Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Inom datateknik refererar återfyllnad till processen att retroaktivt bearbeta historiska data via en datapipeline som har utformats för bearbetning av aktuella eller strömmande data.
Det här är vanligtvis ett separat flöde som skickar data till dina befintliga tabeller. Följande bild visar ett återfyllnadsflöde som skickar historiska data till bronstabellerna i pipelinen.
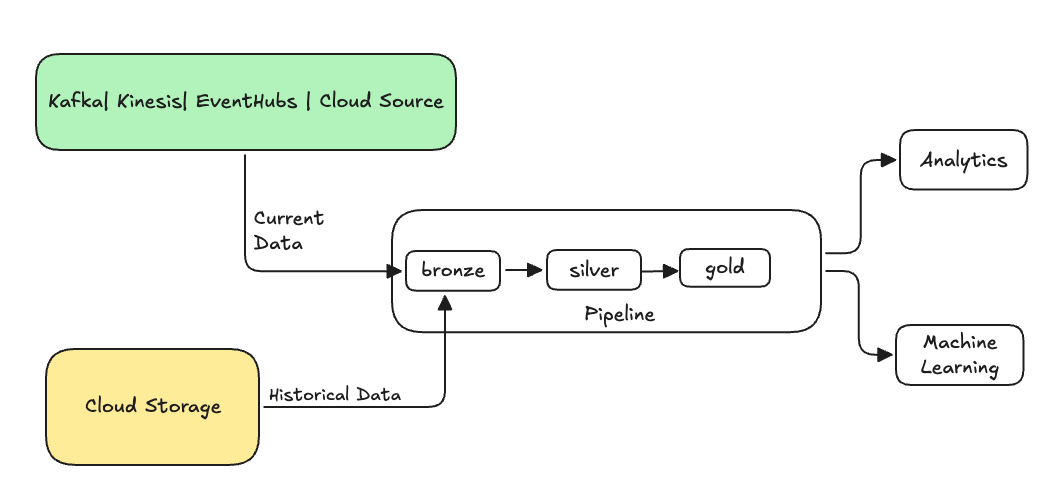
Vissa scenarier som kan kräva en återfyllnad:
- Bearbeta historiska data från ett äldre system för att träna en maskininlärningsmodell (ML) eller skapa en instrumentpanel för historisk trendanalys.
- Bearbeta en delmängd av data på grund av ett datakvalitetsproblem med överordnade datakällor.
- Dina affärskrav har ändrats och du måste fylla på data under en annan tidsperiod som inte omfattades av den inledande pipelinen.
- Din affärslogik har ändrats och du måste bearbeta om både historiska och aktuella data.
En återfyllnad i Lakeflow Spark Deklarativa Pipelines stöds med ett specialiserat tilläggsflöde som använder ONCE-alternativet. Mer information om alternativet finns i append_flow eller ONCE).
Överväganden vid återfyllning av historiska data i en strömningstabell
- Vanligtvis läggs data till i bronstabellen för strömmande data. Nedströms silver- och guldlager hämtar nya data från bronsskiktet.
- Se till att din pipeline kan hantera duplicerade data korrekt om samma data läggs till flera gånger.
- Kontrollera att det historiska dataschemat är kompatibelt med det aktuella dataschemat.
- Överväg datavolymstorleken och det nödvändiga serviceavtalet för bearbetningstid och konfigurera därefter klustret och batchstorlekarna.
Exempel: Lägga till en återfyllnad i en befintlig pipeline
I det här exemplet säger du att du har en pipeline som matar in råa händelseregistreringsdata från en molnlagringskälla från och med jan 01, 2025. Du inser senare att du vill fylla på historiska data från de föregående tre åren för nedströmsrapportering och analysanvändningsfall. Alla data finns på en plats, partitionerade efter år, månad och dag, i JSON-format.
Inledande pipeline
Här är den start-pipelinekod som inkrementellt matar in rådata för händelseregistrering från molnlagringen.
python
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
incremental_load_path = f"{source_root_path}/*/*/*"
# create a streaming table and the default flow to ingest streaming events
@dp.table(name="registration_events_raw", comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2025-01-01T00:00:00.000+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}") # safeguard to not process data before begin_year
)
SQL
-- create a streaming table and the default flow to ingest streaming events
CREATE OR REFRESH STREAMING LIVE TABLE registration_events_raw AS
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025'; -- safeguard to not process data before begin_year
Här använder vi modifiedAfter Auto Loader-alternativet för att säkerställa att vi inte bearbetar alla data från molnlagringens sökväg. Den inkrementella bearbetningen begränsas vid den gränsen.
Tips/Råd
Andra datakällor, till exempel Kafka, Kinesis och Azure Event Hubs, har motsvarande läsalternativ för att uppnå samma beteende.
