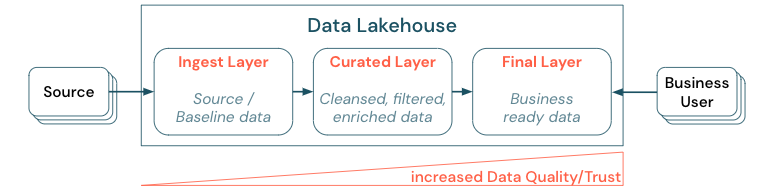
Att kurera data genom att upprätta en arkitektur med flera lager (eller flera hopp) är en viktig metod för lakehouse, eftersom det gör det möjligt för datateam att strukturera data enligt kvalitetsnivåer och definiera roller och ansvarsområden per lager. En vanlig skiktningsmetod är:
- Inmatningslager: Källdata matas in i lakehouse i det första lagret och bör sparas där. När alla underordnade data skapas från inmatningslagret är det möjligt att återskapa efterföljande lager från det här lagret om det behövs.
- Kuraterat lager: Syftet med det andra lagret är att lagra rensade, raffinerade, filtrerade och aggregerade data. Målet med det här lagret är att ge en sund och tillförlitlig grund för analyser och rapporter i alla roller och funktioner.
- Sista lagret: Det tredje lagret skapas kring affärs- eller projektbehov. Det ger en annan vy som dataprodukter till andra affärsenheter eller projekt, förbereder data kring säkerhetsbehov (till exempel anonymiserade data) eller optimerar för prestanda (med föraggregerade vyer). Dataprodukterna i det här lagret ses som sanningen för verksamheten.
Pipelines i alla lager måste säkerställa att datakvalitetsbegränsningar uppfylls, vilket innebär att data alltid är korrekta, fullständiga, tillgängliga och konsekventa, även under samtidiga läsningar och skrivningar. Valideringen av nya data sker vid tidpunkten för datainmatningen till det kurerade lagret, och följande ETL-steg fungerar för att förbättra kvaliteten på dessa data. Datakvaliteten måste förbättras i takt med att data utvecklas genom lagren och därför ökar förtroendet för data senare ur affärssynpunkt.
Eliminera datasilor och minimera dataförflyttning
Skapa inte kopior av en datauppsättning med affärsprocesser som förlitar sig på dessa olika kopior. Kopior kan bli datasilor som blir osynkroniserade, vilket leder till lägre kvalitet på din datasjö och slutligen till inaktuella eller felaktiga insikter. För att dela data med externa partner använder du också en mekanism för företagsdelning som ger direkt åtkomst till data på ett säkert sätt.
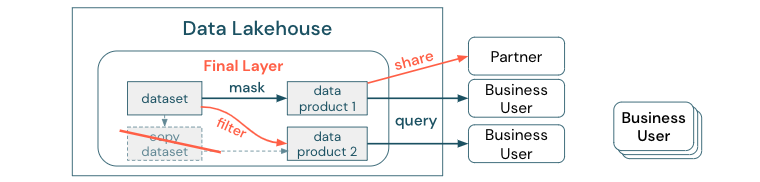
För att göra skillnaden tydlig mellan en datakopia och en datasilo: En fristående eller utspringbar kopia av data är inte skadlig på egen hand. Det är ibland nödvändigt för att öka flexibiliteten, experimenteringen och innovationen. Men om dessa kopior tas i drift med underordnade affärsdataprodukter som är beroende av dem blir de datasilor.
För att förhindra datasilor försöker datateam vanligtvis skapa en mekanism eller datapipeline för att hålla alla kopior synkroniserade med originalet. Eftersom detta sannolikt inte kommer att ske konsekvent försämras datakvaliteten så småningom. Detta kan också leda till högre kostnader och en betydande förlust av förtroende för användarna. Å andra sidan kräver flera affärsanvändningsfall datadelning med partner eller leverantörer.
En viktig aspekt är att dela den senaste versionen av datamängden på ett säkert och tillförlitligt sätt. Kopior av datamängden räcker ofta inte, eftersom de snabbt kan bli osynkroniserade. I stället bör data delas via företagets datadelningsverktyg.
Demokratisera värdeskapande via självbetjäning
Den bästa datasjön kan inte ge tillräckligt med värde om användarna inte enkelt kan komma åt plattformen eller data för sina BI- och ML/AI-uppgifter. Minska hindren för åtkomst till data och plattformar för alla affärsenheter. Överväg lean data management-processer och ge självbetjäningsåtkomst för plattformen och underliggande data.
