Kommentar
Åtkomst till den här sidan kräver auktorisering. Du kan prova att logga in eller ändra kataloger.
Åtkomst till den här sidan kräver auktorisering. Du kan prova att ändra kataloger.
Azure DevOps Services | Azure DevOps Server | Azure DevOps Server 2022
Variabler är ett bekvämt sätt att inkludera viktiga data i olika delar av pipelinen. Den vanligaste användningen av variabler är att definiera ett värde som du kan använda i hela pipelinen. Alla variabler är strängar och är föränderliga. Värdet för en variabel kan ändras från körning till körning eller jobb till jobb i pipelinen.
När du definierar samma variabel på flera platser med samma namn har den mest lokalt begränsade variabeln företräde. Därför kan en variabel som definierats på jobbnivå åsidosätta en variabeluppsättning på stegnivå. En variabel som definieras på stegnivå åsidosätter en variabel som är satt på pipelinens rot-nivå. En variabeluppsättning som anges på pipeline-rot-nivån åsidosätter en variabeluppsättning i användargränssnittet för pipelineinställningar. Mer information om hur du arbetar med variabler som definierats på jobb-, fas- och rotnivå finns i Variabelomfång.
Du kan använda variabler med expressions för att villkorligt tilldela värden och ytterligare anpassa pipelines.
Variablerna skiljer sig från körningsparametrar. Körningsparametrar skrivs och är tillgängliga under mallparsning.
Användardefinierade variabler
När du definierar en variabel använder du olika typer av syntax (makro, malluttryck eller körningstid). Den syntax du väljer avgör var i pipelinen variabeln återges.
I YAML-pipelines anger du variabler på rot-, fas- och jobbnivåerna. Du kan också ange variabler utanför en YAML-pipeline i användargränssnittet. När du anger en variabel i användargränssnittet kan du kryptera variabeln och ange den som hemlig.
Användardefinierade variabler kan anges som skrivskyddade. Det finns namngivningsbegränsningar för variabler (till exempel: du kan inte använda secret i början av ett variabelnamn).
Du kan använda en variabelgrupp för att göra variabler tillgängliga i flera pipelines.
Om du vill definiera variabler i en fil för användning i flera pipelines använder du templates.
Användardefinierade flerradsvariabler
Azure DevOps stöder flerradsvariabler, men det finns några begränsningar.
Underordnade komponenter, till exempel pipelineuppgifter, kanske inte hanterar variabelvärdena korrekt.
Azure DevOps ändrar inte användardefinierade variabelvärden. Du måste formatera variabelvärden korrekt innan du skickar dem som flerradsvariabler. När du formaterar variabeln bör du undvika specialtecken, inte använda begränsade namn och se till att du använder ett radslutformat som fungerar för agentens operativsystem.
Flerradsvariabler fungerar annorlunda beroende på operativsystemet. Undvik det här problemet genom att se till att du formaterar flerradsvariabler korrekt för måloperativsystemet.
Azure DevOps ändrar aldrig variabelvärden, även om du tillhandahåller formatering som inte stöds.
Systemvariabler
Förutom användardefinierade variabler har Azure Pipelines systemvariabler med fördefinierade värden. Den fördefinierade variabeln Build.BuildId ger till exempel ID:t för varje version och kan användas för att identifiera olika pipelinekörningar. Du kan använda variabeln Build.BuildId i skript eller uppgifter när du behöver ett unikt värde.
Om du använder YAML eller de klassiska versionspipelines kan du läsa fördefinierade variabler för en omfattande lista över systemvariabler.
Om du använder klassiska release pipelines kan du läsa om release variables.
När du kör pipelinen anger systemvariablerna sitt aktuella värde. Vissa variabler anges automatiskt. Som pipelineförfattare eller slutanvändare kan du ändra värdet för en systemvariabel innan pipelinen körs.
Systemvariabler är endast läsbara.
Miljövariabler
Miljövariabler är specifika för det operativsystem som du använder. Du matar in dem i en pipeline på plattformsspecifika sätt. Formatet motsvarar hur miljövariabler formateras för din specifika skriptplattform.
I UNIX-system (macOS och Linux) har miljövariabler formatet $NAME. I Windows är %NAME% formatet för batch och $env:NAME i PowerShell.
System- och användardefinierade variabler (förutom hemliga variabler) matas också in som miljövariabler för din plattform. När variabler konverteras till miljövariabler blir variabelnamn stora bokstäver och punkter blir till understreck. Variabelnamnet any.variable blir till exempel variabelnamnet $ANY_VARIABLE.
Det finns begränsningar för variabelnamngivning för miljövariabler (exempel: du kan inte använda secret i början av ett variabelnamn).
Begränsningar för variabelnamngivning
Användardefinierade variabler och miljövariabler kan bestå av bokstäver, siffror och ._ tecken. Använd inte variabelprefix som är reserverade av systemet. Dessa prefix är: endpoint, input, secret, pathoch securefile. Alla variabler som börjar med en av dessa strängar (oavsett användning av versaler) kommer inte att vara tillgängliga för dina uppgifter och skript. Använd inte blanksteg i variabler. Ytterligare begränsningar finns i Azure Pipelines namngivningsbegränsningar.
