Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Viktigt!
Lakebase Autoscaling är den senaste versionen av Lakebase, med automatisk skalningsberäkning, skalning till noll, förgrening och omedelbar återställning. Information om regioner som stöds finns i Regiontillgänglighet. Om du är en Lakebase Provisioned-användare kan du läsa Lakebase Provisioned.
I slutet av den här guiden har du en Postgres-databas som körs med exempeldata, anslutna till Unity Catalog, med data som flödar mellan Lakebase och Databricks lakehouse.
Steg: (1) Skapa ett projekt → (2) Anslut → (3) Skapa en tabell → (4) Registrera dig i Unity Catalog → (5) Hantera data
Steg 1: Skapa ditt första projekt
Öppna Lakebase-appen från appväxlaren.
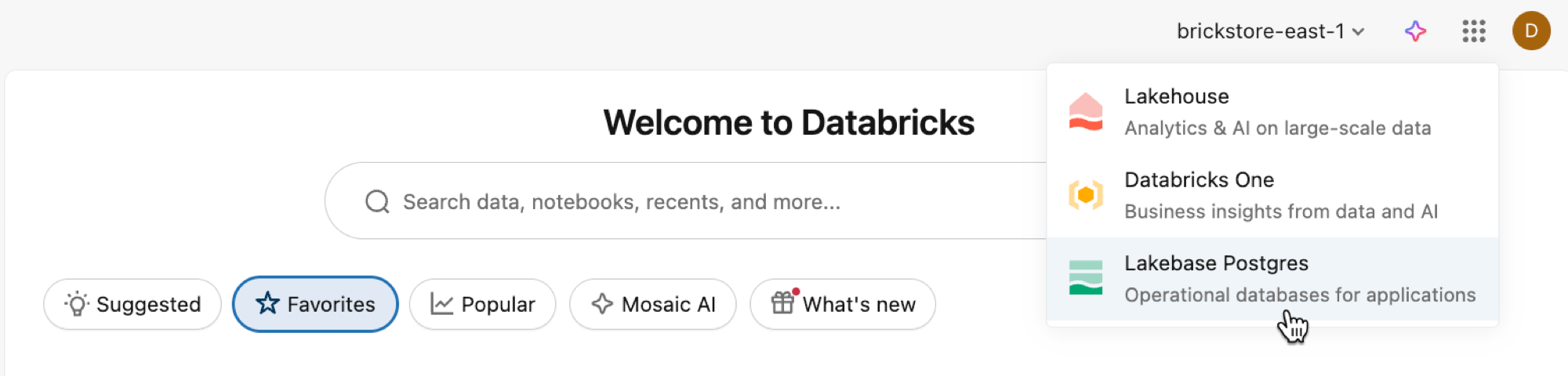
Välj Autoskalning för att få åtkomst till lakebase autoskalningsgränssnittet.
Klicka på Nytt projekt. Ge projektet ett namn och välj din Postgres-version. Projektet skapas med en enda production gren, en standarddatabas databricks_postgres och beräkningsresurser som konfigurerats för grenen.
