Tabell-API och SQL i Apache Flink-kluster® i HDInsight på AKS
Viktigt!
Den här funktionen finns i förhandsgranskning. De kompletterande användningsvillkoren för Förhandsversioner av Microsoft Azure innehåller fler juridiska villkor som gäller för Azure-funktioner som är i betaversion, förhandsversion eller på annat sätt ännu inte har släppts i allmän tillgänglighet. Information om den här specifika förhandsversionen finns i Azure HDInsight på AKS-förhandsversionsinformation. Om du vill ha frågor eller funktionsförslag skickar du en begäran på AskHDInsight med informationen och följer oss för fler uppdateringar i Azure HDInsight Community.
Apache Flink har två relations-API:er – tabell-API:et och SQL – för enhetlig dataström och batchbearbetning. Tabell-API:et är ett språkintegrerad fråge-API som tillåter sammansättningen av frågor från relationsoperatorer, till exempel val, filter och koppling intuitivt. Flinks SQL-stöd baseras på Apache Calcite, som implementerar SQL-standarden.
Tabell-API:et och SQL-gränssnitten integreras sömlöst med varandra och Flinks DataStream-API. Du kan enkelt växla mellan alla API:er och bibliotek, som bygger på dem.
Apache Flink SQL
Liksom andra SQL-motorer fungerar Flink-frågor ovanpå tabeller. Den skiljer sig från en traditionell databas eftersom Flink inte hanterar vilande data lokalt. i stället fungerar frågorna kontinuerligt över externa tabeller.
Flink-databearbetningspipelines börjar med källtabeller och slutar med mottagartabeller. Källtabeller skapar rader som körs under frågekörningen. de är tabellerna som refereras i FROM-satsen för en fråga. Anslut orer kan vara av typen HDInsight Kafka, HDInsight HBase, Azure Event Hubs, databaser, filsystem eller andra system vars anslutningsapp ligger i klassökvägen.
Använda Flink SQL Client i HDInsight i AKS-kluster
Du kan läsa den här artikeln om hur du använder CLI från Secure Shell på Azure-portalen. Här följer några snabba exempel på hur du kommer igång.
Starta SQL-klienten
./bin/sql-client.shSkicka en sql-initieringsfil som ska köras tillsammans med sql-client
./sql-client.sh -i /path/to/init_file.sqlSå här anger du en konfiguration i sql-client
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
SQL DDL
Flink SQL stöder följande CREATE-instruktioner
- CREATE TABLE
- SKAPA DATABAS
- SKAPA KATALOG
Följande är en exempelsyntax för att definiera en källtabell med jdbc-anslutningsprogrammet för att ansluta till MSSQL, med ID, namn som kolumner i en CREATE TABLE-instruktion
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
SKAPA DATABAS :
CREATE DATABASE students;
SKAPA KATALOG:
CREATE CATALOG myhive WITH ('type'='hive');
Du kan köra kontinuerliga frågor ovanpå dessa tabeller
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Skriv ut till mottagartabellen från källtabellen:
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Lägga till beroenden
JAR-uttryck används för att lägga till användarburkar i klassökvägen eller ta bort användarburkar från klassökvägen eller visa tillagda jars i klassökvägen i körningen.
Flink SQL stöder följande JAR-instruktioner:
- ADD JAR
- VISA JAR-FLÖDEN
- TA BORT JAR
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
Hive-metaarkiv i Apache Flink-kluster® i HDInsight på AKS
Kataloger tillhandahåller metadata, till exempel databaser, tabeller, partitioner, vyer och funktioner och information som behövs för att komma åt data som lagras i en databas eller andra externa system.
I HDInsight på AKS stöder Flink två katalogalternativ:
GenericInMemoryCatalog
GenericInMemoryCatalog är en minnesintern implementering av en katalog. Alla objekt är endast tillgängliga under sql-sessionens livslängd.
HiveCatalog
HiveCatalog har två syften: som beständig lagring för rena Flink-metadata och som ett gränssnitt för att läsa och skriva befintliga Hive-metadata.
Kommentar
HDInsight på AKS-kluster levereras med ett integrerat alternativ för Hive Metastore för Apache Flink. Du kan välja Hive Metastore när klustret skapas
Skapa och registrera Flink-databaser i kataloger
Du kan läsa den här artikeln om hur du använder CLI och kommer igång med Flink SQL Client från Secure Shell på Azure-portalen.
Starta
sql-client.shsession
Default_catalog är standardkatalogen i minnet
Låt oss nu kontrollera standarddatabasen för minnesintern katalog
Låt oss skapa Hive-katalogen av version 3.1.2 och använda den
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;Kommentar
HDInsight på AKS stöder Hive 3.1.2 och Hadoop 3.3.2.
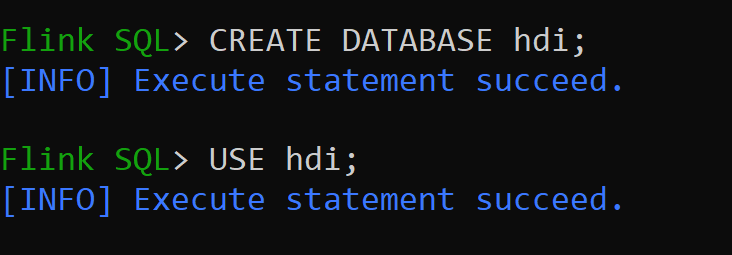
hive-conf-dirÄr inställt på plats/opt/hive-confLåt oss skapa databasen i hive-katalogen och göra den till standard för sessionen (om den inte har ändrats).
Skapa och registrera Hive-tabeller i Hive-katalogen
Följ anvisningarna om hur du skapar och registrerar Flink-databaser till katalog
Låt oss skapa Flink-tabell av anslutningstyp Hive utan partition
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');Infoga data i hive_table
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';Läsa data från hive_table
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rowsKommentar
Hive Warehouse Directory finns i den avsedda containern för lagringskontot som valdes när Apache Flink-klustret skapades, finns i katalogen hive/warehouse/
Låter skapa Flink-tabell av anslutningstypsdatafil med partition
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
Viktigt!
Det finns en känd begränsning i Apache Flink. De sista n-kolumnerna väljs för partitioner, oavsett användardefinierad partitionskolumn. FLINK-32596 Partitionsnyckeln är fel när du använder Flink-dialekt för att skapa Hive-tabell.
Referens
- Apache Flink Table API & SQL
- Apache, Apache Flink, Flink och associerade öppen källkod projektnamn är varumärkensom tillhör Apache Software Foundation (ASF).