Förstå variabelsyntax
Azure Pipelines har stöd för tre olika sätt att referera till variabler: makro, malluttryck och körningsuttryck. Du kan använda varje syntax för olika syften och var och en har vissa begränsningar.
I ett pipeline bearbetas malluttrycksvariabler (${{ variables.var }}) vid kompileringstid, innan programmet körs. Makrosyntaxvariabler ($(var)) bearbetas under körningen innan en aktivitet körs. Körningsuttryck ($[variables.var]) bearbetas även under runtime men är avsedda att användas med villkor och uttryck. När du använder ett körningsuttryck måste det uppta hela den högra sidan av en definition.
I det här exemplet kan du se att malluttrycket fortfarande har det ursprungliga värdet för variabeln när variabeln har uppdaterats. Värdet för makrosyntaxvariabeln uppdateras. Malluttrycksvärdet ändras inte eftersom pipelinen bearbetar alla malluttrycksvariabler vid kompileringstiden innan aktiviteterna körs. Däremot utvärderas makrosyntaxvariabler innan varje aktivitet körs.
variables:
- name: one
value: initialValue
steps:
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one)
displayName: First variable pass
- bash: echo "##vso[task.setvariable variable=one]secondValue"
displayName: Set new variable value
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one) # outputs secondValue
displayName: Second variable pass
Makrosyntaxvariabler
De flesta dokumentationsexempel använder makrosyntax ($(var)). Använd makrosyntax för att interpolera variabelvärden i aktivitetsindata och till andra variabler.
Systemet bearbetar variabler med makrosyntax innan en aktivitet körs under körningen. Exekvering sker efter mallexpansion. När systemet stöter på ett makrouttryck ersätter det uttrycket med innehållet i variabeln. Om det inte finns någon variabel med det namnet ändras inte makrouttrycket. Om det till exempel inte går att ersätta $(var) förblir det som $(var).
Makrosyntaxvariabler förblir oförändrade när de inte har något värde eftersom ett tomt värde som $() kan betyda något för den aktivitet som du kör och agenten inte bör anta att du vill att värdet ska ersättas. Om du till exempel använder $(foo) för att referera till variabeln foo i en Bash-uppgift kan dina Bash-script brytas genom att ersätta alla $()-uttryck i indata till uppgiften.
Makrovariabler expanderas bara när de används för ett värde, inte som ett nyckelord. Värden visas till höger i en pipelinedefinition. Följande är giltigt: key: $(value). Följande är inte giltigt: $(key): value. Makrovariabler utvidgas inte när de används för att visa ett jobbnamn i löpande text. I stället måste du använda egenskapen displayName .
Anteckning
Systemet expanderar bara makrosyntaxvariabler för uppgiftsindata i stages, jobsoch steps.
De expanderas inte i pipeline-nyckelord som löses vid kompileringstidpunkt, till exempel resources, triggereller checkout stegets databasreferensvärde (till exempel checkout: git://MyProject/MyRepo@$(var) fungerar inte).
Om du vill parametrisera dessa värden använder du malluttryck (${{ }}) eller körningsparametrar i stället.
I det här exemplet används makrosyntax med Bash, PowerShell och en skriptaktivitet. Syntaxen för att anropa en variabel med hjälp av makrosyntax är densamma för alla tre.
variables:
- name: projectName
value: contoso
steps:
- bash: echo $(projectName)
- powershell: echo $(projectName)
- script: echo $(projectName)
Syntax för malluttryck
Använd malluttryckssyntax för att expandera både mallparametrar och variabler (${{ variables.var }}). Systemet bearbetar mallvariabler vid kompileringstillfället och ersätter dem innan körningen startar. Använd malluttryck för att återanvända delar av YAML som mallar.
Mallvariabler slås tyst samman till tomma strängar när ett ersättningsvärde inte hittas. Malluttryck, till skillnad från makro- och körningsuttryck, kan visas som antingen nycklar (vänster sida) eller värden (höger sida). Följande är giltigt: ${{ variables.key }} : ${{ variables.value }}.
Körningstidsuttryckssyntax
Använd körningsuttryckssyntax för variabler som expanderar vid körning ($[variables.var]). Körningsuttrycksvariabler sammanfogas tyst till tomma strängar när ett ersättningsvärde inte hittas. Använd körningsuttryck i jobbvillkor för att stödja villkorsstyrd körning av jobb eller hela faser.
Körningsuttrycksvariabler expanderas bara när de används för ett värde, inte som ett nyckelord. Värden visas till höger i en pipelinedefinition. Följande är giltigt: key: $[variables.value]. Följande är inte giltigt: $[variables.key]: value. Körningsuttrycket måste ta upp hela högerdelen av ett nyckel-värdepar. Till exempel är key: $[variables.value] giltigt men key: $[variables.value] foo är inte det.
| Syntax | Exempel | När bearbetas den? | Var expanderar det i en pipelinedefinition? | Hur visas det när det inte hittas? |
|---|---|---|---|---|
| makro | $(var) |
körningstid innan en uppgift exekveras | värde (höger sida) | Utskrifter $(var) |
| template-uttryck | ${{ variables.var }} |
kompileringstid | nyckel eller värde (vänster eller höger sida) | tom sträng |
| körtidsuttryck | $[variables.var] |
Körtid | värde (höger sida) | tom sträng |
Vilken syntax ska jag använda?
