Felsöka och reparera jobbfel
Anta att du har fått ett meddelande (till exempel via ett e-postmeddelande, en övervakningslösning eller i användargränssnittet för Azure Databricks-jobb) om att en uppgift har misslyckats i en körning av ditt Azure Databricks-jobb. Stegen i den här artikeln innehåller vägledning som hjälper dig att identifiera orsaken till felet, förslag för att åtgärda de problem som du hittar och hur du reparerar misslyckade jobbkörningar.
Identifiera orsaken till felet
Så här hittar du den misslyckade uppgiften i användargränssnittet för Azure Databricks-jobb:
Klicka på
 Jobbkörningar i sidofältet.
Jobbkörningar i sidofältet.I kolumnen Namn klickar du på ett jobbnamn. Fliken Körningar visar aktiva körningar och slutförda körningar, inklusive misslyckade körningar. Matrisvyn på fliken Körningar visar en historik över körningar för jobbet, inklusive lyckade och misslyckade körningar för varje jobbaktivitet. En aktivitetskörning kan misslyckas eftersom den misslyckades eller hoppades över på grund av att en beroende uppgift misslyckades. Med hjälp av matrisvyn kan du snabbt identifiera aktivitetsfelen för din jobbkörning.
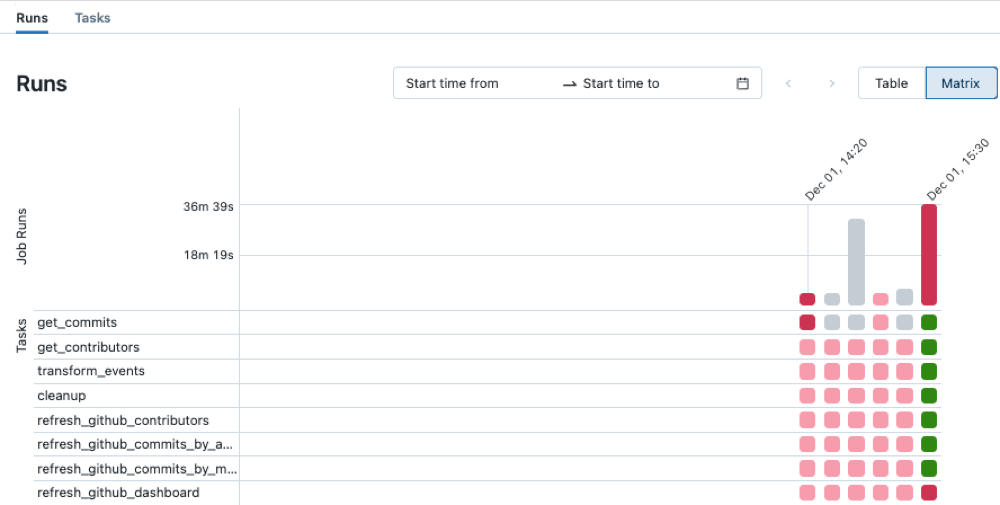
Hovra över en misslyckad uppgift för att se associerade metadata. Dessa metadata innehåller start- och slutdatum, status, varaktighetsklusterinformation och i vissa fall ett felmeddelande.
Klicka på den misslyckade uppgiften för att identifiera orsaken till felet. Sidan Aktivitetskörningsinformation visas och visar aktivitetens utdata, felmeddelande och tillhörande metadata.
Åtgärda orsaken till felet
Din uppgift kan ha misslyckats av flera orsaker, till exempel ett problem med datakvaliteten, en felkonfiguration eller otillräckliga beräkningsresurser. Följande är föreslagna steg för att åtgärda några vanliga orsaker till aktivitetsfel:
- Om felet är relaterat till aktivitetskonfigurationen klickar du på Redigera uppgift. Aktivitetskonfigurationen öppnas på en ny flik. Uppdatera aktivitetskonfigurationen efter behov och klicka på Spara uppgift.
- Om problemet gäller klusterresurser, till exempel otillräckliga instanser, finns det flera alternativ:
- Om ditt jobb har konfigurerats för att använda ett jobbkluster bör du överväga att använda ett delat kluster för alla syften.
- Ändra klusterkonfigurationen. Klicka på Redigera uppgift. I panelen Jobbinformation går du till Beräkning och klickar på Konfigurera för att konfigurera klustret. Du kan ändra antalet arbetare, instanstyper eller andra konfigurationsalternativ för kluster. Du kan också klicka på Växla för att växla till ett annat tillgängligt kluster. För att säkerställa att du använder tillgängliga resurser optimalt kan du läsa metodtipsen för klusterkonfiguration.
