Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Den här sidan innehåller en översikt över verktyg och metoder för att exportera data och konfiguration från din Azure Databricks-arbetsyta. Du kan exportera arbetsytetillgångar för efterlevnadskrav, dataportabilitet, säkerhetskopiering eller migrering av arbetsytor.
Översikt
Azure Databricks-arbetsytor innehåller en mängd olika tillgångar, inklusive konfiguration av arbetsytor, hanterade tabeller, AI- och ML-objekt och data som lagras i molnlagring. När du behöver exportera arbetsytedata kan du använda en kombination av inbyggda verktyg och API:er för att extrahera dessa tillgångar systematiskt.
Vanliga orsaker till att exportera arbetsytedata är:
- Efterlevnadskrav: Uppfylla dataportabilitetsskyldigheter enligt regler som GDPR och CCPA.
- Säkerhetskopiering och haveriberedskap: Skapa kopior av viktiga arbetsytetillgångar för affärskontinuitet.
- Migrering av arbetsyta: Flytta tillgångar mellan arbetsytor eller molnleverantörer.
- Granskning och arkivering: Bevaring av historiska uppteckningar av arbetsytors konfiguration och data.
Planera din export
Innan du börjar exportera arbetsytedata skapar du en inventering av de tillgångar som du behöver för att exportera och förstå beroendena mellan dem.
Förstå arbetsytetillgångar
Din Azure Databricks-arbetsyta innehåller flera kategorier av tillgångar som du kan exportera:
- Konfiguration av arbetsyta: Notebook-filer, mappar, lagringsplatser, hemligheter, användare, grupper, åtkomstkontrollistor (ACL), klusterkonfigurationer och jobbdefinitioner.
- Datatillgångar: Hanterade tabeller, databaser, Databricks-filsystemfiler och data som lagras i molnlagring.
- Beräkningsresurser: Klusterkonfigurationer, principer och instanspoolsdefinitioner.
- AI- och ML-tillgångar: MLflow-experiment, körningar, modeller, Feature Store-tabeller, Vector Search-indices och Unity Catalog-modeller.
- Unity Catalog-objekt: Metaarkivkonfiguration, kataloger, scheman, tabeller, volymer och behörigheter.
Bestäm omfånget för din export
Skapa en checklista med tillgångar som ska exporteras baserat på dina krav. Tänk på följande frågor:
- Behöver du exportera alla tillgångar eller bara specifika kategorier?
- Finns det efterlevnads- eller säkerhetskrav som avgör vilka tillgångar du måste exportera?
- Behöver du bevara relationer mellan tillgångar (till exempel jobb som refererar till notebook-filer)?
- Behöver du återskapa konfigurationen av arbetsytan i en annan miljö?
När du planerar exportomfånget kan du välja rätt verktyg och undvika saknade kritiska beroenden.
Exportera konfiguration av arbetsyta
Terraform-exportören är det primära verktyget för att exportera konfiguration av arbetsytor. Den genererar Terraform-konfigurationsfiler som representerar dina arbetsytetillgångar som kod.
Använda Terraform-exportör
Terraform-exportören är inbyggd i Azure Databricks Terraform-providern och genererar Terraform-konfigurationsfiler för arbetsyteresurser, inklusive notebook-filer, jobb, kluster, användare, grupper, hemligheter och åtkomstkontrollistor. Exportören måste köras separat för varje arbetsyta. Se Databricks Terraform-provider.
Förutsättningar:
- Terraform installerat på datorn
- Azure Databricks-autentisering konfigurerad
- Administratörsbehörigheter på arbetsytan som du vill exportera
Så här exporterar du arbetsyteresurser:
Granska exempelvideon för användning för en genomgång av exportören.
Ladda ned och installera Terraform-providern med exportverktyget:
wget -q -O terraform-provider-databricks.zip $(curl -s https://api.github.com/repos/databricks/terraform-provider-databricks/releases/latest|grep browser_download_url|grep linux_amd64|sed -e 's|.*: "\([^"]*\)".*$|\1|') unzip -d terraform-provider-databricks terraform-provider-databricks.zipKonfigurera miljövariabler för autentisering för din arbetsyta:
export DATABRICKS_HOST=https://your-workspace-url export DATABRICKS_TOKEN=your-tokenKör exportören för att generera Terraform-konfigurationsfiler:
terraform-provider-databricks exporter \ -directory ./exported-workspace \ -listing notebooks,jobs,clusters,users,groups,secretsVanliga exportalternativ:
-
-listing: Ange resurstyper som ska exporteras (kommaavgränsade) -
-services: Alternativ till lista för filtrering av resurser -
-directory: Utdatakatalog för genererade.tffiler -
-incremental: Kör i inkrementellt läge för stegvisa migreringar
-
Granska de genererade
.tffilerna i utdatakatalogen. Exportören skapar en fil för varje resurstyp.