Använd makrosyntax om du tillhandahåller en säker sträng eller en fördefinierad variabel som inmatning för en uppgift.
Välj uttryck under körning om du hanterar villkor och uttryck. Använd dock inte ett runtime-uttryck om du inte vill att den tomma variabeln ska visas (exempel: $[variables.var]). Om du till exempel har villkorsstyrd logik som förlitar sig på en variabel som har ett visst värde eller inget värde använder du ett makrouttryck.
Vanligtvis är en mallvariabel standard att använda. Genom att använda mallvariabler matar pipelinen helt in variabelvärdet i din pipeline vid pipelinekompilering. Den här injektionen är användbar när man försöker felsöka pipelines. Du kan ladda ned loggfilerna och utvärdera det fullständigt expanderade värde som ersätts i. Eftersom variabeln ersätts i ska du inte använda mallsyntax för känsliga värden.
Använda AI för att identifiera problem med variabelsyntax
Den här exempelprompten för Copilot Chat identifierar vilka typer av variabler som används i en pipeline och när variablerna löses. Markera DIN YAML-kod och ange sedan följande Copilot Chat-prompt.
What types of Azure DevOps variables are used in this YAML pipeline? Give specific examples.
When does each variable process in the pipeline?
How will each variable render when not found?
What stages and jobs will the variables be available for?
Anpassa uppmaningen för att lägga till detaljer efter behov.
Copilot drivs av AI, så överraskningar och misstag är möjliga. Mer information finns i Copilot FAQ.
Ange variabler i pipeline
I det vanligaste fallet anger du variablerna och använder dem i YAML-filen. Med den här metoden kan du spåra ändringar i variabeln i versionskontrollsystemet. Du kan också definiera variabler i användargränssnittet för pipelineinställningar (se fliken Klassisk) och referera till dem i YAML.
I följande exempel visas hur du anger två variabler configuration och platformoch använder dem senare i steg. Om du vill använda en variabel i en YAML-instruktion omsluter du den i $(). Du kan inte använda variabler för att definiera en repository i en YAML-instruktion.
# Set variables once
variables:
configuration: debug
platform: x64
steps:
# Use them once
- task: MSBuild@1
inputs:
solution: solution1.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
# Use them again
- task: MSBuild@1
inputs:
solution: solution2.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
Variabelomfång
I YAML-filen anger du en variabel i olika omfång:
- På grundnivå gör du det tillgängligt för alla jobb i pipelinen.
- På fasnivå, för att göra den endast tillgänglig för ett specifikt steg.
- På jobbnivå kan du göra det tillgängligt bara för ett specifikt jobb.
När du definierar en variabel överst i en YAML är variabeln tillgänglig för alla jobb och steg i pipelinen och är en global variabel. Globala variabler som definierats i en YAML visas inte i användargränssnittet för pipelineinställningar.
Variabler på jobbnivå åsidosätter variabler på rot- och stegnivå. Variabler på fasnivå åsidosätter variabler på rotnivå.
variables:
global_variable: value # this is available to all jobs
jobs:
- job: job1
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable1: value1 # this is only available in job1
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable1)
- bash: echo $JOB_VARIABLE1 # variables are available in the script environment too
- job: job2
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable2: value2 # this is only available in job2
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable2)
- bash: echo $GLOBAL_VARIABLE
Utdata från båda jobben ser ut så här:
# job1
value
value1
value1
# job2
value
value2
value
Ange variabler
I föregående exempel följs nyckelordet variables av en lista över nyckel/värde-par.
Nycklarna är variabelnamnen och värdena är variabelvärdena.
En annan syntax är användbar när du vill använda mallar för variabler eller variabelgrupper.
Med hjälp av mallar kan du definiera variabler i en YAML-fil och inkludera dem i en annan YAML-fil.
Variabelgrupper är en uppsättning variabler som du kan använda i flera pipelines. Med hjälp av variabelgrupper kan du hantera och organisera variabler som är gemensamma för olika faser på ett och samma ställe.
Använd den här syntaxen för variabelmallar och variabelgrupper på rotnivån för en pipeline.
I den här alternativa syntaxen tar nyckelordet variables en lista över variabelspecificerare.
Variabelspecificerarna är name för en vanlig variabel, group för en variabelgrupp och template för att inkludera en variabelmall.
I följande exempel visas alla tre.
variables:
# a regular variable
- name: myvariable
value: myvalue
# a variable group
- group: myvariablegroup
# a reference to a variable template
- template: myvariabletemplate.yml
Mer information finns i återanvändning av variabler med mallar.
Åtkomst av variabler via miljön
Observera att variabler också görs tillgängliga för skript via miljövariabler. Syntaxen för att använda dessa miljövariabler beror på skriptspråket.
