Apache Flink-programlägeskluster i HDInsight på AKS
Viktigt!
Den här funktionen finns i förhandsgranskning. De kompletterande användningsvillkoren för Förhandsversioner av Microsoft Azure innehåller fler juridiska villkor som gäller för Azure-funktioner som är i betaversion, förhandsversion eller på annat sätt ännu inte har släppts i allmän tillgänglighet. Information om den här specifika förhandsversionen finns i Azure HDInsight på AKS-förhandsversionsinformation. Om du vill ha frågor eller funktionsförslag skickar du en begäran på AskHDInsight med informationen och följer oss för fler uppdateringar i Azure HDInsight Community.
HDInsight på AKS erbjuder nu ett Flink-programlägeskluster. Med det här klustret kan du hantera livscykeln för klustrets Flink-programläge med hjälp av Azure-portalen med ett användarvänligt gränssnitt och Rest-API:er för Azure Resource Management. Programlägeskluster är utformade för att stödja stora och långvariga jobb med dedikerade resurser och hantera resursintensiva eller omfattande databearbetningsuppgifter.
Med det här distributionsläget kan du tilldela dedikerade resurser för specifika Flink-program, vilket säkerställer att de har tillräckligt med databehandlingskraft och minne för att hantera stora arbetsbelastningar effektivt.

Fördelar
Förenklad klusterdistribution med jobbburk.
Användarvänligt REST-API: HDInsight på AKS tillhandahåller användarvänliga ARM Rest-API:er för att hantera jobbåtgärder i appläge som Uppdatering, Sparapunkt, Avbryt, Ta bort.
Lätt att hantera jobb Uppdateringar och tillståndshantering: Den inbyggda Azure-portalintegreringen ger en problemfri upplevelse för att uppdatera jobb och återställa dem till deras senast sparade tillstånd (sparpunkt). Den här funktionen säkerställer kontinuitet och dataintegritet under hela jobblivscykeln.
Automatisera Flink-jobb med hjälp av Azure Pipelines eller andra CI/CD-verktyg: Med HDInsight på AKS har Flink-användare åtkomst till användarvänligt ARM Rest API kan du sömlöst integrera Flink-jobbåtgärder i din Azure Pipeline eller andra CI/CD-verktyg.
Nyckelfunktioner
Stoppa och starta jobb med savepoints: Användare kan smidigt stoppa och starta sina Flink AppMode-jobb från sitt tidigare tillstånd (Savepoint). Spara punkter säkerställer att jobbförloppet bevaras, vilket möjliggör sömlösa återupptagningar.
Jobb Uppdateringar: Användaren kan uppdatera det AppMode-jobb som körs när jar-filen har uppdaterats på lagringskontot. Den här uppdateringen tar automatiskt sparandepunkten och startar AppMode-jobbet med en ny jar.
Tillståndslös Uppdateringar: Att utföra en ny omstart för ett AppMode-jobb förenklas med tillståndslösa uppdateringar. Med den här funktionen kan användare initiera en ren omstart med hjälp av den uppdaterade jobbburken.
Savepoint Management: När som helst kan användarna skapa sparanden för sina jobb som körs. Dessa sparandepunkter kan visas och användas för att starta om jobbet från en specifik kontrollpunkt efter behov.
Avbryt: Avbryter jobbet permanent.
Ta bort: Ta bort AppMode-kluster.
Så här skapar du Flink-programkluster
Förutsättningar
Slutför förutsättningarna i följande avsnitt:
Lägg till jobbburk i lagringskontot.
Innan du konfigurerar ett Flink App Mode-kluster krävs flera förberedande steg. Ett av de här stegen omfattar att placera applägesjobbets JAR-fil i klustrets lagringskonto.
Skapa en katalog för JAR för applägesjobb:
I de dedikerade containrarna skapar du en katalog där du laddar upp JAR-filen för applägesjobbet. Den här katalogen fungerar som plats för lagring av JAR-filer som du vill inkludera i klassökvägen för Flink-klustret eller jobbet.
Savepoints Directory (valfritt):
Om användarna tänker använda sparandepunkter under jobbkörningen skapar du en separat katalog i lagringskontot för lagring av dessa sparandepunkter. Den här katalogen används för att lagra kontrollpunktsdata och metadata för savepoints.
