Anteckning
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Om du har ett långsamt stadium med inte mycket I/O kan detta orsakas av:
- Läsa många små filer
- Skriva många små filer
- Långsamma UDF:er
- Kartesisk sammanfogning
- Exploderande koppling
Nästan alla dessa problem kan identifieras med hjälp av SQL DAG.
Öppna SQL DAG
Öppna SQL DAG genom att rulla upp till toppen av jobbets sida och klicka på Associerad SQL-fråga:

Nu bör du se DAG. Om inte, rulla runt lite och du bör se det:
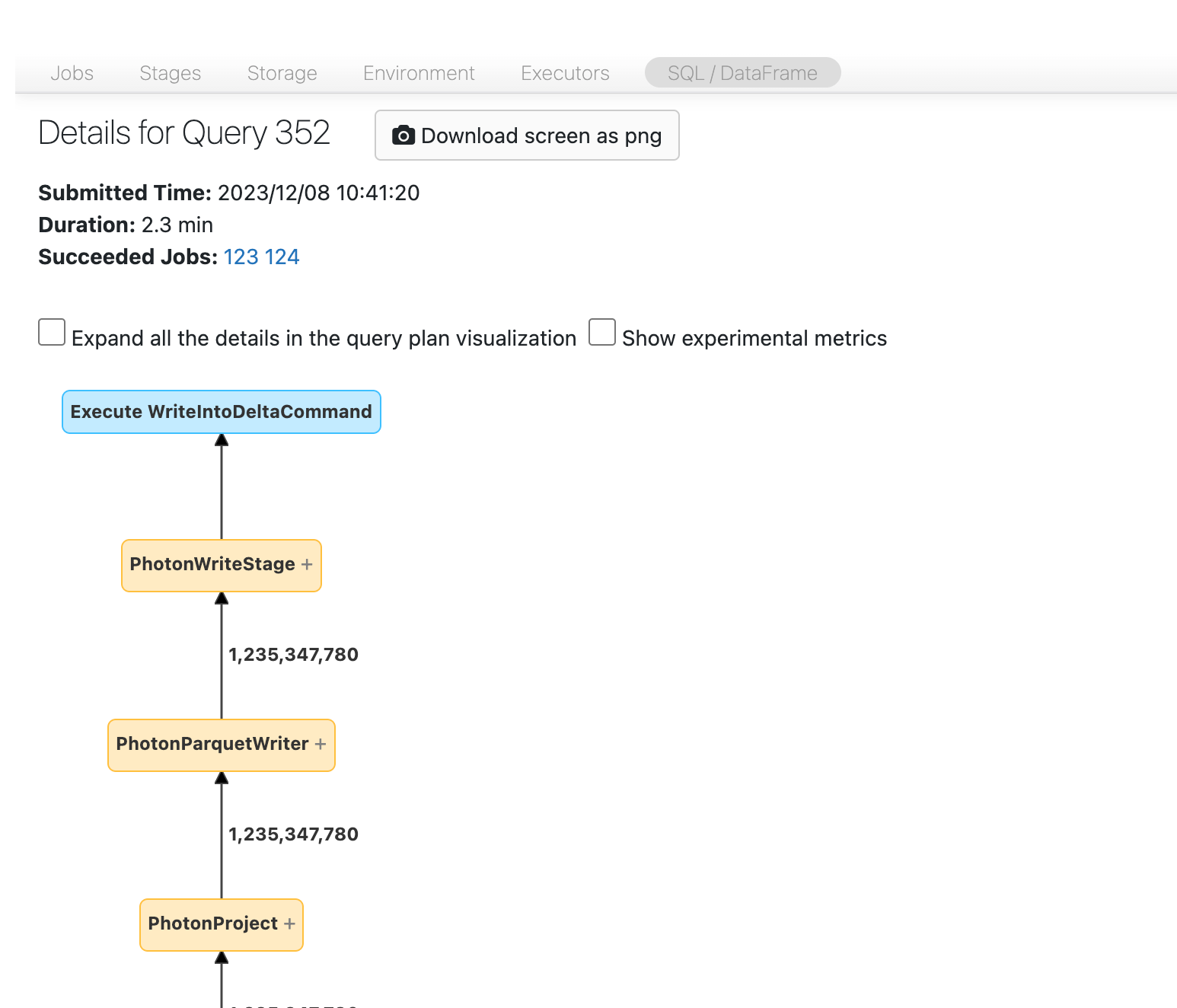
Innan du går vidare, bekanta dig med DAG och var tiden spenderas. Vissa noder i DAG har användbar tidsinformation och andra inte. Det här blocket tog till exempel 2,1 minuter och ger även etapp-ID:

