Not
Åtkomst till denna sida kräver auktorisation. Du kan prova att logga in eller byta katalog.
Åtkomst till denna sida kräver auktorisation. Du kan prova att byta katalog.
Viktigt!
- Foundry Local är tillgängligt i förhandsversionen. Offentliga förhandsversioner ger tidig åtkomst till funktioner som är i aktiv distribution.
- Funktioner, metoder och processer kan ändra eller ha begränsade funktioner, före allmän tillgänglighet (GA).
Foundry Local SDK förenklar AI-modellhantering i lokala miljöer genom att tillhandahålla kontrollplansåtgärder som är separata från dataplanets slutsatsdragningskod. Den här referensen dokumenterar SDK-implementeringar för Python, JavaScript, C#och Rust.
Python SDK-referens
Förutsättningar
- Installera Foundry Local och kontrollera att
foundrykommandot är tillgängligt på dinPATH. - Använd Python 3.9 eller senare.
Installation
Installera Python-paketet:
pip install foundry-local-sdk
Snabbstart
Använd det här kodfragmentet för att kontrollera att SDK:et kan starta tjänsten och nå den lokala katalogen.
from foundry_local import FoundryLocalManager
manager = FoundryLocalManager()
manager.start_service()
catalog = manager.list_catalog_models()
print(f"Catalog models available: {len(catalog)}")
I det här exemplet skrivs ett tal som inte är noll ut när tjänsten körs och katalogen är tillgänglig.
Referenser:
FoundryLocalManager-klass
Klassen FoundryLocalManager innehåller metoder för att hantera modeller, cacheminnen och den lokala foundry-tjänsten.
Initialisering
from foundry_local import FoundryLocalManager
# Initialize and optionally bootstrap with a model
manager = FoundryLocalManager(alias_or_model_id=None, bootstrap=True)
-
alias_or_model_id: (valfritt) Alias eller modell-ID för nedladdning och inläsning vid start. -
bootstrap: (standardvärde sant) Om sant, startar tjänsten om den inte körs och laddar in modellen om den tillhandahålls.
En anteckning om alias
Många metoder som beskrivs i den här referensen har en alias_or_model_id parameter i signaturen. Du kan skicka till metoden antingen ett alias eller modell-ID som ett värde. Om du använder ett alias kommer:
- Välj den bästa modellen för den tillgängliga maskinvaran. Om till exempel en Nvidia CUDA GPU är tillgänglig väljer Foundry Local CUDA-modellen. Om en NPU som stöds är tillgänglig väljer Foundry Local NPU-modellen.
- Gör att du kan använda ett kortare namn utan att behöva komma ihåg modell-ID:t.
Tips/Råd
Vi rekommenderar att du skickar in ett alias_or_model_id i parametern eftersom Foundry Local, när du distribuerar ditt program, hämtar den bästa modellen för slutanvändarens dator under körningstid.
Anmärkning
Om du har en Intel NPU på Windows kontrollerar du att du har installerat Intel NPU-drivrutinen för optimal NPU-acceleration.
Tjänsthantering
| Metod | Signature | Description |
|---|---|---|
is_service_running() |
() -> bool |
Kontrollerar om Foundry-tjänsten körs lokalt. |
start_service() |
() -> None |
Startar den lokala fabrikstjänsten. |
service_uri |
@property -> str |
Returnerar tjänstens URI. |
endpoint |
@property -> str |
Returnerar tjänstslutpunkten. |
api_key |
@property -> str |
Returnerar API-nyckeln (från env eller standard). |
Kataloghantering
| Metod | Signature | Description |
|---|---|---|
list_catalog_models() |
() -> list[FoundryModelInfo] |
Visar en lista över alla tillgängliga modeller i katalogen. |
refresh_catalog() |
() -> None |
Uppdaterar modellkatalogen. |
get_model_info() |
(alias_or_model_id: str, raise_on_not_found=False) -> FoundryModelInfo \| None |
Hämtar modellinformation efter alias eller ID. |
Cachehantering
| Metod | Signature | Description |
|---|---|---|
get_cache_location() |
() -> str |
Returnerar katalogsökvägen för modellcachen. |
list_cached_models() |
() -> list[FoundryModelInfo] |
Visar en lista över modeller som laddats ned till den lokala cachen. |
Modellhantering
| Metod | Signature | Description |
|---|---|---|
download_model() |
(alias_or_model_id: str, token: str = None, force: bool = False) -> FoundryModelInfo |
Laddar ned en modell till den lokala cachen. |
load_model() |
(alias_or_model_id: str, ttl: int = 600) -> FoundryModelInfo |
Läser in en modell på slutsatsdragningsservern. |
unload_model() |
(alias_or_model_id: str, force: bool = False) -> None |
Tar bort en modell från slutsatsdragningsservern. |
list_loaded_models() |
() -> list[FoundryModelInfo] |
Visar en lista över alla modeller som för närvarande är inlästa i tjänsten. |
FoundryModelInfo
Metoderna list_catalog_models(), list_cached_models()och list_loaded_models() returnerar en lista över FoundryModelInfo objekt. Du kan använda informationen i det här objektet för att ytterligare förfina listan. Eller hämta informationen för en modell direkt genom att anropa get_model_info(alias_or_model_id) metoden.
