Varför datapipelines?
Azure DevOps Services
Du kan använda datapipelines för att:
- Mata in data från olika datakällor
- Bearbeta och transformera data
- Spara bearbetade data på en mellanlagringsplats som andra kan använda
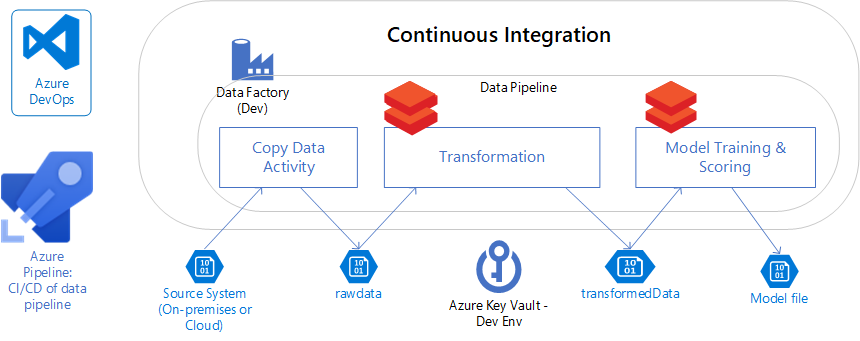
Datapipelines i företaget kan utvecklas till mer komplicerade scenarier med flera källsystem och stöd för olika underordnade program.
Datapipelines tillhandahåller:
- Konsekvens: Datapipelines omvandlar data till ett konsekvent format som användarna kan använda
- Felreducering: Automatiserade datapipelines eliminerar mänskliga fel vid datamanipulering
- Effektivitet: Dataexperter sparar tid på databearbetningstransformering. När du sparar tid kan du sedan fokusera på deras kärnjobbsfunktion – få ut insikter från data och hjälpa företag att fatta bättre beslut
Vad är CI/CD?
Kontinuerlig integrering och kontinuerlig leverans (CI/CD) är en metod för programutveckling där alla utvecklare arbetar tillsammans på en delad lagringsplats med kod – och när ändringar görs sker automatiserad byggprocess för att identifiera kodproblem. Resultatet är en snabbare utvecklingslivscykel och en lägre felfrekvens.
Vad är en CI/CD-datapipeline och varför spelar det någon roll för datavetenskap?
Skapandet av maskininlärningsmodeller liknar traditionell programvaruutveckling i den meningen att dataexperten behöver skriva kod för att träna och poängsätta maskininlärningsmodeller.
Till skillnad från traditionell programvaruutveckling där produkten baseras på kod baseras data science machine learning-modeller på både koden (algoritm, hyperparametrar) och de data som används för att träna modellen. Det är därför de flesta dataexperter kommer att berätta att de ägnar 80 % av tiden åt att förbereda data, rensa och använda funktioner.
För att ytterligare komplicera frågan – för att säkerställa maskininlärningsmodellernas kvalitet används tekniker som A/B-testning. Med A/B-testning kan det finnas flera maskininlärningsmodeller som används samtidigt. Det finns vanligtvis en kontrollmodell och en eller flera behandlingsmodeller för jämförelse – så att modellens prestanda kan jämföras och underhållas. Att ha flera modeller lägger till ytterligare ett lager av komplexitet för CI/CD för maskininlärningsmodeller.
Att ha en CI/CD-datapipeline är avgörande för att data science-teamet ska kunna leverera maskininlärningsmodellerna till verksamheten i tid och på ett kvalitetsmässigt sätt.
Nästa steg
Feedback
Kommer snart: Under hela 2024 kommer vi att fasa ut GitHub-problem som feedbackmekanism för innehåll och ersätta det med ett nytt feedbacksystem. Mer information finns i: https://aka.ms/ContentUserFeedback.
Skicka och visa feedback för