CI/CD-tekniker med Git- och Databricks Git-mappar (Repos)
Lär dig tekniker för att använda Databricks Git-mappar i CI/CD-arbetsflöden. Om du konfigurerar Databricks Git-mappar på arbetsytan får du källkontroll för projektfiler i Git-lagringsplatser.
Följande bild visar en översikt över tekniker och arbetsflöden.
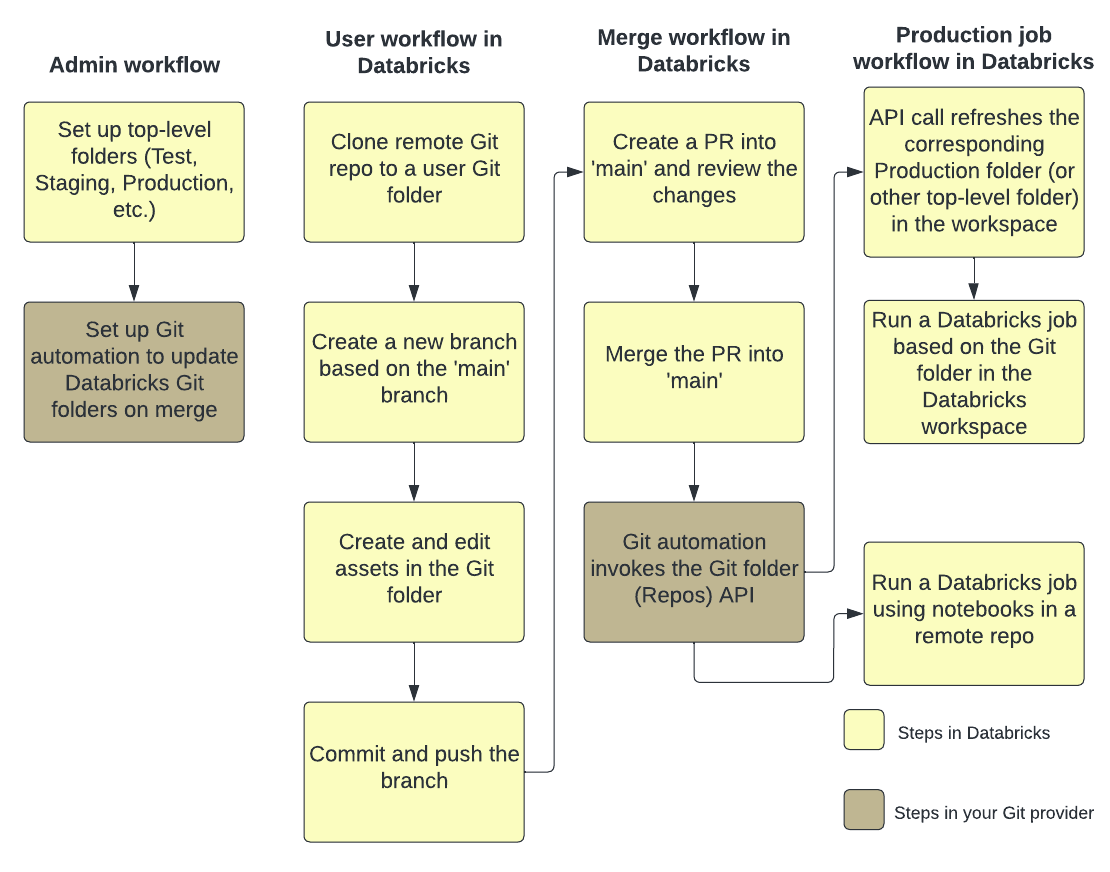
En översikt över CI/CD med Azure Databricks finns i Vad är CI/CD på Azure Databricks?.
Utvecklingsflöde
Databricks Git-mappar har mappar på användarnivå. Mappar på användarnivå skapas automatiskt när användarna först klonar en fjärrlagringsplats. Du kan se Databricks Git-mappar i användarmappar som "lokala utcheckningar" som är enskilda för varje användare och där användarna gör ändringar i sin kod.
Klona fjärrlagringsplatsen i din användarmapp i Databricks Git-mappar. Bästa praxis är att skapa en ny funktionsgren eller välja en tidigare skapad gren för ditt arbete, i stället för att direkt genomföra och push-överföra ändringar till huvudgrenen. Du kan göra ändringar, checka in och skicka ändringar i den grenen. När du är redo att slå samman koden kan du göra det i användargränssnittet för Git-mappar.
