Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
En strömningstabell är en Delta-tabell med ytterligare stöd för direktuppspelning eller inkrementell databearbetning. En strömningstabell kan riktas mot ett eller flera flöden i en pipeline.
Strömmande tabeller är ett bra val för datainmatning av följande skäl:
- Varje indatarad hanteras bara en gång, vilket modellerar de allra flesta inmatningsarbetsbelastningar (dvs. genom att lägga till eller utöka rader till en tabell).
- De kan hantera stora mängder data som endast kan läggas till.
Direktuppspelningstabeller är också ett bra alternativ för strömningstransformeringar med låg latens eftersom de kan resonera över rader och tidsperioder, hantera stora mängder data och tillhandahålla bearbetning med låg latens.
Följande diagram visar hur flöden läser från strömmande källor och skriver inkrementellt till en strömmande tabell inom en pipeline.
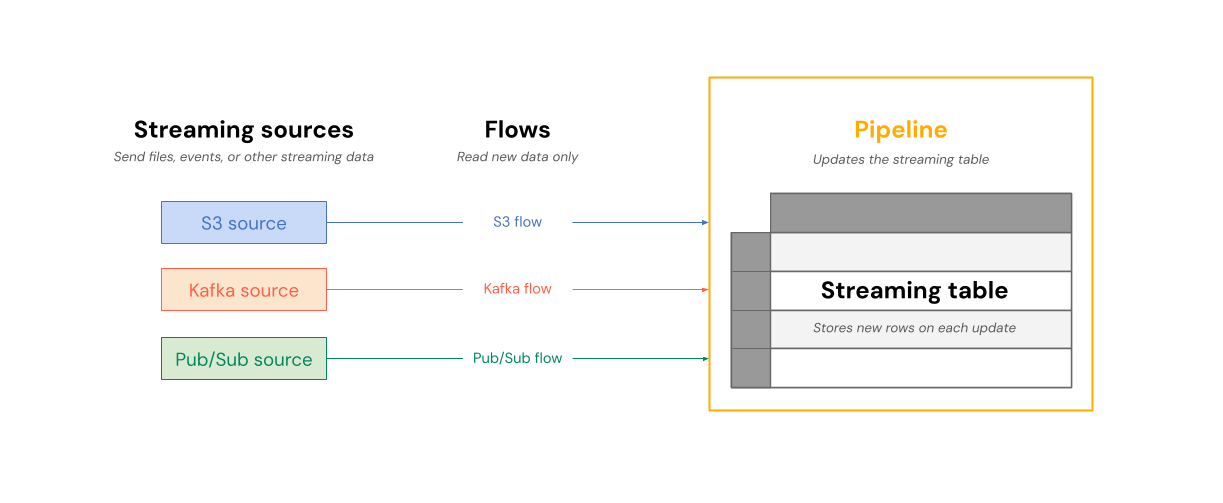
Vid varje uppdatering läser de flöden som är associerade med en strömningstabell den ändrade informationen i en strömmande källa och lägger till ny information i tabellen.
Strömmande tabeller ägs och uppdateras av en enda pipeline. Du definierar explicit strömmande tabeller i pipelinens källkod. Tabeller som definieras av en pipeline kan inte ändras eller uppdateras av någon annan pipeline. Du kan definiera flera flöden för att lägga till i en enda direktuppspelningstabell.
Azure Databricks skapar interna tabeller som stöder bearbetning av strömningstabeller. Dessa tabeller visas i system.information_schema.tables men visas inte i Katalogutforskaren eller andra arbetsytegränssnittssidor.
Anmärkning
När du skapar en strömmande tabell utanför en pipeline med Databricks SQL skapar Azure Databricks en pipeline som används för att uppdatera tabellen. Du kan se pipelinen genom att välja ETL. Strömmande tabeller som skapats i Databricks SQL har en typ av MV/ST.
Mer information om flöden finns i Läsa in och bearbeta data stegvis med Lakeflow Spark deklarativa pipelines-flöden.
Strömmande tabeller för inmatning
Strömmande tabeller är utformade för datakällor där data endast läggs till och bearbetar indatan endast en gång. Detta gör dem väl lämpade för inmatningsarbetsbelastningar där data anländer kontinuerligt och måste samlas in på ett tillförlitligt sätt utan att befintliga poster bearbetas på nytt. Azure Databricks stöder inmatning av data från molnlagring och strömning av meddelandebussar.
Mata in filer från molnlagring
Du kan använda en strömningstabell för att mata in nya filer från molnlagring. De här exemplen använder Auto Loader för att stegvis bearbeta nya filer när de tas emot.
python
from pyspark import pipelines as dp
# Create a streaming table
@dp.table
def customers_bronze():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.option("cloudFiles.inferColumnTypes", "true")
.load("/Volumes/path/to/files")
)
Om du vill skapa en strömningstabell måste datauppsättningsdefinitionen vara en strömtyp. När du använder spark.readStream funktionen i en datauppsättningsdefinition returneras en strömmande datauppsättning.
SQL
-- Create a streaming table
CREATE OR REFRESH STREAMING TABLE customers_bronze
AS SELECT * FROM STREAM read_files(
"/volumes/path/to/files",
format => "json"
);
Strömmande tabeller kräver strömmande datauppsättningar. Nyckelordet STREAM innan read_files instruerar frågan att behandla datauppsättningen som en dataström.