Dessa objekt innehåller följande fält:
| Fält | Typ | Description |
|---|---|---|
alias |
str |
Alias för modellen. |
id |
str |
Unik identifierare för modellen. |
version |
str |
Version av modellen. |
execution_provider |
str |
Acceleratorn (exekveringsleverantören) som används för att köra modellen. |
device_type |
DeviceType |
Enhetstyp för modellen: CPU, GPU, NPU. |
uri |
str |
URI för modellen. |
file_size_mb |
int |
Storleken på modellen på disken i MB. |
supports_tool_calling |
bool |
Om modellen stöder verktygsanrop. |
prompt_template |
dict \| None |
Fråga efter modellens mall. |
provider |
str |
Leverantör av modellen (där modellen publiceras). |
publisher |
str |
Utgivare av modellen (som publicerade modellen). |
license |
str |
Namnet på modellens licens. |
task |
str |
Modellens uppgift. En av chat-completions eller automatic-speech-recognition. |
ep_override |
str \| None |
Åsidosätt exekveringsprovidern, om den skiljer sig från modellens standard. |
Utförandeleverantörer
En av:
-
CPUExecutionProvider– CPU-baserad körning -
CUDAExecutionProvider– NVIDIA CUDA GPU-körning -
WebGpuExecutionProvider– WebGPU-körning -
QNNExecutionProvider- Qualcomm neurala nätverksutförande (NPU) -
OpenVINOExecutionProvider– Intel OpenVINO-körning -
NvTensorRTRTXExecutionProvider– NVIDIA TensorRT-körning -
VitisAIExecutionProvider– AMD Vitis AI-körning
Exempel på användning
Följande kod visar hur du använder FoundryLocalManager klassen för att hantera modeller och interagera med den lokala foundry-tjänsten.
from foundry_local import FoundryLocalManager
# By using an alias, the most suitable model will be selected
# to your end-user's device.
alias = "qwen2.5-0.5b"
# Create a FoundryLocalManager instance. This will start the Foundry.
manager = FoundryLocalManager()
# List available models in the catalog
catalog = manager.list_catalog_models()
print(f"Available models in the catalog: {catalog}")
# Download and load a model
model_info = manager.download_model(alias)
model_info = manager.load_model(alias)
print(f"Model info: {model_info}")
# List models in cache
local_models = manager.list_cached_models()
print(f"Models in cache: {local_models}")
# List loaded models
loaded = manager.list_loaded_models()
print(f"Models running in the service: {loaded}")
# Unload a model
manager.unload_model(alias)
Det här exemplet visar modeller, laddar ned och läser in en modell och tar sedan bort den.
Referenser:
Integrera med OpenAI SDK
Installera OpenAI-paketet:
pip install openai
Följande kod visar hur du integrerar FoundryLocalManager med OpenAI SDK för att interagera med en lokal modell.
import openai
from foundry_local import FoundryLocalManager
# By using an alias, the most suitable model will be downloaded
# to your end-user's device.
alias = "qwen2.5-0.5b"
# Create a FoundryLocalManager instance. This will start the Foundry
# Local service if it is not already running and load the specified model.
manager = FoundryLocalManager(alias)
# The remaining code uses the OpenAI Python SDK to interact with the local model.
# Configure the client to use the local Foundry service
client = openai.OpenAI(
base_url=manager.endpoint,
api_key=manager.api_key # API key is not required for local usage
)
# Set the model to use and generate a streaming response
stream = client.chat.completions.create(
model=manager.get_model_info(alias).id,
messages=[{"role": "user", "content": "Why is the sky blue?"}],
stream=True
)
# Print the streaming response
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
I det här exemplet strömmas ett svar om chattens slutförande från den lokala modellen.
Referenser:
JavaScript SDK-referens
Förutsättningar
- Installera Foundry Local och kontrollera att
foundrykommandot är tillgängligt på dinPATH.
Installation
Installera paketet från npm:
npm install foundry-local-sdk
Snabbstart
Använd det här kodfragmentet för att kontrollera att SDK:et kan starta tjänsten och nå den lokala katalogen.
import { FoundryLocalManager } from "foundry-local-sdk";
const manager = new FoundryLocalManager();
await manager.startService();
const catalogModels = await manager.listCatalogModels();
console.log(`Catalog models available: ${catalogModels.length}`);
I det här exemplet skrivs ett tal som inte är noll ut när tjänsten körs och katalogen är tillgänglig.
Referenser:
FoundryLocalManager-klass
Med FoundryLocalManager klassen kan du hantera modeller, styra cacheminnet och interagera med den lokala foundry-tjänsten i både webbläsare och Node.js miljöer.
Initialisering
import { FoundryLocalManager } from "foundry-local-sdk";
const foundryLocalManager = new FoundryLocalManager();
Tillgängliga alternativ:
-
host: Bas-URL för den lokala foundry-tjänsten -
fetch: (valfritt) Anpassad hämtningsimplementering för miljöer som Node.js
En anteckning om alias
Många metoder som beskrivs i den här referensen har en aliasOrModelId parameter i signaturen. Du kan skicka till metoden antingen ett alias eller modell-ID som ett värde. Om du använder ett alias kommer:
- Välj den bästa modellen för den tillgängliga maskinvaran. Om till exempel en Nvidia CUDA GPU är tillgänglig väljer Foundry Local CUDA-modellen. Om en NPU som stöds är tillgänglig väljer Foundry Local NPU-modellen.
- Gör att du kan använda ett kortare namn utan att behöva komma ihåg modell-ID:t.
Tips/Råd
Vi rekommenderar att du skickar in ett aliasOrModelId i parametern eftersom Foundry Local, när du distribuerar ditt program, hämtar den bästa modellen för slutanvändarens dator under körningstid.
