Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här artikeln hjälper dig att komma igång med MLflow 3. Den beskriver hur du installerar MLflow 3 och innehåller flera demo notebook-filer för att komma igång. Den innehåller även länkar till sidor som beskriver de nya funktionerna i MLflow 3 i detalj.
Vad är MLflow 3 och hur skiljer det sig från den befintliga MLflow-versionen?
MLflow 3 på Azure Databricks levererar toppmodern experimentspårning, observerbarhet och prestandautvärdering för maskininlärningsmodeller, generativa AI-program och agenter i Databricks lakehouse. MLflow 3 introducerar betydande nya funktioner samtidigt som grundläggande spårningsbegrepp bevaras, vilket gör migreringen från 2.x snabb och enkel. Med MLflow 3 på Azure Databricks kan du:
- Spåra och analysera prestanda för dina modeller, AI-program och agenter centralt i alla miljöer, från interaktiva frågor i en utvecklingsanteckningsbok via produktionsbatch- eller realtidsdistributioner.
![]()
- Visa och komma åt modellmått och parametrar från modellversionssidan i Unity Catalog och från REST-API:et över alla arbetsytor och experiment.
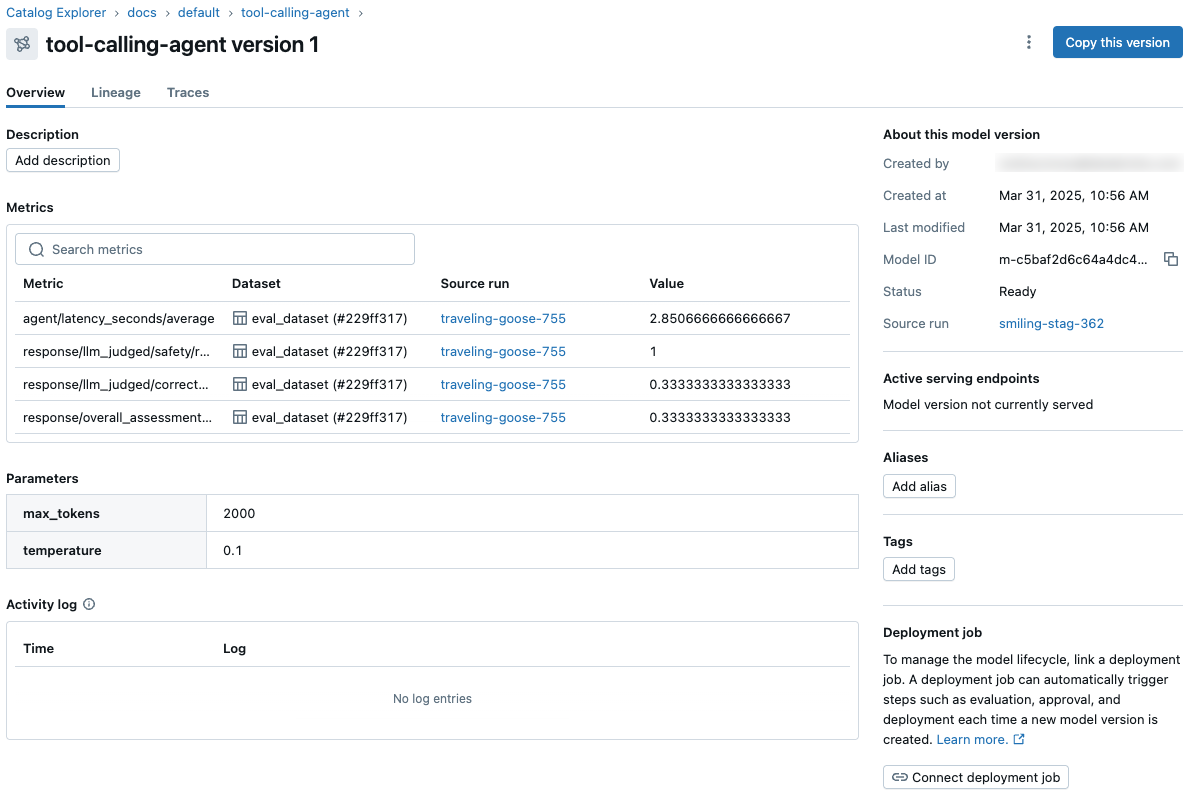
- Kommentera förfrågningar och svar (spårningar) för omfattande observerbarhet från slutpunkt till slutpunkt för alla dina gen-AI-program och agenter, vilket gör det möjligt för mänskliga experter och automatiserade LLM-as-a-judge-tekniker att ge omfattande feedback. Du kan använda den här feedbacken för att utvärdera och jämföra prestanda för programversioner och skapa datauppsättningar för att förbättra kvaliteten.
