Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Lakeflow Spark Deklarativa pipelines (SDP) introducerar flera nya Python-kodkonstruktioner för att definiera materialiserade vyer och strömmande tabeller i pipelines. Python-stöd för att utveckla pipelines bygger på grunderna i PySpark DataFrame och API:er för strukturerad direktuppspelning.
För användare som inte är bekanta med Python och DataFrames rekommenderar Databricks att du använder SQL-gränssnittet. Se Utveckla Lakeflow Spark Deklarativ pipelines-kod med SQL.
En fullständig referens till Python-syntaxen för Lakeflow SDP finns i Språkreferens för Python för Lakeflow Spark Deklarativa Pipelines.
Grunderna i Python för pipelineutveckling
Python-kod som skapar pipline-datauppsättningar måste returnera DataFrames.
Alla Python-API:er för Lakeflow Sparks deklarativa pipelines implementeras i modulen pyspark.pipelines. Din pipelinekod som implementeras med Python måste uttryckligen importera modulen pipelines överst i Python-källan. I våra exempel använder vi följande importkommando och använder dp i exempel för att referera till pipelines.
from pyspark import pipelines as dp
Anmärkning
Apache Spark™ innehåller deklarativa pipelines som börjar i Spark 4.1, tillgängliga via modulen pyspark.pipelines . Databricks Runtime utökar dessa funktioner med öppen källkod med ytterligare API:er och integreringar för hanterad produktionsanvändning.
Kod som skrivs med modulen öppen källkod pipelines körs utan ändringar i Azure Databricks. Följande funktioner ingår inte i Apache Spark:
dp.create_auto_cdc_flowdp.create_auto_cdc_from_snapshot_flow@dp.expect(...)
Pipeline läser och skriver som standard den katalog och det schema som angavs under pipelinekonfigurationen. Se Ange målkatalogen och schemat.
Pipelinespecifik Python-kod skiljer sig från andra typer av Python-kod på ett kritiskt sätt: Python-pipelinekod anropar inte direkt de funktioner som utför datainmatning och transformering för att skapa datauppsättningar. I stället tolkar SDP dekoratörsfunktionerna från modulen dp i alla källkodsfiler som konfigurerats i en pipeline och skapar ett dataflödesdiagram.
Viktigt!
Om du vill undvika oväntat beteende när pipelinen körs ska du inte inkludera kod som kan ha biverkningar i dina funktioner som definierar datauppsättningar. Mer information finns i Python-referensen.
Skapa en materialiserad vy eller strömningstabell med Python
Använd @dp.table för att skapa en strömmande tabell från resultatet av en direktuppspelningsläsning. Använd @dp.materialized_view för att skapa en materialiserad vy från resultatet av en batchläsning.
Som standard härleds materialiserade vy- och strömningstabellnamn från funktionsnamn. I följande kodexempel visas den grundläggande syntaxen för att skapa en materialiserad vy och en strömmande tabell:
Anmärkning
Båda funktionerna refererar till samma tabell i samples-katalogen och använder samma dekoratörsfunktion. De här exemplen visar att den enda skillnaden i den grundläggande syntaxen för materialiserade vyer och strömmande tabeller är att använda spark.read jämfört med spark.readStream.
Alla datakällor stöder inte direktuppspelningsläsningar. Vissa datakällor bör alltid bearbetas med strömmande semantik.
from pyspark import pipelines as dp
@dp.materialized_view()
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dp.table()
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Valfritt kan du ange tabellnamnet med name argumentet i @dp.table dekorator. I följande exempel visas det här mönstret för en materialiserad vy och en strömmande tabell:
from pyspark import pipelines as dp
@dp.materialized_view(name = "trips_mv")
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dp.table(name = "trips_st")
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Läsa in data från objektlagring
Pipelines stöder inläsning av data från alla format som stöds av Azure Databricks. Se alternativ för dataformat.
Anmärkning
I de här exemplen används data som är tillgängliga under /databricks-datasets och monteras automatiskt på din arbetsyta. Databricks rekommenderar att du använder volymsökvägar eller moln-URI:er för att referera till data som lagras i molnobjektlagring. Se Vad är Unity Catalog-volymer?.
Databricks rekommenderar att du använder tabeller för automatisk inläsning och strömning när du konfigurerar inkrementella inmatningsarbetsbelastningar mot data som lagras i molnobjektlagring. Se Vad är en automatisk inläsare?.