Anmärkning
Om du har en Intel NPU på Windows kontrollerar du att du har installerat Intel NPU-drivrutinen för optimal NPU-acceleration.
Tjänsthantering
| Metod | Signature | Description |
|---|---|---|
init() |
(aliasOrModelId?: string) => Promise<FoundryModelInfo \| void> |
Initierar SDK och läser eventuellt in en modell. |
isServiceRunning() |
() => Promise<boolean> |
Kontrollerar om Foundry-tjänsten körs lokalt. |
startService() |
() => Promise<void> |
Startar den lokala fabrikstjänsten. |
serviceUrl |
string |
Grund-URL:en för Foundry Local-tjänsten. |
endpoint |
string |
API-slutpunkten (serviceUrl + /v1). |
apiKey |
string |
API-nyckel (ingen) |
Kataloghantering
| Metod | Signature | Description |
|---|---|---|
listCatalogModels() |
() => Promise<FoundryModelInfo[]> |
Visar en lista över alla tillgängliga modeller i katalogen. |
refreshCatalog() |
() => Promise<void> |
Uppdaterar modellkatalogen. |
getModelInfo() |
(aliasOrModelId: string, throwOnNotFound = false) => Promise<FoundryModelInfo \| null> |
Hämtar modellinformation efter alias eller ID. |
Cachehantering
| Metod | Signature | Description |
|---|---|---|
getCacheLocation() |
() => Promise<string> |
Returnerar katalogsökvägen för modellcachen. |
listCachedModels() |
() => Promise<FoundryModelInfo[]> |
Visar en lista över modeller som laddats ned till den lokala cachen. |
Modellhantering
| Metod | Signature | Description |
|---|---|---|
downloadModel() |
(aliasOrModelId: string, token?: string, force = false, onProgress?) => Promise<FoundryModelInfo> |
Laddar ned en modell till den lokala cachen. |
loadModel() |
(aliasOrModelId: string, ttl = 600) => Promise<FoundryModelInfo> |
Läser in en modell på slutsatsdragningsservern. |
unloadModel() |
(aliasOrModelId: string, force = false) => Promise<void> |
Tar bort en modell från slutsatsdragningsservern. |
listLoadedModels() |
() => Promise<FoundryModelInfo[]> |
Visar en lista över alla modeller som för närvarande är inlästa i tjänsten. |
Exempel på användning
Följande kod visar hur du använder FoundryLocalManager klassen för att hantera modeller och interagera med den lokala foundry-tjänsten.
import { FoundryLocalManager } from "foundry-local-sdk";
// By using an alias, the most suitable model will be downloaded
// to your end-user's device.
// TIP: You can find a list of available models by running the
// following command in your terminal: `foundry model list`.
const alias = "qwen2.5-0.5b";
const manager = new FoundryLocalManager();
// Initialize the SDK and optionally load a model
const modelInfo = await manager.init(alias);
console.log("Model Info:", modelInfo);
// Check if the service is running
const isRunning = await manager.isServiceRunning();
console.log(`Service running: ${isRunning}`);
// List available models in the catalog
const catalog = await manager.listCatalogModels();
// Download and load a model
await manager.downloadModel(alias);
await manager.loadModel(alias);
// List models in cache
const localModels = await manager.listCachedModels();
// List loaded models
const loaded = await manager.listLoadedModels();
// Unload a model
await manager.unloadModel(alias);
Det här exemplet laddar ned och läser in en modell och visar sedan cachelagrade och inlästa modeller.
Referenser:
Integrering med OpenAI-klient
Installera OpenAI-paketet:
npm install openai
Följande kod visar hur du integrerar FoundryLocalManager med OpenAI-klienten för att interagera med en lokal modell.
import { OpenAI } from "openai";
import { FoundryLocalManager } from "foundry-local-sdk";
// By using an alias, the most suitable model will be downloaded
// to your end-user's device.
// TIP: You can find a list of available models by running the
// following command in your terminal: `foundry model list`.
const alias = "qwen2.5-0.5b";
// Create a FoundryLocalManager instance. This will start the Foundry
// Local service if it is not already running.
const foundryLocalManager = new FoundryLocalManager();
// Initialize the manager with a model. This will download the model
// if it is not already present on the user's device.
const modelInfo = await foundryLocalManager.init(alias);
console.log("Model Info:", modelInfo);
const openai = new OpenAI({
baseURL: foundryLocalManager.endpoint,
apiKey: foundryLocalManager.apiKey,
});
async function streamCompletion() {
const stream = await openai.chat.completions.create({
model: modelInfo.id,
messages: [{ role: "user", content: "What is the golden ratio?" }],
stream: true,
});
for await (const chunk of stream) {
if (chunk.choices[0]?.delta?.content) {
process.stdout.write(chunk.choices[0].delta.content);
}
}
}
streamCompletion();
I det här exemplet strömmas ett svar om chattens slutförande från den lokala modellen.
Referenser:
Webbläsaranvändning
SDK innehåller en webbläsarkompatibel version där du måste ange värd-URL:en manuellt:
import { FoundryLocalManager } from "foundry-local-sdk/browser";
// Specify the service URL
// Run the Foundry Local service using the CLI: `foundry service start`
// and use the URL from the CLI output
const host = "HOST";
const manager = new FoundryLocalManager({ host });
// Note: The `init`, `isServiceRunning`, and `startService` methods
// are not available in the browser version
Anmärkning
Webbläsarversionen stöder inte metoderna init, isServiceRunning och startService. Du måste se till att den lokala foundry-tjänsten körs innan du använder SDK:et i en webbläsarmiljö. Du kan starta tjänsten med hjälp av Foundry Local CLI: foundry service start. Du kan hämta tjänst-URL:en från CLI-utdata.