Den här noden kräver att du öppnar den för att se att det tog 1,4 minuter:
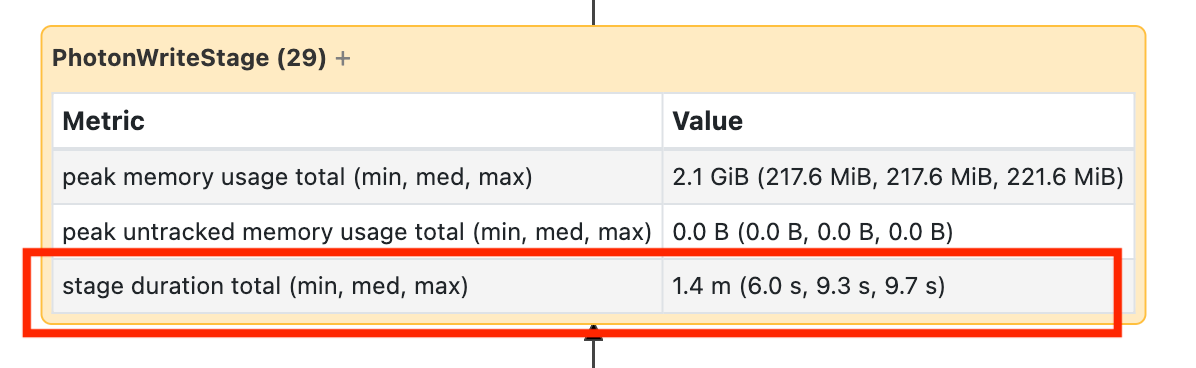
Dessa tider är kumulativa, så det är den totala tiden som spenderas på alla aktiviteter, inte klocktiden. Men det är fortfarande mycket användbart eftersom de är korrelerade med klocktid och kostnad.
Det är bra att bekanta dig med var i DAG tiden spenderas.
Läsa många små filer
Om du märker att en av dina skanningsoperatörer tar lång tid, öppna den och kontrollera antalet lästa filer:
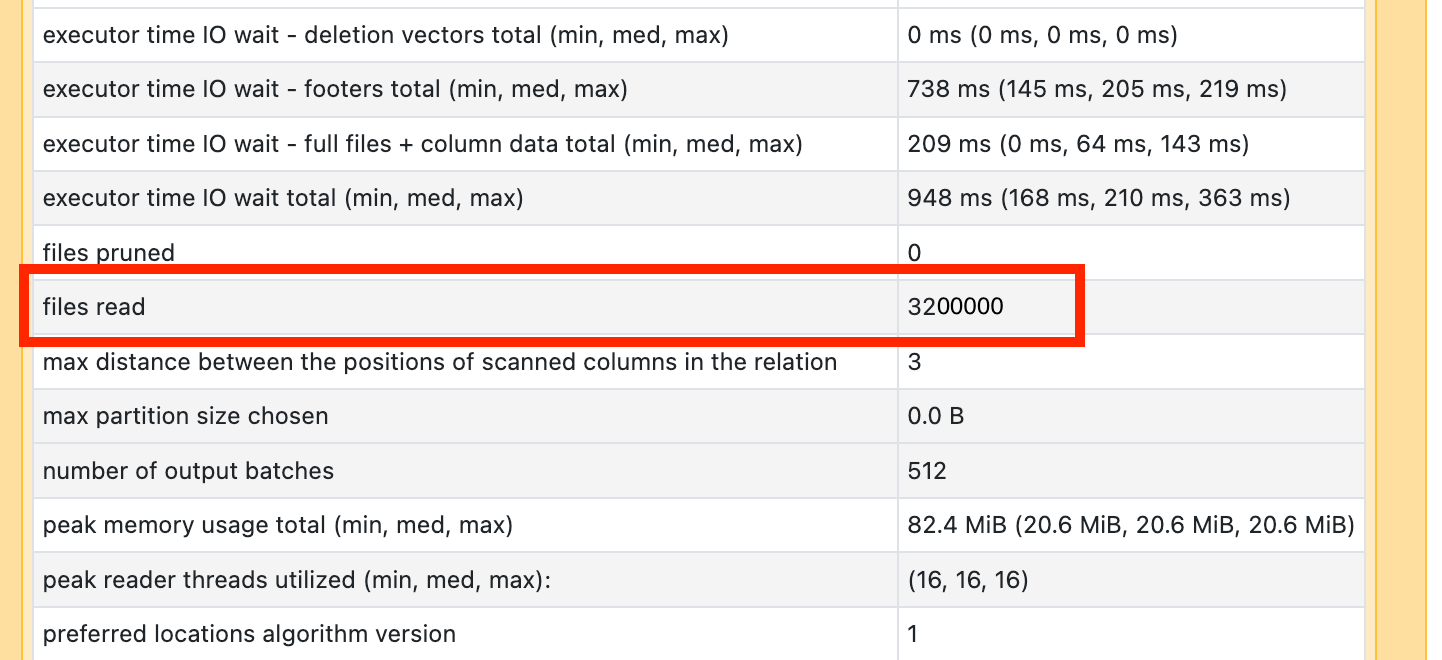
Om du läser tiotusentals filer eller mer kan du ha ett litet filproblem. Filerna ska vara inte mindre än 8 MB. Det lilla filproblemet orsakas oftast av partitionering på för många kolumner eller en kolumn med hög kardinalitet.