Namnet är i versaler, och . ersätts med _. Detta infogas automatiskt i processmiljön. Nedan följer några exempel:
- Batch-skript:
%VARIABLE_NAME% - PowerShell-skript:
$env:VARIABLE_NAME - Bash-skript:
$VARIABLE_NAME
Viktigt!
Fördefinierade variabler som innehåller filsökvägar översätts till lämplig formatmall (Windows-format C:\foo\ jämfört med Unix-format /foo/) baserat på agentens värdtyp och gränssnittstyp. Om du kör bash-skriptuppgifter i Windows bör du använda miljövariabelmetoden för att komma åt dessa variabler i stället för pipelinevariabelmetoden för att säkerställa att du har rätt formatering av filsökväg.
Ange hemliga variabler
Tips
Hemliga variabler exporteras inte automatiskt som miljövariabler. Om du vill använda hemliga variabler i skripten mappar du dem uttryckligen till miljövariabler. Mer information finns i Ange hemliga variabler.
Ange inte hemliga variabler i YAML-filen. Operativsystem loggar ofta kommandon för de processer som de kör, och du vill inte att loggen ska innehålla en hemlighet som du skickade som indata. Använd skriptets miljö eller mappa variabeln variables i blocket för att skicka hemligheter till din pipeline.
Anteckning
Azure Pipelines gör ett försök att maskera hemligheter när data skickas till pipelineloggar, så du kan se ytterligare variabler och data maskerade i utdata och loggar som inte har angetts som hemligheter.
Du måste ange hemliga variabler i pipelineinställningarnas användargränssnitt för din pipeline. Dessa variabler är begränsade till den pipeline där de definieras. Du kan också ange hemliga variabler i variabelgrupper.
Följ dessa steg för att ange hemligheter i webbgränssnittet:
- Gå till sidan Pipelines, välj lämplig pipeline och välj sedan Edit.
- Leta upp variablerna för den här pipelinen.
- Lägg till eller uppdatera variabeln.
- Välj alternativet för att behålla den här värdehemligheten för att lagra variabeln på ett krypterat sätt.
- Spara pipelinen.
Hemliga variabler krypteras i vila med en 2048-bitars RSA-nyckel. Hemligheter är tillgängliga hos agenten för användning av uppgifter och skript. Var försiktig med vem som har åtkomst för att ändra din pipeline.
Viktigt!
Vi gör ett försök att maskera hemligheter från att visas i Azure Pipelines utdata, men du måste fortfarande vidta försiktighetsåtgärder. Skriv aldrig ut hemligheter som utdata. Vissa operativsystem loggar kommandoradsargument. Skicka aldrig hemligheter på kommandoraden. I stället föreslår vi att du mappar dina hemligheter till miljövariabler.
Vi maskerar aldrig delar av hemligheter. Om till exempel "abc123" anges som en hemlighet maskeras inte "abc" från loggarna. Detta är för att undvika maskering av hemligheter på en för detaljerad nivå, vilket gör loggarna olästa. Därför bör hemligheter inte innehålla strukturerade data. Om till exempel "{ "foo": "bar" }" har angetts som en hemlighet maskeras inte "bar" från loggarna.
Till skillnad från en normal variabel dekrypteras de inte automatiskt till miljövariabler för skript. Du måste uttryckligen mappa hemliga variabler.
I följande exempel visas hur du mappar och använder en hemlig variabel som heter mySecret i PowerShell- och Bash-skript. Två globala variabler definieras.
GLOBAL_MYSECRET tilldelas värdet för en hemlig variabel mySecretoch GLOBAL_MY_MAPPED_ENV_VAR tilldelas värdet för en icke-hemlig variabel nonSecretVariable. Till skillnad från en vanlig pipelinevariabel finns det ingen miljövariabel som heter MYSECRET.
PowerShell-aktiviteten kör ett skript för att skriva ut variablerna.
-
$(mySecret): Detta är en direkt referens till den hemliga variabeln och fungerar. -
$env:MYSECRET: Detta försöker ge åtkomst till den hemliga variabeln som en miljövariabel, men det fungerar inte då hemliga variabler inte automatiskt kopplas till miljövariabler. -
$env:GLOBAL_MYSECRET: Detta försöker access den hemliga variabeln via en global variabel, vilket inte heller fungerar eftersom hemliga variabler inte kan mappas på det här sättet. -
$env:GLOBAL_MY_MAPPED_ENV_VAR: Detta kommer åt den icke-hemliga variabeln via en global variabel, som fungerar. -
$env:MY_MAPPED_ENV_VAR: Detta kommer åt den hemliga variabeln via en aktivitetsspecifik miljövariabel, vilket är det rekommenderade sättet att mappa hemliga variabler till miljövariabler.
variables:
GLOBAL_MYSECRET: $(mySecret) # this will not work because the secret variable needs to be mapped as env
GLOBAL_MY_MAPPED_ENV_VAR: $(nonSecretVariable) # this works because it's not a secret.
