Köra MLflow-projekt på Azure Databricks
Varning
MLflow Projects stöds inte längre.
Ett MLflow-projekt är ett format för att paketera datavetenskapskod på ett återanvändbart och reproducerbart sätt. MLflow Projects-komponenten innehåller ett API och kommandoradsverktyg för att köra projekt, som också integreras med komponenten Spårning för att automatiskt registrera parametrarna och git-incheckningen av källkoden för reproducerbarhet.
I den här artikeln beskrivs formatet för ett MLflow-projekt och hur du fjärrkör ett MLflow-projekt i Azure Databricks-kluster med hjälp av MLflow CLI, vilket gör det enkelt att skala datavetenskapskoden lodrätt.
MLflow-projektformat
Alla lokala kataloger eller Git-lagringsplatser kan behandlas som ett MLflow-projekt. Följande konventioner definierar ett projekt:
- Projektets namn är namnet på katalogen.
- Programvarumiljön anges i
python_env.yaml, om den finns. Om det inte finns någonpython_env.yamlfil använder MLflow en virtualenv-miljö som endast innehåller Python (specifikt den senaste Python som är tillgänglig för virtualenv) när projektet körs. - Alla
.pyeller.shfiler i projektet kan vara en startpunkt, utan att några parametrar uttryckligen har deklarerats. När du kör ett sådant kommando med en uppsättning parametrar skickar MLflow varje parameter på kommandoraden med hjälp av--key <value>syntax.
Du anger fler alternativ genom att lägga till en MLproject-fil, som är en textfil i YAML-syntaxen. Ett exempel på en MLproject-fil ser ut så här:
name: My Project
python_env: python_env.yaml
entry_points:
main:
parameters:
data_file: path
regularization: {type: float, default: 0.1}
command: "python train.py -r {regularization} {data_file}"
validate:
parameters:
data_file: path
command: "python validate.py {data_file}"
För Databricks Runtime 13.0 ML och senare kan MLflow Projects inte köras i ett Databricks-jobbtypskluster. Information om hur du migrerar befintliga MLflow-projekt till Databricks Runtime 13.0 ML och senare finns i MLflow Databricks Spark-jobbprojektformat.
MLflow Databricks Spark-jobbprojektformat
MLflow Databricks Spark-jobbprojektet är en typ av MLflow-projekt som introducerades i MLflow 2.14. Den här projekttypen stöder körning av MLflow-projekt inifrån ett Spark-jobbkluster och kan bara köras med hjälp av databricks serverdelen.
Databricks Spark-jobbprojekt måste ange antingen databricks_spark_job.python_file eller entry_points. Att inte ange någon av inställningarna eller att ange båda inställningarna ger upphov till ett undantag.
Följande är ett exempel på en MLproject fil som använder inställningen databricks_spark_job.python_file . Den här inställningen innebär att du använder en hårdkodad sökväg för Python-körningsfilen och dess argument.
name: My Databricks Spark job project 1
databricks_spark_job:
python_file: "train.py" # the file which is the entry point file to execute
parameters: ["param1", "param2"] # a list of parameter strings
python_libraries: # dependencies required by this project
- mlflow==2.4.1 # MLflow dependency is required
- scikit-learn
Följande är ett exempel på en MLproject fil som använder inställningen entry_points :
name: My Databricks Spark job project 2
databricks_spark_job:
python_libraries: # dependencies to be installed as databricks cluster libraries
- mlflow==2.4.1
- scikit-learn
entry_points:
main:
parameters:
model_name: {type: string, default: model}
script_name: {type: string, default: train.py}
command: "python {script_name} {model_name}"
Med entry_points inställningen kan du skicka in parametrar som använder kommandoradsparametrar, till exempel:
mlflow run . -b databricks --backend-config cluster-spec.json \
-P script_name=train.py -P model_name=model123 \
--experiment-id <experiment-id>
Följande begränsningar gäller för Databricks Spark-jobbprojekt:
- Den här projekttypen har inte stöd för att ange följande avsnitt i
MLprojectfilen:docker_env,python_env, ellerconda_env. - Beroenden för projektet måste anges i fältet i
python_librariesdatabricks_spark_jobavsnittet. Versioner av Python kan inte anpassas med den här projekttypen. - Körningsmiljön måste använda spark-drivrutinskörningsmiljön för att köras i jobbkluster som använder Databricks Runtime 13.0 eller senare.
- På samma sätt måste alla Python-beroenden som definieras som nödvändiga för projektet installeras som Databricks-klusterberoenden. Det här beteendet skiljer sig från tidigare projektkörningsbeteenden där bibliotek behövde installeras i en separat miljö.