- Om det behövs ber du en administratör att öka resurskvoterna i det molnkonto och den region där arbetsytan distribueras.
- Om felet orsakas av att de maximala samtidiga körningarna överskrids:
- Vänta tills andra körningar har slutförts.
- Klicka på Redigera uppgift. I panelen Jobbinformation klickar du på Redigera samtidiga körningar, anger ett nytt värde för Maximalt antal samtidiga körningar och klickar på Bekräfta.
I vissa fall kan orsaken till ett fel vara uppströms från jobbet. En extern datakälla är till exempel inte tillgänglig. Du kan fortfarande dra nytta av reparationskörningsfunktionen som beskrivs i nästa avsnitt när det externa problemet har lösts.
Omkörningen misslyckades och överhoppade uppgifter
När du har identifierat orsaken till felet kan du reparera misslyckade eller avbrutna jobb med flera aktiviteter genom att bara köra delmängden av misslyckade aktiviteter och beroende aktiviteter. Eftersom lyckade uppgifter och aktiviteter som är beroende av dem inte körs igen minskar den här funktionen den tid och de resurser som krävs för att återställa från misslyckade jobbkörningar.
Du kan ändra jobb- eller aktivitetsinställningarna innan du reparerar jobbkörningen. Misslyckade aktiviteter körs igen med de aktuella jobb- och aktivitetsinställningarna. Om du till exempel ändrar sökvägen till en notebook-fil eller en klusterinställning, körs uppgiften igen med de uppdaterade notebook- eller klusterinställningarna.
Visa historiken för alla aktivitetskörningar på sidan Aktivitetskörningsinformation .
Kommentar
- Om en eller flera uppgifter delar ett jobbkluster skapar en reparationskörning ett nytt jobbkluster. Om den ursprungliga körningen till exempel använde jobbklustret
my_job_clusteranvänder den första reparationskörningen det nya jobbklustretmy_job_cluster_v1, så att du enkelt kan se de kluster- och klusterinställningar som används av den första körningen och eventuella reparationskörningar. Inställningarna förmy_job_cluster_v1är samma som de aktuella inställningarna förmy_job_cluster. - Reparation stöds endast med jobb som samordnar två eller flera uppgifter.
- Värdet Varaktighet som visas på fliken Körningar inkluderar den tid då den första körningen startade fram till den tidpunkt då den senaste reparationskörningen slutfördes. Om en körning till exempel misslyckades två gånger och lyckades på den tredje körningen inkluderar varaktigheten tiden för alla tre körningarna.
Så här reparerar du en misslyckad jobbkörning:
- Klicka på länken för den misslyckade körningen i kolumnen Starttid i tabellen för jobbkörningar eller klicka på den misslyckade körningen i matrisvyn. Sidan Jobbkörningsinformation visas.
- Klicka på Reparera körning. Dialogrutan Reparera jobbkörning visas med en lista över alla misslyckade aktiviteter och eventuella beroende aktiviteter som ska köras igen.
- Om du vill lägga till eller redigera parametrar för de uppgifter som ska repareras anger du parametrarna i dialogrutan Reparationsjobbkörning . Parametrar som du anger i dialogrutan Reparera jobbkörning åsidosätter befintliga värden. Vid efterföljande reparationskörningar kan du returnera en parameter till dess ursprungliga värde genom att rensa nyckeln och värdet i dialogrutan Reparationsjobbkörning .
- Klicka på Reparera körning i dialogrutan Reparationsjobbkörning .
- När reparationskörningen är klar uppdateras matrisvyn med en ny kolumn för den reparerade körningen. Alla misslyckade uppgifter som var röda bör nu vara gröna, vilket indikerar en lyckad körning för hela jobbet.
Visa och hantera kontinuerliga jobbfel
När efterföljande fel i ett kontinuerligt jobb överskrider ett tröskelvärde använder Azure Databricks Jobs exponentiell backoff för att försöka utföra jobbet igen. När ett jobb är i exponentiellt backoff-tillstånd visar ett meddelande i panelen Jobbinformation information, inklusive:
- Antalet efterföljande fel.
- Perioden för att jobbet ska köras utan fel ska anses vara lyckad.
- Tiden före nästa återförsök om ingen körning är aktiv för närvarande.
Om du vill avbryta den aktiva körningen återställer du återförsöksperioden och startar en ny jobbkörning genom att klicka på Starta om körning.
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för