Återfyllnadsdata från tidigare 3 år
Nu vill du lägga till ett eller flera flöden för att fylla på tidigare data. I det här exemplet utför du följande steg:
- Använd
append onceflödet. Detta utför en engångsåterfyllnad utan ytterligare körning efter den inledande återfyllningen. Koden finns kvar i pipelinen och om pipelinen någonsin återställs helt körs återfyllningen igen. - Skapa tre återfyllnadsflöden, en för varje år (i det här fallet delas data efter år i sökvägen). För Python parameteriserar vi skapandet av flödena, men i SQL upprepar vi koden tre gånger, en gång för varje flöde.
Om du arbetar med ditt eget projekt och inte använder serverlös beräkning kanske du vill uppdatera maximalt antal arbetare för pipelinen. Om du ökar maxantalet ser du till att du har resurser för att bearbeta historiska data samtidigt som du fortsätter att bearbeta aktuella strömmande data i det förväntade serviceavtalet.
Tips/Råd
Om du använder serverlös beräkning med förbättrad automatisk skalning (standard) ökar klustret automatiskt i storlek när belastningen ökar.
python
from pyspark import pipelines as dp
source_root_path = spark.conf.get("registration_events_source_root_path")
begin_year = spark.conf.get("begin_year")
backfill_years = spark.conf.get("backfill_years") # e.g. "2024,2023,2022"
incremental_load_path = f"{source_root_path}/*/*/*"
# meta programming to create append once flow for a given year (called later)
def setup_backfill_flow(year):
backfill_path = f"{source_root_path}/year={year}/*/*"
@dp.append_flow(
target="registration_events_raw",
once=True,
name=f"flow_registration_events_raw_backfill_{year}",
comment=f"Backfill {year} Raw registration events")
def backfill():
return (
spark
.read
.format("json")
.option("inferSchema", "true")
.load(backfill_path)
)
# create the streaming table
dp.create_streaming_table(name="registration_events_raw", comment="Raw registration events")
# append the original incremental, streaming flow
@dp.append_flow(
target="registration_events_raw",
name="flow_registration_events_raw_incremental",
comment="Raw registration events")
def ingest():
return (
spark
.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.option("cloudFiles.maxFilesPerTrigger", 100)
.option("cloudFiles.schemaEvolutionMode", "addNewColumns")
.option("modifiedAfter", "2024-12-31T23:59:59.999+00:00")
.load(incremental_load_path)
.where(f"year(timestamp) >= {begin_year}")
)
# parallelize one time multi years backfill for faster processing
# split backfill_years into array
for year in backfill_years.split(","):
setup_backfill_flow(year) # call the previously defined append_flow for each year
SQL
-- create the streaming table
CREATE OR REFRESH STREAMING TABLE registration_events_raw;
-- append the original incremental, streaming flow
CREATE FLOW
registration_events_raw_incremental
AS INSERT INTO
registration_events_raw BY NAME
SELECT * FROM STREAM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/*/*/*",
format => "json",
inferColumnTypes => true,
maxFilesPerTrigger => 100,
schemaEvolutionMode => "addNewColumns",
modifiedAfter => "2024-12-31T23:59:59.999+00:00"
)
WHERE year(timestamp) >= '2025';
-- one time backfill 2024
CREATE FLOW
registration_events_raw_backfill_2024
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2024/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2023
CREATE FLOW
registration_events_raw_backfill_2023
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2023/*/*",
format => "json",
inferColumnTypes => true
);
-- one time backfill 2022
CREATE FLOW
registration_events_raw_backfill_2022
AS INSERT INTO ONCE
registration_events_raw BY NAME
SELECT * FROM read_files(
"/Volumes/gc/demo/apps_raw/event_registration/year=2022/*/*",
format => "json",
inferColumnTypes => true
);
Den här implementeringen belyser flera viktiga mönster.
Separering av ansvar
- Inkrementell bearbetning är oberoende av datapåfyllningsoperationer.
- Varje flöde har sina egna konfigurations- och optimeringsinställningar.
- Det finns en tydlig skillnad mellan inkrementella åtgärder och återfyllnadsåtgärder.
Kontrollerad exekvering
- Om du använder alternativet
ONCEser du till att varje återfyllnad körs exakt en gång. - Återfyllnadsflödet finns kvar i pipelinediagrammet, men blir inaktivt när det är klart. Den är redo att användas vid fullständig uppdatering, automatiskt.
- Det finns ett tydligt revisionsspår med återfyllnadsoperationer i pipeline-definitionen.
Bearbetningsoptimering
- Du kan dela upp den stora bakfyllnaden i flera mindre bakfyllningar för snabbare bearbetning eller bättre kontroll över bearbetningen.
- Med förbättrad autoskalning skalas klusterstorleken dynamiskt baserat på den aktuella klusterbelastningen.
Schemautveckling
- Använda
schemaEvolutionMode="addNewColumns"hanterar schemaändringar på ett korrekt sätt. - Du har konsekventa schemainferenser för historiska och aktuella data.
- Det finns en säker hantering av nya kolumner i nyare data.