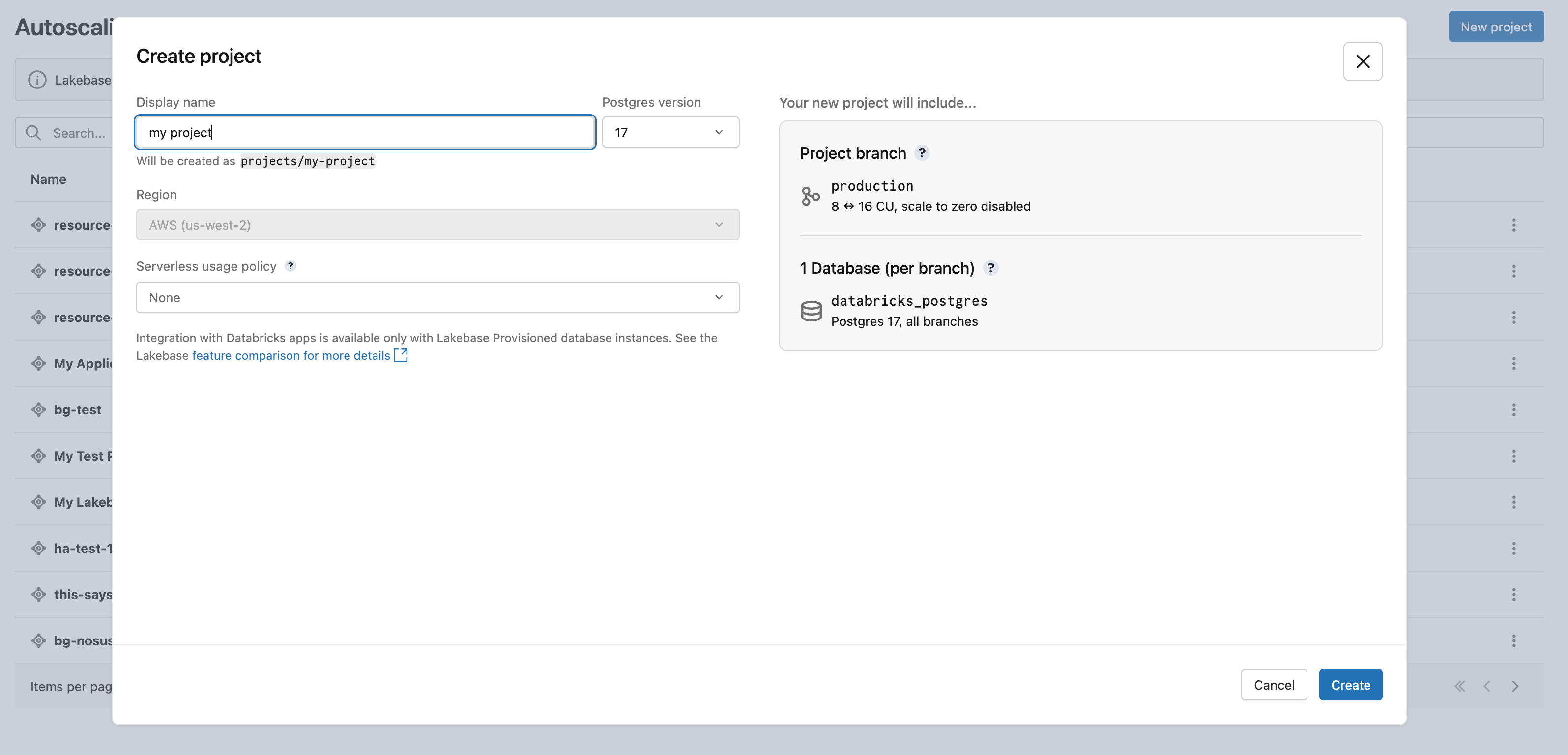
Det kan ta en stund innan beräkningen aktiveras. Beräkningen för grenen production är alltid aktiverad som standard (skalning till noll är inaktiverad), men du kan konfigurera den här inställningen om det behövs.
Regionen för projektet anges automatiskt till din arbetsyteregion.
Läs mer: Skapa ett projekt | Autoskalning | Skalning till noll
Steg 2: Anslut till databasen
I projektet väljer du produktionsgrenen och klickar på Anslut. Anslutningssträngar fungerar med valfri Postgres-standardklient (psql, pgAdmin, DBeaver eller programramverk).
