Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Ett datasjöhus är ett datahanteringssystem som kombinerar fördelarna med datasjöar och informationslager. I den här artikeln beskrivs lakehouse-arkitekturmönstret och vad du kan göra med det i Azure Databricks.
Vad används ett datasjöhus till?
Ett datasjöhus ger skalbara lagrings- och bearbetningsfunktioner för moderna organisationer som vill undvika isolerade system för bearbetning av olika arbetsbelastningar, till exempel maskininlärning (ML) och Business Intelligence (BI). Ett datasjöhus kan hjälpa dig att upprätta en enda sanningskälla, eliminera redundanta kostnader och säkerställa datas färskhet.
Data lakehouses använder ofta ett mönster för datadesign som stegvis förbättrar, berikar och förfinar data när de rör sig genom lager av mellanlagring och transformering. Varje lager i lakehouse-strukturen kan innehålla ett eller flera lager. Det här mönstret kallas ofta för en medaljongarkitektur. Mer information finns i Vad är medallion lakehouse-arkitekturen?
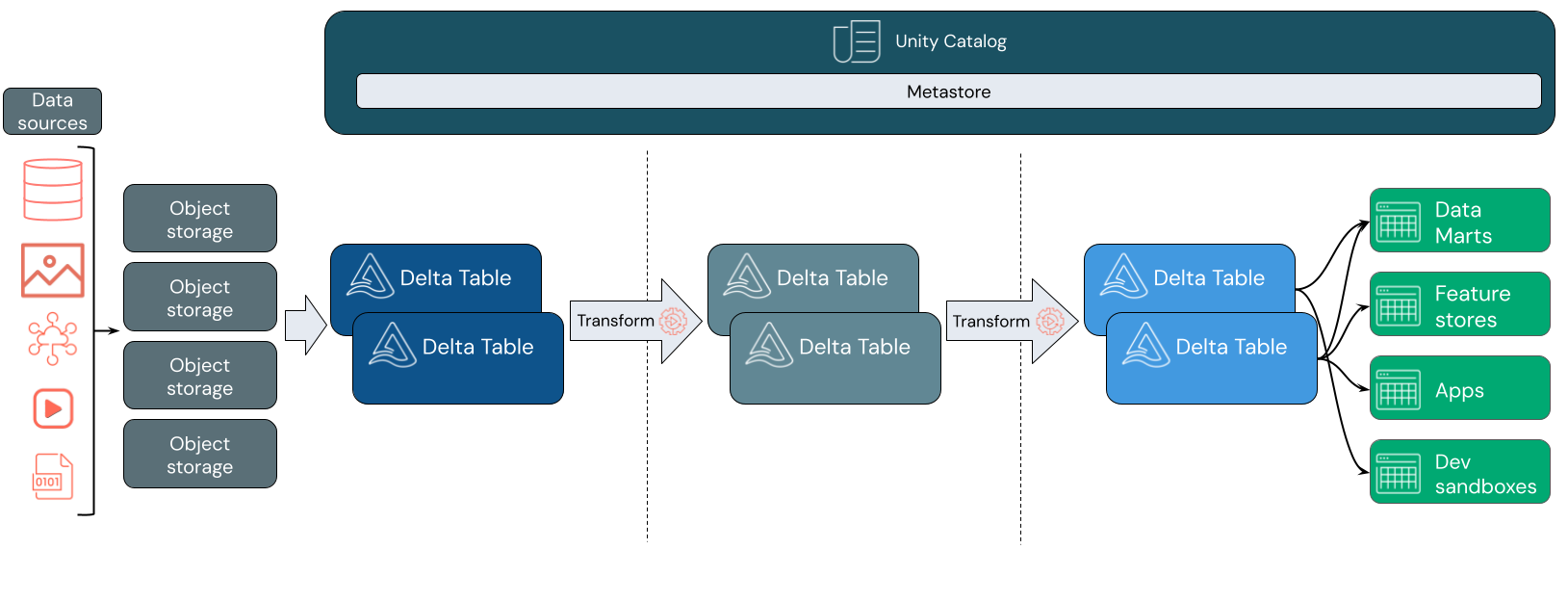
Hur fungerar Databricks lakehouse?
Databricks bygger på Apache Spark. Apache Spark möjliggör en massivt skalbar motor som körs på beräkningsresurser som är frikopplade från lagring. Mer information finns i Översikt över Apache Spark
Databricks lakehouse använder ytterligare två viktiga tekniker:
- Delta Lake: ett optimerat lagringslager som stöder ACID-transaktioner och schemaframtvingande.
- Unity Catalog: en enhetlig, detaljerad styrningslösning för data och AI.
Datainmatning
Vid inmatningslagret anländer batch- eller strömmande data från en mängd olika källor och i olika format. Det här första logiska lagret är en plats där dessa data kan landa i dess råformat. När du konverterar filerna till Delta-tabeller kan du använda funktionerna för schematillämpning i Delta Lake för att söka efter saknade eller oväntade data. Du kan använda Unity Catalog för att registrera tabeller enligt din datastyrningsmodell och nödvändiga gränser för dataisolering. Med Unity Catalog kan du spåra ursprunget för dina data när de transformeras och förfinas, samt använda en enhetlig styrningsmodell för att hålla känsliga data privata och säkra.