steps:
- powershell: |
Write-Host "Using an input-macro works: $(mySecret)"
Write-Host "Using the env var directly does not work: $env:MYSECRET"
Write-Host "Using a global secret var mapped in the pipeline does not work either: $env:GLOBAL_MYSECRET"
Write-Host "Using a global non-secret var mapped in the pipeline works: $env:GLOBAL_MY_MAPPED_ENV_VAR"
Write-Host "Using the mapped env var for this task works and is recommended: $env:MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
- bash: |
echo "Using an input-macro works: $(mySecret)"
echo "Using the env var directly does not work: $MYSECRET"
echo "Using a global secret var mapped in the pipeline does not work either: $GLOBAL_MYSECRET"
echo "Using a global non-secret var mapped in the pipeline works: $GLOBAL_MY_MAPPED_ENV_VAR"
echo "Using the mapped env var for this task works and is recommended: $MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
Utdata från båda aktiviteterna i föregående skript ser ut så här:
Using an input-macro works: ***
Using the env var directly does not work:
Using a global secret var mapped in the pipeline does not work either:
Using a global non-secret var mapped in the pipeline works: foo
Using the mapped env var for this task works and is recommended: ***
Du kan också använda hemliga variabler utanför skript. Du kan till exempel mappa hemliga variabler till aktiviteter med hjälp variables av definitionen. Det här exemplet visar hur du använder hemliga variabler $(vmsUser) och $(vmsAdminPass) i en Azure filkopieringsaktivitet.
variables:
VMS_USER: $(vmsUser)
VMS_PASS: $(vmsAdminPass)
pool:
vmImage: 'ubuntu-latest'
steps:
- task: AzureFileCopy@6
inputs:
SourcePath: 'my/path' # Specify the source path
azureSubscription: 'my-subscription' # Azure subscription name
Destination: 'AzureVMs' # Destination type
storage: 'my-storage' # Azure storage account name
resourceGroup: 'my-resource-group' # Resource group name
vmsAdminUserName: $(VMS_USER) # Admin username for the VM
vmsAdminPassword: $(VMS_PASS) # Admin password for the VM
CleanTargetBeforeCopy: false # Do not clean the target before copying
Referenshemlighetsvariabler i variabelgrupper
Det här exemplet visar hur du refererar till en variabelgrupp i YAML-filen och hur du lägger till variabler i YAML. I exemplet används två variabler från variabelgruppen: user och token. Variabeln token är hemlig och mappas till miljövariabeln $env:MY_MAPPED_TOKEN så att du kan referera till den i YAML.
Denna YAML gör ett REST-anrop för att hämta en lista över versioner och matar ut resultatet.
variables:
- group: 'my-var-group' # variable group
- name: 'devopsAccount' # new variable defined in YAML
value: 'contoso'
- name: 'projectName' # new variable defined in YAML
value: 'contosoads'
steps:
- task: PowerShell@2
inputs:
targetType: 'inline'
script: |
# Encode the Personal Access Token (PAT)
# $env:USER is a normal variable in the variable group
# $env:MY_MAPPED_TOKEN is a mapped secret variable
$base64AuthInfo = [Convert]::ToBase64String([Text.Encoding]::ASCII.GetBytes(("{0}:{1}" -f $env:USER,$env:MY_MAPPED_TOKEN)))
# Get a list of releases
$uri = "https://vsrm.dev.azure.com/$(devopsAccount)/$(projectName)/_apis/release/releases?api-version=5.1"
# Invoke the REST call
$result = Invoke-RestMethod -Uri $uri -Method Get -ContentType "application/json" -Headers @{Authorization=("Basic {0}" -f $base64AuthInfo)}
# Output releases in JSON
Write-Host $result.value
env:
MY_MAPPED_TOKEN: $(token) # Maps the secret variable $(token) from my-var-group
Viktigt!
Med GitHub repositories kan pull requests som standard inte åtkomma hemliga variabler som har en koppling till din pipeline. Mer information finns i Contributions from forks.
Dela variabler mellan pipelines
Om du vill dela variabler över flera pipelines i project använder du webbgränssnittet. Under Bibliotek använder du variabelgrupper.
Använda utdatavariabler från aktiviteter
Vissa uppgifter definierar utdatavariabler som du kan använda i underordnade steg, jobb och faser. I YAML kan du access variabler mellan jobb och steg med hjälp av beroenden.
När du refererar till matrisjobb i underordnade aktiviteter använder du en annan syntax. Se Ange en utdatavariabel för flera jobb. Du måste också använda en annan syntax för variabler i distributionsjobb. Se Stöd för utdatavariabler i distributionsjobb.
- Om du vill referera till en variabel från en annan aktivitet inom samma jobb använder du
TASK.VARIABLE. - Om du vill referera till en variabel från en aktivitet från ett annat jobb använder du
dependencies.JOB.outputs['TASK.VARIABLE'].
Anteckning
Som standard beror varje steg i en pipeline på den precis före den i YAML-filen. Om du behöver referera till en fas som inte är omedelbart före den aktuella, kan du åsidosätta den här automatiska standardinställningen genom att lägga till ett dependsOn avsnitt i fasen.
Anteckning
I följande exempel används standardsyntax för pipeline. Om du använder distribution pipelines skiljer sig både variabel- och villkorsvariabelsyntaxen åt. Information om den specifika syntax som ska användas finns i Distributionsjobb.
Anta att du har en aktivitet med namnet MyTask, som anger en utdatavariabel med namnet MyVar.