Köra ett MLflow-projekt
Om du vill köra ett MLflow-projekt på ett Azure Databricks-kluster på standardarbetsytan använder du kommandot:
mlflow run <uri> -b databricks --backend-config <json-new-cluster-spec>
där <uri> är en Git-lagringsplats-URI eller mapp som innehåller ett MLflow-projekt och <json-new-cluster-spec> är ett JSON-dokument som innehåller en new_cluster struktur. Git-URI:n ska vara av formatet: https://github.com/<repo>#<project-folder>.
Ett exempel på klusterspecifikation är:
{
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
}
Om du behöver installera bibliotek på arbetaren använder du formatet "klusterspecifikation". Observera att Python-hjulfiler måste laddas upp till DBFS och anges som pypi beroenden. Till exempel:
{
"new_cluster": {
"spark_version": "7.3.x-scala2.12",
"num_workers": 1,
"node_type_id": "Standard_DS3_v2"
},
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
},
{
"pypi": {
"package": "/dbfs/path_to_my_lib.whl"
}
}
]
}
Viktigt!
.eggoch.jarberoenden stöds inte för MLflow-projekt.- Körning för MLflow-projekt med Docker-miljöer stöds inte.
- Du måste använda en ny klusterspecifikation när du kör ett MLflow-projekt på Databricks. Det går inte att köra projekt mot befintliga kluster.
Använda SparkR
För att kunna använda SparkR i en MLflow Project-körning måste projektkoden först installera och importera SparkR på följande sätt:
if (file.exists("/databricks/spark/R/pkg")) {
install.packages("/databricks/spark/R/pkg", repos = NULL)
} else {
install.packages("SparkR")
}
library(SparkR)
Projektet kan sedan initiera en SparkR-session och använda SparkR som vanligt:
sparkR.session()
...
Exempel
Det här exemplet visar hur du skapar ett experiment, kör MLflow-självstudieprojektet i ett Azure Databricks-kluster, visar jobbkörningens utdata och visar körningen i experimentet.
Krav
- Installera MLflow med .
pip install mlflow - Installera och konfigurera Databricks CLI. Databricks CLI-autentiseringsmekanismen krävs för att köra jobb i ett Azure Databricks-kluster.
Steg 1: Skapa ett experiment
På arbetsytan väljer du Skapa > MLflow-experiment.
I fältet Namn anger du
Tutorial.Klicka på Skapa. Observera experiment-ID:t. I det här exemplet är det
14622565.
Steg 2: Kör MLflow-självstudieprojektet
Följande steg konfigurerar MLFLOW_TRACKING_URI miljövariabeln och kör projektet, registrerar träningsparametrarna, måtten och den tränade modellen till experimentet som noterades i föregående steg:
MLFLOW_TRACKING_URIAnge miljövariabeln till Azure Databricks-arbetsytan.export MLFLOW_TRACKING_URI=databricksKör MLflow-självstudieprojektet och träna en vinmodell. Ersätt
<experiment-id>med experiment-ID:t som du antecknade i föregående steg.mlflow run https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine -b databricks --backend-config cluster-spec.json --experiment-id <experiment-id>=== Fetching project from https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine into /var/folders/kc/l20y4txd5w3_xrdhw6cnz1080000gp/T/tmpbct_5g8u === === Uploading project to DBFS path /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Finished uploading project to /dbfs/mlflow-experiments/<experiment-id>/projects-code/16e66ccbff0a4e22278e4d73ec733e2c9a33efbd1e6f70e3c7b47b8b5f1e4fa3.tar.gz === === Running entry point main of project https://github.com/mlflow/mlflow#examples/sklearn_elasticnet_wine on Databricks === === Launched MLflow run as Databricks job run with ID 8651121. Getting run status page URL... === === Check the run's status at https://<databricks-instance>#job/<job-id>/run/1 ===Kopiera URL:en
https://<databricks-instance>#job/<job-id>/run/1på den sista raden i MLflow-körningens utdata.