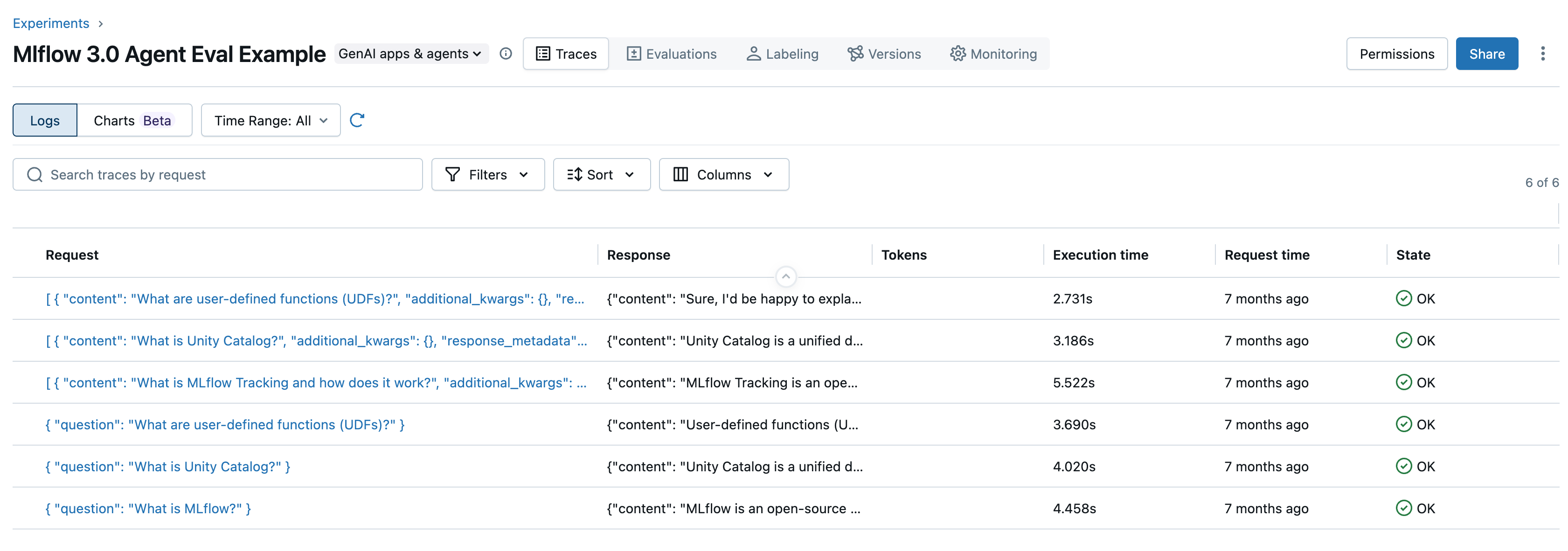
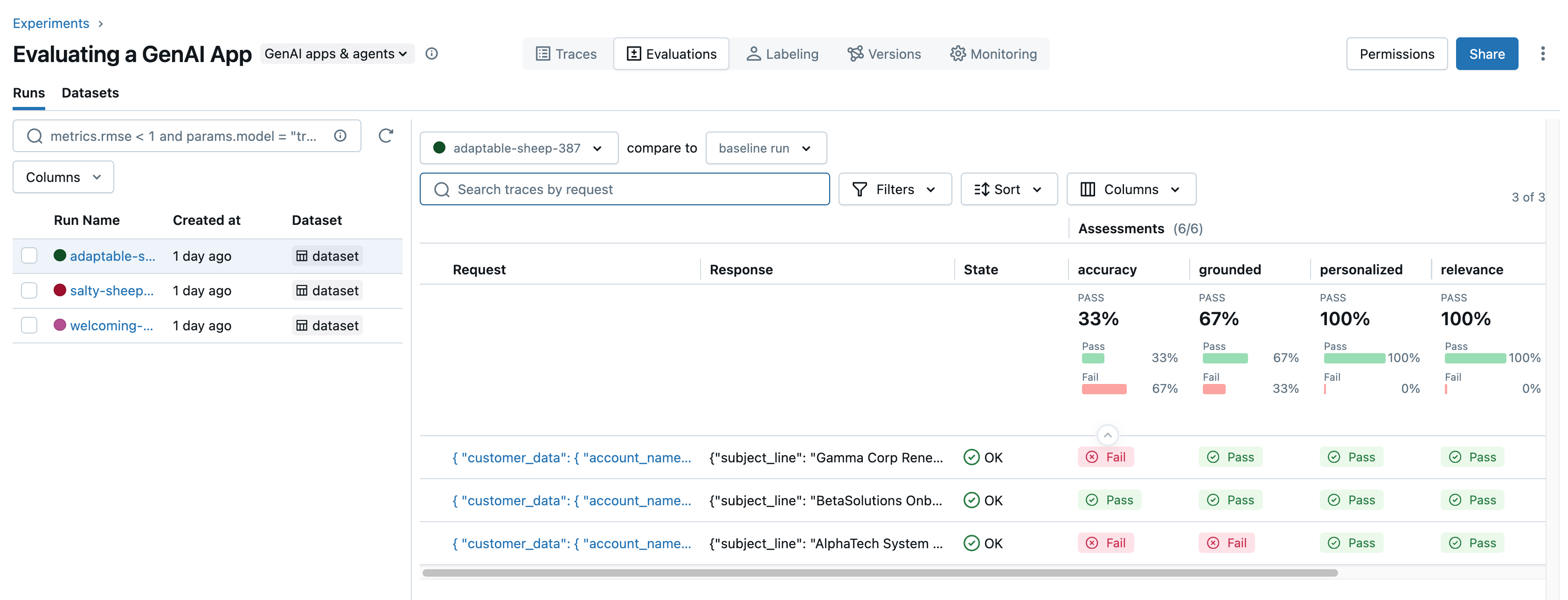
- Utvärdera GenAI-program i stor skala med hjälp av det nya
mlflow.genai.evaluate()API:et med inbyggda och anpassade LLM-domare för korrekthet, relevans, säkerhet med mera, och utvärdera kvaliteten på dina GenAI-program under utveckling och produktion.