Exempel på katalogstruktur:
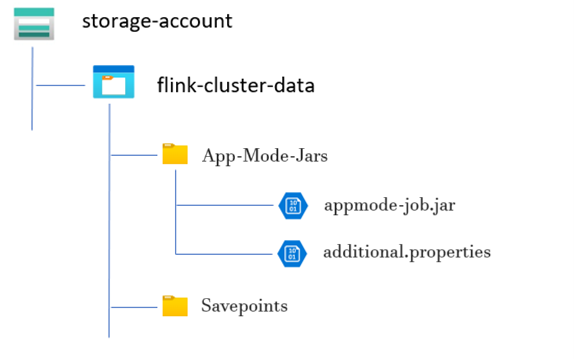

Skapa Flink-applägeskluster
Flink AppMode-kluster kan skapas när distributionen av klusterpoolen har slutförts. Låt oss gå igenom stegen om du kommer igång med en befintlig klusterpool.
I Azure-portalen skriver du HDInsight-klusterpooler/HDInsight/HDInsight på AKS och väljer Azure HDInsight i AKS-klusterpooler för att gå till sidan klusterpooler. På sidan HDInsight på AKS-klusterpooler väljer du den klusterpool där du vill skapa ett nytt Flink-kluster.

På sidan för den specifika klusterpoolen klickar du på + Nytt kluster och anger följande information:
Property Beskrivning Prenumeration Det här fältet fylls i automatiskt med den Azure-prenumeration som registrerades för klusterpoolen. Resursgrupp Det här fältet fylls i automatiskt och visar resursgruppen i klusterpoolen. Region Det här fältet fylls i automatiskt och visar den region som valts i klusterpoolen. Klusterpool Det här fältet fylls i automatiskt och visar klusterpoolens namn som klustret nu skapas på. Om du vill skapa ett kluster i en annan pool letar du upp klusterpoolen i portalen och klickar på + Nytt kluster. HDInsight på AKS-poolversion Det här fältet fylls i automatiskt och visar den klusterpoolversion som klustret nu skapas på. HDInsight på AKS-version Välj den lägre versionen eller korrigeringsversionen av HDInsight på AKS för det nya klustret. Klustertyp I listrutan väljer du Flink. Klusternamn Ange namnet på det nya klustret. Användartilldelad hanterad identitet I listrutan väljer du den hanterade identitet som ska användas med klustret. Om du är ägare till den hanterade tjänstidentiteten (MSI) och MSI inte har rollen Hanterad identitetsoperator i klustret klickar du på länken under rutan för att tilldela den behörighet som krävs från MSI för AKS-agentpoolen. Om MSI redan har rätt behörigheter visas ingen länk. Se Förutsättningar för andra rolltilldelningar som krävs för MSI. Lagringskonto I listrutan väljer du det lagringskonto som ska associeras med Flink-klustret och anger containernamnet. Den hanterade identiteten beviljas ytterligare åtkomst till det angivna lagringskontot med hjälp av rollen "Lagringsblobdataägare" när klustret skapas. Virtuellt nätverk Det virtuella nätverket för klustret. Undernät Det virtuella undernätet för klustret. Aktivera Hive-katalog för Flink SQL:
Property beskrivning Använda Hive-katalog Aktivera det här alternativet om du vill använda ett externt Hive-metaarkiv. SQL Database for Hive I listrutan väljer du den SQL Database där du vill lägga till hive-metaarkivtabeller. ANVÄNDARNAMN för SQL-administratör Ange användarnamnet för SQL Server-administratören. Det här kontot används av metaarkivet för att kommunicera med SQL-databasen. Key Vault I listrutan väljer du Key Vault, som innehåller en hemlighet med lösenord för SQL Server Admin-användarnamn. Du måste konfigurera en åtkomstprincip med alla nödvändiga behörigheter, till exempel nyckelbehörigheter, hemliga behörigheter och certifikatbehörigheter till MSI, som används för att skapa klustret. MSI behöver rollen Key Vault-administratör. Lägg till de behörigheter som krävs med hjälp av IAM. Namn på SQL-lösenordshemlighet Ange det hemliga namnet från Key Vault där SQL-databaslösenordet lagras. 
Kommentar
Som standard använder vi lagringskontot för Hive-katalogen på samma sätt som lagringskontot och containern som användes när klustret skapades.
Välj Nästa: Konfiguration för att fortsätta.