Exempel på användning
import { FoundryLocalManager } from "foundry-local-sdk/browser";
// Specify the service URL
// Run the Foundry Local service using the CLI: `foundry service start`
// and use the URL from the CLI output
const host = "HOST";
const manager = new FoundryLocalManager({ host });
const alias = "qwen2.5-0.5b";
// Get all available models
const catalog = await manager.listCatalogModels();
console.log("Available models in catalog:", catalog);
// Download and load a specific model
await manager.downloadModel(alias);
await manager.loadModel(alias);
// View models in your local cache
const localModels = await manager.listCachedModels();
console.log("Cached models:", localModels);
// Check which models are currently loaded
const loaded = await manager.listLoadedModels();
console.log("Loaded models in inference service:", loaded);
// Unload a model when finished
await manager.unloadModel(alias);
Referenser:
C# SDK-referens
Installationsguide för projekt
Det finns två NuGet-paket för Foundry Local SDK – en WinML och ett plattformsoberoende paket – som har samma API-yta men är optimerade för olika plattformar:
-
Windows: Använder paketet
Microsoft.AI.Foundry.Local.WinMLsom är specifikt för Windows-program, som använder WinML-ramverket (Windows Machine Learning). -
Plattformsoberoende: Använder paketet
Microsoft.AI.Foundry.Localsom kan användas för plattformsoberoende program (Windows, Linux, macOS).
Beroende på målplattformen följer du de här anvisningarna för att skapa ett nytt C#-program och lägger till nödvändiga beroenden:
Använd Foundry Local i ditt C#-projekt genom att följa dessa Windows-specifika eller plattformsoberoende instruktioner (macOS/Linux/Windows):
- Skapa ett nytt C#-projekt och navigera till det:
dotnet new console -n app-name cd app-name - Öppna
app-name.csproj-filen och redigera den för att:<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>net9.0-windows10.0.26100</TargetFramework> <RootNamespace>app-name</RootNamespace> <ImplicitUsings>enable</ImplicitUsings> <Nullable>enable</Nullable> <WindowsAppSDKSelfContained>false</WindowsAppSDKSelfContained> <WindowsPackageType>None</WindowsPackageType> <EnableCoreMrtTooling>false</EnableCoreMrtTooling> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.AI.Foundry.Local.WinML" Version="0.8.2.1" /> <PackageReference Include="Microsoft.Extensions.Logging" Version="9.0.10" /> <PackageReference Include="OpenAI" Version="2.5.0" /> </ItemGroup> </Project> - Skapa en
nuget.configfil i projektroten med följande innehåll så att paketen återställs korrekt:<?xml version="1.0" encoding="utf-8"?> <configuration> <packageSources> <clear /> <add key="nuget.org" value="https://api.nuget.org/v3/index.json" /> <add key="ORT" value="https://aiinfra.pkgs.visualstudio.com/PublicPackages/_packaging/ORT/nuget/v3/index.json" /> </packageSources> <packageSourceMapping> <packageSource key="nuget.org"> <package pattern="*" /> </packageSource> <packageSource key="ORT"> <package pattern="*Foundry*" /> </packageSource> </packageSourceMapping> </configuration>
Snabbstart
Använd det här kodfragmentet för att kontrollera att SDK:et kan initiera och komma åt den lokala modellkatalogen.
using Microsoft.AI.Foundry.Local;
using Microsoft.Extensions.Logging;
using System.Linq;
var config = new Configuration
{
AppName = "app-name",
LogLevel = Microsoft.AI.Foundry.Local.LogLevel.Information,
};
using var loggerFactory = LoggerFactory.Create(builder =>
{
builder.SetMinimumLevel(Microsoft.Extensions.Logging.LogLevel.Information);
});
var logger = loggerFactory.CreateLogger<Program>();
await FoundryLocalManager.CreateAsync(config, logger);
var manager = FoundryLocalManager.Instance;
var catalog = await manager.GetCatalogAsync();
var models = await catalog.ListModelsAsync();
Console.WriteLine($"Models available: {models.Count()}");
I det här exemplet skrivs antalet tillgängliga modeller ut för maskinvaran.
Referenser:
Omformat
För att förbättra din möjlighet att skicka program med hjälp av AI på enheten, finns det betydande ändringar i arkitekturen för C# SDK i version 0.8.0 och senare. I det här avsnittet beskriver vi de viktigaste ändringarna som hjälper dig att migrera dina program till den senaste versionen av SDK.
Anmärkning
I SDK-versionen 0.8.0 och senare finns det icke-bakåtkompatibla ändringar i API:et från tidigare versioner.
Följande diagram visar hur den tidigare arkitekturen – för tidigare versioner än 0.8.0 – förlitade sig mycket på att använda en REST-webbserver för att hantera modeller och slutsatsdragningar som chattavslut:

SDK använder ett RPC (Remote Procedure Call) för att hitta Foundry Local CLI körbart på datorn, starta webbservern och sedan kommunicera med den via HTTP. Den här arkitekturen hade flera begränsningar, bland annat:
- Komplexitet i hanteringen av webbserverns livscykel.
- Utmanande distribution: Slutanvändarna behövde ha Foundry Local CLI installerat på sina datorer och ditt program.
- Versionshantering av CLI och SDK kan leda till kompatibilitetsproblem.
