Beräkningsfunktioner på begäran med hjälp av användardefinierade Python-funktioner
Den här artikeln beskriver hur du skapar och använder funktioner på begäran i Azure Databricks.
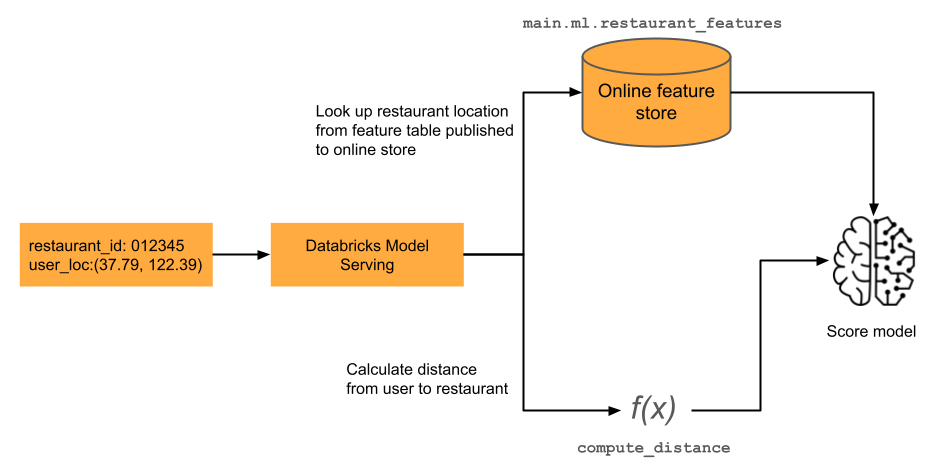
Maskininlärningsmodeller för realtidsprogram kräver ofta de senaste funktionsvärdena. I exemplet som visas i diagrammet är en funktion för en restaurangrekommendationsmodell användarens aktuella avstånd från en restaurang. Den här funktionen måste beräknas "på begäran", d.v.s. vid tidpunkten för bedömningsbegäran. När en bedömningsbegäran tas emot söker modellen upp restaurangens plats och tillämpar sedan en fördefinierad funktion för att beräkna avståndet mellan användarens aktuella plats och restaurangen. Det avståndet skickas som indata till modellen, tillsammans med andra förberäknade funktioner från funktionsarkivet.
Om du vill använda funktioner på begäran måste arbetsytan vara aktiverad för Unity Catalog och du måste använda Databricks Runtime 13.3 LTS ML eller senare.
Vad är funktioner på begäran?
"På begäran" avser funktioner vars värden inte är kända i förväg, men som beräknas vid tidpunkten för slutsatsdragningen. I Azure Databricks använder du användardefinierade Python-funktioner (UDF: er) för att ange hur du beräknar funktioner på begäran. Dessa funktioner styrs av Unity Catalog och kan identifieras via Katalogutforskaren.
Arbetsflöde
För att beräkna funktioner på begäran anger du en Användardefinierad Python-funktion (UDF) som beskriver hur du beräknar funktionsvärdena.
- Under träningen anger du den här funktionen och dess indatabindningar i parametern
feature_lookupsför API:etcreate_training_set. - Du måste logga den tränade modellen med hjälp av metoden
log_modelFeature Store . Detta säkerställer att modellen automatiskt utvärderar funktioner på begäran när den används för slutsatsdragning. - För batchbedömning beräknar och returnerar API:et
score_batchautomatiskt alla funktionsvärden, inklusive funktioner på begäran. - När du hanterar en modell med Databricks Model Serving använder modellen automatiskt Python UDF för att beräkna funktioner på begäran för varje bedömningsbegäran.
Skapa en Python UDF
Du kan skapa en Python UDF i en notebook-fil eller i Databricks SQL.
Om du till exempel kör följande kod i en notebook-cell skapas Python UDF example_feature i katalogen main och schemat default.
%sql
CREATE FUNCTION main.default.example_feature(x INT, y INT)
RETURNS INT
LANGUAGE PYTHON
COMMENT 'add two numbers'
AS $$
def add_numbers(n1: int, n2: int) -> int:
return n1 + n2
return add_numbers(x, y)
$$
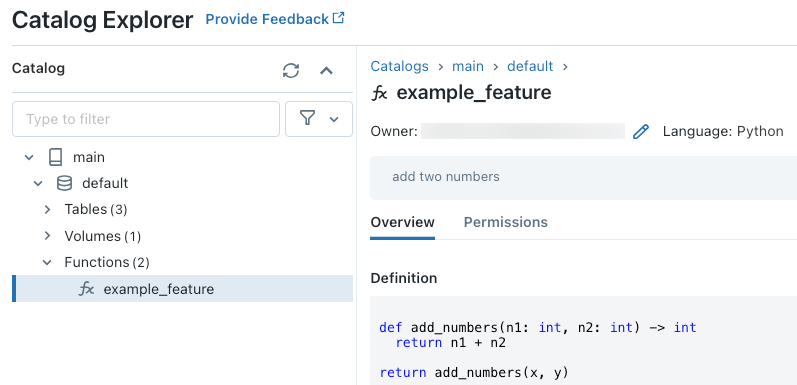
När du har kört koden kan du navigera genom namnområdet på tre nivåer i Katalogutforskaren för att visa funktionsdefinitionen:
Mer information om hur du skapar Python-UDF:er finns i Registrera en Python UDF till Unity Catalog och SQL-språkhandboken.
