Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Den här sidan beskriver hur du använder Delta-tabeller som källor och mottagare för Spark Structured Streaming med readStream och writeStream. Delta Lake löser vanliga prestanda- och tillförlitlighetsproblem för strömningssystem och filer. Exempel på fördelar:
- Samla små filer som produceras av inmatning med låg latens och förbättra prestanda.
- Upprätthåll "exakt-en-gång"-bearbetning med mer än en datastream (eller konkurrerande batchjobb).
- Identifiera nya filer effektivt när du använder filer som en strömkälla.
Information om hur du läser in data med hjälp av strömmande tabeller i Databricks SQL finns i Använda strömmande tabeller i Databricks SQL.
Information om stream-static-kopplingar med Delta Lake finns i Stream-static joins (Ström-statiska kopplingar).
Använda Delta-tabeller som mottagare
Du kan skriva data till en Delta-tabell med strukturerad direktuppspelning. Delta Lake-transaktionsloggen garanterar bearbetning exakt en gång, även när det finns andra strömmar eller batchfrågor som körs samtidigt mot tabellen.
När du skriver till en Delta-tabell med en Structured Streaming-mottagare kan du se tomma commits med epochId = -1. Dessa är förväntade och inträffar vanligtvis:
- På den första batchen för varje körning av strömningsfrågan (detta sker i varje batch för
Trigger.AvailableNow). - När ett schema ändras (till exempel att lägga till en kolumn).
Dessa tomma incheckningar är avsiktliga och tyder inte på något fel. De påverkar inte frågans korrekthet eller prestanda på något betydande sätt.
Note
Funktionen Delta Lake VACUUM tar bort alla filer som inte hanteras av Delta Lake, men hoppar över alla kataloger som börjar med _. Du kan lagra kontrollpunkter på ett säkert sätt tillsammans med andra data och metadata för en Delta-tabell med hjälp av en katalogstruktur som <table-name>/_checkpoints.
Övervaka backlog med metrik
Använd följande mått för att övervaka kvarvarande uppgifter för en strömmande frågeprocess:
-
numBytesOutstanding: Antal byte som ännu inte har bearbetats i kvarvarande uppgifter. -
numFilesOutstanding: Antal filer som ännu inte har bearbetats i kvarvarande uppgifter. -
numNewListedFiles: Antal Delta Lake-filer som anges för att beräkna kvarvarande uppgifter för den här batchen. -
backlogEndOffset: Delta-tabellversionen som används för att beräkna backloggen.
I en anteckningsbok visas dessa mätvärden under fliken Rådata i instrumentpanelen för strömningsfrågans framsteg:
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
Tilläggsläge
Som standard körs strömmar i tilläggsläge och lägger bara till nya poster i tabellen.
toTable Använd metoden vid direktuppspelning till tabeller:
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Fullständigt läge
Använd Strukturerad direktuppspelning med fullständigt läge för att ersätta hela tabellen efter varje batch. Du kan till exempel kontinuerligt uppdatera en aggregerad sammanfattningstabell över händelser per kund:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
För program utan strikta svarstidskrav kan du spara databehandlingsresurser och kostnader med engångsutlösare som AvailableNow. Använd till exempel den här utlösaren för att uppdatera sammanfattningsaggregeringstabeller enligt ett visst schema och bearbeta endast nya data som har anlänt sedan den senaste uppdateringen. Se AvailableNow: Inkrementell batchbearbetning.
Hantera ändringar i Delta-källtabeller
Strukturerad direktuppspelning läser inkrementellt Delta-tabeller. När en strömmande fråga läser från en Delta-tabell bearbetas nya poster på ett idempotent sätt när nya tabellversioner bekräftas i källtabellen. Strukturerad direktuppspelning accepterar endast tilläggsindata och utlöser ett undantag om några ändringar görs i delta-källtabellen. Till exempel, om en UPDATE, DELETE, MERGE INTO eller OVERWRITE ändrar en Delta-källtabell som läses av en strömmande fråga, kommer strömmen att misslyckas och generera ett fel.