För att lösa dessa problem använder den omdesignade arkitekturen i version 0.8.0 och senare en mer effektiviserad metod. Den nya arkitekturen är följande:

I den här nya arkitekturen:
- Programmet är fristående. Det kräver inte att Foundry Local CLI installeras separat på slutanvändarens dator, vilket gör det enklare för dig att distribuera program.
- REST-webbservern är valfri. Du kan fortfarande använda webbservern om du vill integrera med andra verktyg som kommunicerar via HTTP. Läs Använda chattavslut via REST-server med Foundry Local för mer information om hur du använder den här funktionen.
- SDK:n har inbyggt stöd för chattavslutningar och ljudavskrifter, så att du kan skapa konversations-AI-program med färre beroenden. Läs Foundry Locals API för inbyggda chattkompletteringar för detaljer om hur du använder den här funktionen.
- På Windows-enheter kan du använda en Windows ML-version som hanterar maskinvaruacceleration för modeller på enheten genom att dra in rätt körning och drivrutiner.
API-ändringar
Version 0.8.0 och senare ger ett mer objektorienterat och komponerbart API. Huvudinmatningspunkten fortsätter att vara FoundryLocalManager klassen, men i stället för att vara en platt uppsättning metoder som fungerar via statiska anrop till ett tillståndslöst HTTP-API, exponerar SDK nu metoder på den FoundryLocalManager instans som underhåller tillstånd om tjänsten och modellerna.
| Primitiv | Versioner < 0.8.0 | Versioner >= 0.8.0 |
|---|---|---|
| Konfiguration | N/A | config = Configuration(...) |
| Hämta Manager | mgr = FoundryLocalManager(); |
await FoundryLocalManager.CreateAsync(config, logger);var mgr = FoundryLocalManager.Instance; |
| Hämta katalog | N/A | catalog = await mgr.GetCatalogAsync(); |
| Lista modeller | mgr.ListCatalogModelsAsync(); |
catalog.ListModelsAsync(); |
| Hämta modell | mgr.GetModelInfoAsync("aliasOrModelId"); |
catalog.GetModelAsync(alias: "alias"); |
| Hämta variant | N/A | model.SelectedVariant; |
| Ange variant | N/A | model.SelectVariant(); |
| Ladda ned en modell | mgr.DownloadModelAsync("aliasOrModelId"); |
model.DownloadAsync() |
| Läsa in en modell | mgr.LoadModelAsync("aliasOrModelId"); |
model.LoadAsync() |
| Ladda ur en modell | mgr.UnloadModelAsync("aliasOrModelId"); |
model.UnloadAsync() |
| Lista inlästa modeller | mgr.ListLoadedModelsAsync(); |
catalog.GetLoadedModelsAsync(); |
| Hämta modellsökväg | N/A | model.GetPathAsync() |
| Starta tjänsten | mgr.StartServiceAsync(); |
mgr.StartWebServerAsync(); |
| Stoppa tjänsten | mgr.StopServiceAsync(); |
mgr.StopWebServerAsync(); |
| Cacheplats | mgr.GetCacheLocationAsync(); |
config.ModelCacheDir |
| Lista cachelagrade modeller | mgr.ListCachedModelsAsync(); |
catalog.GetCachedModelsAsync(); |
MED API:et kan Foundry Local vara mer konfigurerbart via webbservern, loggning, cacheplats och modellvariantval. Med klassen kan du till exempel Configuration konfigurera programnamn, loggningsnivå, webbserver-URL:er och kataloger för programdata, modellcache och loggar:
var config = new Configuration
{
AppName = "app-name",
LogLevel = Microsoft.AI.Foundry.Local.LogLevel.Information,
Web = new Configuration.WebService
{
Urls = "http://127.0.0.1:55588"
},
AppDataDir = "./foundry_local_data",
ModelCacheDir = "{AppDataDir}/model_cache",
LogsDir = "{AppDataDir}/logs"
};
Referenser:
I den tidigare versionen av Foundry Local C# SDK kunde du inte konfigurera de här inställningarna direkt via SDK:t, vilket begränsade din möjlighet att anpassa tjänstens beteende.
Minska storleken på programpaket
Foundry Local SDK hämtar NuGet-paketet Microsoft.ML.OnnxRuntime.Foundry som ett beroende. Paketet Microsoft.ML.OnnxRuntime.Foundry tillhandahåller inferens-runtime-paketet, vilket är den uppsättning bibliotek som krävs för att effektivt köra slutsatsdragning på specifika maskinvaruenheter för leverantörer. Inferens-runtime-paketet innehåller följande komponenter:
-
ONNX Runtime-bibliotek: Huvudinferensmotorn (
onnxruntime.dll). -
EP-bibliotek (ONNX Runtime Execution Provider). En maskinvaruspecifik serverdel i ONNX Runtime som optimerar och kör delar av en maskininlärningsmodell som maskinvaruaccelerator. Till exempel:
- CUDA EP:
onnxruntime_providers_cuda.dll - QNN EP:
onnxruntime_providers_qnn.dll
- CUDA EP:
-
Independent Hardware Vendor (IHV)-bibliotek. Till exempel:
- WebGPU: DirectX-beroenden (
dxcompiler.dll,dxil.dll) - QNN: Qualcomm QNN-beroenden (
QnnSystem.dllosv.)