Krav
Det här arbetsflödet kräver att du redan har konfigurerat git-integreringen.
Kommentar
Databricks rekommenderar att varje utvecklare arbetar på sin egen funktionsgren. Information om hur du löser sammanslagningskonflikter finns i Lösa sammanslagningskonflikter.
Samarbeta i Git-mappar
Följande arbetsflöde använder en gren som heter feature-b som baseras på huvudgrenen.
- Klona din befintliga Git-lagringsplats till databricks-arbetsytan.
- Använd användargränssnittet för Git-mappar för att skapa en funktionsgren från huvudgrenen. I det här exemplet används en enda funktionsgren
feature-bför enkelhetens skull. Du kan skapa och använda flera funktionsgrenar för att utföra ditt arbete. - Gör dina ändringar i Azure Databricks-notebook-filer och andra filer på lagringsplatsen.
- Checka in och skicka ändringarna till Git-providern.
- Deltagare kan nu klona Git-lagringsplatsen till sin egen användarmapp.
- När du arbetar med en ny gren gör en medarbetare ändringar i notebook-filerna och andra filer i Git-mappen.
- Deltagaren checkar in och push-överför sina ändringar till Git-providern.
- Om du vill sammanfoga ändringar från andra grenar eller ändra bas på funktion-b-grenen i Databricks använder du något av följande arbetsflöden i användargränssnittet för Git-mappar:
- Sammanfoga grenar. Om det inte finns någon konflikt skickas sammanfogningen till git-fjärrlagringsplatsen med hjälp av
git push. - Ändra bas på en annan gren.
- Sammanfoga grenar. Om det inte finns någon konflikt skickas sammanfogningen till git-fjärrlagringsplatsen med hjälp av
- När du är redo att slå samman ditt arbete med git-fjärrlagringsplatsen och
maingrenen använder du användargränssnittet för Git-mappar för att sammanfoga ändringarna från feature-b. Om du vill kan du i stället sammanfoga ändringar i Git-providern.
Arbetsflöde för produktionsjobb
Databricks Git-mappar innehåller två alternativ för att köra dina produktionsjobb:
- Alternativ 1: Ange en git-fjärrreferens i jobbdefinitionen. Kör till exempel en specifik notebook-fil i grenen
mainav en Git-lagringsplats. - Alternativ 2: Konfigurera en Git-produktionslagringsplats och anropa Repos-API:er för att uppdatera den programmatiskt. Kör jobb mot Mappen Databricks Git som klonar den här fjärrlagringsplatsen. Api-anropet för lagringsplatser bör vara den första uppgiften i jobbet.
Alternativ 1: Köra jobb med notebook-filer på en fjärrlagringsplats
Förenkla jobbdefinitionsprocessen och behåll en enda sanningskälla genom att köra ett Azure Databricks-jobb med hjälp av notebook-filer som finns på en fjärransluten Git-lagringsplats. Den här Git-referensen kan vara en Git-incheckning, tagg eller gren och tillhandahålls av dig i jobbdefinitionen.
Detta förhindrar oavsiktliga ändringar i produktionsjobbet, till exempel när en användare gör lokala ändringar i en produktionslagringsplats eller växlar grenar. Det automatiserar också CD-steget eftersom du inte behöver skapa en separat Git-mapp för produktion i Databricks, hantera behörigheter för den och hålla den uppdaterad.
Se Använda versionskontrollerad källkod i ett Azure Databricks-jobb.
Alternativ 2: Konfigurera en Git-produktionsmapp och Git-automatisering
I det här alternativet konfigurerar du en Git-produktionsmapp och automatisering för att uppdatera Git-mappen vid sammanslagning.
Steg 1: Konfigurera mappar på översta nivån
Administratören skapar mappar på den översta nivån som inte är användare. Det vanligaste användningsfallet för dessa mappar på den översta nivån är att skapa utvecklings-, mellanlagrings- och produktionsmappar som innehåller Databricks Git-mappar för lämpliga versioner eller grenar för utveckling, mellanlagring och produktion. Om ditt företag till exempel använder grenen main för produktion måste git-mappen "produktion" ha grenen main utcheckad i den.
Vanligtvis är behörigheter på dessa mappar på den översta nivån skrivskyddade för alla icke-administratörsanvändare på arbetsytan. För sådana mappar på den översta nivån rekommenderar vi att du endast tillhandahåller tjänstens huvudnamn med behörigheten KAN REDIGERA och KAN HANTERA för att undvika oavsiktliga ändringar i produktionskoden av arbetsyteanvändare.