- Samordna utvärderings- och distributionsarbetsflöden med hjälp av Unity Catalog och få åtkomst till omfattande statusloggar för varje version av din modell, AI-program eller agent.
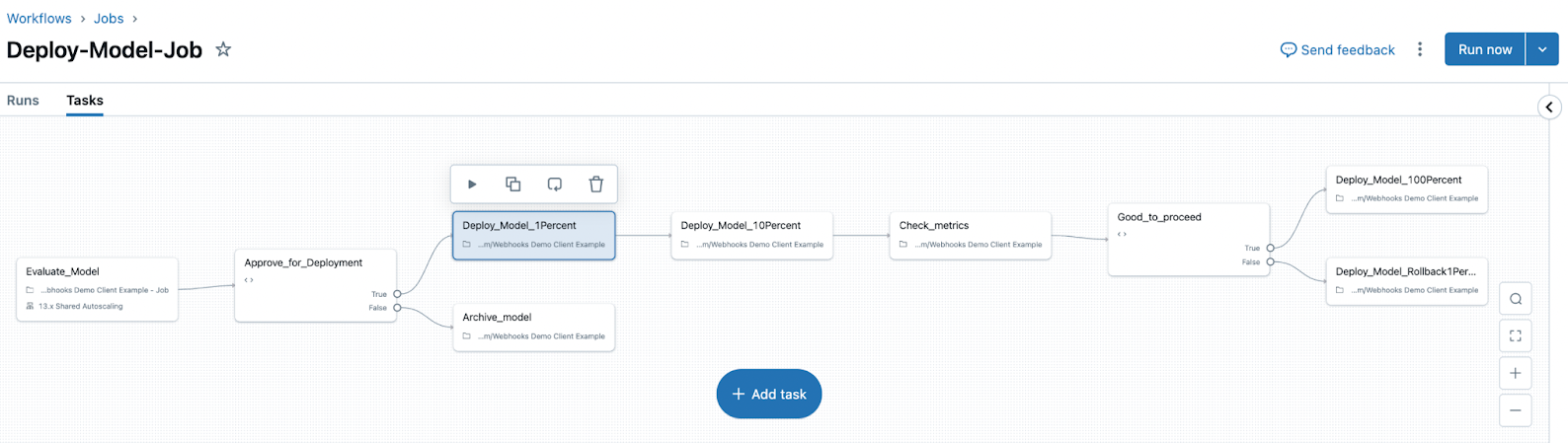
De här funktionerna förenklar och effektiviserar utvärdering, distribution, felsökning och övervakning för alla dina AI-initiativ.