- WebGPU: DirectX-beroenden (
I följande tabell sammanfattas vilka EP- och IHV-bibliotek som paketeras med ditt program och vad WinML laddar ned/installerar vid körning:
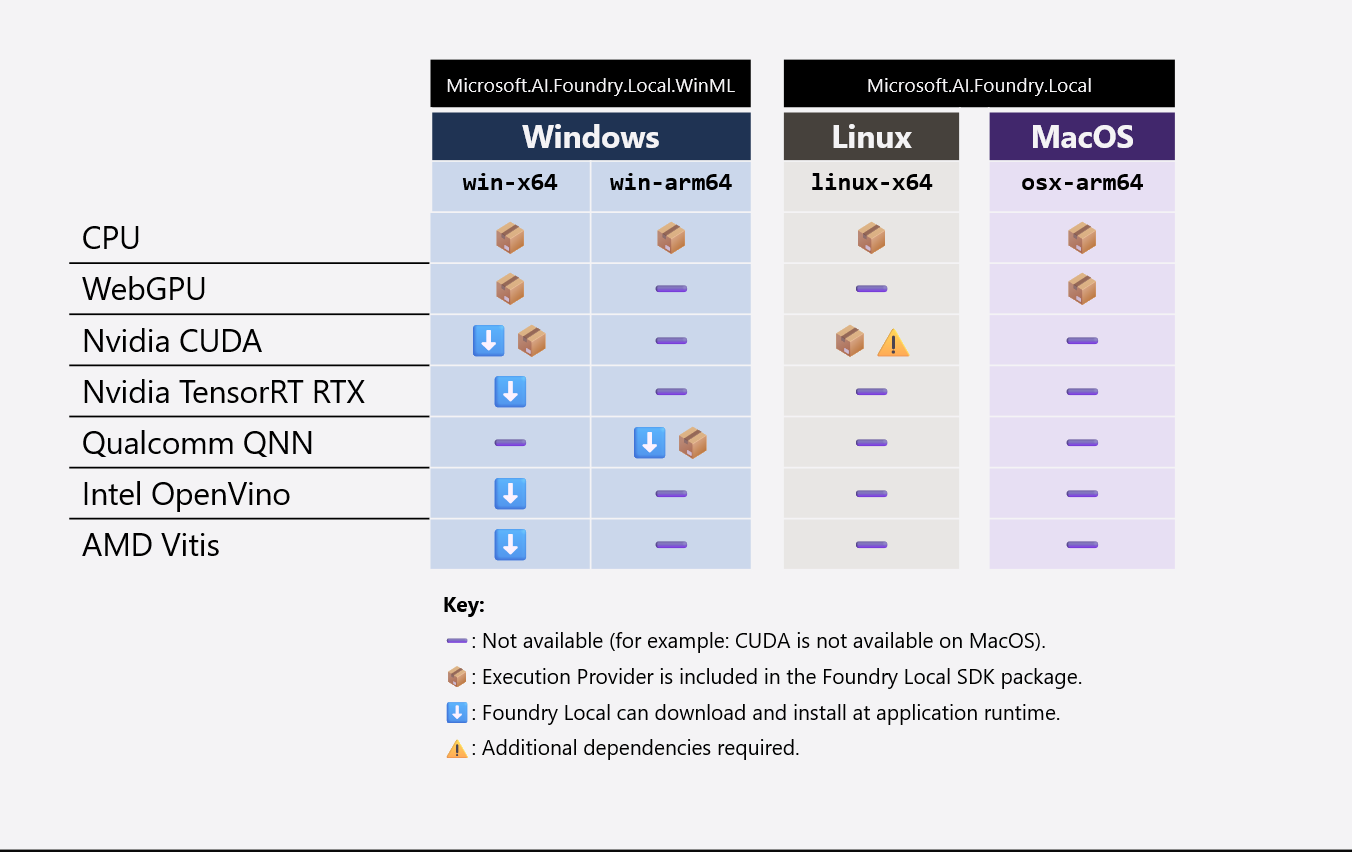
I alla plattformar och arkitekturer krävs PROCESSOR-EP: n. WebGPU EP- och IHV-biblioteken är små i storlek (till exempel lägger WebGPU bara till ~7 MB i programpaketet) och krävs i Windows och macOS. CUDA- och QNN-exekveringsleverantörerna är dock stora i omfattning (till exempel lägger CUDA till ~1 GB i applikationspaketet) så vi rekommenderar att du exkluderar dessa leverantörer från programpaketet. WinML laddar ned/installerar CUDA och QNN vid körning om slutanvändaren har kompatibel maskinvara.
Anmärkning
Vi arbetar med att ta bort CUDA- och QNN-EPs från Microsoft.ML.OnnxRuntime.Foundry paketet i framtida versioner så att du inte behöver inkludera en ExcludeExtraLibs.props fil för att ta bort dem från programpaketet.
