Händelser
17 mars 21 - 21 mars 10
Gå med i mötesserien för att skapa skalbara AI-lösningar baserat på verkliga användningsfall med andra utvecklare och experter.
Registrera dig nuDen här webbläsaren stöds inte längre.
Uppgradera till Microsoft Edge och dra nytta av de senaste funktionerna och säkerhetsuppdateringarna, samt teknisk support.
Azure DevOps Services | Azure DevOps Server 2022 – Azure DevOps Server 2019
Den här artikeln beskriver sekvensen med aktiviteter i Azure Pipelines-pipelinekörningar. En körning representerar en körning av en pipeline. Både pipelines för kontinuerlig integrering (CI) och kontinuerlig leverans (CD) består av körningar. Under en körning bearbetar Azure Pipelines pipelinen och agenter bearbetar ett eller flera jobb, steg och uppgifter.
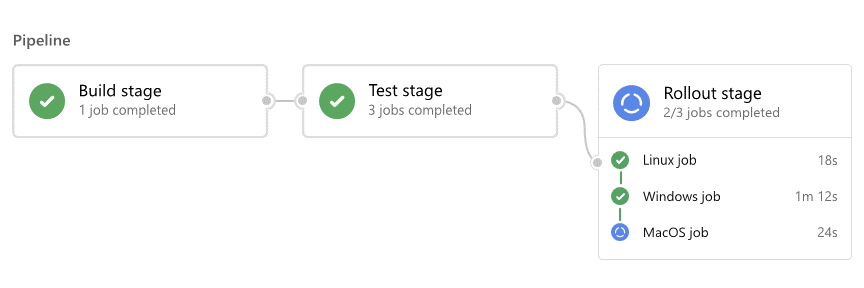
För varje körning, Azure Pipelines:
För varje jobb, en agent:
Jobb kan lyckas, misslyckas, avbrytas eller inte slutföras. Att förstå dessa resultat kan hjälpa dig att felsöka problem.
I följande avsnitt beskrivs pipelinekörningsprocessen i detalj.
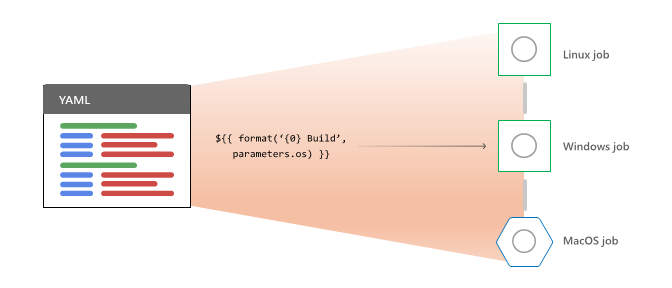
Om du vill bearbeta en pipeline för en körning måste Azure Pipelines först:
För varje steg som den väljer att köra, Azure Pipelines:
Azure Pipelines utför följande aktiviteter för varje jobb som den väljer att köra:
strategy: matrix eller strategy: parallelflera konfigurationer till flera körningsjobb .När körningsjobben har slutförts kontrollerar Azure Pipelines om det finns nya jobb som är berättigade att köras. När faserna är klara kontrollerar Azure Pipelines på samma sätt om det finns fler steg.
Att förstå bearbetningsordningen klargör varför du inte kan använda vissa variabler i mallparametrar. Det första mallexpansionssteget fungerar endast på texten i YAML-filen. Körningsvariabler finns ännu inte under det steget. Efter det steget är mallparametrarna redan lösta.
Du kan inte heller använda variabler för att lösa tjänstanslutnings - eller miljönamn, eftersom pipelinen auktoriserar resurser innan en fas kan börja köras. Variabler på steg- och jobbnivå är inte tillgängliga ännu. Variabelgrupper är själva en resurs som omfattas av auktorisering, så deras data är inte tillgängliga när du kontrollerar resursauktorisering.
Du kan använda variabler på pipelinenivå som uttryckligen ingår i pipelineresursdefinitionen. Mer information finns i Pipeline-resursmetadata som fördefinierade variabler.
När Azure Pipelines behöver köra ett jobb begär den en agent från poolen. Processen fungerar annorlunda för Microsoft-värdbaserade och lokalt installerade agentpooler.
Anteckning
Serverjobb använder inte en pool eftersom de körs på själva Azure Pipelines-servern.
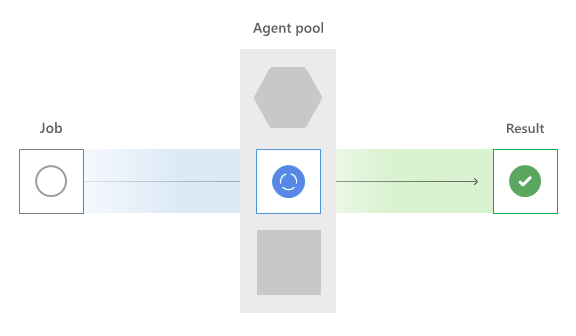
Först kontrollerar Azure Pipelines organisationens parallella jobb. Tjänsten lägger till alla jobb som körs på alla agenter och jämför det med antalet parallella jobb som beviljats eller köpts.