Steg 3: Visa Azure Databricks-jobbkörningen
Öppna url:en som du kopierade i föregående steg i en webbläsare för att visa azure Databricks-jobbkörningens utdata:
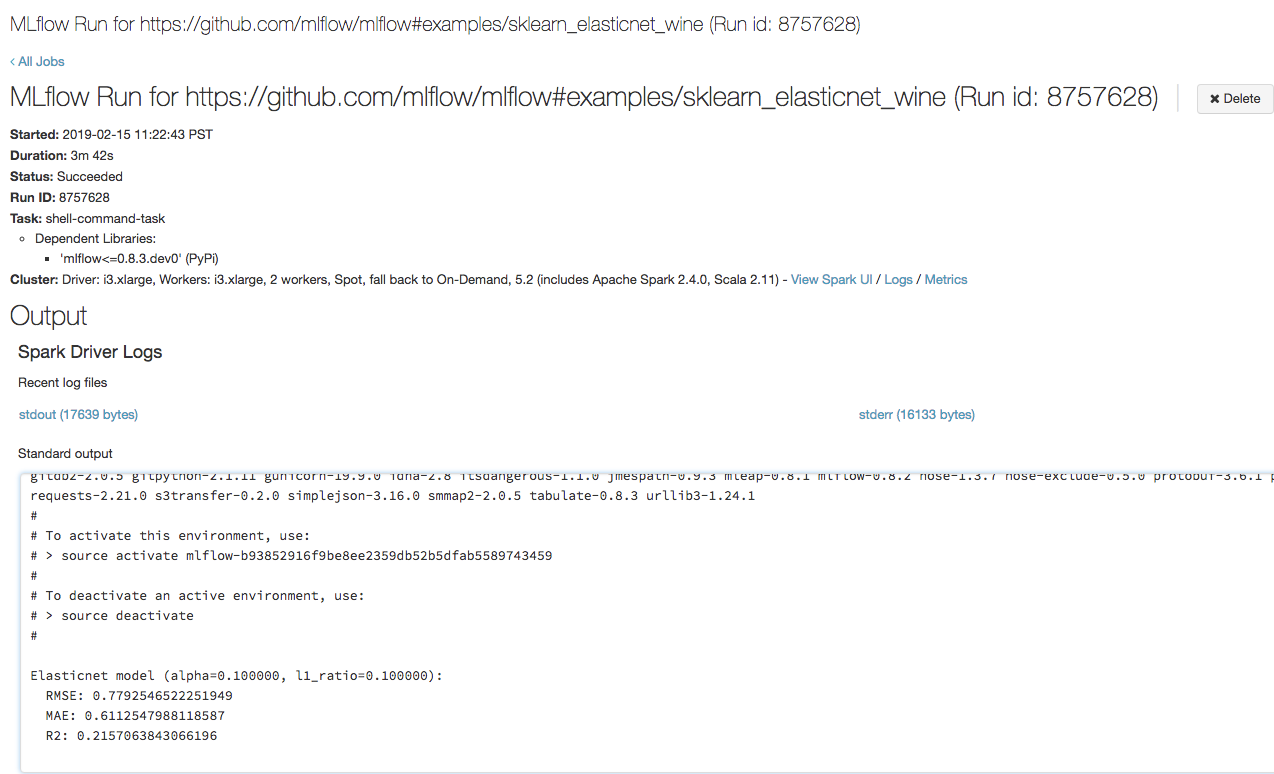
Steg 4: Visa experiment- och MLflow-körningsinformation
Gå till experimentet på din Azure Databricks-arbetsyta.
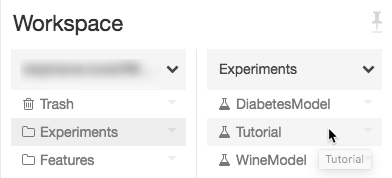
Klicka på experimentet.
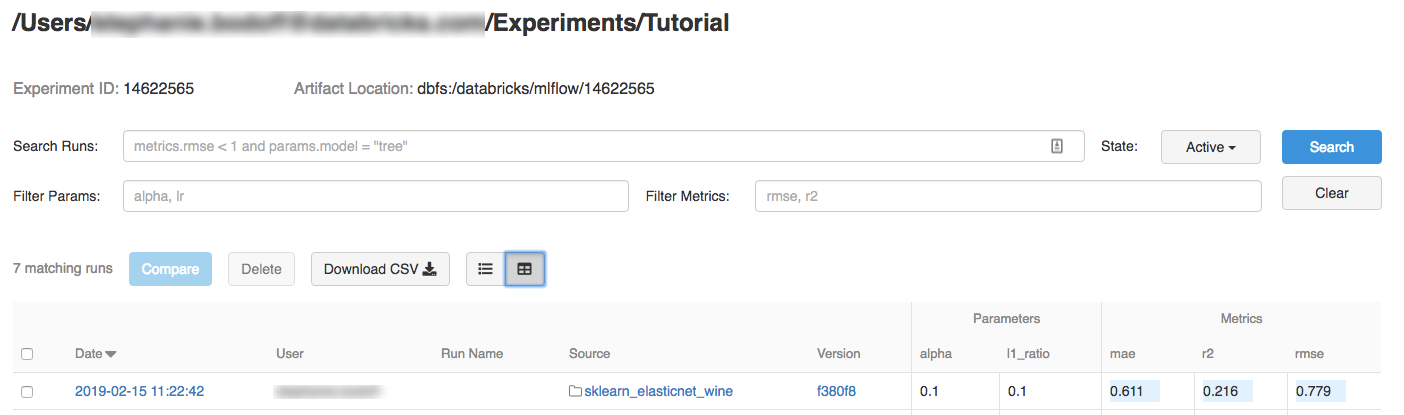
Om du vill visa körningsinformation klickar du på en länk i kolumnen Datum.