GenAI-observerbarhet och utvärdering
MLflow 3 introducerar omfattande GenAI-funktioner som kombinerar spårningsobservabilitet och AI-baserade verktyg för att på ett tillförlitligt sätt mäta GenAI-kvalitet, så att du kan övervaka och förbättra kvaliteten på dina program under hela livscykeln. Du kan nu använda MLflow Experiment UI för realtidsinstrumentpaneler och övervakning av spår från produktionsanvändningar, oavsett om de är distribuerade på Databricks eller externt, och annotering av produktionsspår med feedback samt skapa datauppsättningar för framtida iterationer.
MLflow 3 ger förstklassigt stöd för LLM-domare och mänsklig feedback direkt på MLflow Traces med den nya funktionen Utvärderingar. Det nya mlflow.genai.evaluate() API:et erbjuder en enklare och kraftfullare metod för utvärdering och integrering av LLM-domare som drivs av Agent Evaluation i MLflow SDK. Med stöd för både fördefinierade och anpassade bedömningsverktyg kan du vara säker på kvaliteten på dina GenAI-applikationer före lansering. Dessutom är Databricks Agent Evaluation API:er för domare, datauppsättningar och etiketteringssessioner (Granskningsapp) nu enhetliga under mlflow.genai namnområdet för en sömlös upplevelse. Mer information finns i MLflow 3 för GenAI.
Loggade modeller
Mycket av de nya funktionerna i MLflow 3 kommer från det nya konceptet med en LoggedModel. När du utvecklar generativa AI-program eller agenter kan utvecklare skapa LoggedModels för att samla in git-incheckningar eller uppsättningar med parametrar som objekt som kan länkas till spårningar och mått. För djupinlärning och klassiska ML-program LoggedModels höjer begreppet modell som skapats av en träningskörning och etablerar den som ett dedikerat objekt för att spåra modelllivscykeln mellan olika tränings- och utvärderingskörningar.
LoggedModels samla in mått, parametrar och spårningar mellan utvecklingsfaser (träning och utvärdering) och mellan miljöer (utveckling, mellanlagring och produktion). När en LoggedModel höjs upp till Unity Catalog som en modellversion blir alla prestandadata från originalet LoggedModel synliga på sidan UC-modellversion, vilket ger synlighet över alla arbetsytor och experiment. Mer information finns i Spåra och jämföra modeller med MLflow-loggade modeller.
Implementeringsjobb
MLflow 3 introducerar också begreppet distributionsjobb. Distribueringsjobb använder Lakeflow-jobb för att hantera modellens livscykel, däribland steg som utvärdering, godkännande och distribution. Dessa modellarbetsflöden styrs av Unity Catalog och alla händelser sparas i en aktivitetslogg som är tillgänglig på modellversionssidan i Unity Catalog.
Migrera från MLflow 2.x
Även om det finns många nya funktioner i MLflow 3 förblir huvudbegreppen för experiment och körningar, tillsammans med deras metadata, till exempel parametrar, taggar och mått, alla desamma. Migrering från MLflow 2.x till 3.0 är mycket enkel och bör kräva minimala kodändringar i de flesta fall. Det här avsnittet belyser några viktiga skillnader från MLflow 2.x och vad du bör känna till för en sömlös övergång.
Loggningsmodeller
När du loggar modeller i 2.x används parametern artifact_path .
with mlflow.start_run():
mlflow.pyfunc.log_model(
artifact_path="model",
python_model=python_model,
...
