Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Du kan använda en frågeprofil för att visualisera detaljer om en frågeprocedur. Frågeprofilen hjälper dig att felsöka prestandaflaskhalsar under frågans körning. Till exempel:
- Du kan visualisera varje frågeoperator och relaterade mått, till exempel tid, antal rader som bearbetas, rader som bearbetas och minnesförbrukning.
- Du kan snabbt identifiera den långsammaste delen av körningen av en fråga och utvärdera effekterna av ändringar i frågeformuleringen.
- Du kan identifiera och åtgärda vanliga misstag i SQL-instruktioner, till exempel exploderande kopplingar eller fullständiga tabellgenomsökningar.
Krav
Om du vill visa en frågeprofil måste du antingen vara ägare till frågan eller ha åtminstone behörigheten CAN MONITOR på SQL-lagret som körde frågan.
Visa en frågeprofil
Du kan visa frågeprofilen från frågehistoriken med hjälp av följande steg:
Klicka på
 Frågehistorik i sidofältet.
Frågehistorik i sidofältet.Klicka på namnet på en fråga. En frågeinformationspanel visas till höger på skärmen.
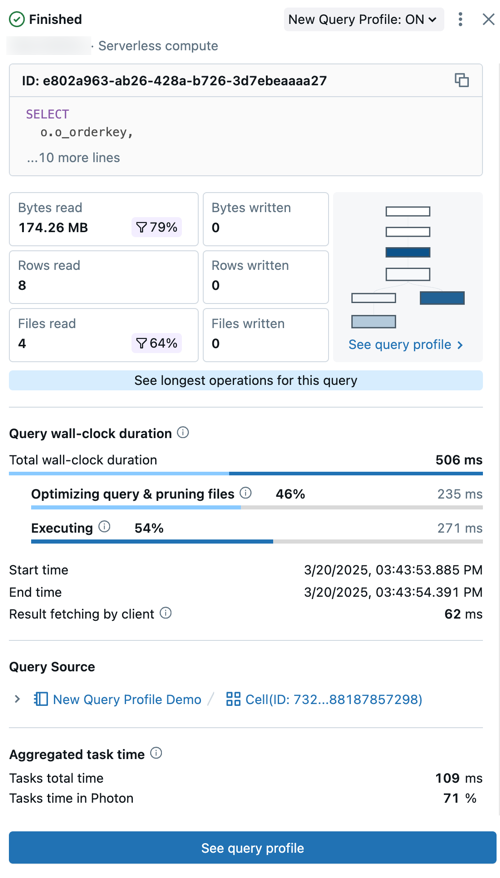
Frågesammanfattningen innehåller:
- Frågestatus: Frågan är taggad med dess aktuella status: I kö, Körs, Slutförd, Misslyckades eller Avbryts.
- Användar- och beräkningsinformation: Se information om användarnamn, beräkningstyp och körning för den här frågekörningen.
- ID: Det här är den universellt unika identifieraren (UUID) som är associerad med den angivna frågekörningen.
- Frågeuttryck: Det här avsnittet innehåller den fullständiga frågeutsatsen. Om frågan är för lång för att visas i förhandsversionen klickar du på ... fler rader för att visa den fullständiga texten.
- Frågemått: Populära mått för frågeanalys visas under frågetexten. Filterikonerna som visas med vissa mått anger procentandelen data som beskärs under genomsökningen.
- Se frågeprofil: En förhandsgranskning av frågeprofilens riktade acykliska graf (DAG) visas i den här sammanfattningen. Detta kan vara användbart för att snabbt uppskatta frågekomplexitet och exekveringsflöde. Klicka på Se frågeprofil för att öppna den detaljerade DAG.
- Se de längsta operatorerna för den här frågan: Klicka på den här knappen för att öppna panelen Översta operatorer . Den här panelen visar de operatorer som körs längst i sökfrågan.
- Fråga varaktighet för wall-clock: Den totala förflutna tiden mellan början av schemaläggningen och slutet av frågekörningen tillhandahålls som en sammanfattning. En detaljerad uppdelning av schemaläggning, frågeoptimering, filrensning och körningstid visas under sammanfattningen.
- Frågekälla: Klicka på namnet på det angivna objektet för att gå till frågekällan.
- Aggregerad aktivitetstid: Visa den kombinerade tid det tog att köra frågan över alla kärnor i alla noder. Det kan vara betydligt längre än tidsåtgången för väggklockan om flera uppgifter excuteras parallellt. Den kan vara kortare än varaktigheten för väggklockan om aktiviteterna väntade på tillgängliga noder.
- Indata/utdata (I/O): Visa information om de data som lästs och skrivits under frågekörningen.
Klicka på Se frågeprofil. En informationspanel öppnas till höger på skärmen.
Anteckning
Om frågeprofilen inte är tillgänglig visas ingen profil för den här frågan. En frågeprofil är inte tillgänglig för frågor som körs från frågecachen. Om du vill kringgå frågecachen gör du en trivial ändring av frågan, till exempel att ändra eller ta bort
LIMIT.
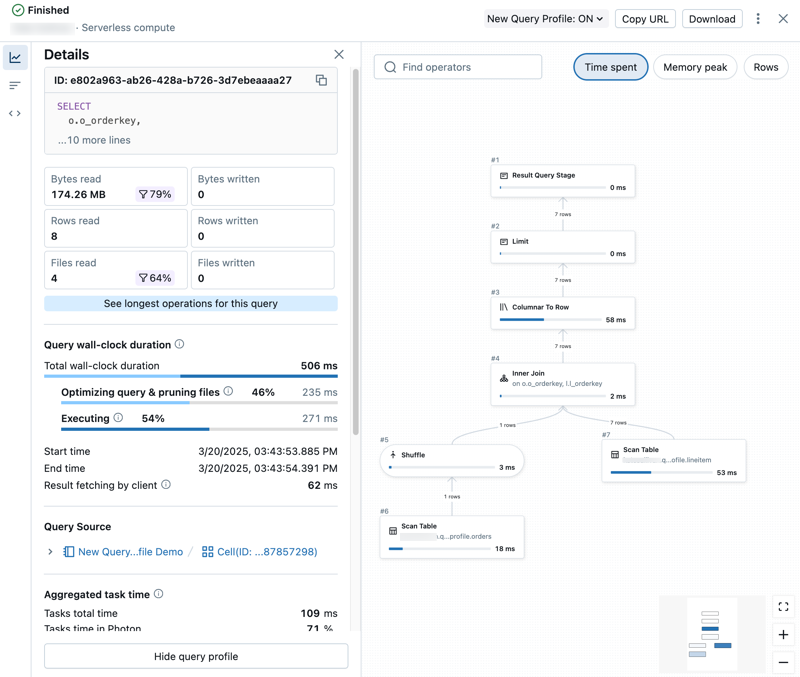
Visa information om frågeprofil
Den detaljerade frågeprofilen innehåller sammanfattningsmått till vänster i panelen och en grafvy över operatorer till höger.
Utforska frågemått
Till vänster i frågeprofilen finns följande flikar:
 Information: Öppnar panelen Information som visar frågesammanfattningsmått.
Information: Öppnar panelen Information som visar frågesammanfattningsmått. Toppoperatorer: Öppnar panelen De översta operatorerna som visar de dyraste operatorerna som används i frågan. Detta kan vara användbart för att identifiera optimeringsmöjligheter.
Toppoperatorer: Öppnar panelen De översta operatorerna som visar de dyraste operatorerna som används i frågan. Detta kan vara användbart för att identifiera optimeringsmöjligheter. Frågetext: Öppnar frågetextpanelen som visar frågans fullständiga text.
Frågetext: Öppnar frågetextpanelen som visar frågans fullständiga text.
Anteckning
Vissa icke-fotonåtgärder körs som en grupp och delar vanliga mått. I det här fallet har alla åtgärder samma värde som den överordnade operatorn för ett visst mått.
Utforska DAG
Den högra halvan av frågeprofilen visar frågans riktade acykliska graf (DAG). Diagramvyn visar mått som Tidsåtgång, Minnestoppar och Rader. Klicka på varje mått för att ändra det rapporteringsmått som visas.
Du kan interagera med DAG på följande sätt:
- Använd sökfältet för att markera olika operatorer eller kolumner.
- Zooma in eller ut på olika delar av DAG:en.
- Klicka på operatorer för att visa detaljerade mätvärden och beskrivningar. En panel till höger i diagrammet visar åtgärdsinformation.