Läs mer om syntaxen i Uttryck – beroenden.
Använda utdata i samma jobb
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- script: echo $(ProduceVar.MyVar) # this step uses the output variable
Använda utdata i ett annat jobb
jobs:
- job: A
steps:
# assume that MyTask generates an output variable called "MyVar"
# (you would learn that from the task's documentation)
- task: MyTask@1
name: ProduceVar # because we're going to depend on it, we need to name the step
- job: B
dependsOn: A
variables:
# map the output variable from A into this job
varFromA: $[ dependencies.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
Använda utdata i en annan fas
Om du vill använda utdata från en annan fas använder du formatet stageDependencies.STAGE.JOB.outputs['TASK.VARIABLE'] för att referera till variabler. På fasnivå, men inte jobbnivå, kan du använda dessa variabler under förhållanden.
Utdatavariabler är endast tillgängliga i nästa nedströmssteg. Om flera steg använder samma utdatavariabel använder du villkoret dependsOn .
stages:
- stage: One
jobs:
- job: A
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- stage: Two
dependsOn:
- One
jobs:
- job: B
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
- stage: Three
dependsOn:
- One
- Two
jobs:
- job: C
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
Du kan också skicka variabler mellan faser med hjälp av en fil som indata. För att göra detta måste du definiera variabler i den andra fasen på jobbnivå och sedan skicka variablerna som env: indata.
## script-a.sh
echo "##vso[task.setvariable variable=sauce;isOutput=true]crushed tomatoes"
## script-b.sh
echo 'Hello file version'
echo $skipMe
echo $StageSauce
## azure-pipelines.yml
stages:
- stage: one
jobs:
- job: A
steps:
- task: Bash@3
inputs:
filePath: 'script-a.sh'
name: setvar
- bash: |
echo "##vso[task.setvariable variable=skipsubsequent;isOutput=true]true"
name: skipstep
- stage: two
jobs:
- job: B
variables:
- name: StageSauce
value: $[ stageDependencies.one.A.outputs['setvar.sauce'] ]
- name: skipMe
value: $[ stageDependencies.one.A.outputs['skipstep.skipsubsequent'] ]
steps:
- task: Bash@3
inputs:
filePath: 'script-b.sh'
name: fileversion
env:
StageSauce: $(StageSauce) # predefined in variables section
skipMe: $(skipMe) # predefined in variables section
- task: Bash@3
inputs:
targetType: 'inline'
script: |
echo 'Hello inline version'
echo $(skipMe)
echo $(StageSauce)
Utdata från faser i föregående pipeline ser ut så här:
Hello inline version
true
crushed tomatoes
Lista variabler
Visa en lista över alla variabler i pipelinen med kommandot az pipelines variable list. För att komma igång, se Kom igång med Azure DevOps CLI.
az pipelines variable list [--org]
[--pipeline-id]
[--pipeline-name]
[--project]
Parametrar
-
org: URL för Azure DevOps-organisation. Konfigurera standardorganisationen med hjälp av
az devops configure -d organization=ORG_URL. Krävs om det inte konfigureras som standard eller hämtas med hjälp avgit config. Exempel:--org https://dev.azure.com/MyOrganizationName/. - pipeline-id: Krävs om pipeline-name inte anges. ID för pipelinen.
- pipeline-name: Krävs om pipeline-ID inte tillhandahålls, men ignoreras om pipeline-id har angetts. Namnet på pipelinan.
-
project: Namn eller ID för project. Konfigurera standardprojektet med
az devops configure -d project=NAME_OR_ID. Krävs om det inte konfigureras som standard eller hämtas med hjälp avgit config.
Exempel
Följande kommando visar alla variabler i pipelinen med ID 12 och visar resultatet i tabellformat.
az pipelines variable list --pipeline-id 12 --output table
Name Allow Override Is Secret Value
------------- ---------------- ----------- ------------
MyVariable False False platform
NextVariable False True platform
Configuration False False config.debug
Ange variabler i skript
Skript kan definiera variabler som senare steg i pipelinen använder. Alla variabler som anges med den här metoden behandlas som strängar. Om du vill ange en variabel från ett skript använder du en kommandosyntax och skriver ut till stdout.
Ange en variabel med jobbomfattning från ett skript
Om du vill ange en variabel från ett skript använder du task.setvariable. Det här kommandot uppdaterar miljövariablerna för efterföljande jobb. Efterföljande jobb kan komma åt den nya variabeln med hjälp av makrosyntax och ange dem i uppgifter som miljövariabler.