Steg 2: Konfigurera automatiska uppdateringar av Databricks Git-mappar med Git-mapp-API:et
Om du vill behålla en Git-mapp i Databricks i den senaste versionen kan du konfigurera Git Automation för att anropa Repos-API:et. I Git-providern konfigurerar du automatisering som efter varje lyckad sammanslagning av en PR till huvudgrenen anropar repos-API-slutpunkten på lämplig Git-mapp för att uppdatera den till den senaste versionen.
På GitHub kan detta till exempel uppnås med GitHub Actions. Mer information finns i API:et för lagringsplatser.
Om du vill anropa databricks REST API inifrån en Databricks Notebook-cell installerar du först Databricks SDK med %pip install databricks-sdk --upgrade (för de senaste Databricks REST-API:erna) och importerar ApiClient sedan från databricks.sdk.core.
Kommentar
Om %pip install databricks-sdk --upgrade returnerar ett fel som "Det gick inte att hitta paketet" databricks-sdk har paketet inte installerats tidigare. Kör kommandot igen utan --upgrade flaggan: %pip install databricks-sdk.
Du kan också köra Databricks SDK-API:er från en notebook-fil för att hämta tjänstens huvudnamn för din arbetsyta. Här är ett exempel med Python och Databricks SDK för Python.
Du kan också använda verktyg som curl, Postman eller Terraform. Du kan inte använda Användargränssnittet för Azure Databricks.
Mer information om tjänstens huvudnamn på Azure Databricks finns i Hantera tjänstens huvudnamn. Information om tjänstens huvudnamn och CI/CD finns i Tjänstens huvudnamn för CI/CD. Mer information om hur du använder Databricks SDK från en notebook-fil finns i Använda Databricks SDK för Python inifrån en Databricks-notebook-fil.
Använda tjänstens huvudnamn med Databricks Git-mappar
Så här kör du ovan nämnda arbetsflöden med tjänstens huvudnamn:
- Skapa ett huvudnamn för tjänsten med Azure Databricks.
- Lägg till git-autentiseringsuppgifterna: Använd git-providerns PAT för tjänstens huvudnamn.
Så här konfigurerar du tjänstens huvudnamn och lägger sedan till autentiseringsuppgifter för Git-providern:
- Skapa ett huvudnamn för tjänsten. Se Köra jobb med tjänstens huvudnamn.
- Skapa en Microsoft Entra-ID-token för ett huvudnamn för tjänsten.
- När du har skapat ett huvudnamn för tjänsten lägger du till det i din Azure Databricks-arbetsyta med API:et För tjänstens huvudnamn.
- Lägg till dina autentiseringsuppgifter för Git-providern på din arbetsyta med din Microsoft Entra-ID-token och GIT-autentiseringsuppgifterna.
Terraform-integrering
Du kan också hantera Databricks Git-mappar i en helt automatiserad installation med Terraform och databricks_repo:
resource "databricks_repo" "this" {
url = "https://github.com/user/demo.git"
}
Lägg till följande konfiguration om du vill använda Terraform för att lägga till Git-autentiseringsuppgifter i tjänstens huvudnamn:
provider "databricks" {
# Configuration options
}
provider "databricks" {
alias = "sp"
host = "https://....cloud.databricks.com"
token = databricks_obo_token.this.token_value
}
resource "databricks_service_principal" "sp" {
display_name = "service_principal_name_here"
}
resource "databricks_obo_token" "this" {
application_id = databricks_service_principal.sp.application_id
comment = "PAT on behalf of ${databricks_service_principal.sp.display_name}"
lifetime_seconds = 3600
}
resource "databricks_git_credential" "sp" {
provider = databricks.sp
depends_on = [databricks_obo_token.this]
git_username = "myuser"
git_provider = "azureDevOpsServices"
personal_access_token = "sometoken"
}
Konfigurera en automatiserad CI/CD-pipeline med Databricks Git-mappar
Här är en enkel automatisering som kan köras som en GitHub-åtgärd.
Krav
- Du har skapat en Git-mapp på en Databricks-arbetsyta som spårar basgrenen som sammanfogas till.
- Du har ett Python-paket som skapar artefakterna som ska placeras på en DBFS-plats. Koden måste:
- Uppdatera lagringsplatsen som är associerad med din föredragna gren (till exempel
development) så att den innehåller de senaste versionerna av dina notebook-filer. - Skapa artefakter och kopiera dem till bibliotekssökvägen.