Det finns fyra vanliga metoder för att hantera överordnade ändringar i Delta-källtabeller, beroende på ditt användningsfall. En referenstabell och information om var och en finns nedan:
| Tillvägagångssätt | Fördelar | Nackdelar |
|---|---|---|
skipChangeCommits |
Enkelt, kräver inte att du skriver komplex logik. Användbart för endast tilläggsbearbetning där uppströms ändringar hanteras separat eller för att tillfälligt hantera en problematisk post. | Sprider inte ändringar och bearbetar endast tillägg. |
| Fullständig uppdatering | Också enkelt, kräver inte att du skriver komplex logik. Användbart för små datauppsättningar med sällsynta överordnade ändringar. | Dyrt för stora datamängder. Kräver ombearbetning av alla underordnade tabeller. |
| Ändra dataflöde | Bearbeta alla ändringstyper (infogningar, uppdateringar och borttagningar). Databricks rekommenderar att du strömmar från CDC-flödet i en Delta-tabell i stället för direkt från tabellen när det är möjligt. | Kräver att du skriver mer komplex logik för att hantera varje ändringstyp. |
| Materialiserade vyer | Enkelt alternativ till strukturerad direktuppspelning som har automatisk ändringsspridning. | Högre svarstid. Endast tillgängligt i Lakeflow Spark Deklarativa pipelines och Databricks SQL. |
Hoppa över uppströms ändringskommandon med skipChangeCommits
Ange skipChangeCommits att ignorera transaktioner som tar bort eller ändrar befintliga poster och att endast bearbeta tillägg. Detta är användbart när ändringar i befintliga data inte behöver spridas via dataströmmen, eller när du föredrar separat logik för att hantera dessa ändringar. Du kan aktivera och inaktivera skipChangeCommits om du tillfälligt behöver ignorera engångsändringar.
Databricks rekommenderar att du använder skipChangeCommits för de flesta arbetsbelastningar som inte använder ändringsdataflöden.
Python
(spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
)
Scala
spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
Important
Om schemat för en Delta-tabell ändras efter att en direktuppspelningsläsning börjar mot tabellen misslyckas frågan. För de flesta schemaändringar kan du starta om strömmen för att lösa matchningsfel för schema och fortsätta bearbetningen.
I Databricks Runtime 12.2 LTS och nedan kan du inte strömma från en Delta-tabell med kolumnmappning aktiverat som har genomgått icke-additiv schemautveckling som att byta namn på eller släppa kolumner. Mer information finns i Kolumnmappning och strömning.
Note
I Databricks Runtime 12.2 LTS och senare skipChangeCommits ersätter ignoreChanges. I Databricks Runtime 11.3 LTS och lägre ignoreChanges är det enda alternativet som stöds. För mer information, se Alternativ för äldre version: ignoreChanges.
Äldre alternativ: ignoreDeletes
ignoreDeletes är ett äldre alternativ som endast hanterar transaktioner som tar bort data vid partitionsgränser (dvs. fullständiga partitionsborttagningar). Om du behöver hantera borttagningar utanför partitioner, uppdateringar eller andra ändringar, använd i stället skipChangeCommits.
Python
(spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
)
Scala
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
Äldre alternativ: ignoreChanges
ignoreChanges finns i Databricks Runtime 11.3 LTS och lägre. I Databricks Runtime 12.2 LTS och senare ersätts det med skipChangeCommits.
Med ignoreChanges aktiverad genereras omskrivna datafiler i källtabellen igen efter en dataändringsåtgärd som UPDATE, MERGE INTO, DELETE (inom partitioner) eller OVERWRITE. Eftersom oförändrade rader ofta genereras tillsammans med nya rader måste mottagarna nedströms kunna hantera dubbletter. Raderingar sprids inte nedströms.
ignoreChanges har företräde framför ignoreDeletes.
Däremot skipChangeCommits bortser från filförändrande operationer helt och hållet. Omskrivna datafiler i källtabellen på grund av dataändringsåtgärder som UPDATE, MERGE INTO, DELETEoch OVERWRITE ignoreras helt. För att återspegla ändringar i dataströmkälltabeller måste du implementera separat logik för att sprida dessa ändringar.
Databricks rekommenderar att du använder skipChangeCommits för alla nya arbetsbelastningar. Om du vill migrera en arbetsbelastning från ignoreChanges till skipChangeCommitsomstrukturerar du din strömningslogik.
Fullständig uppdatering av underordnade tabeller
Om överordnade ändringar är sällsynta och data är tillräckligt små för att bearbetas, kan du ta bort kontrollpunkten för direktuppspelning och utdatatabellen och sedan starta om strömmen från början. Detta gör att strömmen bearbetar om alla data från källtabellen. Tänk på att den här metoden också kräver ombearbetning av alla underordnade tabeller som är beroende av strömmens utdata.
Den här metoden passar bäst för mindre datauppsättningar eller arbetsbelastningar där överordnade ändringar är ovanliga och kostnaden för en fullständig uppdatering är acceptabel.
Använda ändringsdataflöde
För arbetsbelastningar som bearbetar alla typer av ändringar (infogningar, uppdateringar och borttagningar) använder du dataflödet för Delta Lake-ändringar. Ändringsdataflödet registrerar ändringar på radnivå i en Delta-tabell, så att du kan strömma dessa ändringar och skriva logik för att hantera varje ändringstyp i underordnade tabeller. Det här är den mest robusta metoden eftersom koden uttryckligen hanterar alla typer av ändringshändelser. Se Använd Delta Lake-ändringsdataflöde på Azure Databricks.
Om du använder Lakeflow Spark Deklarativa pipelines kan du läsa API :er för AUTOMATISK CDC: Förenkla insamling av ändringsdata med pipelines.
Important
I Databricks Runtime 12.2 LTS och nedan kan du inte strömma från ändringsdataflödet för en Delta-tabell med kolumnmappning aktiverat som har genomgått icke-additiv schemautveckling, till exempel byta namn på eller släppa kolumner. Se Kolumnmappning och strömning.
Använd materialiserade vyer
Materialiserade vyer hanterar automatiskt överordnade ändringar genom att omberäkna resultat när källdata ändras. Om du inte behöver minsta möjliga svarstid och vill undvika att hantera strömningskomplexitet kan en materialiserad vy förenkla din arkitektur. Materialiserade vyer är tillgängliga i Lakeflow Spark deklarativa pipelines och i Databricks SQL. Se även Materialiserade vyer.
Example
Anta till exempel att du har en tabell user_events med date, user_emailoch action kolumner som partitioneras av date. Du strömmar ut från tabellen user_events och du måste ta bort data från den på grund av GDPR.
skipChangeCommits gör att du kan ta bort data i flera partitioner (i det här exemplet filtrering på user_email). Använd följande syntax:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
Om du uppdaterar en user_email med UPDATE-instruktionen skrivs filen som innehåller frågan user_email om. Använd skipChangeCommits för att ignorera de ändrade datafilerna.
Databricks rekommenderar att du använder skipChangeCommits i stället för ignoreDeletes om du inte är säker på att borttagningar alltid innebär fullständig borttagning av partitioner.
Använd foreachBatch för idempotent tabellskrivningar
Note
Databricks rekommenderar att du konfigurerar en separat direktuppspelningsskrivning för varje mottagare som du vill uppdatera i stället för att använda foreachBatch. Skrivningar till flera mottagare i foreachBatch minskar parallelliseringen och ökar den totala svarstiden eftersom skrivningar till flera tabeller serialiseras i foreachBatch.
Deltatabeller stöder följande DataFrameWriter alternativ för att göra skrivningar till flera tabeller i foreachBatch idempotenta:
-
txnAppId: En unik sträng som du kan skicka på varje DataFrame-skrivning. Du kan till exempel använda StreamingQuery-ID:t somtxnAppId.txnAppIdkan vara en användargenererad unik sträng och behöver inte vara relaterad till ström-ID:t. -
txnVersion: Ett monotont ökande tal som fungerar som transaktionsversion.
Delta Lake använder txnAppId och txnVersion för att identifiera och ignorera duplicerade skrivningar. När ett fel till exempel avbryter en batchskrivning kan du köra batchen på nytt med samma txnAppId och txnVersion identifiera och ignorera dubbletter på rätt sätt. Se Använd foreachBatch för att skriva till vilka som helst datamottagare.
Warning
Om du tar bort kontrollpunkten för direktuppspelning och startar om frågan med en ny kontrollpunkt måste du ange en annan txnAppId. Nya kontrollpunkter börjar med ett batch-ID för 0. Delta Lake använder batch-ID och txnAppId som en unik nyckel och hoppar över batchar med redan sedda värden.
Följande kodexempel visar det här mönstret:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}
Upsert från strömmande förfrågningar med hjälp av foreachBatch
Du kan använda merge och foreachBatch för att skriva komplexa upserts från en strömmande fråga till en Delta-tabell. Se Använd foreachBatch för att skriva till vilka som helst datamottagare.
Den här metoden har många användningsområden.
- Förbättra skrivprestandan med
updateutdataläget, medancompleteutdataläget kräver att hela resultattabellen skrivs om för varje mikrobatch. - Tillämpa kontinuerligt en följd av ändringar i en Delta-tabell genom att använda en sammanslagningsfråga för att skriva ändringsdata i
foreachBatch. Se Långsamt föränderliga data (SCD) och ändringsuppföljning av data (CDC) med Delta Lake. - Hantera deduplicering vid dataströmbearbetning. Du kan använda en merge-fråga med enbart infogning i
foreachBatchför att kontinuerligt skriva data till en Delta table med automatisk deduplicering. Se Datadeduplicering när du skriver till Delta-tabeller.
Note
Kontrollera att ditt
mergeuttryck inutiforeachBatchär idempotent. Annars kan omstarter av strömningsfrågan tillämpa åtgärden på samma databatch flera gånger. Se AnvändforeachBatchför idempotent tabellskrivningar.När
mergeanvänds iforeachBatchkan datahastighetsmåttet för indata returnera en multipel av den faktiska hastighet som data genereras vid källan.mergeläser indata flera gånger, vilket multiplicerar måtten. Om du vill förhindra multiplikation av mått cachelagrade du batchdataramen föremergeoch tar sedan bort den eftermerge.Indatahastigheten är tillgänglig via
StreamingQueryProgressoch i diagrammet för strömmande hastighet för notebook. Se Övervaka strukturerade strömningsfrågor på Azure Databricks.
Du kan till exempel använda MERGE SQL-instruktioner i foreachBatch:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Du kan också använda Delta Lake-API:er för strömmande upserts:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Ange den första tabellversionen för att bearbeta ändringar
Som standard börjar strömmarna med den senaste tillgängliga Delta-tabellversionen. Detta inkluderar en fullständig ögonblicksbild av tabellen vid den tidpunkten och alla framtida ändringar. Databricks rekommenderar att du använder den ursprungliga standardtabellversionen för de flesta arbetsbelastningar.
Du kan också använda följande alternativ för att ange startpunkten för Delta Lake-strömningskällan utan att bearbeta hela tabellen.
startingVersion: Delta-tabellversionen som du vill börja läsa från. Alla tabelländringar som har lagts till vid eller efter den angivna versionen läses av dataströmmen. Om den angivna versionen inte är tillgänglig startar inte strömmen.Om du vill hitta tillgängliga incheckningsversioner, kör du
DESCRIBE HISTORYoch kontrollerarversion. Om du bara vill returnera de senaste ändringarna anger dulatest. Information om Delta-tabellversioner finns i Arbeta med tabellhistorik.startingTimestamp: Tidsstämpeln som du vill börja läsa från. Alla tabelländringar som har bekräftats vid eller efter den angivna tidsstämpeln läses av strömmen. Om den angivna tidsstämpeln föregår alla tabellåtaganden börjar strömningsläsningen med den tidigaste tillgängliga tidsstämpeln. Ange antingen:- En sträng som representerar en tidsstämpel. Exempel:
"2019-01-01T00:00:00.000Z" - En datumsträng. Exempel:
"2019-01-01"
- En sträng som representerar en tidsstämpel. Exempel:
Du kan inte ange både startingVersion och startingTimestamp samtidigt. De här inställningarna gäller endast för nya strömmande frågor. Om en direktuppspelningsfråga har startats och förloppet har registrerats i kontrollpunkten ignoreras dessa inställningar.
Important
Även om du kan starta strömningskällan från en angiven version eller tidsstämpel är schemat för strömningskällan alltid det senaste schemat i Delta-tabellen. Du måste se till att det inte finns någon inkompatibel schemaändring i Delta-tabellen efter den angivna versionen eller tidsstämpeln. Annars kan strömningskällan returnera felaktiga resultat när data läss med ett felaktigt schema.
Example
Anta till exempel att du har en tabell user_events. Om du vill läsa ändringar sedan version 5 använder du:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
Om du vill läsa ändringar sedan 2018-10-18 använder du:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
Bearbeta den första ögonblicksbilden utan att ta bort data
Den här funktionen är tillgänglig på Databricks Runtime 11.3 LTS och senare.