Anmärkning
Terraform-exportören fokuserar på konfiguration och metadata för arbetsytor. Den exporterar inte faktiska data som lagras i tabeller eller Databricks-filsystem. Du måste exportera data separat med de metoder som beskrivs i följande avsnitt.
Exportera specifika tillgångstyper
Använd följande metoder för tillgångar som inte är helt täckta av Terraform-exportören:
- Notebook-filer: Ladda ned notebook-filer individuellt från arbetsytans användargränssnitt eller använd ARBETSYTE-API:et för att exportera notebook-filer programmatiskt. Se Hantera arbetsyteobjekt.
- Hemligheter: Hemligheter kan inte exporteras direkt av säkerhetsskäl. Du måste återskapa hemligheter manuellt i målmiljön. Dokumentera hemliga namn och omfång för referens.
- MLflow-objekt: Använd verktyget mlflow-export-import för att exportera experiment, körningar och modeller. Se avsnittet ML-tillgångar nedan.
Exportera data
Kunddata finns vanligtvis i ditt molnkontolagring, inte i Azure Databricks. Du behöver inte exportera data som redan finns i molnlagringen. Du behöver dock exportera data som lagras på Azure Databricks-hanterade platser.
Exportera hanterade tabeller
Även om hanterade tabeller finns i din molnlagring lagras de i en UUID-baserad hierarki som kan vara svår att parsa. Du kan använda DEEP CLONE kommandot för att skriva om hanterade tabeller som externa tabeller på en angiven plats, vilket gör dem enklare att arbeta med.
Exempelkommandon DEEP CLONE :
CREATE TABLE delta.`abfss://container@storage.dfs.core.windows.net/path/to/storage/`
DEEP CLONE my_catalog.my_schema.my_table
Ett fullständigt skript för att klona alla tabeller i en lista med kataloger finns i exempelskriptet nedan.
Exportera Databricks standardlagringsenhet
För serverlösa arbetsytor erbjuder Azure Databricks standardlagring, vilket är en fullständigt hanterad lagringslösning i Azure Databricks-kontot. Data i standardlagringen måste exporteras till kundägda lagringscontainrar innan arbetsytan tas bort eller inaktiveras. Mer information om serverlösa arbetsytor finns i Skapa en serverlös arbetsyta.
För tabeller i standardlagring använder du DEEP CLONE för att skriva data till en kundägd lagringscontainer. Följ samma mönster som beskrivs i dbfs-rotexportavsnittet nedan för volymer och godtyckliga filer.
Exportera rotkatalogen för Databricks-filsystemet
Databricks File System-roten är den äldre lagringsplatsen i ditt lagringskonto för arbetsytan som kan innehålla kundägda tillgångar, användaruppladdningar, init-skript, bibliotek och tabeller. Även om Databricks-filsystemet root är ett föråldrat lagringsmönster kan äldre arbetsytor fortfarande ha data lagrade på den här platsen som måste exporteras. Mer information om lagringsarkitektur för arbetsytor finns i Lagring av arbetsytor.
Exportera Databricks-filsystem-rot:
Eftersom rot bucketar i Azure är privata kan du inte använda Azure-inbyggda verktyg som azcopy att flytta data mellan lagringskonton. Använd i stället dbutils fs cp och Delta DEEP CLONE i Azure Databricks. Det kan ta lång tid att köra, beroende på mängden data.
# Copy DBFS files to a local path
dbutils.fs.cp("dbfs:/path/to/remote/folder", "/path/to/local/folder", recurse=True)
För tabeller i Databricks-filsystemets rotlagring använder du DEEP CLONE:
CREATE TABLE delta.`abfss://container@storage.dfs.core.windows.net/path/to/external/storage/`
DEEP CLONE delta.`dbfs:/path/to/dbfs/location`
Viktigt!
Att exportera stora mängder data från molnlagring kan medföra betydande kostnader för dataöverföring och lagring. Granska molnleverantörens priser innan du påbörjar stora exporter.