När du anger issecret true sparas värdet för variabeln som hemlighet och maskeras från loggen. Mer information om hemliga variabler finns i loggningskommandon.
steps:
# Create a variable
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes" # remember to use double quotes
# Use the variable
# "$(sauce)" is replaced by the contents of the `sauce` variable by Azure Pipelines
# before handing the body of the script to the shell.
- bash: |
echo my pipeline variable is $(sauce)
I efterföljande steg läggs även pipelinevariabeln till i deras miljö. Du kan inte använda variabeln i steget som den har definierats.
steps:
# Create a variable
# Note that this does not update the environment of the current script.
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes"
# An environment variable called `SAUCE` has been added to all downstream steps
- bash: |
echo "my environment variable is $SAUCE"
- pwsh: |
Write-Host "my environment variable is $env:SAUCE"
Utdata från föregående pipeline.
my environment variable is crushed tomatoes
my environment variable is crushed tomatoes
Ange en utdatavariabel för flera jobb
Om du vill göra en variabel tillgänglig för framtida jobb måste du markera den som en utdatavariabel med hjälp isOutput=trueav . Sedan kan du mappa den till framtida jobb med hjälp av syntaxen $[] och inkludera det stegnamn som anger variabeln. Utdatavariabler för flera jobb fungerar bara för jobb i samma fas.
Om du vill skicka variabler till jobb i olika steg använder du syntaxen för fasberoenden .
Anteckning
Som standard beror varje steg i en pipeline på den precis före den i YAML-filen. Därför kan varje steg använda utdatavariabler från föregående fas. För att access ytterligare steg måste du ändra beroendediagrammet, till exempel om steg 3 kräver en variabel från steg 1 måste du deklarera ett explicit beroende av steg 1.
När du skapar en utdatavariabel för flera jobb bör du tilldela uttrycket till en variabel. I denna YAML $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] tilldelas till variabeln $(myVarFromJobA).
jobs:
# Set an output variable from job A
- job: A
pool:
vmImage: 'windows-latest'
steps:
- powershell: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable into job B
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobA: $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] # map in the variable
# remember, expressions require single quotes
steps:
- script: echo $(myVarFromJobA)
name: echovar
Utdata från föregående pipeline.
this is the value
this is the value
Om du ställer in en variabel från en fas till en annan använder du stageDependencies.
stages:
- stage: A
jobs:
- job: A1
steps:
- bash: echo "##vso[task.setvariable variable=myStageOutputVar;isOutput=true]this is a stage output var"
name: printvar
- stage: B
dependsOn: A
variables:
myVarfromStageA: $[ stageDependencies.A.A1.outputs['printvar.myStageOutputVar'] ]
jobs:
- job: B1
steps:
- script: echo $(myVarfromStageA)
Om du ställer in en variabel från en matrix eller slice, måste du referera till variabeln när du accessar den från ett nedströmsjobb:
- Namnet på tjänsten.
- Steget.
jobs:
# Set an output variable from a job with a matrix
- job: A
pool:
vmImage: 'ubuntu-latest'
strategy:
maxParallel: 2
matrix:
debugJob:
configuration: debug
platform: x64
releaseJob:
configuration: release
platform: x64
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the $(configuration) value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the debug job
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobADebug: $[ dependencies.A.outputs['debugJob.setvarStep.myOutputVar'] ]
steps:
- script: echo $(myVarFromJobADebug)
name: echovar
jobs:
# Set an output variable from a job with slicing
- job: A
pool:
vmImage: 'ubuntu-latest'
parallel: 2 # Two slices
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the slice $(system.jobPositionInPhase) value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobsA: $[ dependencies.A.outputs['setvarStep.myOutputVar'] ]
steps:
- script: "echo $(myVarFromJobsA)"
name: echovar
Sv-SE: Se till att prefixa jobbnamnet till utdatavariablerna för ett distributionsjobb. I det här fallet är Ajobbnamnet :
jobs:
# Set an output variable from a deployment
- deployment: A
pool:
vmImage: 'ubuntu-latest'
environment: staging
strategy:
runOnce:
deploy:
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the deployment variable value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromDeploymentJob: $[ dependencies.A.outputs['A.setvarStep.myOutputVar'] ]
steps:
- bash: "echo $(myVarFromDeploymentJob)"
name: echovar
 Ange variablerna
Ange variablerna  Ange variablerna
Ange variablerna  Ange variablerna
Ange variablerna Ange variabler med hjälp av uttryck
Du kan ange en variabel med hjälp av ett uttryck. Du har redan stött på ett fall av den här metoden när du anger en variabel till utdata från en annan variabel från ett tidigare jobb.
- job: B
dependsOn: A
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ] # remember to use single quotes
Du kan använda något av de uttryck som stöds för att ange en variabel. Här är ett exempel på hur du ställer in en variabel som ska fungera som en räknare som börjar vid 100, ökas med 1 för varje körning och återställs till 100 varje dag.
jobs:
- job:
variables:
a: $[counter(format('{0:yyyyMMdd}', pipeline.startTime), 100)]
steps:
- bash: echo $(a)
Mer information om räknare, beroenden och andra uttryck finns i uttryck.
Konfigurera inställningsbara variabler för steg
Du kan definiera settableVariables i ett steg eller ange att inga variabler kan anges.
I det här exemplet kan skriptet inte ange en variabel.
steps:
- script: echo This is a step
target:
settableVariables: none
I följande exempel kan skriptet ange variabeln sauce men kan inte ange variabeln secretSauce. Du ser en varning på pipelinekörningssidan.