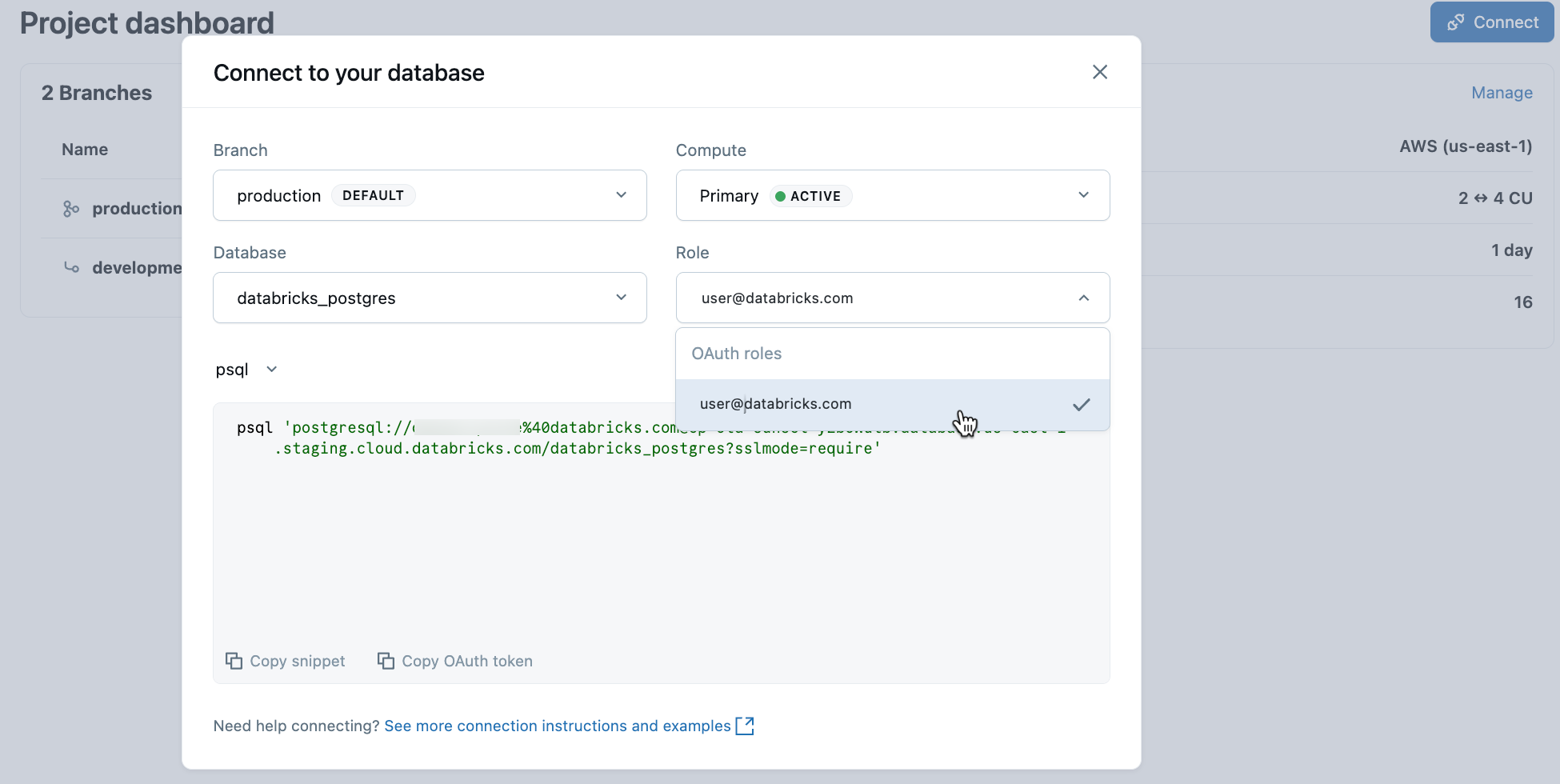
Om du vill ansluta med din Databricks-identitet kopierar du kodfragmentet psql från anslutningsdialogrutan och klistrar in OAuth-token när du uppmanas:
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
Läs mer: Anslutning snabbstart | psql | pgAdmin | Postgres-klienter
Steg 3: Skapa din första tabell
Lakebase SQL-redigeraren är förinstallerad med SQL-exempel. I projektet väljer du produktionsgrenen , öppnar SQL-redigeraren och kör de angivna instruktionerna för att skapa en playing_with_lakebase tabell och infoga exempeldata.