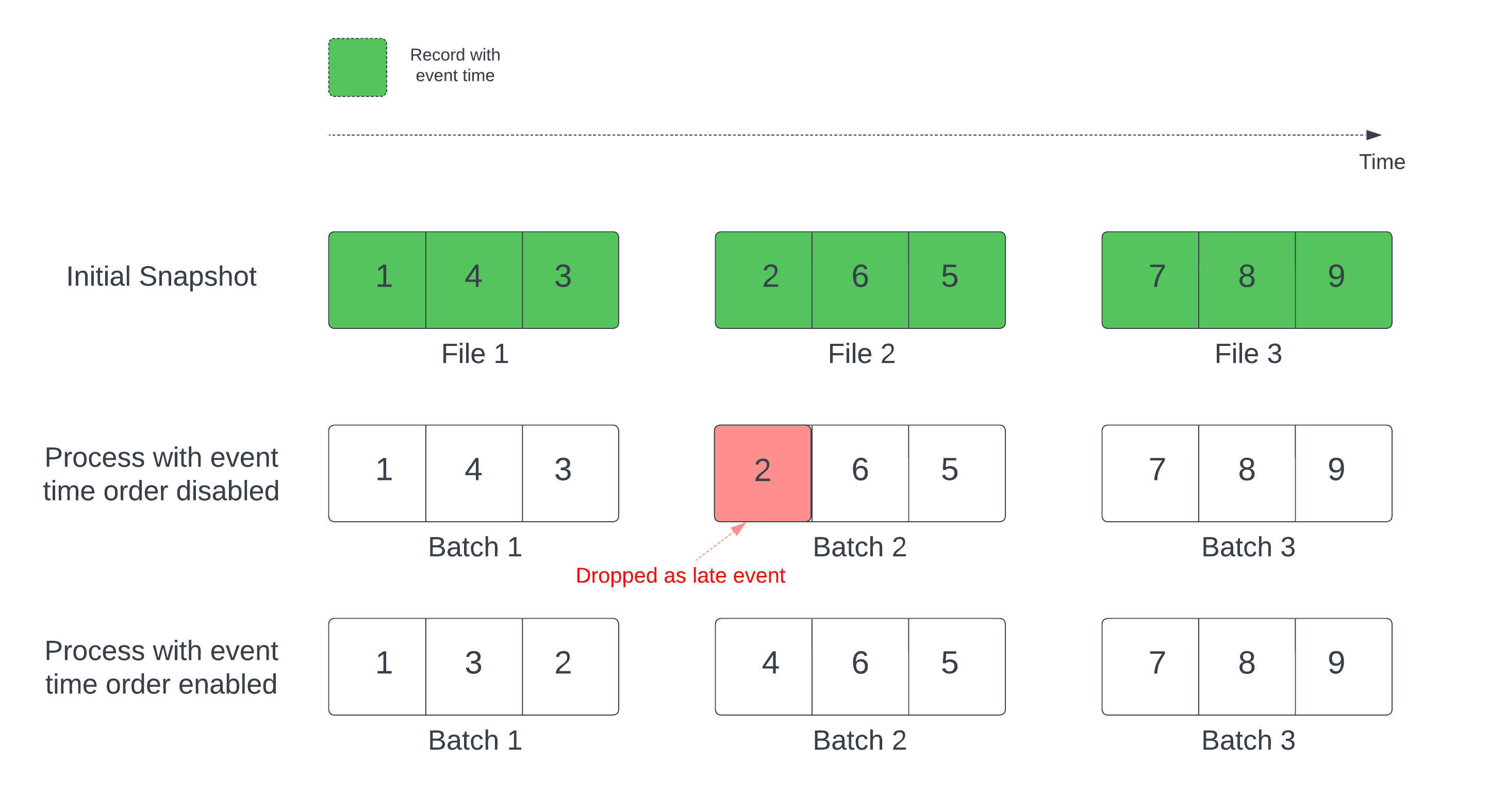
I en tillståndskänslig strömningsfråga med en definierad vattenstämpel kan bearbetning av filer efter ändringstid bearbeta poster i fel ordning. Detta kan göra att vattenstämpeln felaktigt markerar poster som sena händelser och ignorerar dem. Detta kan bara inträffa när den första Delta-ögonblicksbilden bearbetas i standardordningen.