Om du vill minska storleken på programpaketet kan du skapa en ExcludeExtraLibs.props fil i projektkatalogen med följande innehåll, vilket exkluderar CUDA- och QNN EP- och IHV-biblioteken när du publicerar ditt program:
<Project>
<!-- we want to ensure we're using the onnxruntime libraries from Foundry Local Core so
we delete the WindowsAppSdk versions once they're unzipped. -->
<Target Name="ExcludeOnnxRuntimeLibs" AfterTargets="ExtractMicrosoftWindowsAppSDKMsixFiles">
<Delete Files="$(MicrosoftWindowsAppSDKMsixContent)\onnxruntime.dll"/>
<Delete Files="$(MicrosoftWindowsAppSDKMsixContent)\onnxruntime_providers_shared.dll"/>
<Message Importance="Normal" Text="Deleted onnxruntime libraries from $(MicrosoftWindowsAppSDKMsixContent)." />
</Target>
<!-- Remove CUDA EP and IHV libraries on Windows x64 -->
<Target Name="ExcludeCudaLibs" Condition="'$(RuntimeIdentifier)'=='win-x64'" AfterTargets="ResolvePackageAssets">
<ItemGroup>
<!-- match onnxruntime*cuda.* (we're matching %(Filename) which excludes the extension) -->
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="$([System.Text.RegularExpressions.Regex]::IsMatch('%(Filename)',
'^onnxruntime.*cuda.*', RegexOptions.IgnoreCase))" />
</ItemGroup>
<Message Importance="Normal" Text="Excluded onnxruntime CUDA libraries from package." />
</Target>
<!-- Remove QNN EP and IHV libraries on Windows arm64 -->
<Target Name="ExcludeQnnLibs" Condition="'$(RuntimeIdentifier)'=='win-arm64'" AfterTargets="ResolvePackageAssets">
<ItemGroup>
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="$([System.Text.RegularExpressions.Regex]::IsMatch('%(Filename)%(Extension)',
'^QNN.*\.dll', RegexOptions.IgnoreCase))" />
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="$([System.Text.RegularExpressions.Regex]::IsMatch('%(Filename)',
'^libQNNhtp.*', RegexOptions.IgnoreCase))" />
<NativeCopyLocalItems Remove="@(NativeCopyLocalItems)"
Condition="'%(FileName)%(Extension)' == 'onnxruntime_providers_qnn.dll'" />
</ItemGroup>
<Message Importance="Normal" Text="Excluded onnxruntime QNN libraries from package." />
</Target>
<!-- need to manually copy on linux-x64 due to the nuget packages not having the correct props file setup -->
<ItemGroup Condition="'$(RuntimeIdentifier)' == 'linux-x64'">
<!-- 'Update' as the Core package will add these dependencies, but we want to be explicit about the version -->
<PackageReference Update="Microsoft.ML.OnnxRuntime.Gpu" />
<PackageReference Update="Microsoft.ML.OnnxRuntimeGenAI.Cuda" />
<OrtNativeLibs Include="$(NuGetPackageRoot)microsoft.ml.onnxruntime.gpu.linux/$(OnnxRuntimeVersion)/runtimes/$(RuntimeIdentifier)/native/*" />
<OrtGenAINativeLibs Include="$(NuGetPackageRoot)microsoft.ml.onnxruntimegenai.cuda/$(OnnxRuntimeGenAIVersion)/runtimes/$(RuntimeIdentifier)/native/*" />
</ItemGroup>
<Target Name="CopyOrtNativeLibs" AfterTargets="Build" Condition=" '$(RuntimeIdentifier)' == 'linux-x64'">
<Copy SourceFiles="@(OrtNativeLibs)" DestinationFolder="$(OutputPath)"></Copy>
<Copy SourceFiles="@(OrtGenAINativeLibs)" DestinationFolder="$(OutputPath)"></Copy>
</Target>
</Project>
I projektfilen (.csproj) lägger du till följande rad för att importera ExcludeExtraLibs.props filen:
<!-- other project file content -->
<Import Project="ExcludeExtraLibs.props" />
Windows: CUDA-beroenden
CUDA EP hämtas till ditt Linux-program via Microsoft.ML.OnnxRuntime.Foundry, men vi inkluderar inte IHV-biblioteken. Om du vill att slutanvändarna med CUDA-aktiverade enheter ska kunna dra nytta av högre prestanda måste du lägga till följande CUDA IHV-bibliotek i ditt program:
- CUBLAS v12.8.4 (ladda ned från NVIDIA Developer)
- cublas64_12.dll
- cublasLt64_12.dll
- CUDA RT v12.8.90 (ladda ned från NVIDIA Developer)
- cudart64_12.dll
- CUDNN v9.8.0 (ladda ned från NVIDIA Developer)
- cudnn_graph64_9.dll
- cudnn_ops64_9.dll
- cudnn64_9.dll
- CUDA FFT v11.3.3.83 (ladda ned från NVIDIA Developer)
- cufft64_11.dll
Varning
Om du lägger till CUDA EP- och IHV-biblioteken i ditt program ökar storleken på ditt programpaket med 1 GB.
Samples
- Exempelprogram som visar hur du använder Foundry Local C# SDK finns i GitHub-lagringsplatsen Foundry Local C# SDK Samples.
API-referensen
- Mer information om Foundry Local C# SDK finns i Foundry Local C# SDK API-referens.
Rust SDK-referens
Med Rust SDK för Foundry Local kan du hantera modeller, kontrollera cacheminnet och interagera med den lokala foundry-tjänsten.
Förutsättningar
- Installera Foundry Local och kontrollera att
foundrykommandot är tillgängligt på dinPATH. - Använd Rust 1.70.0 eller senare.
Installation
Om du vill använda Foundry Local Rust SDK lägger du till följande i :Cargo.toml
[dependencies]
foundry-local = "0.1.0"
Du kan alternativt lägga till Foundry Local-lådan genom att använda cargo:
cargo add foundry-local
Snabbstart
Använd det här kodfragmentet för att kontrollera att SDK:et kan starta tjänsten och läsa den lokala katalogen.
use anyhow::Result;
use foundry_local::FoundryLocalManager;
#[tokio::main]
async fn main() -> Result<()> {
let mut manager = FoundryLocalManager::builder().bootstrap(true).build().await?;
let models = manager.list_catalog_models().await?;
println!("Catalog models available: {}", models.len());
Ok(())
}
I det här exemplet skrivs ett tal som inte är noll ut när tjänsten körs och katalogen är tillgänglig.