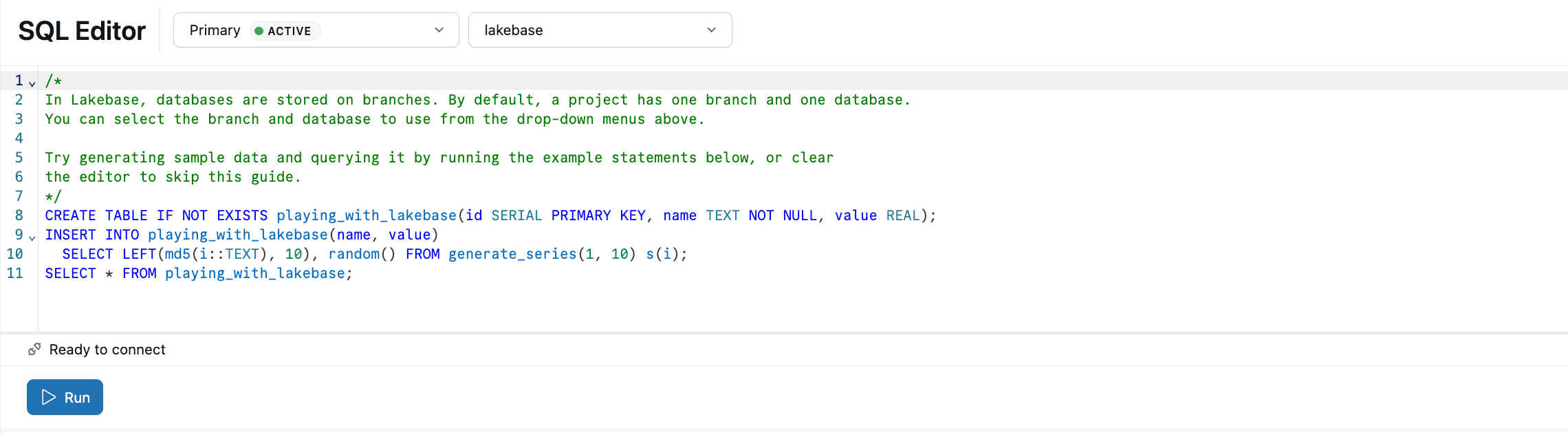
Läs mer: SQL Editor | Tables Editor | Postgres-klienter
Steg 4: Registrera dig i Unity Catalog
Lakebase-databasen körs, men den är osynlig för resten av Databricks-plattformen tills du registrerar den i Unity Catalog. När du har registrerat dig kan du fråga Lakebase-tabeller från Databricks SQL, koppla driftdata till Lakehouse-analys och tillämpa enhetlig styrning.
I Katalogutforskaren skapar du en ny katalog med Lakebase Autoscaling som typ och pekar på projektets production gren och databricks_postgres databas.
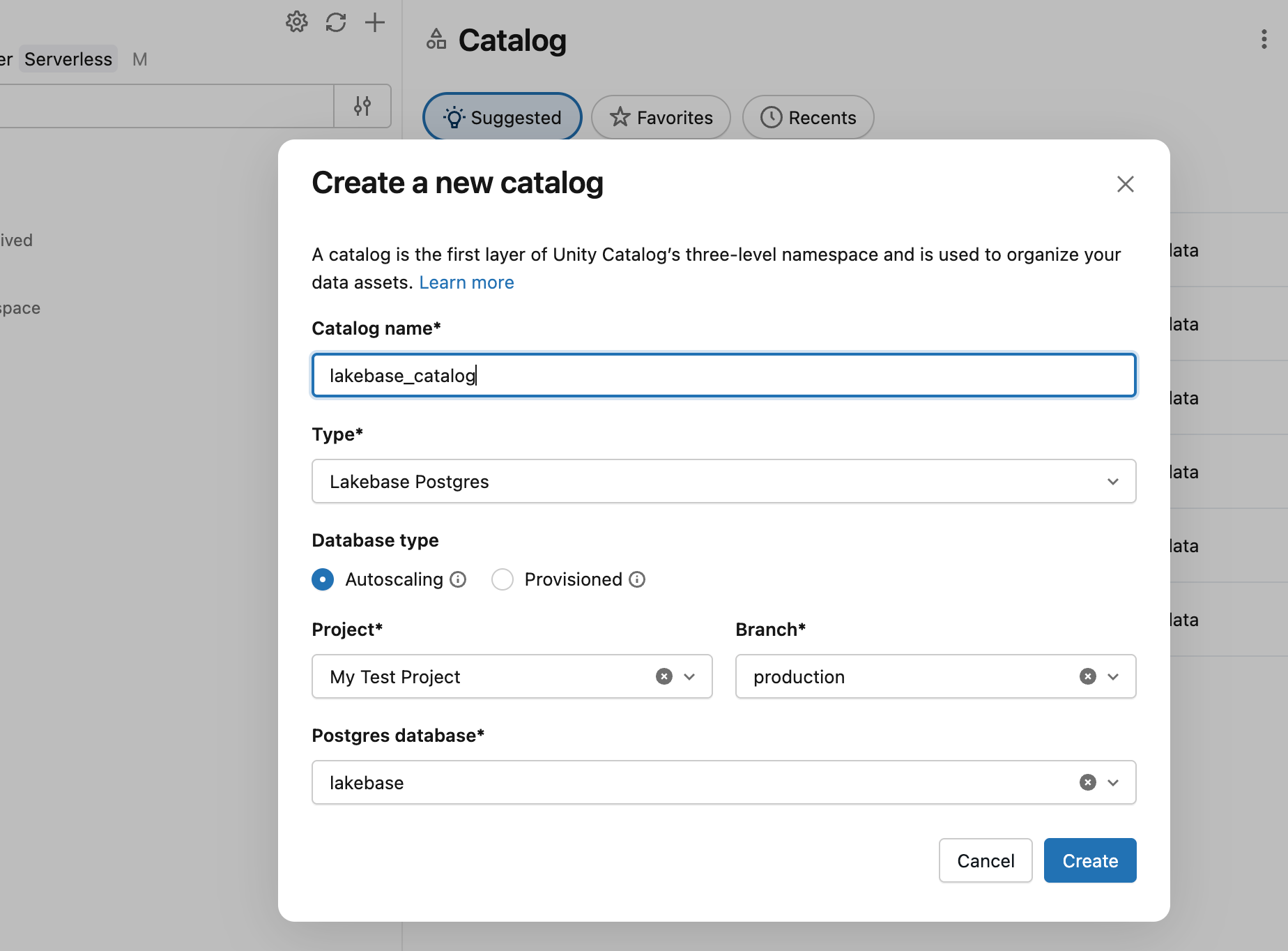
Nu kan du fråga från ett SQL-lager:
SELECT * FROM lakebase_catalog.public.playing_with_lakebase;
Läs mer: Registrera dig i Unity Catalog
Steg 5: Hantera lakehouse-data i din app
Synkroniserade tabeller tar med sig analysdata från Unity Catalog till din Lakebase-databas så att program kan köra frågor mot dem med transaktionsläsningar med låg latens. Skapa en Unity Catalog-exempeltabell och synkronisera den sedan med Lakebase.
Skapa en källtabell i ett SQL-lager eller en notebook-fil:
CREATE TABLE main.default.user_segments AS
SELECT * FROM VALUES
(1001, 'premium', 2500.00, 'high'),
(1002, 'standard', 450.00, 'medium'),
(1003, 'premium', 3200.00, 'high'),
(1004, 'basic', 120.00, 'low')
AS segments(user_id, tier, lifetime_value, engagement);
Synkronisera nu den här tabellen till Lakebase. I Katalogutforskaren skapar du en synkroniserad tabell från user_segments med läget Ögonblicksbild och riktar in sig på projektets databricks_postgres databas. Ögonblicksbildsläget kopierar data en gång. För kontinuerliga uppdateringar, använd Triggered eller Continuous-läge.
