Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
I Azure Databricks kan du källkontrollera en pipeline och all kod som är associerad med den. ** Genom att källkontrollera alla filer som är associerade med din pipeline, versioneras alla ändringar i transformeringskoden, utforskningskoden och pipelinekonfigurationen i Git och kan testas i utvecklingsmiljön och säkert distribueras till produktion.
En källkontrollerad pipeline har följande fördelar:
- Spårningsbarhet: Samla in varje ändring i Git-historiken.
- Testning: Verifiera pipelineändringar i en utvecklingsarbetsyta innan du befordrar till en delad produktionsarbetsyta. Varje utvecklare har en egen utvecklingspipeline på sin egen kodgren i en Git-mapp och i sitt eget schema.
- Samarbete: När individuell utveckling och testning är klar skickas kodändringar till huvudproduktionspipelinen.
- Styrning: Anpassa till företagets CI/CD- och distributionsstandarder.
Med Azure Databricks kan pipelines och deras källfiler källkontrolleras tillsammans med deklarativa automatiseringspaket. Med paket är pipelinekonfigurationen källkontrollerad i form av YAML-konfigurationsfiler tillsammans med Python- eller SQL-källfilerna för en pipeline. Ett paket kan ha en eller flera pipelines samt andra resurstyper, till exempel jobb.
Den här sidan visar hur du konfigurerar en källkontrollerad pipeline med deklarativa Automation-paket (kallades tidigare Databricks Asset Bundles). Mer information om paket finns i Vad är deklarativa automationpaket?.
Kravspecifikation
Om du vill skapa en källkontrollerad pipeline måste du redan ha:
- En Git-mapp som skapats på din arbetsyta och konfigurerats. Med en Git-mapp kan enskilda användare skapa och testa ändringar innan de checkas in på en Git-lagringsplats. Se Azure Databricks Git-kataloger.
- Redigeraren för Lakeflow Pipelines. Mer information finns i Utveckla och felsöka ETL-pipelines med Lakeflow Pipelines-redigeraren .
- Fullständig uppsättning behörigheter som krävs för att skapa, köra, uppdatera och visa pipelines och deras utdata finns i Hantera identiteter, behörigheter och behörigheter för pipelines.
Skapa en ny pipeline i ett paket
Anmärkning
Databricks rekommenderar att du skapar en pipeline som är källkontrollerad från början. Du kan också lägga till en befintlig pipeline i ett paket som redan är källstyrt. Se Migrera befintliga resurser till ett paket.
Så här skapar du en ny källkontrollerad pipeline:
Längst upp i sidofältet klickar du på
 Ny och välj sedan
Ny och välj sedan  ETL-pipeline.
ETL-pipeline.Gör ändringar som du vill göra i pipelinenamnet eller schemat. Se Skapa en ny ETL-pipeline.
Klicka på
 (till höger om
(till höger om  Använd exempelkodknappen ) och välj
Använd exempelkodknappen ) och välj  Konfigureras som källkontrollerad.
Konfigureras som källkontrollerad.Klicka på Skapa nytt projekt och välj sedan en Git-mapp där du vill placera koden och konfigurationen:
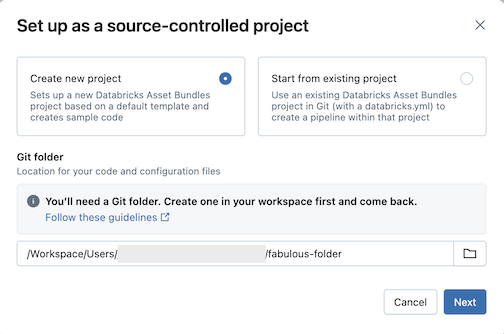
Klicka på Nästa.
Ange följande i dialogrutan Skapa ett tillgångspaket :
- Paketnamn: Namnet på paketet.
- Ursprunglig katalog: Namnet på katalogen som innehåller det schema som ska användas.
- Använd ett personligt schema: Låt den här rutan vara markerad om du vill isolera ändringar i ett personligt schema, så att när användare i din organisation samarbetar i samma projekt skriver du inte över varandras ändringar i dev.
- Ursprungligt språk: Det första språket som ska användas för projektets exempelpipelinefiler, antingen Python eller SQL.
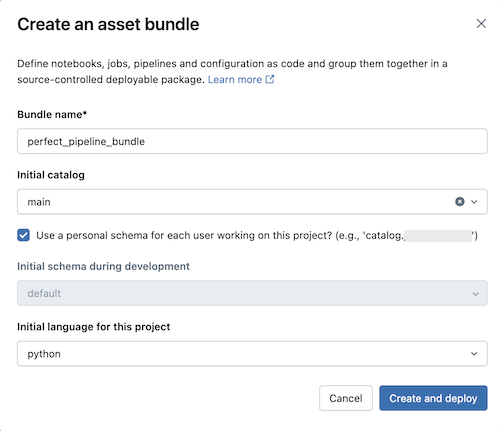
Klicka på Skapa och distribuera. Ett paket med en pipeline skapas i Git-mappen.
Utforska pipelinpaketet
Utforska sedan pipelinepaketet som skapades.
Paketet, som finns i Git-mappen, innehåller paketsystemfiler och databricks.yml filen, som definierar variabler, url:er och behörigheter för målarbetsytan och andra inställningar för paketet. Eftersom databricks.yml finns i paketets rot (den överordnade nivån till pipelineroten) växlar du till fliken Alla filer i resursbläddraren för pipelinen för att se den. Mappen resources i en bundle innehåller definitionerna av resurser, till exempel pipelines och jobb.