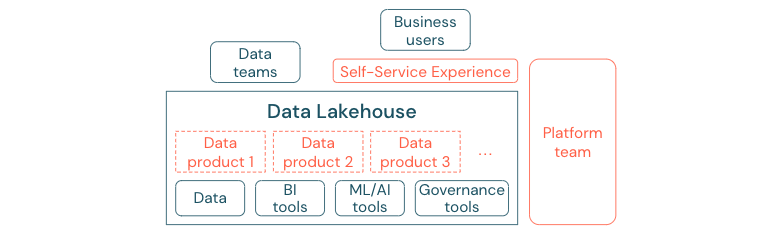
Företag som har flyttat till en datadriven kultur kommer att blomstra. Det innebär att varje affärsenhet härleder sina beslut från analysmodeller eller från att analysera egna eller centralt tillhandahållna data. För konsumenter måste data enkelt identifieras och vara säkert tillgängliga.
Ett bra koncept för dataproducenter är "data som en produkt": Data erbjuds och underhålls av en affärsenhet eller affärspartner som en produkt och förbrukas av andra parter med rätt behörighetskontroll. I stället för att förlita sig på ett centralt team och potentiellt långsamma begärandeprocesser måste dessa dataprodukter skapas, erbjudas, identifieras och användas i en självbetjäningsupplevelse.
Det är dock inte bara data som är viktiga. Demokratisering av data kräver rätt verktyg för att alla ska kunna producera eller använda och förstå data. För detta behöver du data lakehouse vara en modern data- och AI-plattform som tillhandahåller infrastruktur och verktyg för att skapa dataprodukter utan att duplicera arbetet med att konfigurera en annan verktygsstack.
Anta en strategi för datastyrning i hela organisationen
Data är en viktig tillgång för alla organisationer, men du kan inte ge alla åtkomst till alla data. Dataåtkomst måste hanteras aktivt. Åtkomstkontroll, granskning och ursprungsspårning är viktiga för korrekt och säker användning av data.
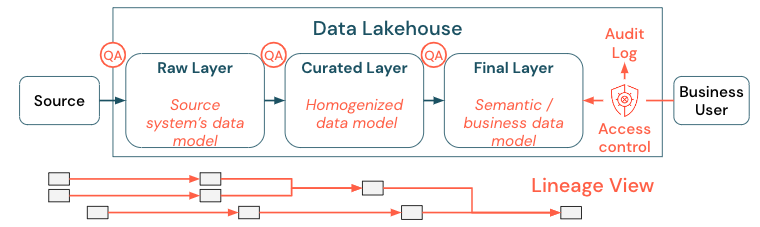
Datastyrning är ett brett ämne. Sjöhuset täcker följande dimensioner:
Datakvalitet
Den viktigaste förutsättningen för korrekta och meningsfulla rapporter, analysresultat och modeller är data av hög kvalitet. Kvalitetssäkring (QA) måste finnas runt alla pipelinesteg. Exempel på hur du implementerar detta är att ha datakontrakt, uppfylla serviceavtal, hålla scheman stabila och utveckla dem på ett kontrollerat sätt.
Datakatalog
En annan viktig aspekt är dataidentifiering: Användare av alla affärsområden, särskilt i en självbetjäningsmodell, måste enkelt kunna identifiera relevanta data. Därför behöver ett lakehouse en datakatalog som omfattar alla affärsreleventa data. De primära målen för en datakatalog är följande:
- Se till att samma affärsidé anropas och deklareras enhetligt i hela verksamheten. Du kanske ser det som en semantisk modell i det kurerade och sista lagret.
- Spåra data härstamningen exakt så att användarna kan förklara hur dessa data kom fram till deras aktuella form och form.
- Underhålla metadata av hög kvalitet, vilket är lika viktigt som själva data för korrekt användning av data.