För Databricks SQL-frågor kan du också visa frågeprofilen i Spark-användargränssnittet. Klicka på ![]() Kebab-menyn längst upp på sidan och klicka sedan på Öppna i Spark-användargränssnittet.
Kebab-menyn längst upp på sidan och klicka sedan på Öppna i Spark-användargränssnittet.
Som standard är mått för vissa åtgärder dolda. Dessa åtgärder är sannolikt inte orsaken till flaskhalsar i prestanda. Om du vill se information om alla åtgärder och om du vill se ytterligare mått klickar du på ![]() Klicka sedan på Aktivera utförligt läge överst på sidan.
Klicka sedan på Aktivera utförligt läge överst på sidan.
Vanliga åtgärder
De vanligaste åtgärderna är:
- Genomsökning: Data lästes från en datakälla och redovisades som rader.
- Join: Rader från flera relationer kombinerades (interfolierade) till en enda uppsättning rader.
- Union: Rader från flera relationer som använder samma schema sammanfogades till en enda uppsättning rader.
- Shuffle: Data omfördelades eller partitionerades om. Shuffle-åtgärder är dyra när det gäller resurser eftersom de flyttar data mellan exekutorer i klustret.
-
Hash/sortering: Rader grupperades efter en nyckel och utvärderades med hjälp av en mängdfunktion som
SUM,COUNTellerMAXinom varje grupp. -
Filter: Indata filtreras enligt ett villkor, till exempel av en
WHEREsats, och en delmängd rader returneras.
Dela en frågeprofil
Så här delar du en frågeprofil med en annan användare:
- Visa frågehistorik.
- Klicka på frågans namn.
- Om du vill dela frågan har du två alternativ:
- Om den andra användaren har behörigheten CAN MANAGE för frågan kan du dela URL:en för frågeprofilen med dem. Klicka på Dela. URL:en kopieras till Urklipp.
- Annars kan du ladda ned frågeprofilen som ett JSON-objekt om den andra användaren inte har behörigheten CAN MANAGE eller inte är medlem i arbetsytan. Hämta. JSON-filen laddas ned till ditt lokala system.
Importera en frågeprofil
Så här importerar du JSON för en frågeprofil:
Visa frågehistorik.
Klicka på
 Välj Importera frågeprofil (JSON) i det övre högra hörnet.
Välj Importera frågeprofil (JSON) i det övre högra hörnet.I filläsaren väljer du JSON-filen som delades med dig och klickar på Öppna. JSON-filen laddas upp och frågeprofilen visas.
När du importerar en frågeprofil läses den in dynamiskt i webbläsarsessionen och sparas inte på arbetsytan. Du måste importera den igen varje gång du vill visa den.
Stäng den importerade frågeprofilen genom att klicka på X överst på sidan.
Få åtkomst till frågeprofilen
Du kan också komma åt frågeprofilen i följande delar av användargränssnittet:
Från SQL-redigeraren: Under och efter frågekörningen visar en länk längst ned på sidan tiden som förflutit och antalet rader som returneras. Klicka på länken för att öppna frågeinformationspanelen. Klicka på Se frågeprofil.

Anteckning
Om du har aktiverat den nya SQL-redigeraren (offentlig förhandsversion) visas länken som den gör i en notebook-fil.
Från en notebook-fil: Om anteckningsboken är kopplad till ett SQL-lager eller en serverlös beräkning kan du komma åt frågeprofilen med hjälp av länken under cellen som innehåller frågan. Klicka på Visa prestanda för att öppna körningshistoriken. Klicka på en instruktion för att öppna frågeinformationspanelen.

Från Lakeflow Spark Deklarativa pipelines-användargränssnittet: Du kan komma åt frågehistoriken och profilen från fliken Frågehistorik i pipelinegränssnittet. Se Åtkomst till frågehistorik för pipelines.
Från jobbgränssnittet: Du kan komma åt frågeprofiler för jobb som körs på SQL-lager och serverlös beräkning. För jobb som körs på serverlös beräkning, se Visa frågeinformation för jobbkörningar för att lära dig hur du visar frågeinformation i jobbgränssnittet.
Nästa steg
- Lär dig mer om att komma åt frågemått med hjälp av frågehistorik-API:et
- Läs mer om frågehistorik