När synkroniseringen är klar är data tillgängliga i Lakebase som default.user_segments_synced. Kör en fråga i Lakebase SQL-redigeraren:
SELECT * FROM "default".user_segments_synced WHERE engagement = 'high';
Anmärkning
default måste anges eftersom det är ett reserverat PostgreSQL-nyckelord. Det synkroniserade tabellschemat ärver schemanamnet för Unity-katalogen, så om schemat heter defaultmåste du alltid citera det i frågor. Citattecken runt andra identifierare är valfria.
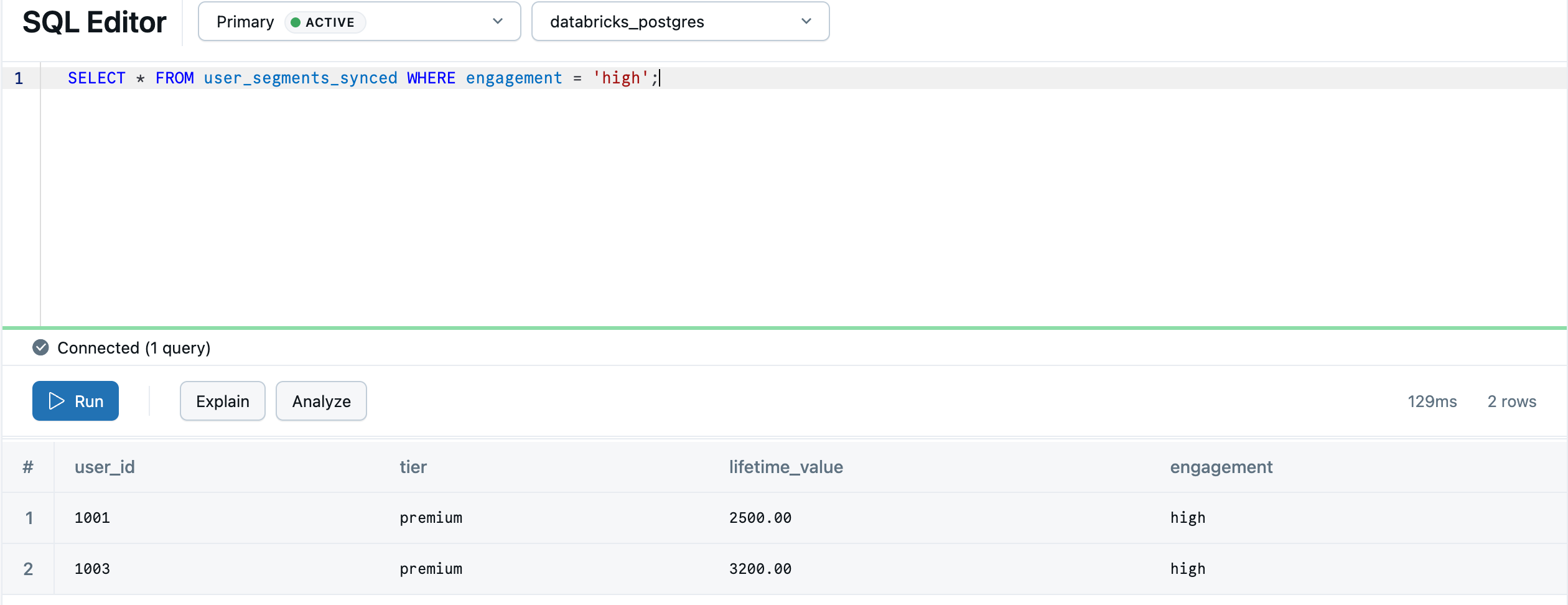
Din lakehouse-analys är nu redo att användas från transaktionsdatabasen.
Läs mer: Synkroniserade tabeller | Synkroniseringslägen | Datatypsmappning
Nästa steg
- Skapa en app:Självstudie om Databricks-appar | Externa appar
- Utveckla med grenar:Självstudie om grenbaserad utveckling
- Konfigurera ditt team:Bevilja projekt- och databasåtkomst
- Utforska plattformen:Grundläggande begrepp | Projektöversikt | Alla självstudier