Hantera saknade funktionsvärden
När en Python UDF är beroende av resultatet av en FeatureLookup beror värdet som returneras om den begärda uppslagsnyckeln inte hittas på miljön. När du använder score_batchär Nonevärdet som returneras . När du använder onlineservering är float("nan")värdet som returneras .
Följande kod är ett exempel på hur du hanterar båda fallen.
%sql
CREATE OR REPLACE FUNCTION square(x INT)
RETURNS INT
LANGUAGE PYTHON AS
$$
import numpy as np
if x is None or np.isnan(x):
return 0
return x * x
$$
Träna en modell med hjälp av funktioner på begäran
Om du vill träna modellen använder du en FeatureFunction, som skickas till API:et create_training_set i parametern feature_lookups .
I följande exempelkod används Python UDF main.default.example_feature som definierades i föregående avsnitt.
# Install databricks-feature-engineering first with:
# %pip install databricks-feature-engineering
# dbutils.library.restartPython()
from databricks.feature_engineering import FeatureEngineeringClient
from databricks.feature_engineering import FeatureFunction, FeatureLookup
from sklearn import linear_model
fe = FeatureEngineeringClient()
features = [
# The feature 'on_demand_feature' is computed as the sum of the the input value 'new_source_input'
# and the pre-materialized feature 'materialized_feature_value'.
# - 'new_source_input' must be included in base_df and also provided at inference time.
# - For batch inference, it must be included in the DataFrame passed to 'FeatureEngineeringClient.score_batch'.
# - For real-time inference, it must be included in the request.
# - 'materialized_feature_value' is looked up from a feature table.
FeatureFunction(
udf_name="main.default.example_feature", # UDF must be in Unity Catalog so uses a three-level namespace
input_bindings={
"x": "new_source_input",
"y": "materialized_feature_value"
},
output_name="on_demand_feature",
),
# retrieve the prematerialized feature
FeatureLookup(
table_name = 'main.default.table',
feature_names = ['materialized_feature_value'],
lookup_key = 'id'
)
]
# base_df includes the columns 'id', 'new_source_input', and 'label'
training_set = fe.create_training_set(
df=base_df,
feature_lookups=features,
label='label',
exclude_columns=['id', 'new_source_input', 'materialized_feature_value'] # drop the columns not used for training
)
# The training set contains the columns 'on_demand_feature' and 'label'.
training_df = training_set.load_df().toPandas()
# training_df columns ['materialized_feature_value', 'label']
X_train = training_df.drop(['label'], axis=1)
y_train = training_df.label
model = linear_model.LinearRegression().fit(X_train, y_train)
Logga modellen och registrera den i Unity Catalog
Modeller som paketeras med funktionsmetadata kan registreras i Unity Catalog. De funktionstabeller som används för att skapa modellen måste lagras i Unity Catalog.
För att säkerställa att modellen automatiskt utvärderar funktioner på begäran när den används för slutsatsdragning måste du ange register-URI:n och sedan logga modellen enligt följande:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="main.default.model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model"
)
Om Python UDF som definierar funktionerna på begäran importerar alla Python-paket måste du ange dessa paket med argumentet extra_pip_requirements. Till exempel:
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.log_model(
model=model,
artifact_path="model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name="main.default.recommender_model",
extra_pip_requirements=["scikit-learn==1.20.3"]
)
Begränsning
Funktioner på begäran kan mata ut alla datatyper som stöds av Funktionsarkiv förutom MapType och ArrayType.
Notebook-exempel: Funktioner på begäran
Följande notebook-fil visar ett exempel på hur du tränar och poängsätter en modell som använder en funktion på begäran.
Demo notebook-fil för grundläggande funktioner på begäran
Följande notebook-fil visar ett exempel på en modell för restaurangrekommendationer. Restaurangens läge är uppsökt från en Databricks online-tabell. Användarens aktuella plats skickas som en del av bedömningsbegäran. Modellen använder en funktion på begäran för att beräkna realtidsavståndet från användaren till restaurangen. Avståndet används sedan som indata till modellen.
Restaurangrekommendationsfunktioner på begäran med demoanteckningsbok för onlinetabeller
Följande notebook-fil visar samma modell för restaurangrekommendationer med hjälp av en onlinebutik från tredje part. Restaurangens plats är uppslagen från en förmaterialiserad funktionstabell publicerad till CosmosDB.