För strömmar med en Delta-källtabell bearbetar frågan först alla data som finns i tabellen och skapar en version som kallas den första ögonblicksbilden. Som standard bearbetas Delta-tabellens datafiler baserat på vilken fil som senast ändrades. Den senaste ändringstiden representerar dock inte nödvändigtvis ordningen av händelser i inspelningen.
Aktivera alternativet withEventTimeOrder för att undvika dataförlust under den initiala bearbetningen av ögonblicksbilder.
withEventTimeOrder delar upp händelsetidsintervallet för initiala ögonblicksbilddata i tids bucketar. Varje mikrobatch bearbetar en bucket genom att filtrera data inom tidsintervallet. Alternativen maxFilesPerTrigger och maxBytesPerTrigger gäller fortfarande för att styra mikrobatchstorleken, men endast ungefär på grund av bearbetningsmetoden.
Följande diagram visar den här processen:
Constraints
- Du kan inte ändra
withEventTimeOrderom dataströmfrågan har startats och den första ögonblicksbilden bearbetas aktivt. Om du vill starta om medwithEventTimeOrderändrat måste du ta bort kontrollpunkten. - Om
withEventTimeOrderär aktiverat kan du inte nedgradera en dataström till en Databricks Runtime-version som inte stöder den här funktionen förrän den första bearbetningen av ögonblicksbilder har slutförts. Om du vill nedgradera väntar du tills den första ögonblicksbilden har slutförts eller tar bort kontrollpunkten och startar om frågan. - Den här funktionen stöds inte i följande scenarier:
- Händelsetidskolumnen är en genererad kolumn och det finns icke-projektiontransformeringar mellan Delta-källan och vattenstämpeln.
- Det finns en vattenstämpel som har mer än en Delta-källa i strömfrågan.
Performance
Om withEventTimeOrder är aktiverat kan prestanda för bearbetning av första ögonblicksbilder vara långsammare. Varje mikrobatch söker igenom den första ögonblicksbilden för att filtrera data inom motsvarande händelsetidsintervall. Så här förbättrar du filtreringsprestandan:
- Använd en Delta-källkolumn som händelsetid så att dataskipping kan tillämpas. Se Hoppa över data.
- Partitionera tabellen längs kolumnen händelsetid.
Använd Spark-användargränssnittet för att se hur många Delta-filer som genomsöks efter en specifik mikrobatch.
Example
Anta att du har en tabell user_events med en event_time kolumn. Din direktuppspelningsfråga är en aggregeringsfråga. Om du vill se till att inga data släpps under den första bearbetningen av ögonblicksbilder kan du använda:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
Du kan ställa in withEventTimeOrder med en Spark-konfiguration i klustret för att tillämpa den på alla strömmande frågor: spark.databricks.delta.withEventTimeOrder.enabled true.
Begränsa indatahastigheten för att förbättra bearbetningsprestanda
Som standard bearbetar Structured Streaming så många filer som möjligt i varje mikrobatch. Använd följande alternativ för att begränsa mängden data som bearbetas per batch och hantera minnesanvändning, stabilisera svarstiden eller minska kostnaderna för molnlagring:
-
maxFilesPerTrigger: Antalet nya filer som ska beaktas i varje mikrobatch. Standardvärdet är 1000. -
maxBytesPerTrigger: Mängden data som bearbetas i varje mikrobatch. Det här alternativet anger ett "mjukt maxvärde", vilket innebär att en batch bearbetar ungefär den här mängden data och kan bearbeta mer än gränsen för att få strömningsfrågan att gå framåt i de fall då den minsta indataenheten är större än den här gränsen. Detta anges inte som standard.
Om du använder både maxBytesPerTrigger och maxFilesPerTriggerbearbetar mikrobatchdata tills antingen maxFilesPerTrigger gränsen eller maxBytesPerTrigger har nåtts.
Note
Som standard, om logRetentionDuration rensar transaktioner i källtabellen och strömningsfrågan försöker bearbeta dessa versioner, misslyckas frågan för att förhindra dataförlust. Du kan ange alternativet failOnDataLoss till false för att ignorera förlorade data och fortsätta bearbetningen. Se Konfigurera datalagring för frågor rörande tidsresor.
Kontrollera kostnaden för molnlagring
Strömningsfrågor har flera tillgängliga utlösarlägen som gör att du kan balansera kostnader och svarstider, inklusive processingTime, availableNowoch realTime. Se Kontrollera kostnaden för molnlagring.