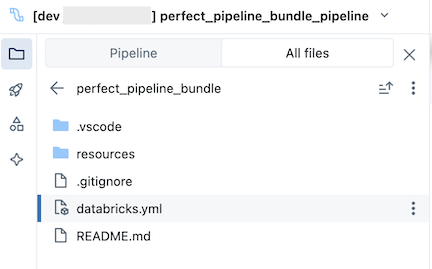
resources Öppna mappen och klicka sedan på pipelineredigeraren för att visa den källkontrollerade pipelinen:
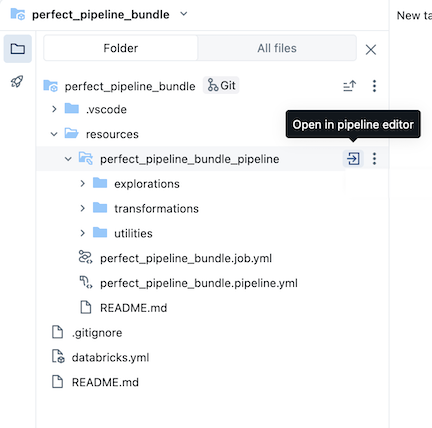
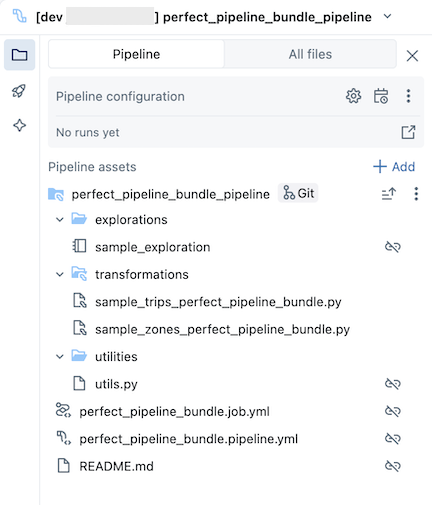
Exempelpaketet för pipeline innehåller följande filer:
En exempelutforskningsanteckningsbok
Två exempelkodfiler som utför transformeringar i tabeller
En exempelkodfil som innehåller en verktygsfunktion
En YAML-fil för jobbkonfiguration som definierar jobbet i paketet som kör pipelinen
En YAML-fil för pipelinekonfiguration som definierar pipelinen
Viktigt!
Du måste redigera den här filen för att permanent spara eventuella konfigurationsändringar i pipelinen, inklusive ändringar som görs via användargränssnittet, annars åsidosätts ändringar i användargränssnittet när paketet distribueras om. Om du till exempel vill ange en annan standardkatalog för pipelinen redigerar du fältet
catalogi den här konfigurationsfilen.En README-fil med ytterligare information om exempelpipelinepaketet och instruktioner om hur du kör pipelinen
Mer information om pipeline-filer finns i resurswebbläsaren för pipeline.
Mer information om hur du redigerar och distribuerar ändringar i pipelinepaketet finns i Skapa paket på arbetsytan och Distribuera paket och kör arbetsflöden från arbetsytan.
Kör pipelinen
Du kan köra antingen enskilda transformeringar eller hela den källkontrollerade pipelinen:
- Om du vill köra och förhandsgranska en enskild transformering i pipelinen väljer du transformeringsfilen i arbetsytans webbläsarträd för att öppna den i filredigeraren. Längst upp i filen i redigeraren klickar du på knappen Kör filspel .
- Om du vill köra alla transformeringar i pipelinen klickar du på knappen Kör pipeline uppe till höger på Databricks-arbetsytan.
Mer information om hur du kör pipelines finns i Köra pipelinekod.
Uppdatera arbetsflödet
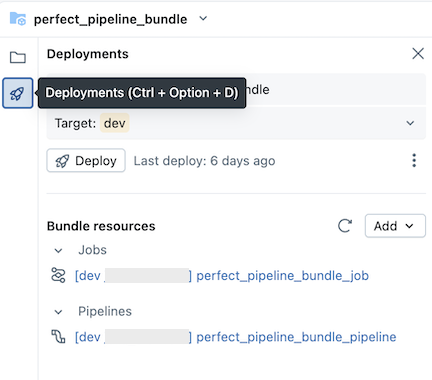
Du kan uppdatera artefakter i din pipeline eller lägga till ytterligare utforskningar och transformeringar, men sedan vill du skicka ändringarna till GitHub. Klicka på ![]() Git-ikonen som är associerad med pipelinepaketet eller klicka på kebaben för mappen och sedan Git... för att välja vilka ändringar som ska skickas. Se Begå och skicka ändringar.
Git-ikonen som är associerad med pipelinepaketet eller klicka på kebaben för mappen och sedan Git... för att välja vilka ändringar som ska skickas. Se Begå och skicka ändringar.
När du uppdaterar pipelinekonfigurationsfiler eller lägger till eller tar bort filer från paketet sprids inte ändringarna till målarbetsytan förrän du uttryckligen distribuerar paketet. Se Distribuera paket och köra arbetsflöden från arbetsytan.
Anmärkning
Databricks rekommenderar att du behåller standardinställningen för källkontrollerade pipelines. Standardkonfigurationen är konfigurerad så att du inte behöver redigera YAML-konfigurationen för pipelinepaketet när ytterligare filer läggs till via användargränssnittet.
Lägga till en befintlig pipeline i ett paket
Om du vill lägga till en befintlig pipeline i ett paket skapar du först ett paket på arbetsytan och lägger sedan till YAML-definitionen för pipelinen i paketet enligt beskrivningen på följande sidor:
- Självstudie: Skapa och distribuera ett paket på arbetsytan
- Lägga till en befintlig resurs i ett paket
Information om hur du migrerar resurser till ett paket med databricks CLI finns i Migrera befintliga resurser till ett paket.
Ytterligare resurser
Mer handledningar och referensmaterial om pipelines finns i Spark Declarative Pipelines.