Om det inte finns några tillgängliga parallella platser måste jobbet vänta på ett fack för att frigöra sig. När ett parallellt fack är tillgängligt dirigeras jobbet till lämplig agenttyp.
Konceptuellt är den Microsoft-värdbaserade poolen en global pool med datorer, även om det är fysiskt många olika pooler uppdelade efter geografi och operativsystemtyp. Baserat på det begärda yaml vmImage - eller klassiska redigeringspoolnamnet väljer Azure Pipelines en agent.
Alla agenter i Microsoft-poolen är nya, nya virtuella datorer som aldrig har kört några pipelines. När jobbet är klart tas den virtuella agentdatorn bort.
När en parallell plats är tillgänglig undersöker Azure Pipelines den lokalt installerade poolen efter en kompatibel agent. Lokalt installerade agenter erbjuder funktioner som anger att viss programvara är installerad eller att inställningar har konfigurerats. Pipelinen har krav som är de funktioner som krävs för att köra jobbet.
Om Azure Pipelines inte kan hitta en kostnadsfri agent vars funktioner matchar pipelinens krav fortsätter jobbet att vänta. Om det inte finns några agenter i poolen vars funktioner matchar kraven misslyckas jobbet.
Lokalt installerade agenter återanvänds vanligtvis från körning till körning. För lokalt installerade agenter kan ett pipelinejobb ha biverkningar, till exempel att värma upp cacheminnen eller att de flesta incheckningar redan är tillgängliga på den lokala lagringsplatsen.
När en agent accepterar ett jobb utför den följande förberedelsearbete:
Agenten kör stegen sekventiellt i ordning. Innan ett steg kan starta måste alla föregående steg vara slutförda eller hoppas över.
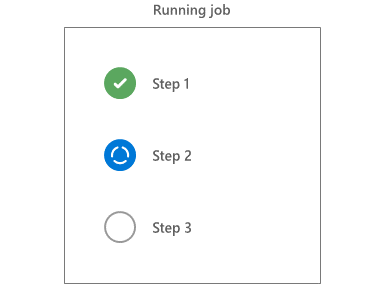
Stegen implementeras av uppgifter som kan vara Node.js, PowerShell eller andra skript. Aktivitetssystemet dirigerar indata och utdata till backningsskripten. Uppgifter tillhandahåller också vanliga tjänster som att ändra systemsökvägen och skapa nya pipelinevariabler.
Varje steg körs i sin egen process och isolerar miljön från föregående steg. På grund av den här modellen för process-per-steg bevaras inte miljövariabler mellan stegen. Uppgifter och skript kan dock använda en mekanism som kallas loggningskommandon för att kommunicera tillbaka till agenten. När en uppgift eller ett skript skriver ett loggningskommando till standardutdata vidtar agenten den åtgärd som kommandot begär.
Du kan använda ett loggningskommando för att skapa nya pipelinevariabler. Pipelinevariabler konverteras automatiskt till miljövariabler i nästa steg. Ett skript kan ange en ny variabel myVar med värdet myValue enligt följande:
echo '##vso[task.setVariable variable=myVar]myValue'
Write-Host "##vso[task.setVariable variable=myVar]myValue"
Varje steg kan rapportera varningar, fel och fel. Steget rapporterar fel och varningar på pipelinesammanfattningssidan genom att markera aktiviteterna som slutförda med problem eller rapporterar fel genom att markera aktiviteten som misslyckad. Ett steg misslyckas om det antingen uttryckligen rapporterar fel med hjälp av ett ##vso kommando eller avslutar skriptet med en icke-nollavslutskod.
När stegen körs skickar agenten hela tiden utdatalinjer till Azure Pipelines, så att du kan se en live-feed för konsolen. I slutet av varje steg laddas hela utdata från steget upp som en loggfil. Du kan ladda ned loggen när pipelinen är klar.
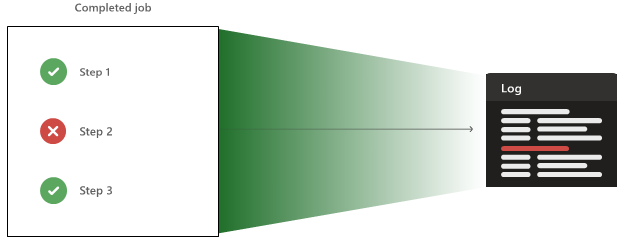
Agenten kan också ladda upp artefakter och testresultat, som också är tillgängliga när pipelinen har slutförts.
Agenten håller reda på att varje steg lyckades eller misslyckades. När stegen lyckas med problem eller misslyckas uppdateras jobbets status. Jobbet återspeglar alltid det sämsta resultatet från vart och ett av stegen. Om ett steg misslyckas misslyckas även jobbet.
Innan agenten kör ett steg kontrollerar den det stegets villkor för att avgöra om steget ska köras. Som standard körs bara ett steg när jobbets status lyckas eller lyckas med problem, men du kan ange andra villkor.
Många jobb har rensningssteg som måste köras oavsett vad som händer, så att de kan ange ett villkor för always(). Rensning eller andra steg kan också ställas in på att endast köras vid annullering.