På sidan Konfiguration anger du följande information:
Property beskrivning Nodstorlek Välj den nodstorlek som ska användas för Flink-noderna både huvud- och arbetsnoder. Antal noder Välj antalet noder för Flink-klustret. som standard är huvudnoder två. The worker nodes sizing helps determine the task manager configurations for the Flink. Jobbhanteraren och historikservrarna finns på huvudnoder. I avsnittet Distribution väljer du distributionstyp som Programläge och anger följande information:
Property beskrivning Jar-sökväg Ange ABFS-sökvägen (Lagring) för din jobbburk. Till exempel: abfs://flink@teststorage.dfs.core.windows.net/appmode/job.jarEntry-klass (valfritt) Huvudklass för ditt programlägeskluster. Exempel: com.microsoft.testjob Args (valfritt) Argument för jobbets huvudklass. Spara punktnamn Namnet på den gamla sparandepunkten som du vill använda för att starta jobbet Uppgraderingsläge Välj standardalternativet Uppgradera. Det här alternativet används när större versionsuppgradering sker för kluster. Det finns tre tillgängliga alternativ. UPPDATERING: Används när en användare vill återställa från den senaste sparpunkten efter uppgraderingen. STATELESS_UPDATE: Används när en användare vill ha ny omstart för jobbet efter uppgraderingen. LAST_STATE_UPDATE: Används när en användare vill återställa jobbet från den senaste kontrollpunkten efter uppgraderingen Flink-jobbkonfiguration Lägg till ytterligare konfiguration som krävs för Flink-jobbet. Välj "Sammansättning av jobbloggar". Kryssruta om du vill ladda upp jobbloggen till fjärrlagring. Det hjälper till att felsöka jobbproblemen. Standardplatsen för jobbloggen är "StorageAccount/Container/DeploymentId/logs". Du kan ändra standardloggkatalogen genom att konfigurera "pipeline.remote.log.dir". Standardintervallet för logginsamling är 600 sekunder. Användaren kan ändra genom att konfigurera "pipeline.log.aggregation.interval".
I avsnittet Tjänstkonfiguration anger du följande information:
Property beskrivning Processor för Aktivitetshanteraren Heltal. Ange storleken på Aktivitetshanterarens processorer (i kärnor). Minne för Aktivitetshanteraren i MB Ange minnesstorleken för Aktivitetshanteraren i MB. Min på 1 800 MB. Processor för Job Manager Heltal. Ange antalet processorer för Jobbhanteraren (i kärnor). Jobbhanterarens minne i MB Ange minnesstorleken i MB. Minst 1 800 MB. Processor för historikserver Heltal. Ange antalet processorer för Jobbhanteraren (i kärnor). Historikserverminne i MB Ange minnesstorleken i MB. Minst 1 800 MB. 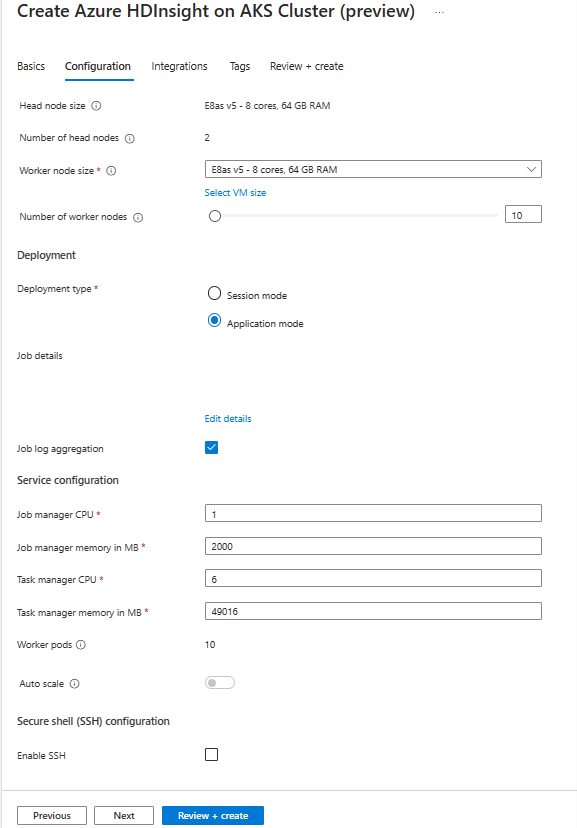
Klicka på Nästa: Integreringsknappen för att fortsätta till nästa sida.