Åtkomstkontroll
När värdeskapandet från data i lakehouse sker i alla affärsområden måste sjöhuset byggas med säkerhet som en förstklassig medborgare. Företag kan ha en mer öppen dataåtkomstprincip eller strikt följa principen om minsta behörighet. Oberoende av detta måste dataåtkomstkontroller finnas på plats i varje lager. Det är viktigt att implementera finklassade behörighetsscheman från början (åtkomstkontroll på kolumn- och radnivå, rollbaserad eller attributbaserad åtkomstkontroll). Företag kan börja med mindre strikta regler. Men i takt med att lakehouse-plattformen växer bör alla mekanismer och processer för ett mer sofistikerat säkerhetssystem redan finnas på plats. Dessutom måste all åtkomst till data i lakehouse styras av granskningsloggar från get-go.
Uppmuntra öppna gränssnitt och öppna format
Öppna gränssnitt och dataformat är avgörande för samverkan mellan lakehouse och andra verktyg. Det förenklar integreringen med befintliga system och öppnar även ett ekosystem av partner som har integrerat sina verktyg med plattformen.
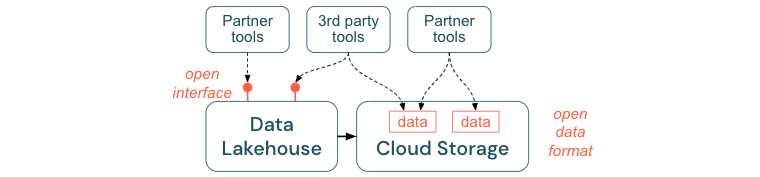
Öppna gränssnitt är viktiga för att möjliggöra samverkan och förhindra beroende av en enskild leverantör. Traditionellt har leverantörer byggt proprietära tekniker och slutna gränssnitt som begränsar företag på det sätt som de kan lagra, bearbeta och dela data.
Genom att bygga på öppna gränssnitt kan du skapa för framtiden:
- Det ökar livslängden och portabiliteten för data så att du kan använda dem med fler program och för fler användningsfall.
- Det öppnar ett ekosystem av partner som snabbt kan utnyttja de öppna gränssnitten för att integrera sina verktyg i Lakehouse-plattformen.
Genom att standardisera på öppna format för data blir de totala kostnaderna betydligt lägre. man kan komma åt data direkt på molnlagringen utan att behöva skicka dem via en egenutvecklad plattform som kan medföra höga kostnader för utgående och beräkning.
Skapa för att skala och optimera för prestanda och kostnad
Data fortsätter oundvikligen att växa och bli mer komplexa. För att rusta din organisation för framtida behov bör ditt sjöhus kunna skalas. Du bör till exempel enkelt kunna lägga till nya resurser på begäran. Kostnaderna bör begränsas till den faktiska förbrukningen.
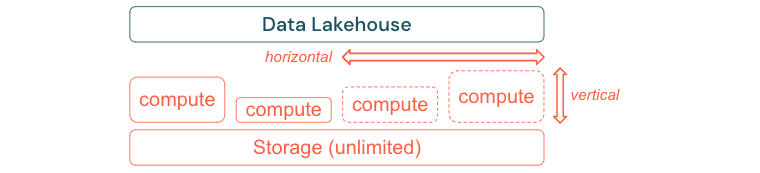
Standard-ETL-processer, affärsrapporter och instrumentpaneler har ofta ett förutsägbart resursbehov ur ett minnes- och beräkningsperspektiv. Nya projekt, säsongsaktiviteter eller moderna metoder som modellträning (omsättning, prognos, underhåll) genererar dock toppar i resursbehovet. För att ett företag ska kunna utföra alla dessa arbetsbelastningar krävs en skalbar plattform för minne och beräkning. Nya resurser måste enkelt läggas till på begäran, och endast den faktiska förbrukningen ska generera kostnader. Så snart toppen är över kan resurser frigöras igen och kostnaderna minskas i enlighet därmed. Detta kallas ofta för horisontell skalning (färre eller fler noder) och vertikal skalning (större eller mindre noder).
Skalning gör det också möjligt för företag att förbättra prestandan för frågor genom att välja noder med fler resurser eller kluster med fler noder. Men i stället för att permanent tillhandahålla stora datorer och kluster kan de endast etableras på begäran under den tid som behövs för att optimera det övergripande förhållandet mellan prestanda och kostnad. En annan aspekt av optimeringen är lagring jämfört med beräkningsresurser. Eftersom det inte finns någon tydlig relation mellan mängden data och arbetsbelastningar som använder dessa data (till exempel att endast använda delar av data eller utföra intensiva beräkningar på små data) är det en bra idé att etablera sig på en infrastrukturplattform som frikopplar lagrings- och beräkningsresurser.