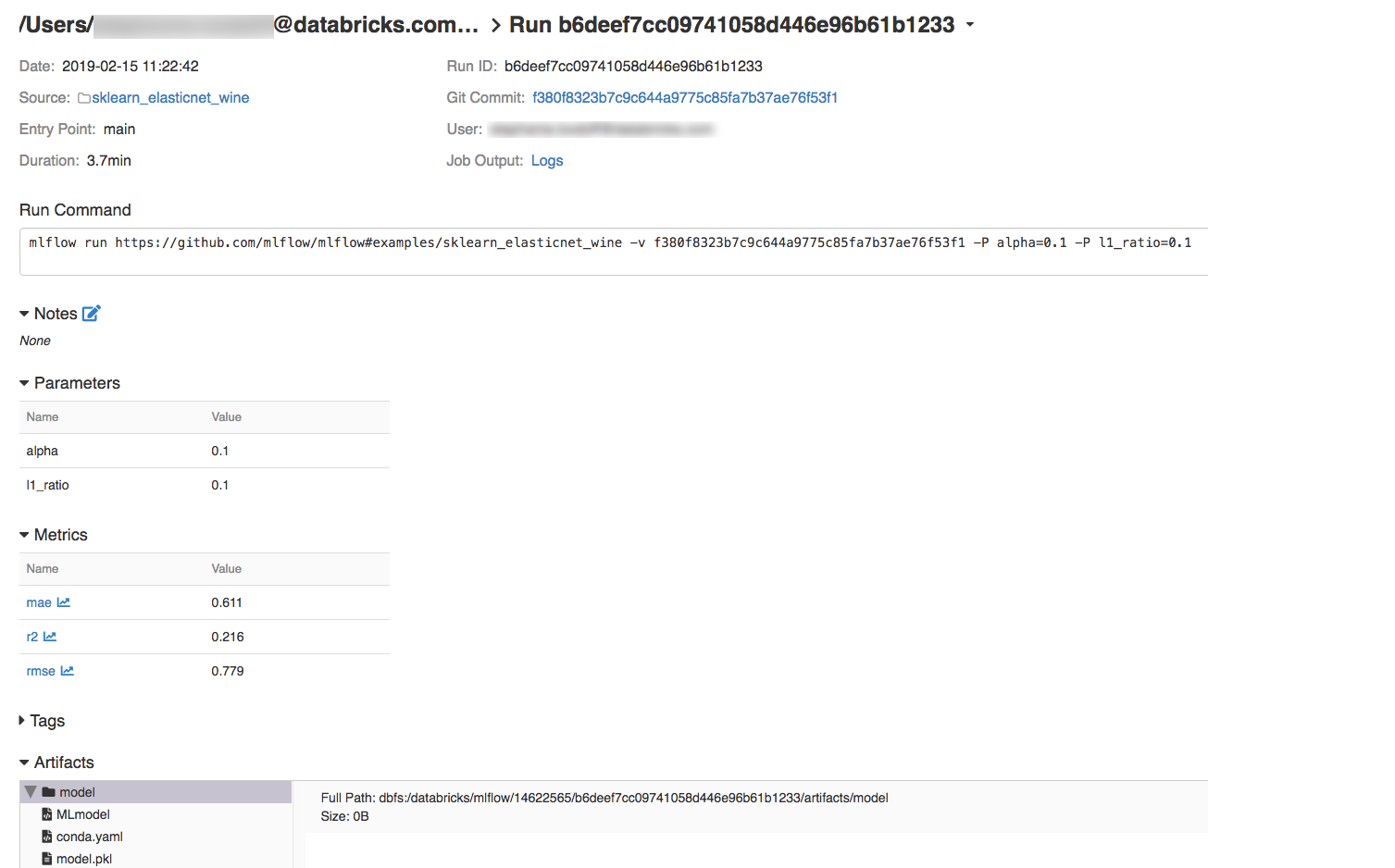
Du kan visa loggar från körningen genom att klicka på länken Loggar i fältet Jobbutdata.
Resurser
Exempel på MLflow-projekt finns i MLflow-appbiblioteket, som innehåller en lagringsplats med färdiga projekt som gör det enkelt att inkludera ML-funktioner i koden.