I följande exempel skapas en strömmande tabell från JSON-filer med autoinläsning:
from pyspark import pipelines as dp
@dp.table()
def ingestion_st():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
I följande exempel används batchsemantik för att läsa en JSON-katalog och skapa en materialiserad vy:
from pyspark import pipelines as dp
@dp.materialized_view()
def batch_mv():
return spark.read.format("json").load("/databricks-datasets/retail-org/sales_orders")
Verifiera data med förväntningar
Du kan använda förväntningar för att ange och tillämpa datakvalitetsbegränsningar. Se avsnittet Hantera datakvalitet med pipeline-förväntningar.
Följande kod använder @dp.expect_or_drop för att definiera en förväntan med namnet valid_data som tar bort poster som är null under datainmatning:
from pyspark import pipelines as dp
@dp.table()
@dp.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders_valid():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
Fråga efter materialiserade vyer och strömstabeller som är definierade i din pipeline
I följande exempel definieras fyra datauppsättningar:
- En strömmande tabell med namnet
orderssom läser in JSON-data. - En materialiserad vy med namnet
customerssom läser in CSV-data. - En materialiserad vy med namnet
customer_orderssom kopplar poster från datauppsättningarnaordersochcustomers, omvandlar ordertidsstämpeln till ett datum och väljer fältencustomer_id,order_number,stateochorder_date. - En materialiserad vy med namnet
daily_orders_by_statesom aggregerar det dagliga antalet order för varje tillstånd.
Anmärkning
När du kör frågor mot vyer eller tabeller i pipelinen kan du ange katalogen och schemat direkt, eller så kan du använda standardvärdena som konfigurerats i pipelinen. I det här exemplet skrivs tabellerna orders, customersoch customer_orders från standardkatalogen och schemat som konfigurerats för pipelinen.
Publiceringsläget för äldre system använder LIVE-schemat för att hämta data från andra materialiserade vyer och strömmande tabeller som definierats i din pipeline. I nya pipelines ignoreras schemasyntaxen LIVE utan att det märks. Se LIVE-schemat (äldre).
from pyspark import pipelines as dp
from pyspark.sql.functions import col
@dp.table()
@dp.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
@dp.materialized_view()
def customers():
return spark.read.format("csv").option("header", True).load("/databricks-datasets/retail-org/customers")
@dp.materialized_view()
def customer_orders():
return (spark.read.table("orders")
.join(spark.read.table("customers"), "customer_id")
.select("customer_id",
"order_number",
"state",
col("order_datetime").cast("int").cast("timestamp").cast("date").alias("order_date"),
)
)
@dp.materialized_view()
def daily_orders_by_state():
return (spark.read.table("customer_orders")
.groupBy("state", "order_date")
.count().withColumnRenamed("count", "order_count")
)
Skapa tabeller i en for-loop
Du kan använda Python for-loopar för att skapa flera tabeller programmatiskt. Detta kan vara användbart när du har många datakällor eller måldatauppsättningar som bara varierar med några få parametrar, vilket resulterar i mindre total kod att underhålla och mindre kodredundans.
Den for-loopen utvärderar logik i seriell ordning, men när planeringen är klar för datauppsättningarna körs logiken parallellt.
Viktigt!
När du använder det här mönstret för att definiera datauppsättningar kontrollerar du att listan över värden som skickas till for-loopen alltid är additiv. Om en datauppsättning som tidigare definierats i en pipeline utelämnas från en framtida pipelinekörning tas datauppsättningen bort automatiskt från målschemat.
I följande exempel skapas fem tabeller som filtrerar kundbeställningar efter region. Här används regionnamnet för att ange namnet på de materialiserade målvyerna och filtrera källdata. Tillfälliga vyer används för att definiera kopplingar från de källtabeller som används för att skapa de slutliga materialiserade vyerna.