)
I MLflow 3 använder du name i stället, vilket gör att modellen senare kan sökas efter namn. Parametern artifact_path stöds fortfarande men har blivit inaktuell. Dessutom kräver MLflow inte längre att en körning är aktiv när man loggar en modell, eftersom modeller har blivit förstklassiga enheter i MLflow 3. Du kan logga en modell direkt utan att först starta en körning.
mlflow.pyfunc.log_model(
name="model",
python_model=python_model,
...
)
Modellartefakter
I MLflow 2.x lagras modellartefakter som körningsartefakter under körningens artefaktsökväg. I MLflow 3 lagras nu modellartefakter på en annan plats, under modellens artefaktsökväg i stället.
# MLflow 2.x
experiments/
└── <experiment_id>/
└── <run_id>/
└── artifacts/
└── ... # model artifacts are stored here
# MLflow 3
experiments/
└── <experiment_id>/
└── models/
└── <model_id>/
└── artifacts/
└── ... # model artifacts are stored here
Vi rekommenderar att du läser in modeller med hjälp av mlflow.<model-flavor>.load_model modell-URI:n som returneras av mlflow.<model-flavor>.log_model för att undvika problem. Den här modell-URI:n är av formatet models:/<model_id> (i stället runs:/<run_id>/<artifact_path> för som i MLflow 2.x) och kan även konstrueras manuellt om endast modell-ID:t är tillgängligt.
Modellregister
I MLflow 3 är standardregister-URI:n nu databricks-uc, vilket innebär att MLflow Model Registry i Unity Catalog används (se Hantera modelllivscykel i Unity Catalog för mer information). Namnen på modeller som registrerats i Unity Catalog är av formatet <catalog>.<schema>.<model>. När du anropar API:er som kräver ett registrerat modellnamn, till exempel mlflow.register_modelanvänds detta fullständiga namn på tre nivåer.
För arbetsytor som har Unity Catalog aktiverat och vars standardkatalog finns i Unity Catalog kan du också använda <model> som namn och standardkatalogen och schemat kommer att härledas (ingen ändring i beteendet från Mlflow 2.x). Om din arbetsyta har Unity Catalog aktiverat, men dess standardkatalog inte är konfigurerad att finnas i Unity Catalog, måste du ange hela det fullständiga namnet med tre nivåer.
Databricks rekommenderar att du använder MLflow Model Registry i Unity Catalog för att hantera livscykeln för dina modeller.
Om du vill fortsätta använda arbetsytans modellregister (äldre) använder du någon av följande metoder för att ange register-URI:n till databricks:
- Använd
mlflow.set_registry_uri("databricks"). - Ange miljövariabeln MLFLOW_REGISTRY_URI.
- Om du vill ange miljövariabeln för register-URI i stor skala kan du använda init-skript. Detta kräver beräkning för alla syften.
Andra viktiga ändringar
- MLflow 3-klienter kan läsa in alla körningar, modeller och spårningar som loggats med MLflow 2.x-klienter. Det omvända är dock inte nödvändigtvis sant, så modeller och spårningar som loggas med MLflow 3-klienter kanske inte kan läsas in med äldre 2.x-klientversioner.
- API:et
mlflow.evaluatehar blivit inaktuellt. För LLMs- eller GenAI-program använder du API:etmlflow.genai.evaluatei stället. För traditionella ML- eller djupinlärningsmodeller användsmlflow.models.evaluatesom upprätthåller fullständig kompatibilitet med det ursprungligamlflow.evaluateAPI:et - Attributet
run_uuidhar tagits bort från objektetRunInfo. Användrun_idi stället i koden.
Installera MLflow 3
Om du vill använda MLflow 3 måste du uppdatera paketet så att det använder rätt version (>= 3.0). Följande kodrader måste köras varje gång en notebook-fil körs:
%pip install mlflow>=3.0 --upgrade
dbutils.library.restartPython()
Exempelanteckningsböcker
Följande sidor illustrerar arbetsflödet för MLflow 3-modellspårning för traditionell ML och djupinlärning. Varje sida innehåller en exempelanteckningsbok.
Nästa steg
Mer information om de nya funktionerna i MLflow 3 finns i följande artiklar: