Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
TensorBoard är en uppsättning visualiseringsverktyg för felsökning, optimering och förståelse av TensorFlow, PyTorch, Hugging Face Transformers och andra maskininlärningsprogram.
Använd TensorBoard
Att starta TensorBoard i Azure Databricks skiljer sig inte från att starta det på en Jupyter-anteckningsbok på den lokala datorn.
Läs in det
%tensorboardmagiska kommandot och definiera loggkatalogen.%load_ext tensorboard experiment_log_dir = <log-directory>Anropa det
%tensorboardmagiska kommandot.%tensorboard --logdir $experiment_log_dirTensorBoard-servern startar och visar användargränssnittet i en inbäddad vy i anteckningsboken. Den innehåller också en länk för att öppna TensorBoard på en ny flik.
Följande skärmbild visar tensorboard-användargränssnittet som startats i en ifylld loggkatalog.
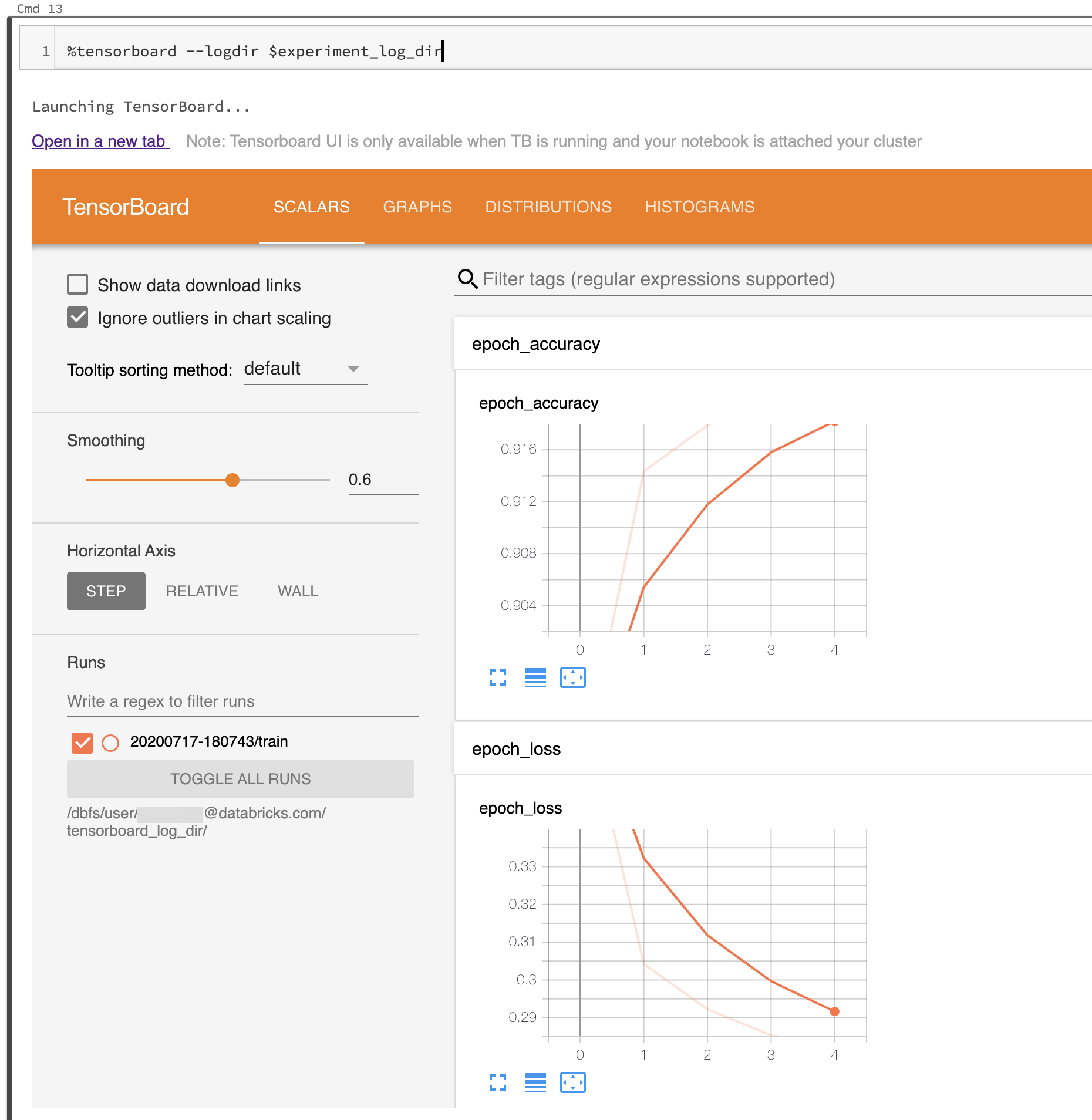
Du kan också starta TensorBoard med hjälp av TensorBoards notebook-modul direkt.