steps:
- bash: |
echo "##vso[task.setvariable variable=Sauce;]crushed tomatoes"
echo "##vso[task.setvariable variable=secretSauce;]crushed tomatoes with garlic"
target:
settableVariables:
- sauce
name: SetVars
- bash:
echo "Sauce is $(sauce)"
echo "secretSauce is $(secretSauce)"
name: OutputVars
Tillåt vid kö-tiden
Om en variabel visas i blocket för variables en YAML-fil är dess värde fast och användarna kan inte åsidosätta den vid kötid. Definiera dina variabler i en YAML-fil, men det finns tillfällen då den här metoden inte är meningsfull. Du kanske till exempel vill definiera en hemlig variabel och inte exponera den i din YAML. Eller så kan du behöva ange ett variabelvärde manuellt under pipelinekörningen.
Du har två alternativ för att definiera kötidsvärden. Du kan definiera en variabel i användargränssnittet och välja alternativet Låt användare åsidosätta det här värdet när de kör den här pipelinen , eller så kan du använda körningsparametrar i stället. Om din variabel inte är en hemlighet är det bästa sättet att använda körningsparametrar.
För att ange en variabel vid kötid lägger du till en ny variabel inom din pipeline och väljer alternativet åsidosättning. Endast användare med behörigheten Tillåt konfiguration av redigeringskö kan ändra värdet på en variabel.
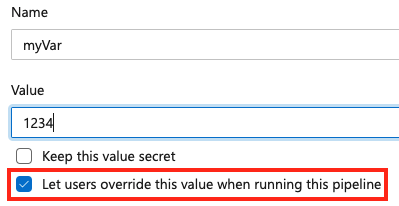
Om du vill tillåta att en variabel ställs in vid kötid, kontrollera att variabeln inte också förekommer i blocket för en pipeline eller ett jobb variables. Om du definierar en variabel i både variabelblocket för en YAML och i användargränssnittet har värdet i YAML prioritet.
För ökad säkerhet, använd en fördefinierad uppsättning värden för variabler som kan sättas vid kötid och säkra typer som booleanska och heltal. För strängar använder du en fördefinierad uppsättning värden.

Expansion av variabler
När du anger en variabel med samma namn i flera omfång gäller följande prioritet (högsta prioritet först):
- Variabel på jobbnivå som anges i YAML-filen
- Variabel på fasnivå som anges i YAML-filen
- Variabel på pipelinenivå som anges i YAML-filen
- Variabel som ställs in under tid i kön
- Pipelinevariabel som anges i användargränssnittet för pipelineinställningar
I följande exempel anges samma variabel a på pipelinenivå och jobbnivå i YAML-filen. Den anges också i en variabelgrupp Goch som en variabel i användargränssnittet för pipelineinställningar.
variables:
a: 'pipeline yaml'
stages:
- stage: one
displayName: one
variables:
- name: a
value: 'stage yaml'
jobs:
- job: A
variables:
- name: a
value: 'job yaml'
steps:
- bash: echo $(a) # This will be 'job yaml'
När du anger en variabel med samma namn i samma omfång har det sista angivna värdet företräde.
stages:
- stage: one
displayName: Stage One
variables:
- name: a
value: alpha
- name: a
value: beta
jobs:
- job: I
displayName: Job I
variables:
- name: b
value: uno
- name: b
value: dos
steps:
- script: echo $(a) #outputs beta
- script: echo $(b) #outputs dos
Anteckning
När du anger en variabel i YAML-filen ska du inte definiera den i webbredigeraren som inställbar vid kötid. Du kan för närvarande inte ändra variabler som anges i YAML-filen vid kötiden. Om du behöver en variabel som kan ställas in vid kötid ska du inte ange den i YAML-filen.
Variabler expanderas en gång när körningen startar och igen i början av varje steg. Till exempel:
jobs:
- job: A
variables:
a: 10
steps:
- bash: |
echo $(a) # This will be 10
echo '##vso[task.setvariable variable=a]20'
echo $(a) # This will also be 10, since the expansion of $(a) happens before the step
- bash: echo $(a) # This will be 20, since the variables are expanded just before the step
Det finns två steg i föregående exempel. Expansionen av $(a) sker en gång i början av jobbet och en gång i början av vart och ett av de två stegen.
Eftersom variabler expanderas i början av ett jobb kan du inte använda dem i en strategi. I följande exempel kan du inte använda variabeln a för att expandera jobbmatrisen, eftersom variabeln endast är tillgänglig i början av varje expanderat jobb.
jobs:
- job: A
variables:
a: 10
strategy:
matrix:
x:
some_variable: $(a) # This does not work
Om variabeln a är en utdatavariabel från ett tidigare jobb kan du använda den i ett framtida jobb.
- job: A
steps:
- powershell: echo "##vso[task.setvariable variable=a;isOutput=true]10"
name: a_step
# Map the variable into job B
- job: B
dependsOn: A
variables:
some_variable: $[ dependencies.A.outputs['a_step.a'] ]
Rekursiv expansion
På agenten expanderas variabler som refereras med syntax $( ) rekursivt.
Till exempel:
variables:
myInner: someValue
myOuter: $(myInner)
steps:
- script: echo $(myOuter) # prints "someValue"
displayName: Variable is $(myOuter) # display name is "Variable is someValue"