Om du har tur kanske du bara behöver köra OPTIMIZE. Oavsett vad, behöver du ompröva layouten på din -fil.
Skriva många små filer
Om du ser att din skrivning tar lång tid öppnar du den och letar efter antalet filer och hur mycket data som skrevs:
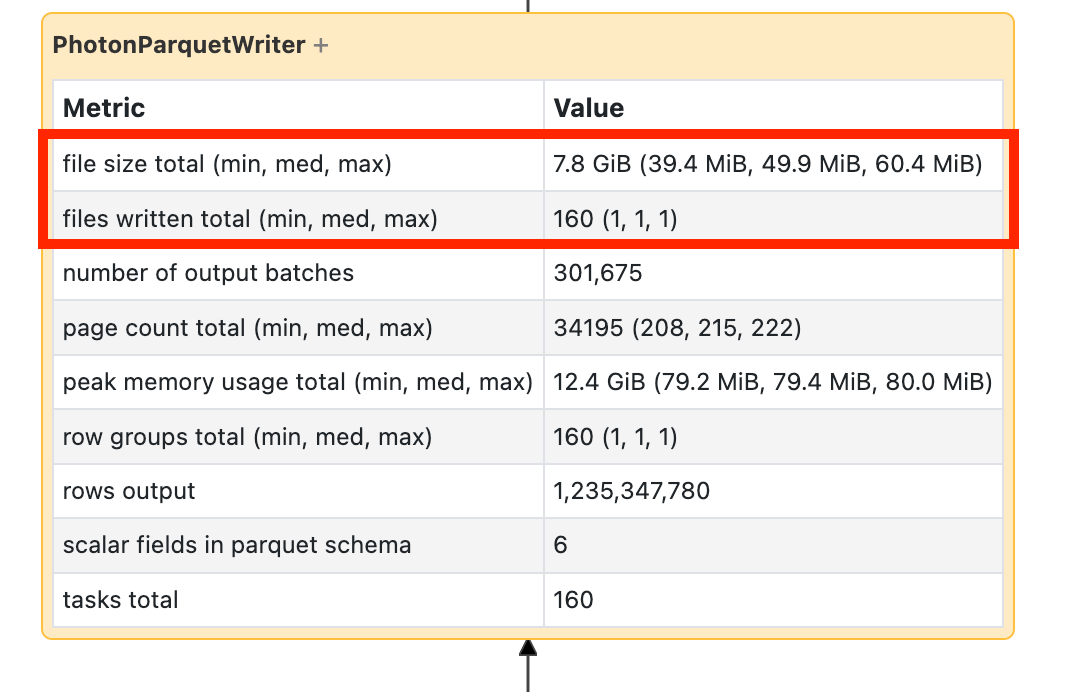
Om du skriver tiotusentals filer eller mer kan du ha ett litet filproblem. Filerna ska vara inte mindre än 8 MB. Det lilla filproblemet orsakas oftast av partitionering på för många kolumner eller en kolumn med hög kardinalitet. Du måste ompröva layouten för din -fil eller aktivera optimerade skrivningar .
Långsamma UDF:er
Om du vet att du har UDF:ereller ser något liknande i din DAG kan du drabbas av långsamma UDF:er:
Om du tror att du lider av det här problemet kan du prova att kommentera ut din UDF för att se hur det påverkar pipelinens hastighet. Om UDF verkligen är där du spenderar tid är det bästa du kan göra att skriva om UDF genom att använda inbyggda funktioner. Om det inte är möjligt bör du överväga antalet aktiviteter i fasen som kör din UDF. Om det är mindre än antalet kärnor i klustret måste repartition() du använda din dataram innan du använder UDF:
(df
.repartition(num_cores)
.withColumn('new_col', udf(...))
)
UDF:er kan också drabbas av minnesproblem. Tänk på att varje uppgift kan behöva läsa in alla data i partitionen i minnet. Om dessa data är för stora kan det bli mycket långsamt eller instabilt. Ompartition kan också lösa problemet genom att göra varje uppgift mindre.
Kartesisk sammanfogning
Om du ser en kartesisk koppling eller kapslad loopkoppling i din DAG bör du veta att dessa kopplingar är mycket dyra. Se till att det är vad du avsåg och se om det finns ett annat sätt.
Exploderande koppling eller explosion
Om du ser några rader som går in i en nod och betydligt fler som kommer ut, kan du lida av en exploderande join eller explode().

Läs mer om detaljer i Databricks-optimeringsguiden.