Vanliga exportutmaningar
Hemligheter:
Hemligheter kan inte exporteras direkt av säkerhetsskäl. När du använder Terraform-exportören med -export-secrets alternativet genererar exportören en variabel i vars.tf med samma namn som hemligheten. Du måste uppdatera filen manuellt med de faktiska hemliga värdena eller köra Terraform-exportören med -export-secrets alternativet (endast för Azure Databricks-hanterade hemligheter).
Azure Databricks rekommenderar att du använder en Azure Key Vault-stödd hemlighetslagring.
Exportera AI- och ML-tillgångar
Vissa AI- och ML-tillgångar kräver olika verktyg och metoder för export. Unity Catalog-modeller exporteras som en del av Terraform-exportören.
MLflow-objekt
MLflow omfattas inte av Terraform-exportören på grund av luckor i API:et och problem med serialisering. Om du vill exportera MLflow-experiment, körningar, modeller och artefakter använder du verktyget mlflow-export-import . Det här verktyget med öppen källkod ger en halv komplett täckning av MLflow-migreringen.
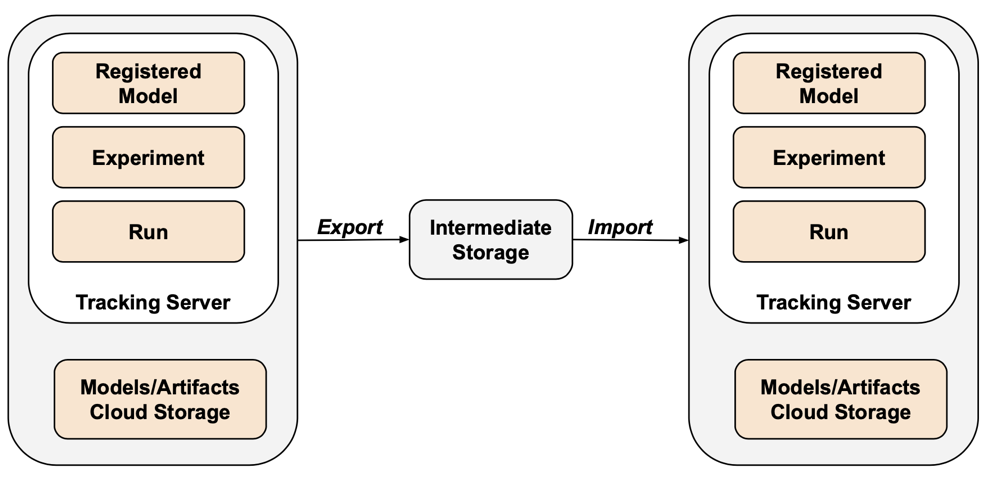
För endast exportscenarier kan du lagra alla MLflow-tillgångar i en kundägd bucket utan att behöva utföra importsteget. Mer information om MLflow-hantering finns i Hantera modelllivscykel i Unity Catalog.
Funktionsarkiv och vektorsökning
Index för vektorsökning: Index för vektorsökning omfattas inte av EU:s dataexportprocedurer. Om du fortfarande vill exportera dem måste de skrivas till en standardtabell och sedan exporteras med .DEEP CLONE
Funktionslagertabeller: Funktionslagret bör behandlas på samma sätt som index för vektorsökning. Använd SQL, välj relevanta data och skriv dem till en standardtabell och exportera sedan med .DEEP CLONE
Verifiera exporterade data
När du har exporterat arbetsytedata kontrollerar du att jobb, användare, notebook-filer och andra resurser exporterades korrekt innan den gamla miljön inaktiverades. Använd checklistan som du skapade under omfångs- och planeringsfasen för att kontrollera att allt du förväntade dig att exportera har exporterats.
Checklista för verifiering
Använd den här checklistan för att verifiera exporten:
- Konfigurationsfiler som genereras: Terraform-konfigurationsfiler skapas för alla nödvändiga arbetsyteresurser.
- Notebook-filer exporteras: Alla notebook-filer exporteras med sitt innehåll och sina metadata intakta.
- Klonade tabeller: Hanterade tabeller klonas till exportplatsen.
- Kopierade datafiler: Molnlagringsdata kopieras helt utan fel.
- Exporterade MLflow-objekt: Experiment, körningar och modeller exporteras med sina artefakter.
- Dokumenterade behörigheter: Åtkomstkontrollistor och behörigheter samlas in i Terraform-konfigurationen.
- Identifierade beroenden: Relationer mellan resurser (till exempel jobb som hänvisar till notebook-filer) bevaras i exporten.