- Ersätt de senaste versionerna av byggartefakter för att undvika att behöva uppdatera artefaktversioner manuellt i jobbet.
- Uppdatera lagringsplatsen som är associerad med din föredragna gren (till exempel
Steg
Kommentar
Steg 1 måste utföras av en administratör för Git-lagringsplatsen.
Konfigurera hemligheter så att koden kan komma åt Databricks-arbetsytan. Lägg till följande hemligheter på Github-lagringsplatsen:
- DEPLOYMENT_TARGET_URL: Ställ in den på arbetsytans URL, men ta inte med delsträngen
/?o. - DEPLOYMENT_TARGET_TOKEN: Ange ett PAT-värde (Databricks Personal Access Token). Du kan generera en Databricks PAT genom att följa anvisningarna i Konfigurera Git-autentiseringsuppgifter och ansluta en fjärrdatabas till Azure Databricks.
- DEPLOYMENT_TARGET_URL: Ställ in den på arbetsytans URL, men ta inte med delsträngen
Gå till fliken Åtgärder i Git-lagringsplatsen och klicka på knappen Nytt arbetsflöde. Längst upp på sidan väljer du Konfigurera ett arbetsflöde själv och klistrar in det här skriptet:

# This is a basic automation workflow to help you get started with GitHub Actions. name: CI # Controls when the workflow will run on: # Triggers the workflow on push for main and dev branch push: branches: # Set your base branch name here - your-base-branch-name # A workflow run is made up of one or more jobs that can run sequentially or in parallel jobs: # This workflow contains a single job called "deploy" deploy: # The type of runner that the job will run on runs-on: ubuntu-latest env: DBFS_LIB_PATH: dbfs:/path/to/libraries/ REPO_PATH: /Repos/path/here LATEST_WHEEL_NAME: latest_wheel_name.whl # Steps represent a sequence of tasks that will be executed as part of the job steps: # Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it - uses: actions/checkout@v2 - name: Setup Python uses: actions/setup-python@v2 with: # Version range or exact version of a Python version to use, using SemVer's version range syntax. python-version: 3.8 - name: Install mods run: | pip install databricks-cli pip install pytest setuptools wheel - name: Configure CLI run: | echo "${{ secrets.DEPLOYMENT_TARGET_URL }} ${{ secrets.DEPLOYMENT_TARGET_TOKEN }}" | databricks configure --token - name: Extract branch name shell: bash run: echo "##[set-output name=branch;]$(echo ${GITHUB_REF#refs/heads/})" id: extract_branch - name: Update Databricks Git folder run: | databricks repos update --path ${{env.REPO_PATH}} --branch "${{ steps.extract_branch.outputs.branch }}" - name: Build Wheel and send to Databricks workspace DBFS location run: | cd $GITHUB_WORKSPACE python setup.py bdist_wheel dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}} # there is only one wheel file; this line copies it with the original version number in file name and overwrites if that version of wheel exists; it does not affect the other files in the path dbfs cp --overwrite ./dist/* ${{env.DBFS_LIB_PATH}}${{env.LATEST_WHEEL_NAME}} # this line copies the wheel file and overwrites the latest version with itUppdatera följande miljövariabelvärden med dina egna:
- DBFS_LIB_PATH: Sökvägen i DBFS till de bibliotek (hjul) som du ska använda i den här automatiseringen, som börjar med
dbfs:. Till exempeldbfs:/mnt/myproject/libraries. - REPO_PATH: Sökvägen i Databricks-arbetsytan till Git-mappen där notebook-filer uppdateras. Exempel:
/Repos/Develop - LATEST_WHEEL_NAME: Namnet på den senast kompilerade Python-hjulfilen (
.whl). Detta används för att undvika att manuellt uppdatera hjulversioner i dina Databricks-jobb. Exempel:your_wheel-latest-py3-none-any.whl
- DBFS_LIB_PATH: Sökvägen i DBFS till de bibliotek (hjul) som du ska använda i den här automatiseringen, som börjar med
Välj Genomför ändringar... för att checka in skriptet som ett GitHub Actions-arbetsflöde. När pull-begäran för det här arbetsflödet har sammanfogats går du till fliken Åtgärder på Git-lagringsplatsen och bekräftar att åtgärderna har slutförts.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för