from tensorboard import notebook
notebook.start("--logdir {}".format(experiment_log_dir))
TensorBoard-loggar och -kataloger
TensorBoard visualiserar dina maskininlärningsprogram genom att läsa loggar som genereras av TensorBoard-återanrop och funktioner i TensorBoard eller PyTorch. Om du vill generera loggar för andra maskininlärningsbibliotek kan du skriva loggar direkt med TensorFlow-filskrivare (se Modul: tf.summary för TensorFlow 2.x och se Modul: tf.compat.v1.summary för det äldre API:et i TensorFlow 1.x ).
För att säkerställa att experimentloggarna lagras på ett tillförlitligt sätt rekommenderar Databricks att du skriver loggar till molnlagring i stället för på det tillfälliga klusterfilsystemet. Starta TensorBoard i en unik katalog för varje experiment. För varje körning av maskininlärningskoden i experimentet som genererar loggar ställer du in TensorBoard-återanropet eller filskrivaren för att skriva till en underkatalog till experimentkatalogen. På så sätt separeras data i TensorBoard-användargränssnittet i körningar.
Läs den officiella TensorBoard-dokumentationen för att komma igång med TensorBoard för att logga information för ditt maskininlärningsprogram.
Hantera TensorBoard-processer
TensorBoard-processerna som startas i Azure Databricks notebook avslutas inte när notebook kopplas bort eller när REPL startas om (till exempel när du rensar notebookens status). Om du vill avsluta en TensorBoard-process manuellt skickar du en avslutningssignal med .%sh kill -15 pid TensorBoard-processer som felaktigt har dödats kan skada notebook.list().
Om du vill visa en lista över TensorBoard-servrarna som för närvarande körs i klustret, med motsvarande loggkataloger och process-ID:n, kör notebook.list() du från modulen TensorBoard Notebook.
Kända problem
- Det infogade TensorBoard-användargränssnittet finns i en iframe. Webbläsarsäkerhetsfunktioner förhindrar att externa länkar i användargränssnittet fungerar om du inte öppnar länken på en ny flik.
-
--window_title-alternativet i TensorBoard åsidosätts på Azure Databricks. - Som standard söker TensorBoard igenom ett portintervall för att välja en port att lyssna på. Om det finns för många TensorBoard-processer som körs i klustret kan alla portar i portintervallet vara otillgängliga. Du kan kringgå den här begränsningen genom att ange ett portnummer med
--portargumentet . Den angivna porten ska vara mellan 6006 och 6106. - För att nedladdningslänkar ska fungera måste du öppna TensorBoard på en flik.
- När du använder TensorBoard 1.15.0 är fliken Projektor tom. Om du vill besöka projektorsidan direkt kan du ersätta
#projectori URL:endata/plugin/projector/projector_binary.htmlmed . - TensorBoard 2.4.0 har ett känt problem som kan påverka TensorBoard-återgivning om det uppgraderas.
- Om du loggar TensorBoard-relaterade data till DBFS- eller UC-volymer kan du få ett fel som
No dashboards are active for the current data set. För att lösa det här felet rekommenderar vi att du anroparwriter.flush()ochwriter.close()efter att du har använtwriterför att logga data. Detta säkerställer att alla loggade data skrivs korrekt och är tillgängliga för TensorBoard att rendera.