På sidan Integrering anger du följande information:
Property beskrivning Log Analytics Den här funktionen är endast tillgänglig om den klusterpool som är associerad med log analytics-arbetsytan, när de loggar som ska samlas in kan väljas. Azure Prometheus Den här funktionen är att visa insikter och loggar direkt i klustret genom att skicka mått och loggar till Azure Monitor-arbetsytan. 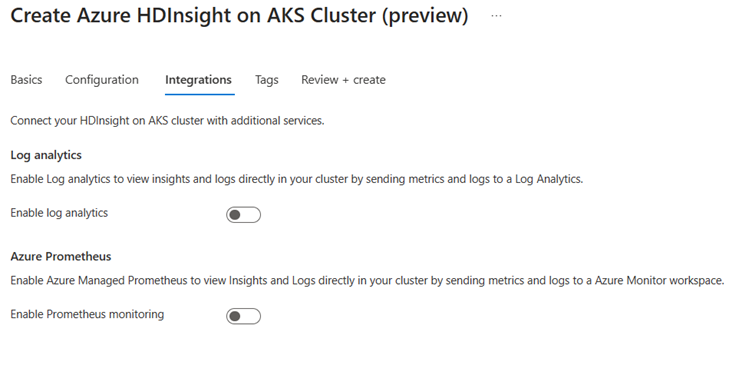
Klicka på knappen Nästa: Taggar för att fortsätta till nästa sida.
På sidan Taggar anger du följande information:
Property Beskrivning Name Valfritt. Ange ett namn som HDInsight på AKS för att enkelt identifiera alla resurser som är associerade med dina klusterresurser. Värde Du kan lämna det tomt. Resurs Välj Alla resurser har valts. Välj Nästa: Granska + skapa för att fortsätta.
På sidan Granska + skapa letar du efter meddelandet Validering lyckades överst på sidan och klickar sedan på Skapa.




Sidan Distribution i process visade vilket kluster som skapas. Det tar 5–10 minuter att skapa klustret. När klustret har skapats visas meddelandet "Distributionen är klar". Om du navigerar bort från sidan kan du kontrollera om dina meddelanden har aktuell status.
Hantera programjobb från portalen
HDInsight AKS tillhandahåller sätt att hantera Flink-jobb. Du kan starta om ett misslyckat jobb. Starta om jobbet från portalen.
Om du vill köra Flink-jobbet från portalen går du till:
Portal > HDInsight på AKS-klusterpoolens > Flink-kluster > Inställningar > Flink-jobb.

Stopp: Stoppjobbet krävde inga parametrar. Användaren kan stoppa jobbet genom att välja åtgärden. När jobbet har stoppats stoppas jobbstatusen på portalen.
Start: Startar jobbet från savepoint. Starta jobbet genom att välja det stoppade jobbet och starta det.
Uppdatering: Uppdateringen hjälper till att starta om jobb med uppdaterad jobbkod. Användarna måste uppdatera den senaste jobbburken på lagringsplatsen och uppdatera jobbet från portalen. Den här åtgärden stoppar jobbet med savepoint och börjar igen med den senaste jar-filen.
Tillståndslös uppdatering: Tillståndslös är som en uppdatering, men det innebär en ny omstart av jobbet med den senaste koden. När jobbet har uppdaterats visas jobbstatusen på portalen som Körs.
Spara punkt: Ta sparpunkten för Flink-jobbet.
Avbryt: Avsluta jobbet.
Ta bort: Ta bort AppMode-kluster.
Visa jobbinformation: Om du vill visa jobbinformationen som användaren kan klicka på jobbnamnet ger det information om jobbet och resultatet av den senaste åtgärden.
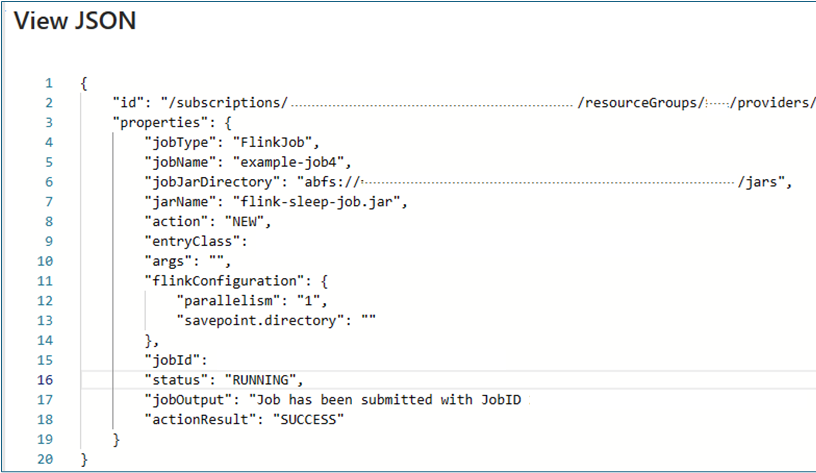

För alla misslyckade åtgärder ger den här json-vyn detaljerade undantag och orsaker till felet.