Referenser:
FoundryLocalManager
Chef för Foundry Local SDK-verksamhet.
Fält
-
service_uri: Option<String>— URI för foundry-tjänsten. -
client: Option<HttpClient>— HTTP-klient för API-begäranden. -
catalog_list: Option<Vec<FoundryModelInfo>>— Cachelagrad lista över katalogmodeller. -
catalog_dict: Option<HashMap<String, FoundryModelInfo>>– Cachelagrad ordlista över katalogmodeller. -
timeout: Option<u64>– Valfri tidsgräns för HTTP-klienten.
Methods
pub fn builder() -> FoundryLocalManagerBuilder
Skapa en ny byggare förFoundryLocalManager.pub fn service_uri(&self) -> Result<&str>
Hämta tjänstens URI.
Returnerar: URI för Foundry-tjänsten.fn client(&self) -> Result<&HttpClient>
Hämta HTTP-klientinstansen.
Returnerar: HTTP-klient.pub fn endpoint(&self) -> Result<String>
Hämta slutpunkten för tjänsten.
Returnerar: Endpunkt-URL.pub fn api_key(&self) -> String
Hämta API-nyckeln för autentisering.
Returnerar: API-nyckel.pub fn is_service_running(&mut self) -> bool
Kontrollera om tjänsten körs och ange tjänst-URI:n om den hittas.
Returnerar:trueom körs,falseannars.pub fn start_service(&mut self) -> Result<()>
Starta Foundry Local-tjänsten.pub async fn list_catalog_models(&mut self) -> Result<&Vec<FoundryModelInfo>>
Hämta en lista över tillgängliga modeller i katalogen.pub fn refresh_catalog(&mut self)
Uppdatera katalogcachen.pub async fn get_model_info(&mut self, alias_or_model_id: &str, raise_on_not_found: bool) -> Result<FoundryModelInfo>
Hämta modellinformation efter alias eller ID.
Argument:-
alias_or_model_id: Alias eller modell-ID. -
raise_on_not_found: Om sant, fel om det inte hittas.
-
pub async fn get_cache_location(&self) -> Result<String>
Hämta cacheplatsen som en sträng.pub async fn list_cached_models(&mut self) -> Result<Vec<FoundryModelInfo>>
Lista cachelagrade modeller.pub async fn download_model(&mut self, alias_or_model_id: &str, token: Option<&str>, force: bool) -> Result<FoundryModelInfo>
Ladda ned en modell.
Argument:-
alias_or_model_id: Alias eller modell-ID. -
token: Valfri autentiseringstoken. -
force: Framtvinga ny nedladdning om det redan har cachelagrats.
-
pub async fn load_model(&mut self, alias_or_model_id: &str, ttl: Option<i32>) -> Result<FoundryModelInfo>
Läs in en modell för slutsatsdragning.
Argument:-
alias_or_model_id: Alias eller modell-ID. -
ttl: Valfri time-to-live i sekunder.
-
pub async fn unload_model(&mut self, alias_or_model_id: &str, force: bool) -> Result<()>
Ta bort en modell.
Argument:-
alias_or_model_id: Alias eller modell-ID. -
force: Tvångsavlasta även om det används.
-
pub async fn list_loaded_models(&mut self) -> Result<Vec<FoundryModelInfo>>
Visa en lista över inlästa modeller.
FoundryLocalManagerBuilder
Konstruktor för att skapa en FoundryLocalManager instans.
Fält
-
alias_or_model_id: Option<String>– Alias eller modell-ID för att ladda ned och läsa in. -
bootstrap: bool— Om tjänsten ska startas själv om den inte redan är igång. -
timeout_secs: Option<u64>— HTTP-klientens timeout på några sekunder.
Methods
pub fn new() -> Self
Skapa en ny builder-instans.pub fn alias_or_model_id(mut self, alias_or_model_id: impl Into<String>) -> Self
Ange alias eller modell-ID för att ladda ned och ladda in.pub fn bootstrap(mut self, bootstrap: bool) -> Self
Ange om tjänsten ska startas om den inte körs.pub fn timeout_secs(mut self, timeout_secs: u64) -> Self
Ange tidsgränsen för HTTP-klienten i sekunder.pub async fn build(self) -> Result<FoundryLocalManager>
Skapa instansenFoundryLocalManager.
FoundryModelInfo
Representerar information om en modell.
Fält
-
alias: String– Modellaliaset. -
id: String— Modell-ID. -
version: String— Modellversionen. -
runtime: ExecutionProvider— Exekveringsleverantören (CPU, CUDA osv.). -
uri: String– Modellens URI. -
file_size_mb: i32– Modellfilstorlek i MB. -
prompt_template: serde_json::Value– Fråga efter mall för modellen. -
provider: String— Providernamn. -
publisher: String– Utgivarens namn. -
license: String– Licenstyp. -
task: String— Modellaktivitet (t.ex. textgenerering).
Methods
from_list_response(response: &FoundryListResponseModel) -> Self
Skapar ettFoundryModelInfofrån ett katalogsvar.to_download_body(&self) -> serde_json::Value
Konverterar modellinformationen till en JSON-brödtext för nedladdningsbegäranden.
ExecutionProvider
Enum för exekveringsleverantörer som stöds.
CPUWebGPUCUDAQNN
Methods
get_alias(&self) -> String
Returnerar ett strängalias för exekveringsprovidern.
ModelRuntime
Beskriver körningsmiljön för en modell.
device_type: DeviceTypeexecution_provider: ExecutionProvider