Ett lyckat rensningssteg kan inte rädda jobbet från att misslyckas. Jobb kan aldrig återgå till framgång efter att fel har angetts.
Varje jobb har en tidsgräns. Om jobbet inte slutförs under den angivna tiden avbryter servern jobbet. Servern försöker signalera att agenten ska stoppas och markerar jobbet som avbrutet. På agentsidan innebär annullering att avbryta alla återstående steg och ladda upp eventuella återstående resultat.
Jobben har en respitperiod som kallas tidsgränsen för avbokning för att slutföra ett annulleringsarbete. Du kan också markera steg som ska köras även vid annullering. Om agenten inte rapporterar att arbetet har stoppats efter en timeout för jobbet plus tidsgränsen för avbrutet markerar servern jobbet som ett fel.
Agentdatorer kan sluta svara på servern om agentens värddator förlorar ström eller är avstängd, eller om det uppstår ett nätverksfel. För att identifiera dessa villkor skickar agenten ett pulsslagsmeddelande en gång per minut för att låta servern veta att den fortfarande fungerar.
Om servern inte får pulsslag fem minuter i rad förutsätter det att agenten inte kommer tillbaka. Jobbet markeras som ett fel och låter användaren veta att de ska försöka pipelinen igen.
Du kan hantera pipelinekörningar med az pipelines-körningar i Azure DevOps CLI. Kom igång genom att läsa Kom igång med Azure DevOps CLI. En fullständig kommandoreferens finns i Kommandoreferens för Azure DevOps CLI.
Följande exempel visar hur du använder Azure DevOps CLI för att lista pipelinekörningarna i projektet, visa information om en specifik körning och hantera taggar för pipelinekörningar.
az loginaz devops configure --defaults organization=<YourOrganizationURL>av .Lista pipelinekörningarna i projektet med kommandot az pipelines runs list .
Följande kommando visar de tre första pipelinekörningarna som har statusen slutförd och resultatet lyckades och returnerar resultatet i tabellformat.
az pipelines runs list --status completed --result succeeded --top 3 --output table
Run ID Number Status Result Pipeline ID Pipeline Name Source Branch Queued Time Reason
-------- ---------- --------- --------- ------------- -------------------------- --------------- -------------------------- ------
125 20200124.1 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 18:56:10.067588 manual
123 20200123.2 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 11:55:56.633450 manual
122 20200123.1 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 11:48:05.574742 manual
Visa information om en pipelinekörning i projektet med kommandot az pipelines runs show .
Följande kommando visar information om pipelinekörningen med ID 123, returnerar resultatet i tabellformat och öppnar webbläsaren till resultatsidan för Azure Pipelines-versionen.
az pipelines runs show --id 122 --open --output table
Run ID Number Status Result Pipeline ID Pipeline Name Source Branch Queued Time Reason
-------- ---------- --------- --------- ------------- -------------------------- --------------- -------------------------- --------
123 20200123.2 completed succeeded 12 Githubname.pipelines-java master 2020-01-23 11:55:56.633450 manual
Lägg till en tagg i en pipelinekörning i projektet med kommandot az pipelines runs runs add .
Följande kommando lägger till taggen YAML i pipelinekörningen med ID 123 och returnerar resultatet i JSON-format.
az pipelines runs tag add --run-id 123 --tags YAML --output json
[
"YAML"
]
Lista taggarna för en pipelinekörning i projektet med kommandot az pipelines runs tag list . Följande kommando visar taggarna för pipelinekörningen med ID 123 och returnerar resultatet i tabellformat.
az pipelines runs tag list --run-id 123 --output table
Tags
------
YAML
Ta bort en tagg från en pipelinekörning i projektet med kommandot az pipelines runs tag delete . Följande kommando tar bort YAML-taggen från pipelinekörningen med ID 123.
az pipelines runs tag delete --run-id 123 --tag YAML
Händelser
17 mars 21 - 21 mars 10
Gå med i mötesserien för att skapa skalbara AI-lösningar baserat på verkliga användningsfall med andra utvecklare och experter.
Registrera dig nuUtbildning
Certifiering
Microsoft-certifierad: DevOps-teknikerexpert - Certifications
Den här certifieringen mäter din förmåga att utföra följande tekniska uppgifter: Utforma och implementera processer och kommunikation, utforma och implementera en källkontrollstrategi, utforma och implementera bygg- och versionspipelines, utveckla en säkerhets- och efterlevnadsplan och implementera en instrumenteringsstrategi.
Dokumentation
Ny användarhandbok för Azure Pipelines – viktiga begrepp - Azure Pipelines
Lär dig hur Azure Pipelines fungerar med din kod och dina verktyg för att automatisera bygget och distributionen samt de viktigaste begreppen bakom den.
Redigeringsguide för YAML-pipeline - Azure Pipelines
Lär dig hur du skapar och redigerar pipelines med YAML-pipelineredigeraren.
YAML jämfört med klassiska pipelines - Azure Pipelines
Lär dig grunderna om Azure Pipelines och utforska de olika funktionerna som är tillgängliga för både YAML- och klassiska pipelines.