Mata in strömmande meddelanden
Du kan också använda strömmande tabeller för att mata in data från meddelandebussar. I följande exempel visas hur du skapar en strömningstabell som läser från ett Pub/Sub-ämne.
python
@dp.table
def pubsub_raw():
auth_options = {
"clientId": client_id,
"clientEmail": client_email,
"privateKey": private_key,
"privateKeyId": private_key_id
}
return (
spark.readStream
.format("pubsub")
.option("subscriptionId", "my-subscription")
.option("topicId", "my-topic")
.option("projectId", "my-project")
.options(auth_options)
.load()
)
SQL
CREATE OR REFRESH STREAMING TABLE pubsub_raw
AS SELECT * FROM STREAM read_pubsub(
subscriptionId => 'my-subscription',
projectId => 'my-project',
topicId => 'my-topic',
clientEmail => secret('pubsub-scope', 'clientEmail'),
clientId => secret('pubsub-scope', 'clientId'),
privateKeyId => secret('pubsub-scope', 'privateKeyId'),
privateKey => secret('pubsub-scope', 'privateKey')
);
Databricks rekommenderar att du använder hemligheter när du tillhandahåller auktoriseringsalternativ. Se Konfigurera åtkomst till Pub/Sub för alla autentiseringsalternativ.
För mer information om hur du laddar data i en streamingtabell, se Ladda data i pipelines.
Följande diagram visar hur strömmande tabeller som enbart tillåter tillägg fungerar.

En rad som redan har lagts till i en strömningstabell efterfrågas inte igen med senare uppdateringar av pipelinen. Om du ändrar frågan (till exempel från SELECT LOWER (name) till SELECT UPPER (name)) uppdateras inte befintliga rader till versaler, men nya rader kommer att vara versaler. Du kan utlösa en fullständig uppdatering för att hämta alla tidigare data från källtabellen för att uppdatera alla rader i tabellen Direktuppspelning.
Strömningstabeller och strömning med låg fördröjning
Strömningstabeller är utformade för strömning med låg latens över begränsat tillstånd. Strömningstabeller använder kontrollpunktshantering, vilket gör dem väl lämpade för strömning med låg fördröjning. De förväntar sig dock strömmar som är naturligt avgränsade eller avgränsade med en vattenstämpel.
En naturligt avgränsad dataström skapas av en strömmande datakälla som har en väldefinierad start och slut. Ett exempel på en naturligt avgränsad dataström är att läsa data från en katalog med filer där inga nya filer läggs till efter att en första batch med filer har placerats. Dataströmmen anses vara begränsad eftersom antalet filer är begränsat och strömmen avslutas när alla filer har bearbetats.
Du kan också använda en vattenstämpel för att begränsa en datastream. En vattenstämpel i Structured Streaming är en mekanism som hjälper till att hantera sena data genom att ange hur länge systemet ska vänta på fördröjda händelser innan tidsfönstret betraktas som slutfört. En obunden ström som inte har en vattenstämpel kan orsaka att en pipeline misslyckas på grund av minnesbelastning.
Mer information om tillståndskänslig dataströmbearbetning finns i Optimera tillståndskänslig bearbetning med vattenstämplar.
Strömögonblicksbildanslutningar
Ström-ögonblicksbild-anslutningar kopplar en strömmande datauppsättning till en dimensionstabell, av vilken en ögonblicksbild tas vid strömstarten. Eftersom dimensionstabellen behandlas som fast vid den tidpunkten återspeglas inte eventuella ändringar som görs i den när strömmen startar i kopplingen. Detta är acceptabelt när små avvikelser inte spelar någon roll , till exempel när antalet transaktioner är många storleksordningar större än antalet kunder.
Följande kodexempel kopplar ihop en dimensionstabell med två rader som anropas customers med en ständigt ökande datauppsättning, transactions. Den materialiserar en koppling mellan dessa två datauppsättningar i en tabell med namnet sales_report. Om en extern process uppdaterar kundtabellen genom att lägga till en ny rad (customer_id=3, name=Zoya) kommer den nya raden inte att finnas i kopplingen eftersom den statiska dimensionstabellen ögonblicksbilderades när strömmar startades.
from pyspark import pipelines as dp
@dp.temporary_view
# assume this table contains an append-only stream of rows about transactions
# (customer_id=1, value=100)
# (customer_id=2, value=150)
# (customer_id=3, value=299)
# ... <and so on> ...
def v_transactions():
return spark.readStream.table("transactions")
# assume this table contains only these two rows about customers
# (customer_id=1, name=Bilal)
# (customer_id=2, name=Olga)
@dp.temporary_view
def v_customers():
return spark.read.table("customers")
@dp.table
def sales_report():
facts = spark.readStream.table("v_transactions")
dims = spark.read.table("v_customers")
return facts.join(dims, on="customer_id", how="inner")
Begränsningar för strömmande tabeller
Strömmande tabeller har följande begränsningar:
-
Begränsad utveckling: Du kan ändra frågan utan att omberäkna hela datauppsättningen. Utan en fullständig uppdatering ser en strömmande tabell bara varje rad en gång, så olika frågeställningar har bearbetat olika rader. Om du till exempel lägger till
UPPER()i ett fält i frågan kommer endast rader som bearbetas efter ändringen att vara i versaler. Det innebär att du måste vara medveten om alla tidigare versioner av frågan som körs på din datauppsättning. För att bearbeta befintliga rader som bearbetades före ändringen krävs en fullständig uppdatering. - Tillståndshantering: Strömmande tabeller har låg svarstid och kräver strömmar som är naturligt avgränsade eller avgränsade med en vattenstämpel. Mer information finns i Optimera tillståndskänslig bearbetning med vattenstämplar.
- Kopplingar beräknas inte om: Kopplingar i strömmande tabeller beräknas inte om när dimensionerna ändras. Den här egenskapen kan vara bra för "snabba men fel"-scenarier. Om du vill att vyn alltid ska vara korrekt kanske du vill använda en materialiserad vy. Materialiserade vyer är alltid korrekta eftersom de automatiskt omkomplerar kopplingar när dimensionerna ändras. Mer information finns i Materialiserade vyer.