Databehandling, kuration och integrering
När du har verifierat det kan du börja sortera och förfina dina data. Dataforskare och maskininlärningsutövare arbetar ofta med data i det här skedet för att börja kombinera eller skapa nya funktioner och slutföra datarensningen. När dina data har rensats noggrant kan de integreras och omorganiseras i tabeller som är utformade för att uppfylla dina specifika affärsbehov.
En schema-on-write-metod i kombination med deltaschemautvecklingsfunktioner innebär att du kan göra ändringar i det här lagret utan att nödvändigtvis behöva skriva om den nedströmslogik som hanterar data till slutanvändarna.
Dataleverans
Det sista lagret innehåller rena, berikade data till slutanvändare. De sista tabellerna bör utformas för att hantera data för alla dina användningsfall. En enhetlig styrningsmodell innebär att du kan spåra data härstamning tillbaka till din enda sanningskälla. Datalayouter, optimerade för olika uppgifter, gör det möjligt för slutanvändare att komma åt data för maskininlärningsprogram, datateknik och business intelligence och rapportering.
Mer information om Delta Lake finns i Vad är Delta Lake i Azure Databricks? Mer information om Unity Catalog finns i Vad är Unity Catalog?
Kapaciteter för ett Databricks lakehouse
Ett sjöhus byggt på Databricks ersätter det nuvarande beroendet av datasjöar och informationslager för moderna dataföretag. Några viktiga uppgifter som du kan utföra är:
- databearbetning i realtid: Bearbeta strömmande data i realtid för omedelbar analys och åtgärd.
- dataintegrering: Förena dina data i ett enda system för att möjliggöra samarbete och upprätta en enda sanningskälla för din organisation.
- Schemautveckling: Ändra dataschema över tid för att anpassa till föränderliga affärsbehov utan att störa befintliga datapipelines.
- Datatransformeringar: Användning av Apache Spark och Delta Lake ger dina data hastighet, skalbarhet och tillförlitlighet.
- Dataanalys och rapportering: Kör komplexa analysfrågor med en motor optimerad för data warehousing-arbetsbelastningar.
- Maskininlärning och AI: Tillämpa avancerade analystekniker på alla dina data. Använd ML för att utöka dina data och stödja andra arbetsbelastningar.
- Data versionshantering och ursprung: Underhålla versionshistorik för datauppsättningar och spåra ursprung för att säkerställa data proveniens och spårbarhet.
- Datastyrning: Använd ett enda enhetligt system för att kontrollera åtkomsten till dina data och utföra granskningar.
- Datadelning: Underlätta samarbete genom att tillåta delning av utvalda datauppsättningar, rapporter och insikter mellan team.
- Driftanalys: Övervaka datakvalitetsmått, modellkvalitetsmått och drift med hjälp av datakvalitetsövervakning.
Lakehouse vs Data Lake vs Data Warehouse
Informationslager har drivit business intelligence-beslut (BI) i cirka 30 år, efter att ha utvecklats som en uppsättning designriktlinjer för system som styr dataflödet. Företagsdatalager optimerar frågor för BI-rapporter, men det kan ta minuter eller till och med timmar att generera resultat. Informationslagret är utformat för data som sannolikt inte kommer att ändras med hög frekvens och försöker förhindra konflikter mellan frågor som körs samtidigt. Många informationslager förlitar sig på egna format, vilket ofta begränsar stödet för maskininlärning. Datalagerhantering i Azure Databricks utnyttjar funktionerna i en Databricks lakehouse och Databricks SQL. Mer information finns i Informationslager på Azure Databricks.
Datasjöar som drivs av tekniska framsteg inom datalagring och drivs av exponentiella ökningar av datatyper och datavolymer har använts i stor utsträckning under det senaste decenniet. Datasjöar lagrar och bearbetar data billigt och effektivt. Datasjöar definieras ofta i motsats till informationslager: Ett informationslager levererar rena, strukturerade data för BI-analys, medan en datasjö permanent och billigt lagrar data av alla slag i alla format. Många organisationer använder datasjöar för datavetenskap och maskininlärning, men inte för BI-rapportering på grund av dess ovaliderade karaktär.
Data lakehouse kombinerar fördelarna med datasjöar och informationslager och tillhandahåller:
- Öppna, direktåtkomst till data som lagras i standarddataformat.
- Indexeringsprotokoll som är optimerade för maskininlärning och datavetenskap.
- Låg frågesvarstid och hög tillförlitlighet för BI och avancerad analys.
Genom att kombinera ett optimerat metadatalager med verifierade data som lagras i standardformat i molnobjektlagring kan du arbeta med Data Lakehouse från samma data och på samma plattform i olika användningsfall.
Nästa steg
Mer information om principer och metodtips för att implementera och driva ett sjöhus med Databricks finns i Introduktion till det välarkitekterade datasjöhuset