from pyspark import pipelines as dp
from pyspark.sql.functions import collect_list, col
@dp.temporary_view()
def customer_orders():
orders = spark.read.table("samples.tpch.orders")
customer = spark.read.table("samples.tpch.customer")
return (orders.join(customer, orders.o_custkey == customer.c_custkey)
.select(
col("c_custkey").alias("custkey"),
col("c_name").alias("name"),
col("c_nationkey").alias("nationkey"),
col("c_phone").alias("phone"),
col("o_orderkey").alias("orderkey"),
col("o_orderstatus").alias("orderstatus"),
col("o_totalprice").alias("totalprice"),
col("o_orderdate").alias("orderdate"))
)
@dp.temporary_view()
def nation_region():
nation = spark.read.table("samples.tpch.nation")
region = spark.read.table("samples.tpch.region")
return (nation.join(region, nation.n_regionkey == region.r_regionkey)
.select(
col("n_name").alias("nation"),
col("r_name").alias("region"),
col("n_nationkey").alias("nationkey")
)
)
# Extract region names from region table
region_list = spark.read.table("samples.tpch.region").select(collect_list("r_name")).collect()[0][0]
# Iterate through region names to create new region-specific materialized views
for region in region_list:
@dp.materialized_view(name=f"{region.lower().replace(' ', '_')}_customer_orders")
def regional_customer_orders(region_filter=region):
customer_orders = spark.read.table("customer_orders")
nation_region = spark.read.table("nation_region")
return (customer_orders.join(nation_region, customer_orders.nationkey == nation_region.nationkey)
.select(
col("custkey"),
col("name"),
col("phone"),
col("nation"),
col("region"),
col("orderkey"),
col("orderstatus"),
col("totalprice"),
col("orderdate")
).filter(f"region = '{region_filter}'")
)
Följande är ett exempel på dataflödesdiagrammet för den här pipelinen:
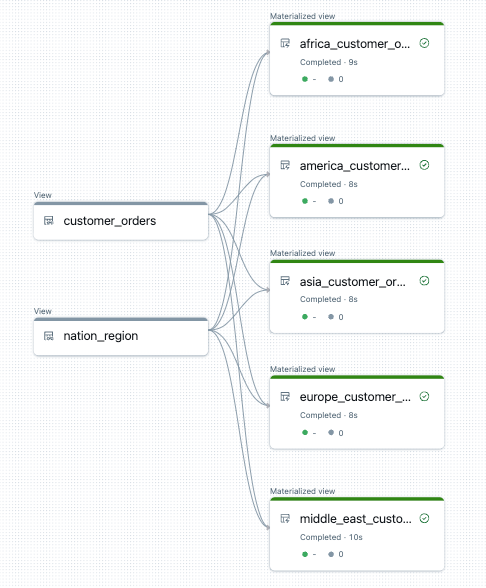
Felsökning: for loop skapar många tabeller med samma värden
Den lata utförandemodell som pipelines använder för att utvärdera Python-kod kräver att din logik direkt refererar till enskilda värden när funktionen som är dekorerad med @dp.materialized_view() anropas.
I följande exempel visas två korrekta metoder för att definiera tabeller med en for-loop. I båda exemplen refereras varje tabellnamn från listan tables uttryckligen i funktionen som är dekorerad av @dp.materialized_view().
from pyspark import pipelines as dp
# Create a parent function to set local variables
def create_table(table_name):
@dp.materialized_view(name=table_name)
def t():
return spark.read.table(table_name)
tables = ["t1", "t2", "t3"]
for t_name in tables:
create_table(t_name)
# Call `@dp.materialized_view()` within a for loop and pass values as variables
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dp.materialized_view(name=t_name)
def create_table(table_name=t_name):
return spark.read.table(table_name)
Följande exempel refererar inte till referensvärden korrekt. I det här exemplet skapas tabeller med distinkta namn, men alla tabeller läser in data från det sista värdet i for-loopen:
from pyspark import pipelines as dp
# Don't do this!
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dp.materialized(name=t_name)
def create_table():
return spark.read.table(t_name)
Ta bort poster permanent från en materialiserad vy eller direktuppspelningstabell
Om du vill ta bort poster permanent från en materialiserad vy eller strömningstabell med borttagningsvektorer aktiverade, till exempel för GDPR-efterlevnad, måste ytterligare åtgärder utföras på objektets underliggande Delta-tabeller. Information om hur du tar bort poster från en materialiserad vy finns i Ta bort poster permanent från en materialiserad vy med borttagningsvektorer aktiverade. Information om hur du tar bort poster från en strömmande tabell finns i Ta bort poster permanent från en strömmande tabell.