Bästa praxis för postexport
Validerings- och acceptanstestning drivs till stor del av dina krav och kan variera kraftigt. Dessa allmänna metodtips gäller dock:
- Definiera en testbädd: Skapa en testbädd med jobb eller anteckningsböcker som verifierar att hemligheter, data, monter, anslutningsappar och andra beroenden fungerar korrekt i den exporterade miljön.
- Börja med utvecklingsmiljöer: Om du flyttar på ett stegvis sätt börjar du med utvecklingsmiljön och arbetar upp till produktion. Detta identifierar stora problem tidigt och undviker påverkan på produktionen.
- Utnyttja Git-mappar: Använd Git-mappar när det är möjligt eftersom de finns i en extern Git-lagringsplats. Detta undviker manuell export och säkerställer att koden är identisk mellan miljöer.
- Dokumentera exportprocessen: Registrera de verktyg som används, kommandon som körs och eventuella problem som påträffas.
- Säkra exporterade data: Se till att exporterade data lagras säkert med lämpliga åtkomstkontroller, särskilt om de innehåller känslig eller personligt identifierbar information.
- Underhåll efterlevnad: Om du exporterar i kompatibilitetssyfte kontrollerar du att exporten uppfyller regelkrav och kvarhållningsprinciper.
Exempelskript och automatisering
Du kan automatisera exporten av arbetsytor med hjälp av skript och schemalagda jobb.
Exportskript för djupkloning
Följande skript exporterar hanterade Unity Catalog-tabeller med .DEEP CLONE Den här koden ska köras på källarbetsytan för att exportera en viss katalog till en mellanliggande bucket. Uppdatera variablerna catalogs_to_copy och dest_bucket .
import pandas as pd
# define catalogs and destination bucket
catalogs_to_copy = ["my_catalog_name"]
dest_bucket = "<cloud-storage-path>://my-intermediate-bucket"
manifest_name = "manifest"
# initialize vars
system_info = sql("SELECT * FROM system.information_schema.tables")
copied_table_names = []
copied_table_types = []
copied_table_schemas = []
copied_table_catalogs = []
copied_table_locations = []
# loop through all catalogs to copy, then copy all non-system tables
# note: this would likely be parallelized using thread pooling in prod
for catalog in catalogs_to_copy:
filtered_tables = system_info.filter((system_info.table_catalog == catalog) & (system_info.table_schema != "information_schema"))
for table in filtered_tables.collect():
schema = table['table_schema']
table_name = table['table_name']
table_type = table['table_type']
print(f"Copying table {schema}.{table_name}...")
target_location = f"{dest_bucket}/{catalog}_{schema}_{table_name}"
sqlstring = f"CREATE TABLE delta.`{target_location}` DEEP CLONE {catalog}.{schema}.{table_name}"
sql(sqlstring)
# lists used to create manifest table DF
copied_table_names.append(table_name)
copied_table_types.append(table_type)
copied_table_schemas.append(schema)
copied_table_catalogs.append(catalog)
copied_table_locations.append(target_location)
# create the manifest as a df and write to a table in dr target
# this contains catalog, schema, table and location
manifest_df = pd.DataFrame({"catalog": copied_table_catalogs,
"schema": copied_table_schemas,
"table": copied_table_names,
"location": copied_table_locations,
"type": copied_table_types})
spark.createDataFrame(manifest_df).write.mode("overwrite").format("delta").save(f"{dest_bucket}/{manifest_name}")
display(manifest_df)
Automationsöverväganden
Vid automatisering av exporter:
- Använd schemalagda jobb: Skapa Azure Databricks-jobb som kör exportskript enligt ett regelbundet schema.
- Övervaka exportjobb: Konfigurera aviseringar för att meddela dig om exporten misslyckas eller tar längre tid än förväntat.
- Hantera autentiseringsuppgifter: Lagra autentiseringsuppgifter för molnlagring och API-token på ett säkert sätt med hjälp av Azure Databricks-hemligheter. Se Hemlig hantering.
- Versionsexport: Använd tidsstämplar eller versionsnummer i exportsökvägar för att underhålla historiska exporter.
- Rensa gamla exporter: Implementera kvarhållningsprinciper för att ta bort gamla exporter och hantera lagringskostnader.
- Inkrementell export: För stora arbetsytor bör du överväga att implementera inkrementella exporter som endast exporterar ändrade data sedan den senaste exporten.